从0到1实战:AI知识库智能问答系统搭建全攻略
本次将全程带大家实操,手把手完成AI知识库智能问答系统的从0到1搭建!这套系统以RAG(检索增强生成)为核心,专为企业项目文档场景打造,集成Embedding、BM25与实体检索的多模态检索能力,可高效输出精准的文档问答服务。
项目代码已同步开源,仓库地址:AI知识库智能问答系统。实操前,建议大家先查看项目Raw文件夹内的原始文件,快速摸清项目基础脉络~
一、LLM Wiki的搭建
step1,生成摘要
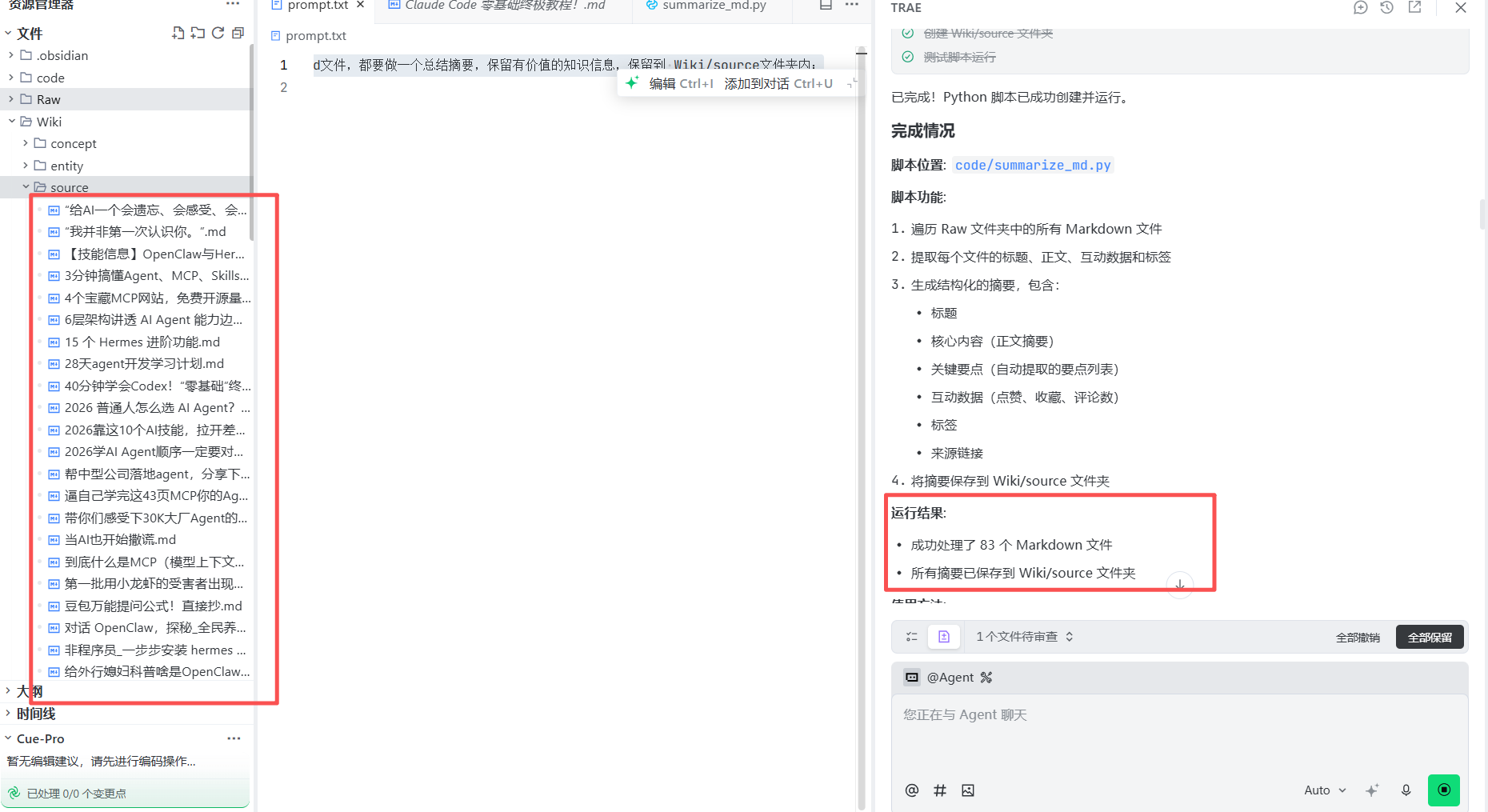
prompt:帮我编写python脚本,脚本保存到code文件夹内,脚本完成的任务:Raw文件夹里面的每一个md文件,都要做一个总结摘要,保留有价值的知识信息,保留到 Wiki/source文件夹内;
