LangGraph 持久化(Persistence)[ 3 ]

持久化实现的三大应用能力
那接下来我们就一起来看一下持久化能力实现的三大应用能力。这三大应用能力分别是:第一个记忆功能,第二个人机交互功能,第三个时间旅行功能。
关于这三大能力的具体概念定义,我们会在逐一讲解每个功能的时候再详细说明。现在首先要和大家区分清楚概念层级:我们后续要实现的这三大应用能力,本质上都是基于 LangGraph 的持久化能力延伸而来的。
我们再来回顾巩固一下相关概念,加深大家的记忆。首先要明确,持久化能力是 LangGraph 提供的底层能力。我们此前一直在学习这项底层功能,而现在我们的视角要转向基于 LangGraph 搭建的智能应用系统。对于这类上层应用而言,LangGraph 提供的持久化属于底层支撑,应用本身是建立在这些底层能力之上的。
简单划分层级:外层是依托 LangGraph 开发的 AI 应用、智能应用;这类应用的核心功能,就是我们接下来要讲解的记忆、人机交互、时间旅行这三大应用层能力。这里大家一定要分清表述逻辑:如果有人询问你的 AI 应用具备哪些功能,你要回答应用层面的记忆、人机交互、时间旅行,而不能说应用实现了持久化功能。因为持久化是 LangGraph 框架自带的底层能力,记忆、人机交互、时间旅行才是我们最终落地到产品里的应用能力,并且这三项应用能力,全部依托 LangGraph 的持久化功能来实现。

延伸一下知识点:如果之后大家学习其他非 LangGraph 的 AI 智能框架,比如一些 Java 方向常用的框架,最终开发出的 AI 应用,同样也需要具备记忆、人机交互、时间旅行这些核心能力。区别只在于底层支撑不同:要么依托对应框架自带的持久化能力,要么就需要我们自己手动实现一套持久化逻辑。所以总结来说,对外介绍应用功能,就讲三大应用能力;深挖底层原理,就说明其依托框架的持久化特性实现。
LangGraph 的底层持久化分为线程级持久化和跨会话持久化,这也是我们之前重点学习的内容。线程级持久化依靠线程与检查点(checkpoint)实现整套工作流程;跨会话持久化依托存储库实现数据保存,不仅可以存储关键信息,还支持基于语义检索数据。
记忆(Memory)
记忆概念
记忆,是一种能够记住之前互动信息的系统。对于人工智能代理来说,记忆至关重要,因为它使他们能够记住之前的互动,从反馈中学习,并根据用户偏好进行调整。随着代理处理涉及大量用户交互的更复杂任务,这一能力对效率和用户满意度都变得至关重要。
注意要区分记忆和持久化的概念:
- 持久化为 LangGraph 底层能力,包含【线程级】持久化和【跨会话】持久化
- 记忆为 LangGraph 能实现的应用层能力,包含【短期记忆】和【长期记忆】
在应用层,短期记忆就由线程级持久化实现,长期记忆由跨会话持久化实现。
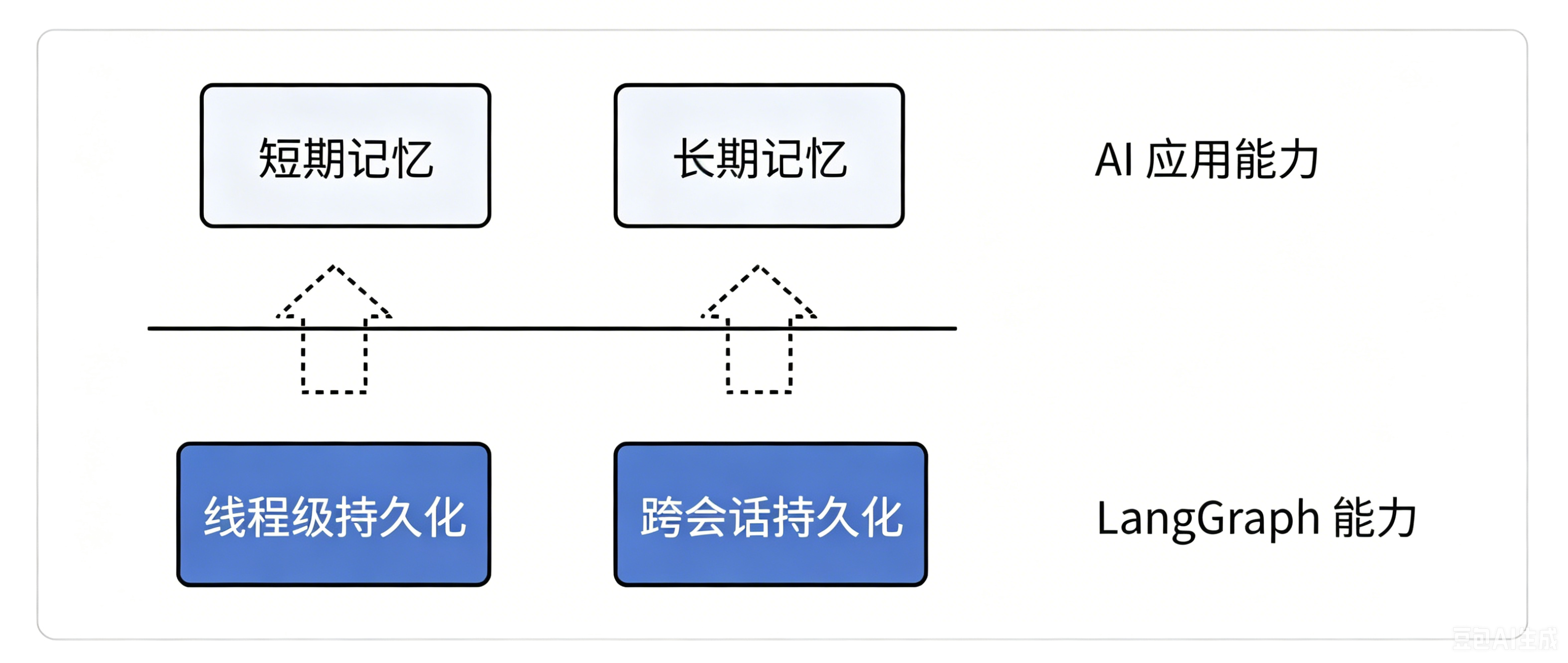
- 短期记忆:单次会话中保持的上下文信息
- 长期记忆:跨会话保存的用户或应用数据
结合实际场景理解:跨会话持久化会把关键数据持久化存储到数据库中,无论用户何时使用、开启多少个会话,都能读取到这些数据,这就是我们所说的长期记忆。落实到智能应用中,长期记忆就是对用户关键信息、业务数据进行长久保存。
而短期记忆,可以直接理解为单线程、单次对话的线程级持久化。在同一个会话里,我们和用户持续交流,系统会不断保存对话历史、状态快照,这就是短期记忆。在 LangGraph 中,短期记忆是一对一绑定单次会话的。简单来说,短期记忆和线程级持久化、长期记忆和跨会话持久化,只是叫法和所处层级不同,底层逻辑完全一致。
