关于在瑞芯微Rk3588s上部署ai语音翻译模型心得记录
硬件和系统
开发板使用的是鲁班猫 RK3588S 平台,核心芯片是 Rockchip RK3588S。当前 SD 卡系统是 Ubuntu 22.04,Python 主环境为 3.10。

板端主要硬件资源包括:
-
RK3588S,带 RKNPU v2,用于跑 RKNN 模型。
-
系统内存约 8GB
-
开发板自带ES8388 完整音频设备,用于录音和播放。
-
7 寸 HDMI IPS 屏,用于显示本地工作界面。
-
32GB SD 卡作为当前项目运行系统。
关于环境,因为考虑到我只是为了体验一下应用层开发以及ai部署,所以也没有必要调整太多底层的东西,选择直接下载了野火官方提供的完整镜像,然后用rufus写进sd卡环境就搞定了.
(如果做图像识别的话有一定区别,为了提高帧率需要解决GStreamer管道优化/RGA硬件加速/DRM零拷贝Sink之类的难点,需要修改设备树或者升级驱动重新编译,最好还是花一两天编译一下SDK)
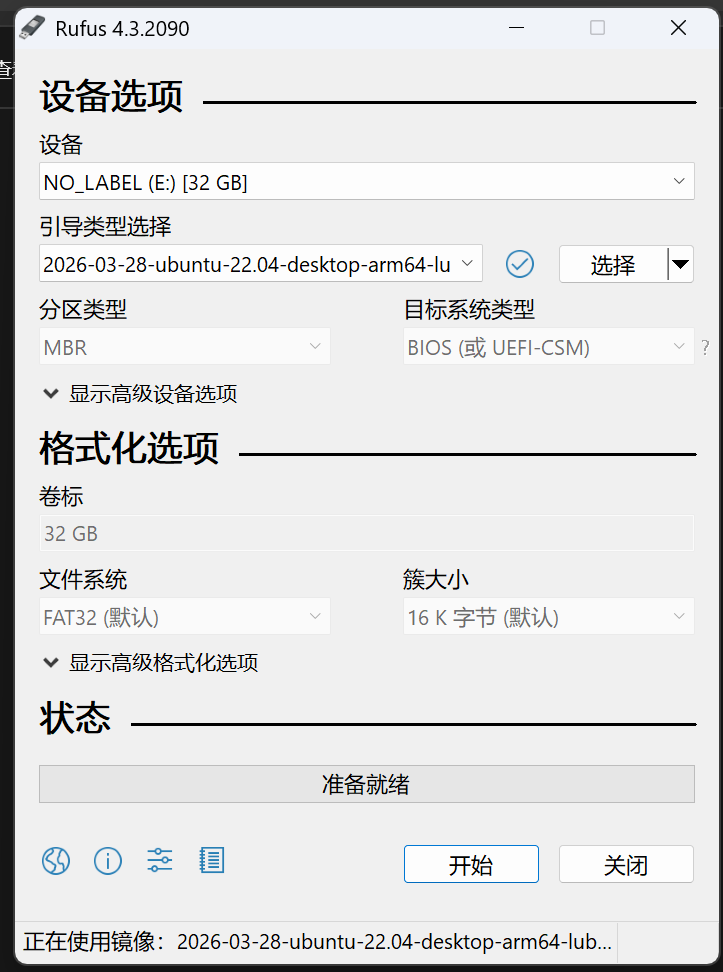
当前模型组合
语音识别使用 Zipformer。原始模型是 ONNX 格式,包含 encoder、decoder、joiner 三个部分,后来在 Ubuntu 虚拟机里用 rknn-toolkit2 2.3.2 转成 RKNN 模型。板端用 rknn-toolkit-lite2 2.3.2 和 librknnrt.so 运行。
原先使用的模型是whisper,效果不太理想(尝试了轻量的tiny和相对完整的base,双双翻车):
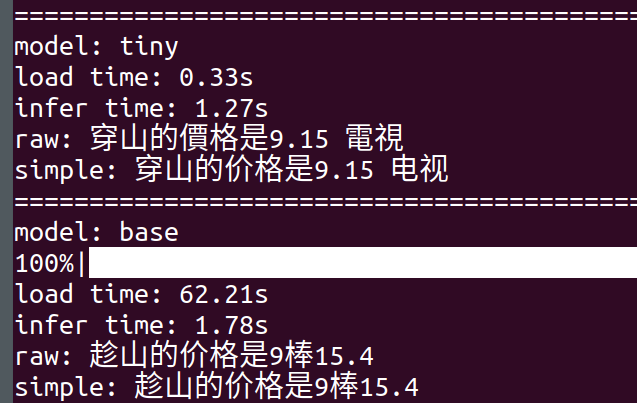
我想说的是"衬衫的价格是九磅十五便士"
Zipformer 是什么
这里要感谢B站lxmyzzs up主提供的模型,非常好用,针对瑞芯微的优化十分优秀
gitee仓库:
AtomGit | GitCode - 全球开发者的开源社区,开源代码托管平台
Zipformer 是一种用于自动语音识别,也就是 ASR 的模型。它可以把输入的语音信号转换成文字。在本项目里,Zipformer 负责完成“中文语音 -> 中文文本”这一步,是整条翻译链路的第一个 AI 模型。这个 GitCode 仓库本身就是一个面向 RK3588、Intel、NVIDIA 等平台的边缘端部署实战库,其中 RK3588 NPU 部署部分明确包含 Zipformer_rk3588,功能是语音识别,支持模型是 Zipformer。
根据lxmyzzs 仓库提供的 Zipformer 示例代码 + ONNX 模型下载方式 在 Ubuntu 虚拟机里用 rknn-toolkit2 把 ONNX 转成 RKNN,再把 .rknn 同步到开发板上运行
翻译使用 Helsinki-NLP 的 opus-mt-zh-en,本地离线加载,基于 Transformers 的 MarianMTModel 跑在 CPU 上。这个模型体积不算大,优点是部署简单,不依赖网络 API;缺点是长句、口语和断句不佳时翻译会受影响。