step2,生成实体、概念关键字
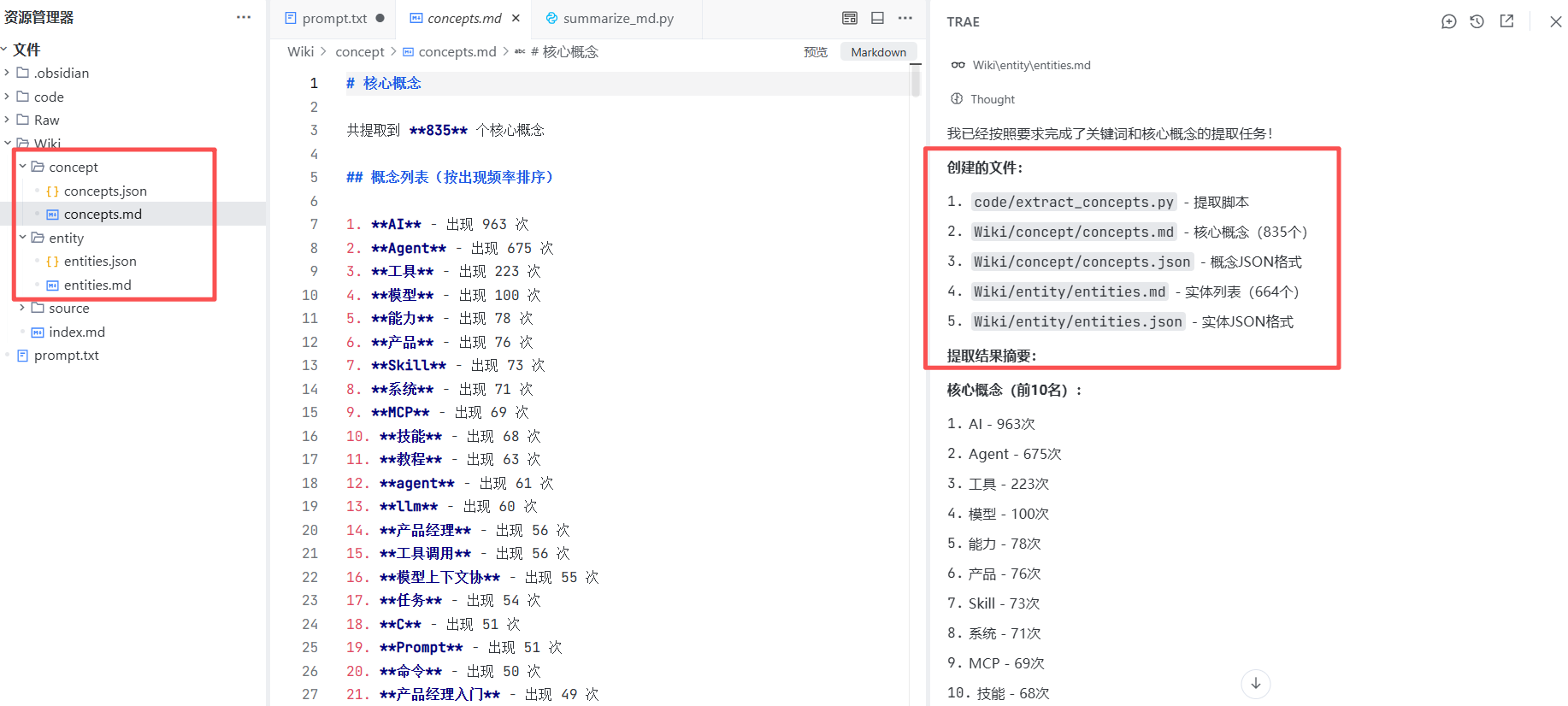
prompt:帮我编写新的.py文件,.py文件放到code文件夹内,任务:基于Raw文件夹、Wiki/source文件夹的所有文件,按照concept概念、entity实体,提取高频出现的关键词以及核心概念,提取的概念保留到Wiki/concept文件夹内,关键词保留到Wiki/entity文件夹内;
step3,生成单独的文件
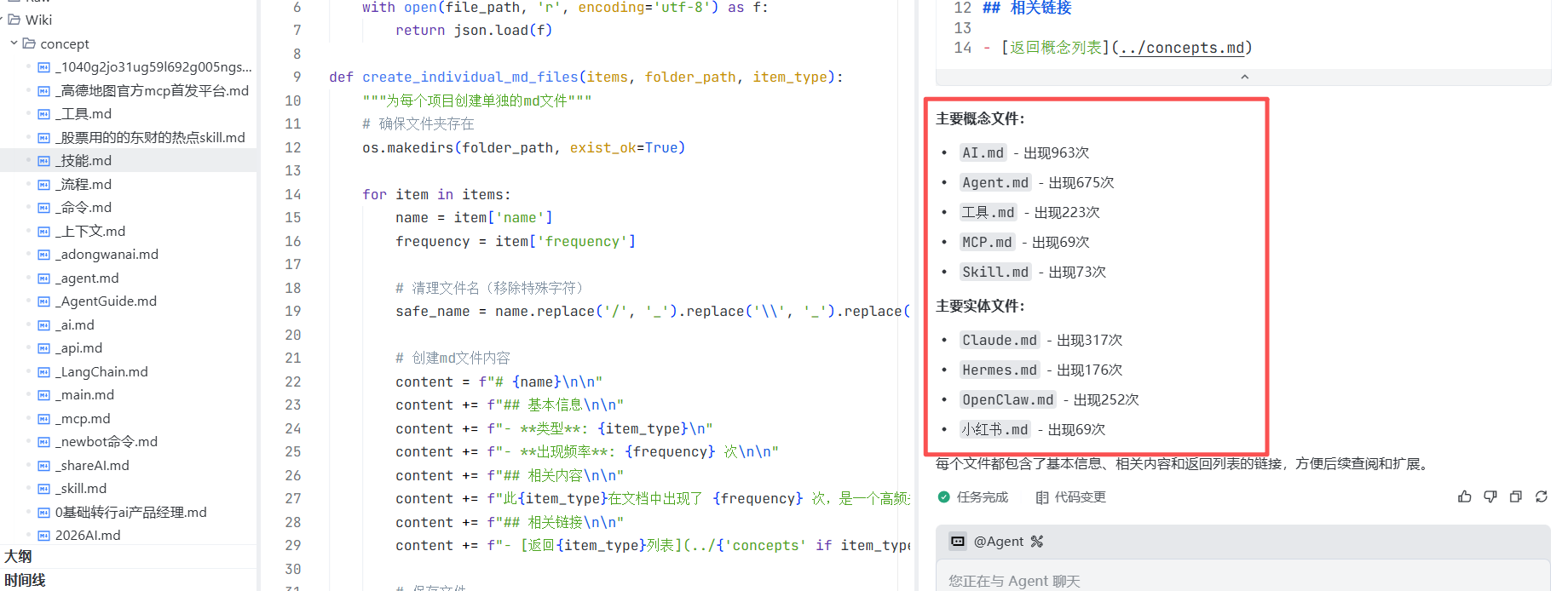
prompt:为这批概念与实体创建单独的md文件
