国产GPU能跑DeepSeek吗?天数智芯天垓150与智铠100怎么选?
一、企业为什么开始重新关注国产GPU
随着DeepSeek、Qwen等开源大模型快速发展,越来越多企业开始建设自己的AI能力,包括知识库问答、智能客服、Agent平台、多模态分析等应用。相比调用公有云API,私有化部署在数据安全、合规管理和长期成本控制方面具备明显优势。
与此同时,企业对AI基础设施的关注点也发生了变化。过去行业讨论更多是训练能力,而如今大量算力消耗发生在推理侧。企业更关心的是:
- 模型能否稳定运行
- 推理成本是否可控
- 部署是否灵活
- 供应链是否稳定
因此,企业真正需要的已经不是单纯的高算力,而是能够长期支撑业务运行的AI基础设施。在这样的背景下,天数智芯的天垓150与智铠100开始进入越来越多企业的技术选型范围。

二、天数智芯在国产GPU中的定位
目前国产GPU厂商众多,但路线差异明显。天数智芯是国内较早坚持通用GPU路线的厂商之一,其自研ivcore11架构采用7nm工艺,在编程模型上与CUDA保持较高兼容性,能够降低迁移门槛。
产品主要分为两条路线:
|
产品系列 |
主要定位 |
|
天垓系列 |
训练、微调、高性能推理 |
|
智铠系列 |
推理、视频AI、边缘计算 |
简单理解:
- 天垓150更接近训练平台定位
- 智铠100更偏向企业推理部署
两者解决的是不同阶段的AI算力需求。

三、智铠100:企业推理场景的核心选择
智铠100最大的特点不是峰值算力,而是围绕推理场景进行了针对性优化。
相比训练任务,推理更关注:
- INT8计算能力
- 并发处理能力
- 视频解码能力
- 功耗控制能力
智铠100最高提供384TOPS INT8算力、96TFLOPS FP16算力以及32GB HBM2e显存,同时支持128路1080P视频解码。
对于企业来说,其价值主要体现在:
- DeepSeek、Qwen等模型推理部署
- 企业知识库与RAG应用
- Agent平台
- 视频AI分析
- 边缘推理场景
从模型规模来看,32GB显存基本能够覆盖7B至14B级模型推理需求。
一句话总结:智铠100更适合企业推理、视频AI和边缘部署场景。

四、天垓150:训练、微调与高性能推理平台
如果说智铠100解决的是“如何高效运行模型”,那么天垓150解决的是“如何训练和优化模型”。
天垓150采用64GB HBM2e显存设计,支持FP32、FP16、BF16、INT8等多种精度计算,定位于训练、微调及高性能推理场景。
相比32GB级产品,64GB显存能够支持:
- 32B及以上模型部署
- LoRA微调
- 多模态训练
- 长上下文推理
- 多用户并发推理
公开资料显示,天垓150已完成千卡级集群验证,在大规模训练和集群部署方面具备较成熟的工程能力。
一句话总结:天垓150更适合大模型部署、LoRA微调、高性能推理及训练场景。

五、企业应该选择智铠100还是天垓150?
目前智铠100系列主要包括MR-V100和MR-V100 DUO两种形态。
其中MR-V100定位于标准企业推理场景,适合知识库问答、Agent应用及中小规模模型部署;MR-V100 DUO则通过双GPU集成设计提供更高的推理密度和并发能力,更适合高并发推理服务、视频AI以及空间受限的数据中心部署。
|
版本 |
INT8 |
FP16 |
FP32 |
显存 |
带宽 |
功耗 |
|
MR-V100 |
384 TOPS |
96 TFLOPS |
24 TFLOPS |
32GB HBM2e |
800 GB/s |
150W |
|
MR-V100 DUO |
600 TOPS |
192 TFLOPS |
45 TFLOPS |
64GB HBM2e |
1.6 TB/s |
300W |
|
BI-V150 |
384 TOPS |
192 TFLOPS |
48 TFLOPS |
64 GB HBM2e |
1.6 TB/s |
350W |
需要注意的是,MR-V100 DUO虽然在INT8算力和显存容量上接近甚至超过部分训练GPU,但其产品定位仍然以推理加速为主,而非训练平台。因此企业在选型时不应仅比较算力参数,更应结合训练、微调和推理等实际业务需求综合评估。
对于企业而言,选型核心仍然取决于业务目标。
|
业务场景 |
MR-V100 |
MR-V100 DUO |
BI-V150 |
|
企业知识库 |
★★★★★ |
★★★★★ |
★★★★ |
|
Agent平台 |
★★★★★ |
★★★★★ |
★★★★ |
|
视频AI |
★★★★ |
★★★★★ |
★★★ |
|
32B推理 |
★★★ |
★★★★★ |
★★★★★ |
|
LoRA微调 |
★ |
★★ |
★★★★★ |
|
全量训练 |
☆ |
☆ |
★★★★★ |
|
集群训练 |
☆ |
☆ |
★★★★★ |
企业选型建议
如果你的目标是:
✅ 部署企业知识库、智能客服、Agent应用
→ 优先选择 MR-V100
✅ 部署DeepSeek/Qwen生产环境、高并发推理服务
→ 优先选择 MR-V100 DUO
✅ 进行模型微调、训练或规划未来AI集群建设
→ 优先选择 BI-V150
在实际项目中,我们发现企业选型往往不是简单比较GPU参数,而是需要结合模型规模、并发需求、未来扩展规划以及整体预算综合评估。昊源诺信已基于MR-V100、MR-V100 DUO及BI-V150完成多种国产AI服务器方案验证,可根据不同业务场景提供从单机部署到集群建设的整体AI基础设施方案。