opus-mt-zh-en 是什么
opus-mt-zh-en 是 Helsinki-NLP 发布的一个中译英机器翻译模型,完整模型名是:
Helsinki-NLP/opus-mt-zh-en
它的任务很单一:把中文文本翻译成英文文本。在项目里,它接在 Zipformer 后面:
Zipformer ASR 得到中文文本 -> opus-mt-zh-en 翻译成英文 -> Piper TTS 播报英文
负责文本翻译。
这个模型属于 OPUS-MT 系列。OPUS-MT 是 Helsinki-NLP 做的开源机器翻译项目,目标是提供免费可用的机器翻译模型和工具。OPUS-MT 论文里提到,这个项目提供了大量预训练神经机器翻译模型,面向在线翻译服务和普通桌面硬件部署。
TTS 原先用过 espeak-ng,声音比较机械。后面换成 Piper,当前声音模型是 en_US-ryan-medium.onnx,效果明显自然一些。Piper 目前也在 CPU 上跑,合成后转成 48k stereo 再通过 ALSA 播放。
Piper 是什么
Piper 是一个本地神经网络 TTS 系统,也就是 Text-To-Speech,文字转语音。官方对它的定位是“fast, local neural text to speech system”,重点就是快、本地运行、神经网络语音合成。
来源:GitHub - rhasspy/piper: A fast, local neural text to speech system · GitHub
一开始用过 espeak-ng,它的优点是轻、容易安装、命令行简单。但缺点也明显:声音比较机械,听起来不像自然语音。Piper 相比 espeak-ng 的提升主要在声音自然度。
离线可用 模型和依赖都放在本地后,不需要网络 API。
声音自然度比 espeak-ng 好很多 演示效果更像正常播报,不那么机械。
模型体积可控 en_US-ryan-medium 大约几十 MB,比 GPT-SoVITS 这类声音克隆方案轻很多。
软件流程
当前主流程如下:
麦克风录音 -> RMS 阈值检测和分段 -> 音频增强 -> Zipformer RKNN/NPU 中文 ASR -> OpenCC 文本规整 -> Opus-MT 离线中译英 -> Piper 英文 TTS -> ALSA 播放 -> HDMI UI 显示状态和文本
界面没有使用完整桌面应用,而是启动一个最小 Xorg,把 PIL 渲染出来的 UI 图片设置成 X root 背景。这样比开一个桌面环境轻。
遇到过分辨率兼容问题,当前 HDMI 输出用 1280x720@50,实测比 1024x600 和 800x600 更稳定。
主程序 -> 写 /tmp/ai_translate_state.json -> UI 渲染脚本读取状态 JSON -> 用 PIL 画成一张 1280x720 图片 -> 用 feh 把图片设置成 X11 root 背景 -> HDMI 屏显示这张背景图