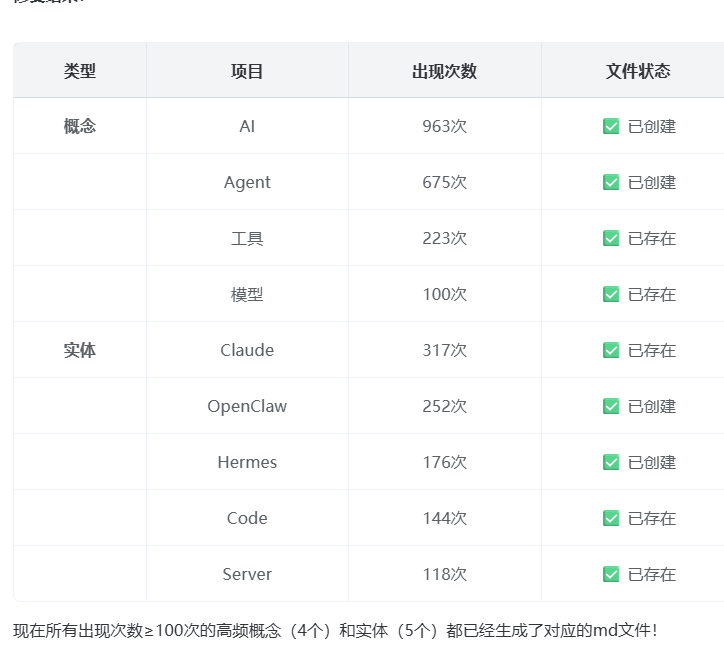
step4,实体、概念.md文件太多了,要做筛选
prompt:给出现次数超过100次的概念、实体,创建单独的md文件,概念相关的md文件保存在Wiki/concept文件夹内,实体相关的md文件保存在Wiki/entity文件夹内;
step5,进行Wiki的双向链接
prompt:我现在已经有了所有的实体和概念,在Wiki/entity文件夹、Wiki/concept文件夹里也都创建好了相应的md文件,现在请你扫描Raw文件夹、Wiki/source文件夹内所有的md文件,将其中扫描到的每一个实体关键字、概念关键字,都改为[[关键字]]格式,所有合法的实体和概念,都在Wiki/entity文件夹、Wiki/concept文件夹里。