基于这个对应关系,短期记忆的操作方式,就是我们此前学过的线程级持久化的使用方法。在编译图的时候配置检查点(checkpoint),就开启了短期记忆。借助它,我们可以获取会话状态快照、查看历史记录、回放对话、更新状态,这些操作统一归类为短期记忆管理,相关用法我们之前已经实操过。
同理,长期记忆的启用方式,就是在编译图时配置存储库(store),之后就可以在图的各个节点中完成数据存储。
了解完概念,我们再讲开发中的存储选型问题,短期记忆和长期记忆通用这套规则。在开发、本地测试阶段,我们选择内存级存储即可;但应用正式上线、进入生产阶段,就必须切换为数据库存储,比如我们之前提到的 PostgreSQL。
这里解释一下选型原因:内存级存储的数据生命周期很短,程序单次运行结束、进程关闭后,内存数据就会被销毁,只适用于本地临时测试,无法满足线上服务需求。而线上应用会部署在服务器中,使用数据库做持久化存储,即便系统意外崩溃,数据库中的数据也不会丢失,能够保证数据长期可用、稳定可靠。
如下所示:
# 开发阶段:内存存储
from langgraph.checkpoint.memory import InMemorySaver
from langgraph.store.memory import InMemoryStore
# 生产阶段:数据库
from langgraph.checkpoint.postgres import PostgresSaver
from langgraph.store.postgres import PostgresStore
管理短期记忆
讲完基础概念,我们继续深入应用层的实操内容。依托线程级持久化实现的短期记忆,在实际使用中会遇到一个典型问题:随着单次会话内对话次数不断增加,状态中的消息列表会持续堆积。消息体量过大后,调用大语言模型时很容易超出 Token 限制。因此我们需要针对消息列表做专项管理,这也是短期记忆管理的核心内容,主要分为三类操作:消息修剪、消息删除、消息总结。除此之外,状态快照、历史记录查看等线程级持久化基础用法,也都属于短期记忆管理范畴。接下来我们逐一讲解这三类消息管理操作。
修剪消息
首先第一类:修剪消息。大多数 LLM 都有一个最大支持的上下文窗口。决定何时截断消息的一种方法是对消息历史记录中的令牌进行计数,并在接近该限制时截断。修剪消息的核心目的,就是控制消息体量,避免超出大模型的 Token 上限。对应的工具方法 trim_messages 我们在 LangChain 阶段就已经学习过。
在 LangGraph 中的使用思路也很明确:我们可以专门构建一个功能节点,在节点内从状态中取出完整消息列表,作为入参传给 trim_messages 方法,完成消息修剪。这里要区分场景:我们当下讲解的,是调用大模型之前对消息做临时修剪【是临时,不是永久】,这种修剪并不会改变状态里原始的消息列表,消息依然会正常叠加保存。
我们再梳理 trim_messages 的核心参数与逻辑:
第一个参数传入待处理的消息列表;strategy 配置修剪策略,设置为 last 代表保留靠后的消息,从列表前端开始裁剪;max_tokens 设定允许保留的最大 Token 数量;token_counter 传入模型对象,由模型负责统计消息的 Token 数量;start_on 和 end_on 用来划定修剪的消息边界,比如从用户消息(human)开始、到用户消息 / 工具消息结束。
设置消息边界是为了保证对话语义完整。举个例子:一轮对话由「用户消息 + AI 消息」组成,我们划定从用户消息开始裁剪,就能保证最后留存的内容是完整的对话轮次,不会出现语义断裂的情况。
