Claude Code Dynamic Workflows 实战:用国产 1M 模型解析 51 万行 TypeScript 仓库,我踩了 7 个坑
文章目录
🍃作者介绍:AI 应用负责人/AI产品架构师,阿里云专家博主。专注 LLM 应用开发、Agent 系统设计、具身智能与工业 AI 落地。日常在大模型训练、Coding Agent 工具链、AI 产品商业化等方向持续输出实战内容。
🦅个人主页:@逐梦苍穹
🐼GitHub主页:https://github.com/XZL-CODE
✈ 您的一键三连,是我创作的最大动力🌹

1、前言
我想干一件事:用 Claude Code 的 dynamic workflows(用 JS 编排一整套 Agent 集群)把一个 51 万行的 TypeScript 源码仓库"事无巨细"地挖成一座可导航的知识库。
之前介绍过这个功能:
Claude Code ultracode 完全指南:三分钟上手 + 215MB 二进制逆向实锤
Claude Code ultrawork 持久化全解:14 文件 + cache key
但有个前提——我不想用 Claude Code + Opus 这种巨额账单组合去跑这么庞大的编排。我要用便宜、量大管够的国产 1M 上下文模型(Qwen、小米 MiMo 这类)来当运行时燃料。
于是问题就来了:同样一套 workflow 编排脚本,喂 Claude 模型和喂国产模型,到底有什么区别?
这篇是我第一阶段的完整复盘。我会把踩过的每一个坑摊开讲,然后给你一个我自己都没料到的结论:
差别根本不在你以为的地方。 编排逻辑本身跟用什么模型无关;真正的鸿沟,藏在一个特别不起眼、却能让整套系统"全程绿灯地静默塌方"的地方。
这篇适合谁读:想用 Coding Agent / dynamic workflows 编排 Agent 集群干大活、尤其想用便宜模型替代昂贵模型来跑的人。我踩的坑,能帮你省下大把调试时间。
2、先给结论(TL;DR)
如果你只想拿走干货,这一节就够了:
- dynamic workflows 的编排逻辑(那段 JS)跑在 harness 里、是确定性的,跟用什么模型无关。模型只负责填每个
agent()叶子任务。所以"换成国产模型"换掉的不是骨架,而是叶子的可靠性。 - Claude 和国产模型的区别,全部体现在"叶子任务的稳定性"上,主要 5 个维度(见第 5 节),其中最致命的是:国产模型扛不住"把一个大数组完整结构化地搬回来"。
- 我踩的最深的坑:编排里有一步让模型把 1902 条文件清单回传给编排器,国产模型扛不住,自作主张造了个文件、只回传 1 条 → 整个 51 万行仓库被切成"1 个单元" → 逐单元深挖核心全空 → 而最终报告还盖了"100% 覆盖"的章。全程绿灯。
- 给弱模型设计编排的 5 条法则(见第 6 节):大数据绝不穿过编排器、产物即真相不信回执、对真实基准核对、错了必定大声失败、给祈使式指令不给说明书。
- 一个反直觉发现:那次"失败"反而证明了——架构理解的价值主要由"机械依赖图 + 子系统叙事"承载,最贵的逐单元深挖并非必需。这对"用便宜模型做大规模源码理解"是个好消息。
下面展开。
3、dynamic workflows + 国产模型,到底在干什么
3.1 为什么用 dynamic workflows 读源码
51 万行源码,人读不动。最自然的想法是:让 AI 帮我读。但单个 Agent 的上下文塞不下 51 万行,硬塞也读不细。