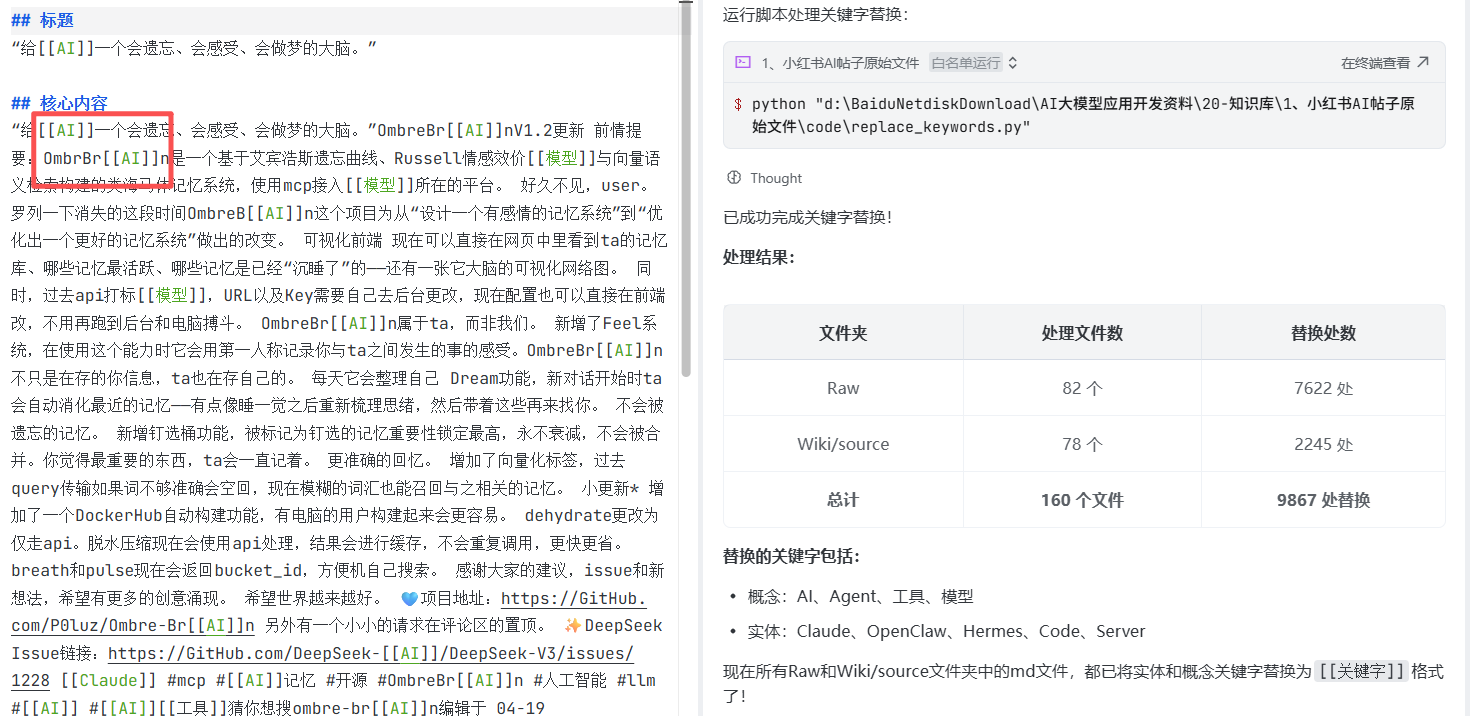
obsidian的实体链接如下:
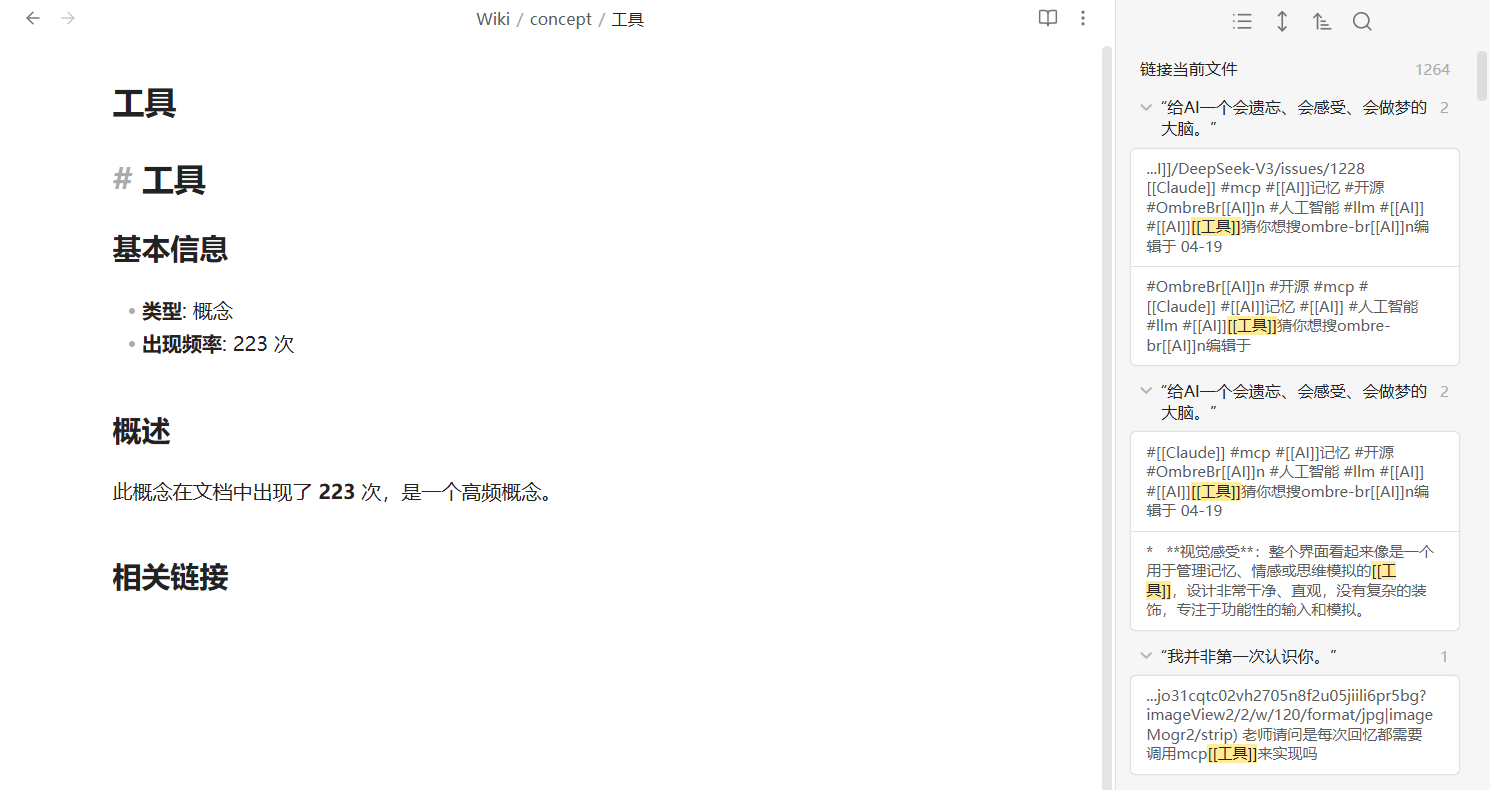
obsidian的关系图谱显示如下:

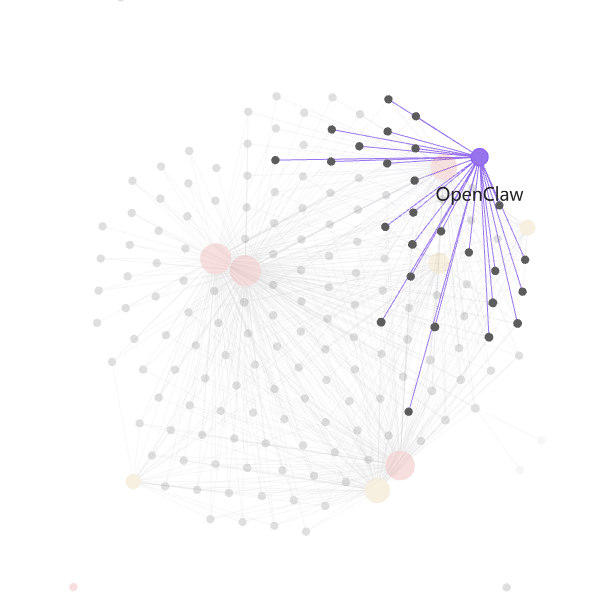
step6,构建index目录
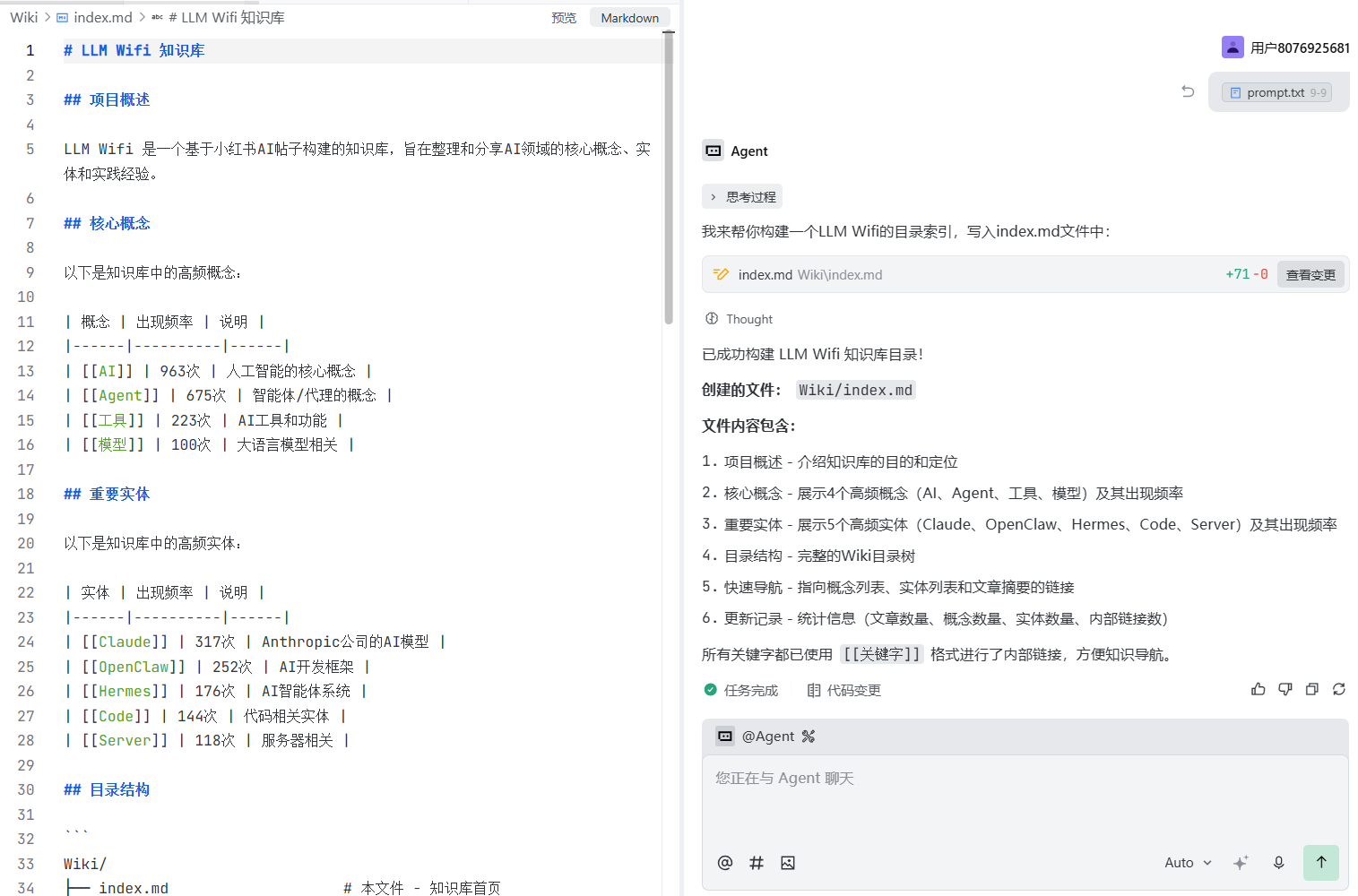
prompt:帮我构建一个LLM Wifi的目录,内容写到index.md内
二、搭建AI知识库智能问答系统
在LLM Wiki的基础上,我们进行搭建AI知识库智能问答系统。