结合案例逻辑说明:我们案例中设置最大保留 128 个 Token,这个数值是根据测试场景提前计算好的。我们在同一个会话内连续发起多轮对话,消息不断累积,当第四轮提问时,消息总量触发修剪规则,早期的对话消息会被裁剪。此时如果我们询问 “我的名字是什么”,模型就会因为丢失了早期记录而无法回答。这个案例也直观验证了消息堆积、消息裁剪带来的影响。
同时我们再回顾线程级持久化的工作流程:每一次执行工作流,系统都会加载当前线程内的全部历史状态,此前所有对话产生的消息都会被重新载入,这也是单次会话消息持续累加的根本原因。理解了底层流程,就能明白我们为什么必须做消息修剪。
from langchain_core.messages.utils import trim_messages
from langchain.chat_models import init_chat_model
from langgraph.checkpoint.memory import InMemorySaver
from langgraph.graph import StateGraph, START, END, MessagesState
model = init_chat_model("gpt-4o-mini", temperature=0)
def call_model(state: MessagesState):
# 只保留最近的128个token的消息
messages = trim_messages(
state["messages"],
strategy="last", # 策略:保留最后的部分
token_counter=model, # 计算token数量
max_tokens=128, # 最大token数
start_on="human", # 从用户消息开始
end_on=("human", "tool"), # 结束于用户或工具消息
)
response = model.invoke(messages)
return {"messages": [response]}
checkpointer = InMemorySaver()
builder = StateGraph(MessagesState)
builder.add_node(call_model)
builder.add_edge(START, "call_model")
builder.add_edge("call_model", END)
graph = builder.compile(checkpointer=checkpointer)
config = {"configurable": {"thread_id": "1"}}
graph.invoke({"messages": "hi, my name is bob"}, config)
graph.invoke({"messages": "write a short poem about cats"}, config)
graph.invoke({"messages": "now do the same but for dogs"}, config)
final_response = graph.invoke({"messages": "what's my name?"}, config)
final_response["messages"][-1].pretty_print()
================================== Ai Message ==================================
Based on our conversation, I don't have a name for you. You haven't told me what it is.