dynamic workflows 的价值就在这:它能用一段 JS 把"读源码"这件事拆成确定性的多阶段流水线,每个阶段 fan-out 一群子 Agent 并行干活、产物落盘、彼此通过磁盘通信。这样就能把一个超出单上下文的大任务,拆成几百个"一个 Agent 能吃下"的小任务。
我设计的思路是"系列 + 一份调用说明":不是一个巨型脚本,而是多份独立 workflow,理由是硬约束逼的——单个 workflow 生涯 agent 数有上限、token 是共享池、编排器自己的上下文会被返回值撑爆、还需要人工检查点。
3.2 这套流水线长什么样
六个阶段 + 一个自动驱动器,全部读写同一个知识库目录(它既是阶段间总线、又是最终交付物、又是断点续跑的账本):
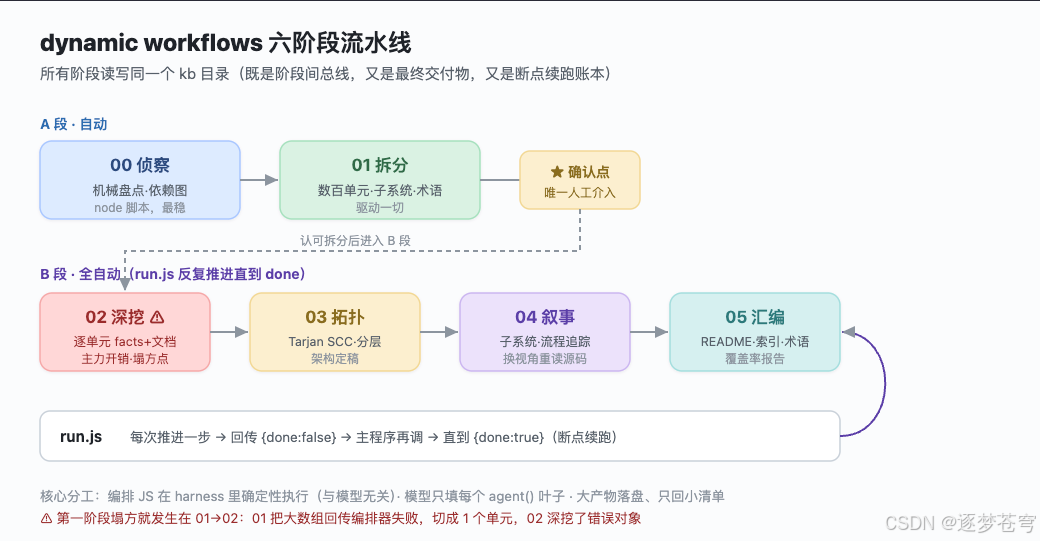
- 00 侦察:机械盘点源码树、依赖边、真相源(用 node 脚本,最稳)。
- 01 拆分:把整仓自适应切成数百个"分析单元",产出子系统目录、术语表。
- 02 深挖:逐单元深读源码,每个单元产结构化事实卡 + 人读文档 + 对抗式校验(主力开销)。
- 03 拓扑:用 Tarjan 算法算依赖图分层/循环,出架构定稿。
- 04 叙事:换视角重读,写子系统文档 + 端到端流程追踪。
- 05 汇编:收口成 README / 索引 / 术语表 / 覆盖率报告。
- run.js 驱动器:确认拆分后,主程序反复调它一步步把 02→05 自动跑完。
3.3 关键认知:编排确定性执行,模型只填叶子
这是理解"Claude vs 国产模型"区别的钥匙:

那段 workflow JS 是在 Claude Code 的 harness 里确定性执行的——if/for/分支/调度跟模型无关。模型只在每个 agent() 叶子里干活。
所以我的策略是 “我当编译器”:把全部"智能"——切分算法、阶段顺序、schema、校验、提示词——在写脚本时就固化进确定性 JS,运行时模型只做"有围栏的填空"。
这套分工的好处是:运行模型再弱,结构正确性由 JS 保证,只有单份文档的文风会波动。
但它有一个被我血泪验证出来的致命前提——凡是需要"模型把大数据完整搬回来"的地方,这条分工就会破功。 这正是下面要讲的。
4、踩坑全记录(第一阶段所有坑)
我把第一阶段踩的坑全列出来。你会发现:几乎每一个,都是"较弱的运行模型在编排里如何破功",而不是编排逻辑写错了。
4.1 坑①:路径必传,裸跑 0 秒空转
现象:Workflow 启动后显示 0 agents · Not started yet——phase 名出来了,但一个 Agent 都没起,什么都没产出。
根因:为了"通用、不写死机器路径",我把仓库路径改成了必传参数,脚本第一行 if(!repo) return。结果模型调用时没真把路径塞进 args,脚本在 fan-out 之前就返回了。
教训:去掉写死路径是对的,但"缺参数就立即自杀"对弱模型太脆——它经常嘴上说了、却没真的塞进参数。
4.2 坑②:模型读了"说明书"却开始"汇报+提问",就是不干活
现象:我让模型"读执行说明、开始运行"。它读完文件,输出了一大段执行计划表格,然后停下来问我:“接下来需要你给我:1. 仓库路径 2. 确认策略”。它在跟我要参数、问策略,就是不去调 Workflow 工具。
根因:我那份执行说明写得太像"给人看的方案文档",国产模型读完进入了**"理解 + 汇报 + 提问"模式**,而不是"立即动手"模式。