六、企业部署国产GPU,难点往往不在GPU本身
很多企业第一次部署国产GPU时,容易把关注点全部放在芯片参数上。
但实际项目中,影响最终效果的往往是:
- 网络架构
- 存储性能
- 驱动适配
- 推理框架优化
- 模型量化策略
例如同样部署vLLM,不同GPU平台在KV Cache管理、显存调度和量化路径上都存在差异。
因此企业真正采购的并不是一张GPU,而是一整套AI基础设施能力。
特别是在天垓150这类训练场景中,高速网络、NVMe存储和服务器散热设计的重要性甚至不亚于GPU本身。

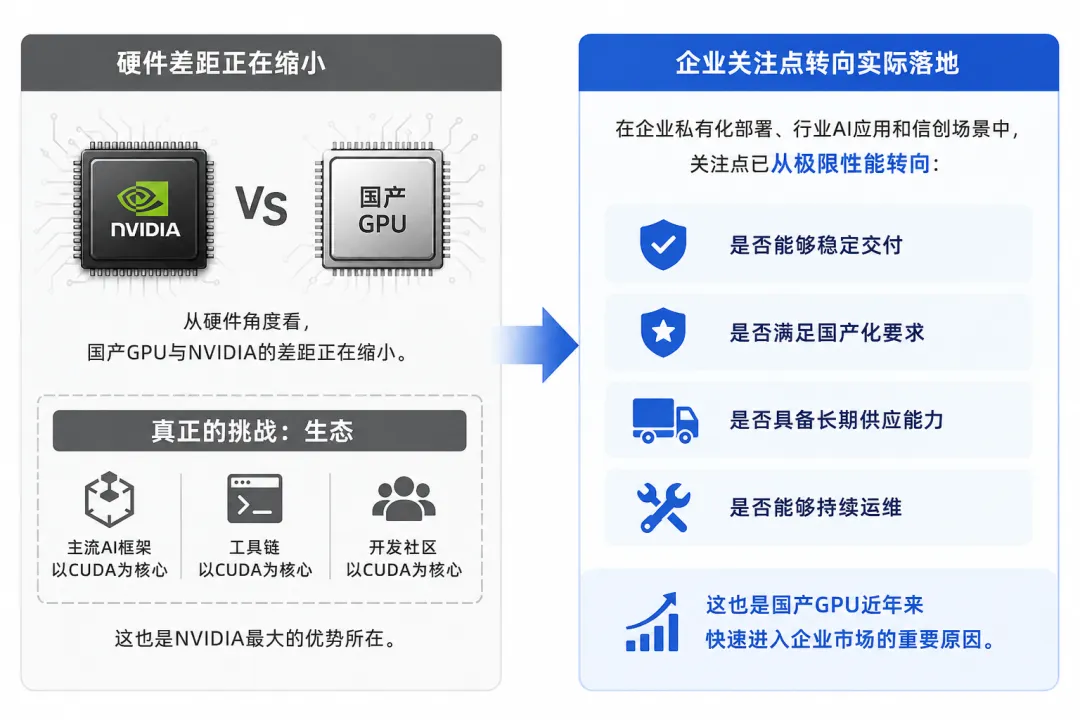
七、国产GPU与NVIDIA的差距在哪里
从硬件角度看,国产GPU与NVIDIA的差距正在缩小。
但真正的挑战仍然来自生态。
目前主流AI框架、工具链和开发社区仍以CUDA生态为核心,这也是NVIDIA最大的优势所在。
不过对于企业私有化部署、行业AI应用和信创场景来说,关注点已经从极限性能转向:
- 是否能够稳定交付
- 是否满足国产化要求
- 是否具备长期供应能力
- 是否能够持续运维
这也是国产GPU近年来快速进入企业市场的重要原因。
八、FAQ:企业最关心的几个问题
Q1:智铠100能部署DeepSeek和Qwen吗?
可以。智铠100已完成主流国产大模型适配,适合7B~14B级模型推理及企业知识库场景。
Q2:天垓150适合训练还是推理?
两者都可以,但更适合训练、LoRA微调以及32B以上模型的高性能推理场景。
Q3:企业知识库应该选择智铠100还是天垓150?
以知识库问答、RAG应用为主,优先选择智铠100;如需模型微调或未来扩展训练能力,可考虑天垓150。
Q4:国产GPU可以替代NVIDIA吗?
取决于场景。在企业推理、行业AI和信创场景中已具备较强竞争力,但超大规模训练生态仍有差距。
Q5:企业首次部署国产GPU应该重点验证什么?
建议优先验证模型兼容性、推理性能、驱动稳定性和运维复杂度,而不是只关注理论参数。
Q6:企业采购GPU时最应该关注什么?
不要只看算力参数,更要关注模型适配能力、整体方案成熟度、运维成本和长期供应能力。
赋创:企业需要完整的AI基础设施
大模型正在从训练竞争走向规模化部署阶段。
未来企业更关注的是:推理成本、运维效率、国产化合规、长期供应稳定性。
从目前的发展情况来看,天垓150与智铠100已经能够覆盖企业训练、微调和推理部署的大部分需求。
对于企业而言,国产GPU选型只是AI建设的第一步。从模型部署到正式上线,往往还涉及服务器架构设计、存储规划、网络互联、推理优化以及运维管理等多个环节。


Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐
 8
8 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)