需求只是展示状态和文字,不需要鼠标点击、输入框、复杂控件,所以用这种很土的额方法反而实现最快最稳定。
很轻,不需要完整桌面环境可以放心干掉Gui只保留最小 Xorg 显示环境节省资源。而且稳定,适合开机自启动。
当前反应时间开销
下面是一次完整业务的时间开销估算:
| 环节 | 当前开销 |
|---|---|
| 录音分段最短时长 | min-sec=2.0,短句至少录 2 秒 |
| 句尾静音判断 | end-silence-sec=0.8,说完后约等 0.8 秒才切段 |
| 长句强制切段 | max-sec=10.0,最长 10 秒切一段 |
| Zipformer ASR | 短句通常约 1 秒左右,长段约 1 到 2 秒 |
| Opus-MT 翻译 | 一般短句约 1 到 3 秒 |
| Piper TTS 合成 | 中短句约 2 到 3 秒,之后再按音频长度播放 |
| UI 刷新 | 大约 0.5 到 1 秒级 |
所以现在短句从“说完”到“开始播报”,体感大约在 5 到 8 秒之间。长句如果一直没有满足静音条件,会等到 10 秒强制切段,反应就会更慢。
在录音分段过程中会经常打交道的一个变量叫做RMS (Root Mean Square),均方根。代表一小段声音的平均能量/响度。不是分贝,也不是音量百分比,但可以用来判断当前是不是有声音
RMS = sqrt(平均值(采样值平方))
声音越大,RMS 通常越高。
通过 RMS 判断当前音频帧的能量大小,用它来完成语音分段。录音程序以 100ms 为一帧持续读取麦克风数据,当某一帧 RMS 高于开始阈值时,认为用户开始说话,并把前面短时间的缓存音频一起加入当前语音段,避免切掉句首。
进入语音段后,系统继续统计每帧 RMS。如果连续一段时间低于结束阈值,就认为用户说完一句话,将该段音频保存并送入 ASR;如果一直没有检测到静音,则在达到最大时长后强制切段,避免单段过长。
TTS 播放时,系统会暂停录音,防止播报声音被麦克风重新采集。播放完成后重新打开录音设备,并丢弃前几帧数据,避免设备刚恢复时的异常帧影响 RMS 判断。
可以在启动参数里修改判断逻辑的各个阈值:
python scripts/board_demo_realtime.py \
--device plughw:2,0 \
--start-rms 20 \
--end-rms 8 \
--gain-db 30 \
--pre-roll-sec 0.4 \
--end-silence-sec 0.8 \
--min-sec 2.0 \
--max-sec 10.0 \
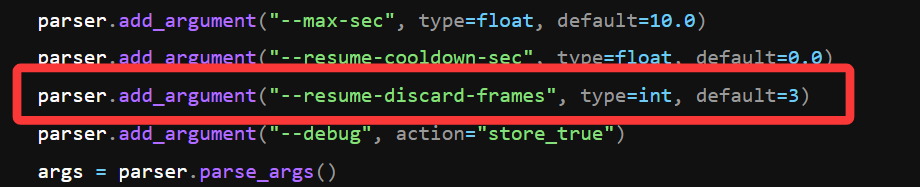
--resume-cooldown-sec 0.0 \
--resume-discard-frames 3
| 参数 | 作用 |
|---|---|