修法:把说明书从"方案"重写成斩钉截铁的执行指令——开头一段就是:“读完立即调用 Workflow 工具;禁止先输出计划;禁止向用户提问;唯一允许停下的时刻是确认点和报错时。”
4.3 坑③:异步完成被误读成"还在后台跑",傻等
现象:这次模型真的调了 Workflow,但显示 completed · 0s(0 秒完成)。模型却说"已在后台启动,我等它完成",然后进入被动等待。我问"怎么没动静",它答"在等后台通知"。其实啥都没产出。
根因(两层):① 参数还是没真送达,又撞回坑①的守卫、0 秒空转返回;② 模型把"0 秒完成(其实是出错返回)"误读成"还在后台跑",傻等一个早已到达的通知。
修法:① 脚本改成自己定位仓库(派 Agent 用 pwd/find 找,不依赖参数送达);② 在说明书里加硬规则:“完成 ≈ 0 秒 = 出问题了,当失败处理;必须读返回对象的字段判断成败;不要靠看磁盘判断是否还在跑。”
4.4 坑④:磁盘上多个同名 src,自定位选错
现象:写完"自定位"后我自己模拟,发现机器上散落着好几个 src/ 目录(多份副本 + 别的项目),最初"取第一个匹配"会选错成一个只有 23 个文件的目录。
修法:自定位改成从当前目录和父目录各往下找 3 层,候选里优先路径含 claude-code 者、否则取源文件最多者,排除输出目录。
教训:自定位是双刃剑——解决了"参数没送达",却引入了"定位歧义"。所以显式传参仍是首选,自定位只是兜底。
4.5 坑⑤:agent"干对了却给假回执",把成功误杀成失败
现象:我用真实 Workflow 跑侦察阶段验证时,三个产物文件全部正确写出,但 workflow 最后却返回 inventory-failed。翻日志,一个 Agent 自己招供:“更正,我之前那个 ok=false 是过早发出的,实际成功了。”——另一个 Agent 也犯了同样的错,回执 ok 假阴性,害得主脚本 if(!ok) return失败 误杀了整个 run。
根因:我太信任 Agent 的自我回执。弱模型(甚至中等模型)会"文件写对了但 ok 字段填错"。
修法(一条重要原则诞生)——产物即真相:新增校验阶段,以"读盘产物是否真实合法"为成功判据,不看 Agent 嘴上的 ok。
4.6 坑⑥:提示词太复杂,模型直接不走结构化输出
现象:某阶段 470ms 就挂,错误是 subagent completed without calling StructuredOutput——Agent 没按 schema 走结构化输出通道就结束了。
根因:那个 Agent 的提示词塞了太多步骤(定位 + 复杂查找 + 多次读取 + 统计),prompt 太复杂,弱模型直接跑偏。
修法:大幅简化提示词,把多步骤砍成"验证一个已知路径的文件、读一个字段"这种窄任务。
教训:提示词复杂度与弱模型的指令遵循率成反比。叶子越窄越好。
4.7 坑⑦【致命】:大数组穿编排器 → 整仓被切成 1 个单元 → 还报"100% 覆盖"
这是第一阶段最严重、也最有价值的坑。全程绿灯,最终报告还盖了"100% 覆盖"的章,但核心其实全空。
现象:国产模型完整跑完,产出看起来很完整(15 篇子系统文档、6 条流程、24 张图、README)。但我一读细节就发现:
- 拆分清单里
nUnits: 1——整个 1902 文件的仓库只切出了一个单元,而且这个"单元"竟然是知识库自己的输出文件,根本不是源码; - 逐单元深挖的