Would you like to tell me your name?
进程已结束,退出代码为 0删除消息
接下来第二类操作:删除状态内的消息列表。可以从图状态中删除消息以管理消息历史记录。当想要删除特定消息或清除整个消息历史记录时,这非常有用。这和上一种 “调用模型前临时修剪” 不同,本次操作会直接修改工作流状态里的原始消息列表,永久删除指定消息。
第一种方式:直接覆写状态,清空全部消息。这种方式操作简单,能够一键清空状态内所有历史消息。
第二种方式:根据消息 ID 删除指定消息。LangGraph 中所有消息(用户消息、AI 消息等)都会自动生成唯一 ID,我们可以借助 RemoveMessage 组件,根据 ID 精准删除单条或多条消息。具体用法:遍历状态中的消息列表,根据业务规则筛选出需要删除的消息,取出对应 ID,再将 RemoveMessage 对象组成列表,通过 return 返回,框架就会根据返回内容更新状态、完成消息删除。
举个实操规则示例:我们可以设定规则,当消息列表长度大于 6 条时,删除最早的 6 条消息,只保留最新内容。这里有两个关键注意点:
-
第一,
RemoveMessage必须配合状态返回机制使用,单纯调用方法无法生效; -
第二,该删除方式仅作用于通过消息追加机制生成的消息列表,普通列表格式无法使用此功能。
def call_model(state: MessagesState):
messages = state["messages"]
if len(messages) > 6:
# 删除最早的6条消息
return {
"messages": [RemoveMessage(id=m.id) for m in messages[:6]]
}
response = model.invoke(messages)
return {"messages": [response]}
# ....
# 测试:可以发现只剩最后一条消息了
for message in final_response["messages"]:
message.pretty_print()
除此之外,框架还提供了一键清空所有消息的快捷方式:使用内置常量 REMOVE_ALL_MESSAGES,将其传入 RemoveMessage,就能实现全量消息删除,效果和直接覆写状态清空消息完全一致。
删除所有消息:
from langgraph.graph.message import REMOVE_ALL_MESSAGES
def call_model(state: MessagesState):
return {"messages": [RemoveMessage(id=REMOVE_ALL_MESSAGES)]}
注意:删除后消息无法恢复,要确保删除后的对话仍然是有效的。
消息删除虽然能控制消息体量,但也会带来新问题:删除消息的同时,也会丢失历史对话中的关键信息。就像前面的案例,删除早期消息后,模型就忘记了用户的名字。在实际的 AI 应用中,我们肯定不希望丢失关键历史信息,这就引出了第三类消息管理操作 ——消息总结。
总结消息
实际上,修剪或删除消息也会存在问题:可能会因删除消息而丢失信息。因此,某些应用更希望将消息历史记录进行总结,把旧的对话内容总结成简短摘要,保留关键信息,以代替冗长的历史记录。
第三类:总结消息。核心思路是:在删除原始历史消息之前,先调用大语言模型,把冗长的对话内容提炼成简短的摘要,用摘要替代原始消息保存。这样一来,既缩减了内容体量、降低了 Token 占用,又完整保留了对话的关键信息,解决了裁剪、删除消息导致信息丢失的问题。
想要实现消息总结,首先需要扩展原有状态结构。原本的 MessagesState 只存储消息列表,我们基于它自定义新的状态类,新增一个 summary 字段,专门用来存放对话摘要。
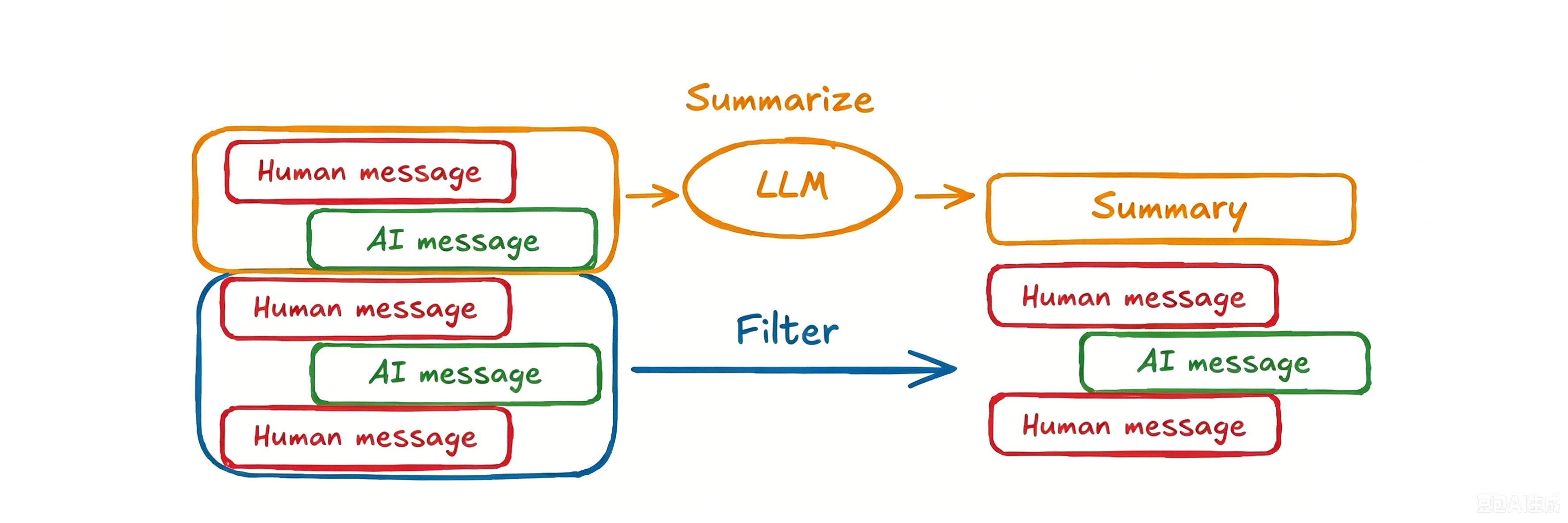
我们可以先将 State 进行扩展,除了对话记录,还包含一个总结摘要字段:
from langgraph.graph import MessagesState
class State(MessagesState):
summary: str
现在要求:
- 对话记录:记录新的对话与结果【继承 MessagesState 自动完成】
- 摘要:每次对话完成,需要进行总结【状态中记录了 summary 字段】