| --device plughw:2,0 | 指定录音声卡设备。 |
| --start-rms 20 | 开始说话阈值,RMS 高于 20 就认为开始录音。 |
| --end-rms 8 | 静音判断阈值,RMS 低于 8 认为当前帧接近静音。 |
| --gain-db 30 | 送入 ASR 前对录音做音量增强,提高识别效果。 |
| --pre-roll-sec 0.4 | 触发录音前保留 0.4 秒缓存,避免切掉句首。 |
| --end-silence-sec 0.8 | 连续静音 0.8 秒后认为一句话结束。 |
| --min-sec 2.0 | 每段录音最短 2 秒,避免太短的噪声段进入识别。 |
| --max-sec 10.0 | 每段录音最长 10 秒,超时强制切段。 |
| --resume-cooldown-sec 0.0 | TTS 播放结束后恢复录音的固定等待时间,目前不额外等待。 |
| --resume-discard-frames 3 | 恢复录音后丢弃前 3 帧,避免刚打开设备时异常帧影响判断。 |
遇到过的问题:
录音播放设备选择、Whisper 效果不稳定后切到 Zipformer、Piper 替换 espeak-ng、播放时暂停录音、播放后尾音误触发、HDMI 屏显示不稳定。
播放时暂停录音
目前播放tts时需要关闭麦克风输入,因为:录音和播放用的是同一个声卡设备 plughw:2,0,播放 TTS 时如果录音还开着,会互相干扰。
况且,如果播放录音时还开着麦克风也会影响到声音的采集导致系统会把自己刚播出的英文又当成新输入,造成误触发
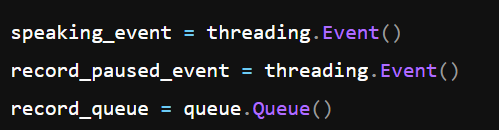
暂停录音靠两个线程事件实现:speaking_event,表示现在要播报了,录音线程应该暂停。record_paused_event,表示录音线程已经确认暂停。
在播放期间录音线程会一直在循环读标志位
播放结束后,先清除标志位,然后录音线程发现标志位为空再打开录音
这样做解决了声卡冲突问题,但也带来了下一个问题:
播放后尾音误触发
在早期版本有一个问题,每一次播放完一段录音后显示rms = 400多然后直接触发下一次录音开始的动作
一开始我以为原因是播放后尾音误触发,系统刚播完自己的 TTS,麦克风/声卡又把这段声音或残响当成了新的用户讲话。于是我在每次播放完语音之后加入一定时延,然后通过事件握手来允许麦克风再打开,但是现象仍然一模一样:播放完成后显示rms=400直接再次触发录音
说明并非音响原因引入的干扰,猜想是这个rms=400很可能是arecord 重新打开 ES8388 录音设备时产生的启动瞬态、驱动毛刺、声卡切换噪声或前几帧异常数据。
验证的方法很简单,直接丢掉每次启动前的前几帧就好
默认丢3帧,按照时间来算是忽略约 300ms 的录音设备启动毛刺.
这带来了新的时间开销,所以要看看模拟端到底怎么回事,如果是简单的启动过冲/毛刺导致,可以对地加一个滤波电容来避免增长业务时间,但是实测发现,不是这么回事