step7,先设计方案:Embedding嵌入+BM25关键词检索、图谱结构检索双路检索引擎
prompt:如果我想基于这套知识库做一个AI问答功能,你设计一下,应该怎么做,只输出方案,不写代码。

step8,方案调整好后,进行编写脚本
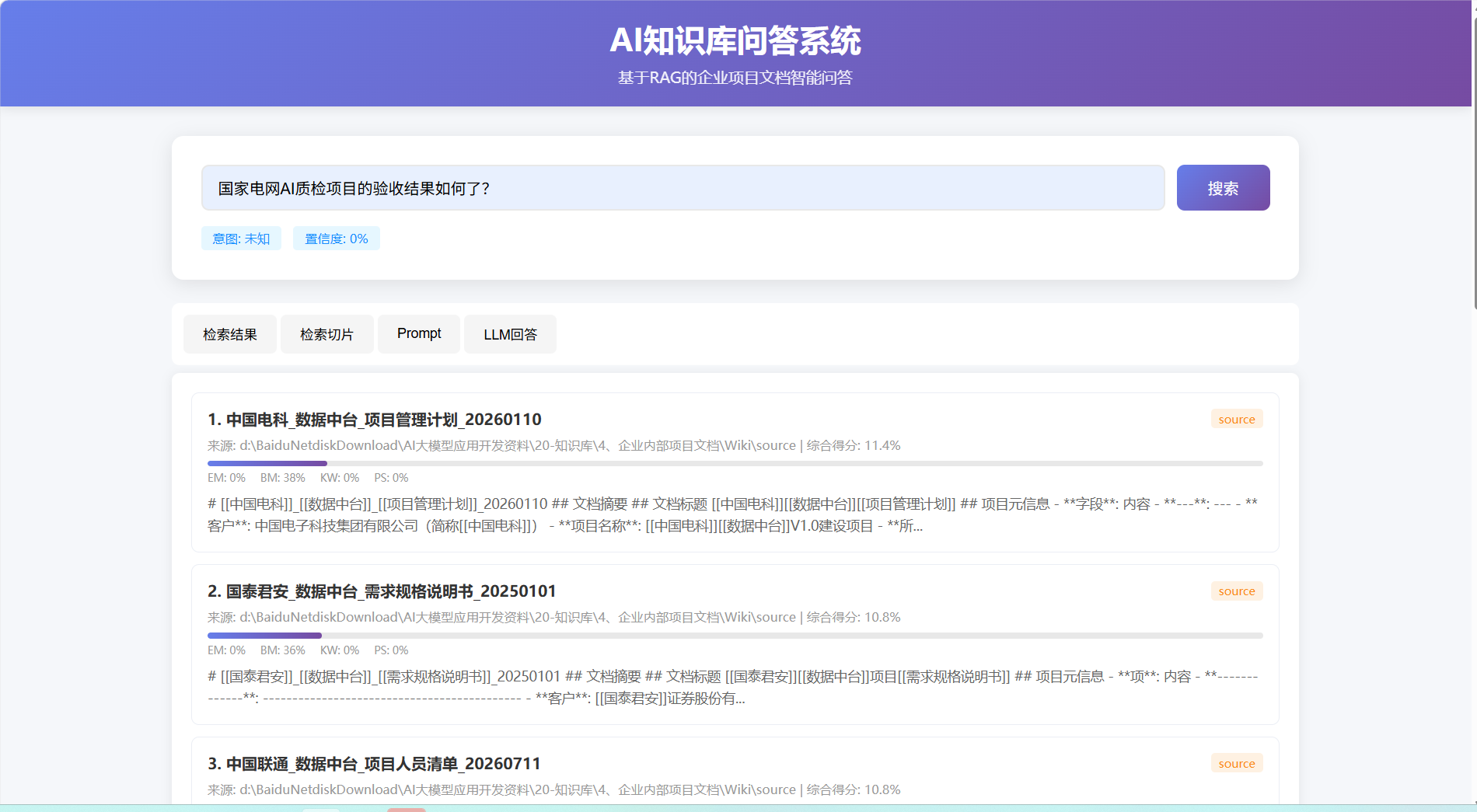
prompt:按照这个方案进行编写代码,代码保存到search文件夹内,同时也需要一个web页面:输入query检索,即可展示用户query的检索结果,展示检索到的切片,展示拼接出来的最终提示词,以及最终LLM的回答,
可以参考 @example03.py,编写LLM API。
step8,增加用户query的提取关键字与推荐问题
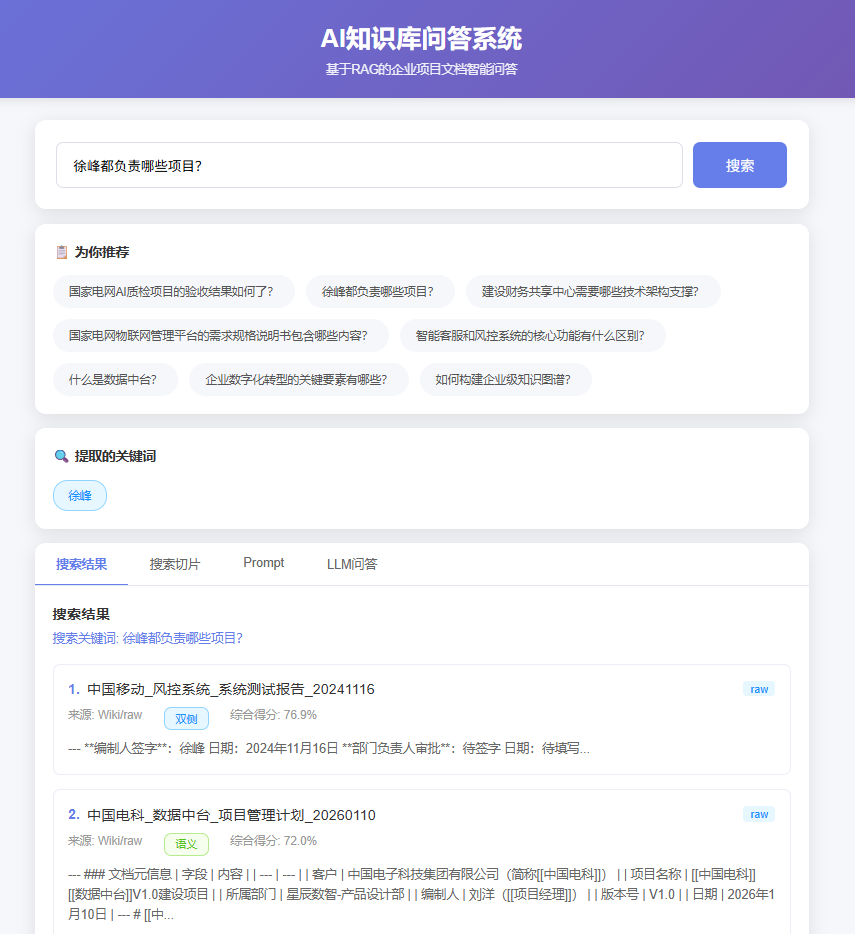