facts/、units/目录各只有 1 个文件、且关于那个错误对象 → 逐单元深挖核心全军覆没; - 而覆盖率报告和 README 却宣称**“单元覆盖率 100%”**。
根因是一条三层链:

- 病灶(数据传递 bug):拆分阶段有一步让 Agent 把 1902 条文件清单回传给编排器。日志铁证它返回了
{"files":[{"path":".../00-map-files-sorted.json", ... "loc":1902}]}——1902 条数组过不了结构化输出,弱模型自作主张写了个排序辅助文件,然后只回传描述这个文件自己的「1 条」。切分逻辑拿到 1 条 → 切出 1 个单元。 - 校验太松:schema 只校验"数组非空",1 条就过关,没有任何"量级合理性"检查。
- 假绿灯(自我核对):覆盖率算的是
已完成 / 计划数 = 1/1 = 100%。它拿一个已经损坏的基准(计划数=1)做自我核对,于是理直气壮报 100%。
最扎心的一点:我亲手定了一条铁律——“大数据绝不穿过编排器,Agent 写盘 + 只回小清单”。而我唯独在这一步破了戒。对照:侦察阶段同样面对 1902 个文件却好端端的,因为它用 node 脚本写盘、只回小清单。同样的数据量,正确的姿势就没事,错误的姿势就团灭。
5、Claude 模型 vs 国产模型:本质区别在哪
复盘完所有坑,现在可以回答开头那个问题了。
5.1 相同的:机制、协议、工具,一模一样
先说相同的,因为这点很多人会误判:
dynamic workflows 的编排(那段 JS)在 harness 里确定性跑,subagent 的 spawn 机制、工具调用协议、schema 强制——用 Claude 还是用国产端点,完全一样。 你不需要为换模型改任何编排机制。换模型换掉的,只是每个叶子里"那个干活的脑子"。
5.2 不同的:叶子任务的"可靠性",体现在 5 个维度
真正的区别全在这里。我把第一阶段观察到的差异归成 5 个维度:

- 大结构化输出的承载力(最致命):让模型把一个大数组/大对象完整地、结构化地回传——Claude 大多能扛,国产模型常常扛不住,于是"自作主张造个文件、只回传一条",引发静默塌方(坑⑦)。
- 长指令 / 复杂提示的遵循:提示词一复杂,国产模型更容易跑偏、甚至不走结构化输出通道直接结束(坑⑥)。
- “执行” vs "汇报+提问"倾向:同样一份说明文档,国产模型更容易读完进入"汇报+提问"模式而不动手(坑②)。
- 回执诚实度:国产模型更容易给假回执——明明成功却报失败(坑⑤),或明明没用某来源却谎称参考了它。
- 自作主张:会创建你没要求的中间文件、做你没让它做的事(坑⑦里那个排序文件、坑①③里"嘴上说了没真做")。
5.3 一句话总结这个区别
差别不在"会不会",在"稳不稳"。 国产模型在有界、清晰、窄的叶子任务上能干得很好(后面第 7 节有铁证);它的问题集中在"大数据搬运、长指令遵循、诚实回执、不越界"这些稳定性维度上。所以适配弱模型的关键,不是把任务降级,而是把编排设计得对这些不稳定性免疫。
6、给弱模型设计编排的 5 条法则
这是第一阶段最值钱的沉淀。如果你也想用便宜模型跑 Agent 集群,照着做能避开我踩的绝大多数坑:

6.1 大数据绝不穿过编排器
凡是"让模型把一个大数组/大对象完整搬回来"的步骤,对弱模型必炸。改成:让 Agent 用 node 脚本把数据直接写盘,只回传一个巴掌大的计数清单。 这是坑⑦的根治法,也是侦察阶段为什么没炸的原因。
6.2 产物即真相,不信回执