后来才想到rms=400 在 16bit PCM 里其实不算特别大,满量程是 32768。它只是相对我的 start-rms=20 很高,所以足够误触发,但在模拟端可能只是很小的交流扰动,示波器如果看的是咪头 DC 偏置,确实可能看不出来。
另一方面,干扰也可能不在这里,如果示波器看咪头偏置/输出电压一直稳定,而软件里重开录音后仍然出现 rms=400,那这个毛刺大概率不是麦克风本体产生的
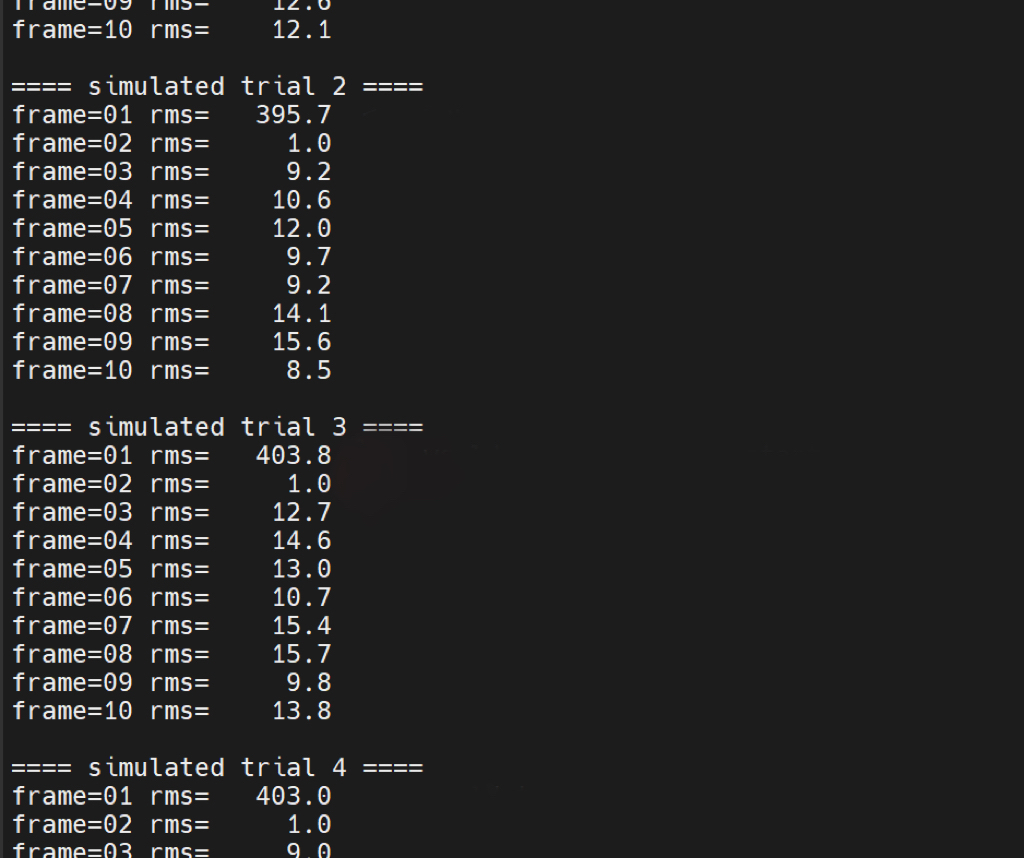
做了一个脚本,不停开关录音和扬声器,发现确实有这个rms不稳的问题,可能是以下原因,这里我没有再多纠结了:
ES8388 codec / ADC ALSA capture 初始化 arecord 刚启动时的前几帧缓冲 驱动刚打开设备时的瞬态数据
不管怎样,说明前几帧采样业务不稳定,我们丢掉前3帧的解决办法总归是生效了 多300ms也不是不可接受
优化方向
1.优化断句策略,这是流畅度最直接的一个关联项。
2.朋友提出过“像本人声音”的方向,
我考虑过自行训练或是 GPT-SoVITS ;这部分会明显比 Piper 复杂,细说的话分为两种:
1)提前准备好目标的大量录音作为训练集得到一个模型然后通过瑞芯微工具转换成RNKK,优点是:足够轻,可以板端离线跑,缺点也很明显:训练所需要的庞大素材收集过程,以及不能实现根据不同用户说话来立刻模仿出不同的声音.
2)GPT-SoVITS :如果只看效果,这是最理想的模型,它是B站上一位up主(花儿不哭大佬orz)组织起来并且在github上与他人共同维护的一个项目[github发布地址GitHub - RVC-Boss/GPT-SoVITS: 1 min voice data can also be used to train a good TTS model! (few shot voice cloning) · GitHub]

它的优点十分夸张:5秒克隆.这就代表我们可以跳过训练的过程,只需要在翻译用户第一句的时间开销中增加若干秒,之后就能得到一个和用户相似的声音,而且声音自然度高,一个比较有信服力的例子就是很多"虚拟主播"他们都采用了这个方案.以及免费. 但是缺点也让我无法接受:
部署重。GPT-SoVITS 依赖多,通常更偏 PC/GPU 环境,直接放到 RK3588S 上离线跑会麻烦很多。
NPU 适配不确定。GPT-SoVITS 这类链路包含文本前端、GPT/语义模型、SoVITS/声码器等部分,动态图和自回归结构比较多,不像 Zipformer 那样有现成 RKNN 路线。
英文输出不一定天然适配。最后播报的是英文,如果只录用户的中文样本,克隆出的英文发音、节奏、口音未必理想。
这个模型如果非要比较理想的效果下使用也不是无法实现:
PC 负责重模型(简单点说就是负责给出wav),RK3588S 继续负责录音、ASR、翻译、UI 和播放。而且pc必须联网来请求GPT-SoVITS API.