prompt:先把用户query提取关键词,在为你推荐模块下面展示,提取的关键词:xxx,
BM25关键词匹配到的,展示关键词标签,embedding相似度比对到的,显示语义标签,embedding与BM25都匹配到的,显示双侧。
step9,使用llm wiki知识图谱进行检索
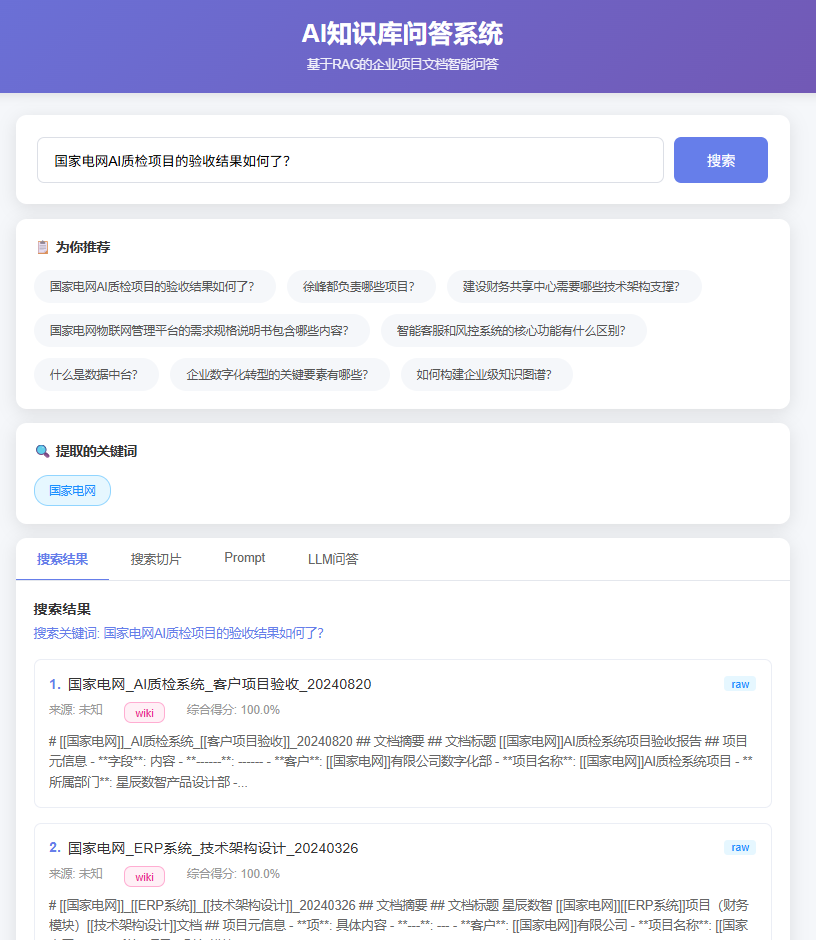
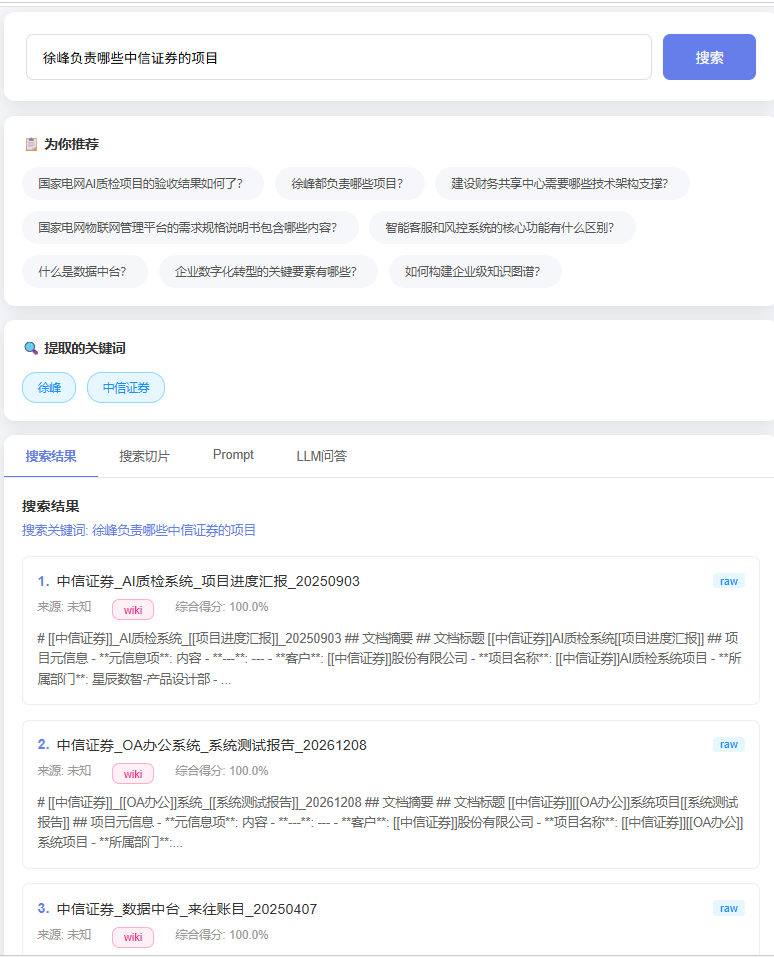
prompt:增加第三种检索方式,如果LLM解析用户的query,得到的关键字,是一个实体或概念,则按照该实体名称去扫描Raw中的所有文件,列出文件内容包含[[实体关键词]]的文件,