- 完成总结摘要后,可以删除历史对话【可是采用 RemoveMessage 方法】
那么,在每次调用 LLM 时,便可以根据【新的请求】与【总结摘要信息】共同构建提示词来完成请求。
整体业务流程设计为两个核心节点串联:
-
第一个节点负责调用大语言模型处理用户最新提问;
-
第二个节点专门负责对话总结与历史消息清理。
完整代码如下所示:
from langchain.chat_models import init_chat_model
from langchain_core.messages import HumanMessage, RemoveMessage
from langgraph.checkpoint.memory import InMemorySaver
from langgraph.graph import StateGraph, START, MessagesState
model = init_chat_model("gpt-4o-mini", temperature=0)
class State(MessagesState):
summary: str
def call_model(state: State):
# 使用历史总结+最新消息发起调用
summary = state.get("summary", "")
messages = model.invoke([HumanMessage(content=summary)] + state["messages"])
return {"messages": messages}
def summarize_conversation(state: State):
""" 生成历史总结 """
# 1. 创建总结提示词
summary = state.get("summary", "")
if summary: # 有摘要,扩展
summary_message = (
f"这是到目前为止的对话摘要: {summary}\n\n"
"基于上面的新消息扩展摘要: "
)
else: # 无摘要,新增
summary_message = "创建上面对话的摘要: "
# 2. 生成新总结:【消息列表】 + 【历史总结】调用模型
messages = state["messages"] + [HumanMessage(content=summary_message)]
response = model.invoke(messages)
# 3. 删除历史对话:除了最新的AI消息,都可以删除
return {
"summary": response.content, # 历史总结
"messages": [RemoveMessage(id=m.id) for m in state["messages"][:-1]] # 保留最后的消息是为了打印结果
}
checkpointer = InMemorySaver()
builder = StateGraph(State)
builder.add_node("call_model", call_model)
builder.add_node("summarize", summarize_conversation)
builder.add_edge(START, "call_model")
builder.add_edge("call_model", "summarize") # 每次对话完,进行总结
graph = builder.compile(checkpointer=checkpointer)
config = {"configurable": {"thread_id": "1"}}
graph.invoke({"messages": "hi, my name is bob"}, config)
graph.invoke({"messages": "write a short poem about cats"}, config)
graph.invoke({"messages": "now do the same but for dogs"}, config)
final_response = graph.invoke({"messages": "what's my name?"}, config)
final_response["messages"][-1].pretty_print()
print("\nSummary:", final_response["summary"])
