【论文阅读】RoboFactory: Exploring Embodied Agent Collaboration with Compositional Constraints
·
快速了解部分
基础信息(英文):
- 题目: RoboFactory: Exploring Embodied Agent Collaboration with Compositional Constraints
- 时间: 2025.3
- 机构: Sun Yat-sen University, Shanghai Jiao Tong University, Oxford, Shanghai Artificial Intelligence Laboratory, HKU
- 3个英文关键词: Embodied Agent, Multi-Agent Collaboration, Compositional Constraints
1句话通俗总结本文干了什么事情
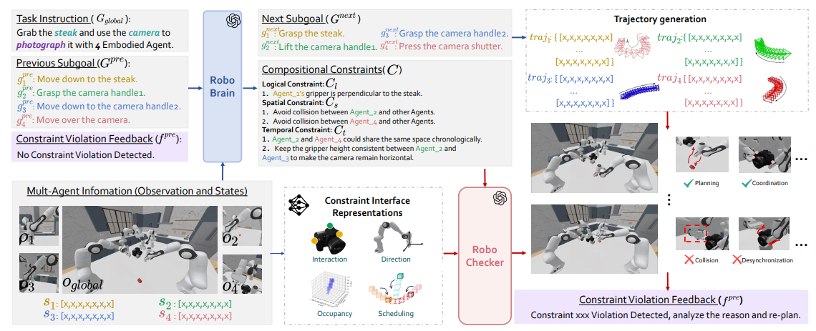
本文提出了一种名为 RoboFactory 的框架和基准测试,利用大模型生成“逻辑、空间、时间”三重限制条件,来自动化地生成高质量的多机器人协作训练数据,并探索了如何训练多机器人模仿学习模型。
研究痛点:现有研究不足 / 要解决的具体问题
- 数据收集难:多机器人协作任务如果靠人手遥操作收集数据,效率极低且昂贵。
- 单智能体方法失效:直接套用单机器人(Single-Agent)的方法到多机器人上会出问题,因为多机器人需要解决**任务分配、防撞(空间)和动作同步(时间)**的复杂问题,缺乏额外的约束会导致动作不合理或失败。
核心方法:关键技术、模型或研究设计(简要)
提出了 Compositional Constraints(组合约束) 概念,包含逻辑、空间、时间三类约束;构建了 RoboFactory 框架(RoboBrain 负责规划生成带约束的轨迹,RoboChecker 负责利用约束接口检查并修正轨迹),从而实现自动化、安全的多机器人数据生成流水线。
深入了解部分
作者想要表达什么
作者想表达:在多机器人协作中,不能只靠大模型“想”出任务就完了,必须要把大模型的抽象指令转化为具体的“物理限制”(如哪里不能去、什么时候动、怎么抓)。 只有通过这种“组合约束”的方式,才能在不依赖大量人工演示的情况下,自动生成既安全又高效的训练数据,从而训练出能真正协同工作的多机器人系统。
相比前人创新在哪里
- 提出了“组合约束”新概念:将多机器人协作的复杂要求具体拆解为逻辑(谁干什么)、空间(别撞车)、时间(同步动)三个维度的可计算约束。
- 自动化数据流水线:不同于以往依赖昂贵的人工遥操作,本文利用 LLM + 约束接口实现了数据的自动生成(Simulation to Real),且保证了数据的安全性。
- 首个基准测试(Benchmark):建立了包含 11 个任务的 RoboFactory Benchmark,填补了多机器人操作领域缺乏标准测试集的空白。
解决方法/算法的通俗解释
想象有两个机械臂要合作拍照:
- 大脑(RoboBrain):用大模型指挥,“机械臂 A 去拿相机,机械臂 B 去拿牛排,然后 A 按快门”。
- 紧箍咒(Constraints):大模型同时生成三条规则:a. 逻辑上,必须先拿相机才能按快门;b. 空间上,两个机械臂不能撞在一起; c. 时间上,按快门时手不能抖(保持静止)。
- 监工(RoboChecker):这是一个专门的小程序,它把这些文字规则变成数学公式(Interface),实时检查机械臂的动作轨迹。如果发现轨迹会导致“撞车”或“顺序错”,就立刻叫停并让大脑重算,直到动作完美为止。
解决方法的具体做法
- RoboBrain (规划):
- 输入:全局任务描述、视觉观测(RGB)、之前的反馈。
- 输出:每个机器人的子目标 + 文本形式的组合约束(逻辑、空间、时间)+ 调用动作原语生成的初始轨迹。
- Constraint Interface (转化):
- 逻辑接口:标注物体的交互点和方向(比如快门只能按,不能抓侧面)。
- 空间接口:利用深度相机或估计生成 3D 占据网格(Voxel),实时检测碰撞。
- 时间接口:建立动态占据模型,检查动作的时间顺序和同步性(比如是否同时抬起了物体)。
- RoboChecker (验证):
- 利用上述接口对轨迹进行代码级的检查(Code Evaluation)。
- 如果违反约束,反馈给 RoboBrain 重新规划;如果通过,则记录为高质量数据。
基于前人的哪些方法
- 大模型(LLM/VLM):利用 GPT-4o 等模型的强大推理能力进行高层任务规划和子目标生成。
- 动作原语(Motion Primitives):利用预定义的、原子化的动作库来执行具体操作,而非从零开始控制关节。
- 模仿学习(Imitation Learning):最终训练策略网络(Policy)是基于生成的专家数据进行模仿(如 Diffusion Policy)。
实验
exp1:
- 设置: 在 RoboFactory Benchmark 上评估 Diffusion Policy 的基线表现。
- 数据: 使用了 50、100、150 组演示数据进行训练。
- 评估方式: 任务成功率。
- 结论: 数据量增加能提升成功率;但随着机器人数量增加(1个到4个),成功率显著下降(从49%降到10%),证明多机器人协作极具挑战性。
exp2: - 设置: 对比 4 种不同的多机器人模仿学习架构(基于 2 个具体任务 Lift Barrier 和 Place Food)。
- 数据: RoboFactory 生成的数据。
- 评估方式: 任务成功率。
- 结论: 独立策略(Separate Policy)优于共享策略;使用**局部视角(Local/Ego view)**通常比全局视角效果更好,因为能捕捉更精细的操作细节。
exp3: - 设置: 消融实验,验证三种约束(逻辑、空间、时间)的有效性。
- 数据: 生成的有效数据。
- 评估方式: 数据生成的成功率(%)和平均片段长度(Episode Length,越短越好)。
- 结论: 缺少空间或时间约束会导致成功率暴跌(证明了防撞和同步的重要性);加入时间约束能显著缩短动作长度,提升效率。
提到的同类工作
- EMET (2024) : 被列为多智能体系统相关工作。
- Partnr (2024) : 被列为具身多智能体任务的规划与推理基准。
- Diffusion Policy (2023) : 被列为机器人模仿学习中的扩散模型方法。
和本文相关性最高的3个文献
- Diffusion Policy: Visuomotor Policy Learning via Action Diffusion (2023) : 本文实验部分主要采用的模仿学习方法,用于训练最终的策略网络。
- ManiSkill (2024) : 本文构建 RoboFactory Benchmark 所基于的模拟仿真平台。
- GPT-4 Technical Report (2023) : 本文 RoboBrain 模块所依赖的核心大模型技术基础。
我的
- multi agent的数据合成:用VLM来生成子目标和约束信息。用另一个VLM来检验是否符合约束。
- 约束主要是逻辑(不同物体抓取点和方向不同)、空间(防碰撞:3D occupancy)、时间(协调多robot动的时间)。

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐



 8
8 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)