并且将文件内容塞到提示词,取消5个召回的限制,在实体的这种检索模式下,所有文件都可以进入提示词,让LLM进行回答,第三种搜索模式直接跳过关键词和向量检索。
step10,先去读目录,而不应该直接搜索关键词或向量,按照llm wiki来,双向跳转逻辑
prompt:你帮我设计一下,什么样的query,应该先去读目录,而不应该直接搜索关键词或向量

RAG、LLM Winki的微调
step10,RAG优化
prompt:统计一下“徐峰负责哪些项目”,关键词是徐峰的时候,实体检索到的5个文档,都塞进提示词后,最后拼接出来的总提示词字数
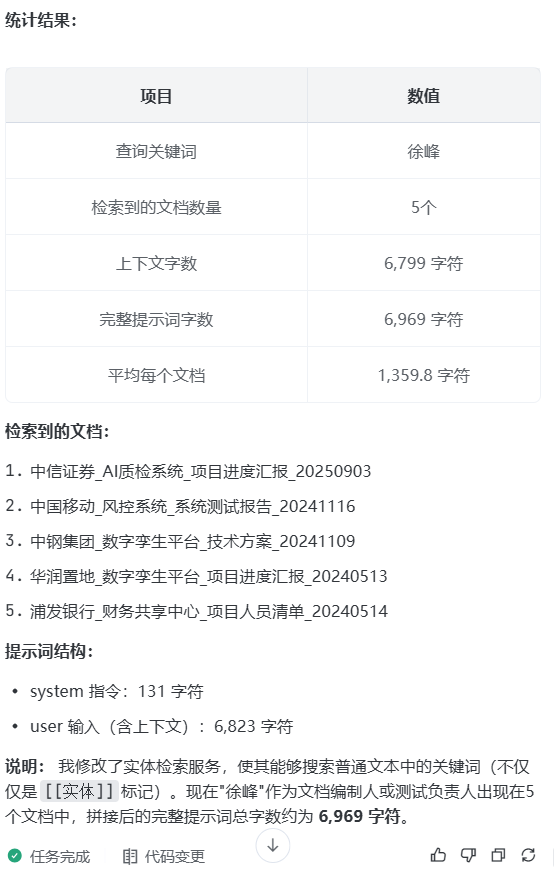
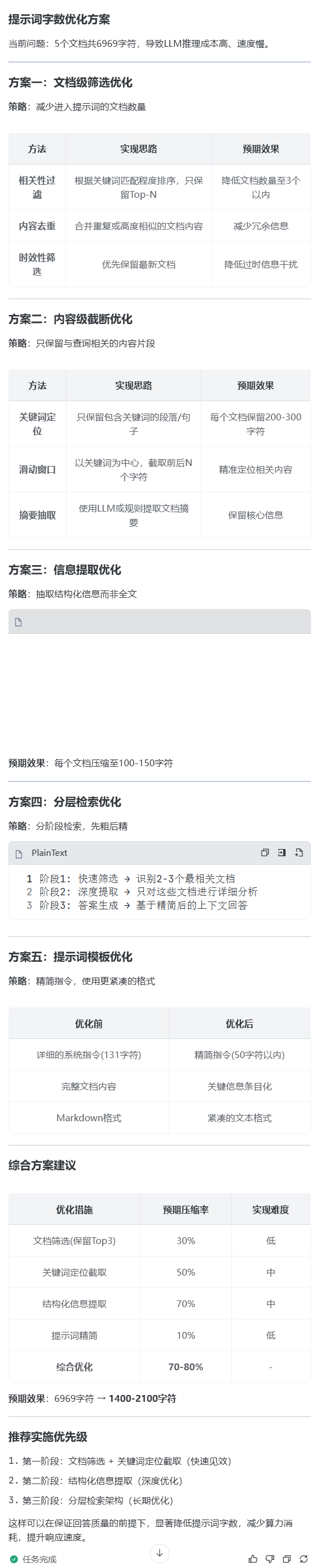
prompt:字数太多,太消耗算力,又贵又慢,你设计一下,6969字,5个文档,如何优化,可以降低提示词的字数,先输出方案,不要修改代码

流程只是框架,细节才是产品的灵魂
这份流程仅梳理了核心脉络,其中大量待打磨的细节并未逐一展开。打造一款真正优质的产品,本就需要沉下心、耐住性,在反复打磨中沉淀价值。我在此仅作抛砖引玉,帮大家理清行动方向、锚定关键环节,真正的落地实践,还需靠各位在后续的打磨中,一步步将细节打磨到位,让产品从框架走向成熟。

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐
 4
4 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)