# 打印结果如下:
# ================================ Ai Message ================================
# Your name is Bob.
# Summary: 对话摘要: 用户自我介绍为Bob,并询问如何获得帮助。随后,用户请求写一首关于猫的短诗。接着,用户又请求写一首关于狗的短诗。用户对动物的诗歌表现出兴趣,可能希望进一步探讨与宠物相关的主题或创作。
完整流程如下:
- 执行工作流时,系统加载历史状态,读取已生成的摘要
summary和用户最新消息; - 将历史摘要与新消息组合,一并传给大语言模型,得到模型回复;
- 一轮对话结束后,进入总结节点:结合已有摘要、本轮完整对话内容,生成 / 更新最新的全局对话摘要;
- 保留最新一条消息用于结果展示,删除其余所有原始对话消息;
- 状态中仅留存更新后的摘要和最新消息,等待下一轮对话。
我们拆解总结节点的具体逻辑:首先读取状态中已有的摘要字段,判断摘要是否存在。如果已有历史摘要,就构造提示词,要求模型在原有摘要的基础上,结合新对话内容扩展、更新摘要;如果暂无摘要,就提示模型基于当前对话内容,生成第一版对话摘要。
将历史消息、提示词组合后调用大模型,模型返回的文本就是最新的对话摘要。拿到摘要后,我们再执行消息清理逻辑:遍历消息列表,通过消息 ID 删除除最后一条之外的所有原始消息。保留最后一条消息,主要是为了方便我们打印、查看单轮对话的最终结果。
这套流程循环执行:每一轮对话结束,都会更新摘要、清理历史消息。下一轮对话启动时,线程级持久化会加载状态中的摘要,模型依靠摘要就能知晓全部历史关键信息,不会因为原始消息被删除而遗忘内容。同时,简短摘要的 Token 数量远少于多条原始消息,从根源上解决了消息堆积、Token 超限的问题。
结合实际运行效果来看:全程依靠摘要传递历史信息,即便原始对话消息被不断清理,模型也能记住用户身份、过往对话内容。偶尔出现模型识别异常,主要是大模型本身的随机性导致,整体方案是稳定有效的。
不过实际上,对于这里的设计,其实无需每次调用后都进行总结,可设置阈值进行总结。只需判断 消息数量 > 阈值,再进行总结与删除即可。
扩展:LangMem 是一个由 LangChain 维护的库。它提供了可与任何存储系统一起使用的功能原语,也提供了与 LangGraph 存储层的本机集成。例如上述我们手动完成的汇总消息功能,在 LangMem 中专门提供了记忆管理库(如:SummarizationNode),简化了总结消息的过程。有兴趣的同学可以自行了解。
最后我们对记忆功能做整体总结:
-
概念对应:应用层的短期记忆对应 LangGraph 底层线程级持久化,长期记忆对应底层跨会话持久化,底层能力决定上层应用能力;
-
存储选型:开发测试用内存存储,线上生产环境必须使用数据库做持久化;
-
短期记忆管理核心:针对会话内消息列表,提供消息修剪、消息删除、消息总结三种解决方案。修剪和删除用于控制消息体量,但易丢失信息;消息总结是最优方案,兼顾 “瘦身” 和 “信息留存”;
-
核心设计思想:所有操作都是围绕线程级持久化展开,在框架底层能力之上,封装出符合业务需求的应用层逻辑。
以上就是三大应用能力中第一个 —— 记忆功能的全部讲解内容。

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐

 6
6 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)