考虑到这些缺点,最终没有采用这套方案--它让这个项目系统不再是纯开发板独立运行,不那么"嵌入式"了,必须保证 PC 开机、服务启动、局域网连通。
附录:为什么要将 Zipformer 转换为 RKNN
在本项目中,Zipformer 负责完成中文语音识别,也就是将麦克风录到的中文语音转换成中文文本。原始模型是 ONNX 格式,虽然可以直接使用 ONNX Runtime 在 CPU 上运行,但 RK3588S 开发板本身带有 RKNPU,因此更适合将模型转换为 RKNN 格式,让语音识别部分尽量运行在 NPU 上。
1. 不同平台的模型加速路线
| 平台 | 常见推理路线 | 适用场景 |
|---|---|---|
| Rockchip RK3588S | ONNX -> RKNN -> RKNPU | ARM 开发板、低功耗边缘部署 |
| Intel 平台 | ONNX -> OpenVINO | x86 工控机、边缘网关 |
| NVIDIA 平台 | ONNX -> TensorRT | 独显服务器、高性能实时推理 |
| 通用 CPU | PyTorch / ONNX Runtime | 调试方便,但性能和功耗不占优 |
2. 转换为 RKNN 的原因
第一,RKNN 可以调用 RK3588S 的 NPU。 Zipformer 作为 ASR 模型,是整个系统中计算量较大的部分之一。如果全部放在 CPU 上运行,CPU 既要处理录音分段,又要做翻译、TTS 和 UI,负载会更集中。将 ASR 部分转到 NPU,可以减轻 CPU 压力。
第二,RKNN 更适合板端部署。 ONNX 模型通用性更好,适合在 PC 或虚拟机里调试;但在 RK3588S 这类 Rockchip 平台上,RKNN Runtime 和 RKNNLite 是更贴近硬件的部署方式。模型转换后,板端只需要加载 .rknn 文件即可运行。
第三,可以更好体现 RK3588S 的硬件价值。 将 ONNX 模型转换为 RKNN,并在板端通过 RKNPU 运行,是 RK3588S AI 部署中很关键的一步。
3. 本项目中的转换流程
本项目参考 lxmyzzs 仓库中的 RK3588 Zipformer 示例,先下载 Zipformer 的三个 ONNX 模型:
encoder-epoch-99-avg-1.onnx decoder-epoch-99-avg-1.onnx joiner-epoch-99-avg-1.onnx
然后在 Ubuntu 虚拟机中使用 rknn-toolkit2 2.3.2 将它们转换为 RKNN:
encoder-epoch-99-avg-1.onnx -> encoder-epoch-99-avg-1.rknn decoder-epoch-99-avg-1.onnx -> decoder-epoch-99-avg-1.rknn joiner-epoch-99-avg-1.onnx -> joiner-epoch-99-avg-1.rknn
转换完成后,再将 .rknn 模型复制到 RK3588S 开发板,在板端通过 rknn-toolkit-lite2 和 librknnrt.so 加载运行。
4. 转换后的收益和限制
转换 RKNN 后,Zipformer 的主要推理过程可以交给 RKNPU 执行,CPU 可以更多负责录音控制、文本翻译、TTS 和界面显示。这样系统分工更合理,也更符合 RK3588S 的硬件结构。
不过 RKNN 转换也有一定限制。模型需要满足 RKNN 工具链支持的算子和输入形状要求,转换后还要验证识别结果是否正常。项目中也遇到过 static_shape、动态范围查询等提示,这类信息不一定是致命错误,但需要结合实际推理结果确认。
另外,本项目并不是所有环节都运行在 NPU 上。当前只有 Zipformer ASR 部分使用 RKNN/NPU;Opus-MT 翻译和 Piper TTS 仍然运行在 CPU 上。

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐

 15
15 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)