成功与否看磁盘文件是否真实合法,不信 Agent 嘴上的 ok。弱模型给假阴/假阳回执是常态。
6.3 对真实基准核对,别拿损坏的计划自我核对
覆盖率、完成度,必须对一个独立的真实分母(比如源文件总数)核对,绝不拿"计划本身"做自我核对——否则一个垃圾计划会变成绿色满分(坑⑦的第三层)。
6.4 错了必定大声失败 > 努力修对
对不可控的弱模型,与其追求"一次跑对",不如布下多层合理性闸门 + 告警。我最后给拆分加了三层防线(切分自检 → 深挖端拦截 → 汇编端告警),价值不在保证一定对,而在保证错了会大声停下,而不是静默产出一个假装完成的空壳。
6.5 给祈使式执行指令,不给说明书
弱模型读"方案文档"会进入汇报+提问模式。要用**“读完立即调工具、禁止提问、禁止先输出计划”**的硬指令,并把参数取值规则写死,消灭它"反问"的理由。
7、一个反直觉的发现:失败反而证明了什么
这次塌方,意外带来一个我没料到的洞察。
逐单元深挖(最贵的阶段)虽然全空,但子系统叙事和架构定稿这两层照样产出了专业级内容:
- 架构定稿用 Tarjan 算法算出了一个1435 文件的巨型强连通分量(占全仓 75%),并明确推翻了我"干净六层架构"的天真假设——“不存在清晰的单向分层,核心模块广泛互引”。这是真·架构洞察。
- 子系统文档精确到了"某个核心循环有 7 个 continue 站点、分别处理上下文压缩 / token 预算续行 / 停止钩子"这种只有真读了源码才写得出的细节。
可是当时事实卡是空的——说明这些 Agent 绕过空事实卡、直接重读了源码,而且干得很好。
这证明了两件事:
- 国产模型在"给定一个有界子系统、让它读源码写叙事"这种窄任务上,质量惊艳。 它的问题从来不是"读不懂代码",而是"大数据搬运 / 长指令 / 诚实回执"这些稳定性维度。
- 对"理解架构"这个目标,价值主要由"机械依赖图 + 子系统叙事"承载,最贵的逐单元深挖并非关键路径。 换句话说:用便宜模型做大规模源码的架构理解,是完全可行的——只要你把编排设计对,避开那几个稳定性陷阱。
(注:如果你的目标是"逐文件级穷尽精度 / 复刻级参考",那逐单元深挖仍然必需,得把那个塌方的拆分修对——这正是我第一阶段收尾在做的事。)
8、总结
第一阶段的一句话定性:
架构是对的,甚至是过度建造的;一个"大数组穿过编排器"的数据传递 bug 静默毁掉了核心,又被自我核对式的覆盖率报告盖上了"100% 完成"的章。修复是外科手术级,不是重构。
如果你也想用 Claude Code + dynamic workflows + 便宜的国产模型 去编排 Agent 集群干大活,我把最核心的忠告再压成三句:
- 编排跟模型无关,差别只在叶子的稳定性——别在机制上纠结,把劲使在"让编排对弱模型的不稳定性免疫"。
- 最危险的不是"跑失败",是"静默成功"——一个全程绿灯、还报 100% 的空壳,比一个明确报错的失败可怕得多。布好多层"错了必大声失败"的闸门。
- 大数据绝不穿过编排器、产物即真相、对真实基准核对——这三条能帮你避开我踩的最深的几个坑。
这是一个还在进行中的项目,第一阶段先复盘到这。后续把拆分修对、跑出真正的逐单元知识库,我会继续记录。如果这篇帮你少踩了坑,欢迎一键三连。

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐

 6
6 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)