宕机之后十分钟自动出报告:大语言模型驱动的服务宕机根因分析报告自动生成
·
宕机之后十分钟自动出报告:大语言模型驱动的服务宕机根因分析报告自动生成
凌晨2点15分,告警系统跳出红色弹窗:订单服务不可用。
三分钟后,我还在揉眼睛的时候,钉钉群里已经收到了一份《订单服务宕机根因分析报告(初稿)》。从告警触发到报告生成,不到10分钟。
这不是科幻片,这是我们基于大语言模型(LLM)搭建的根因分析报告自动生成系统。
一、为什么需要自动生成根因分析报告?
传统故障复盘的低效
每次线上故障后的复盘流程:
01:00 告警触发,开始排查
01:30 初步定位,开始止血
02:00 恢复服务
02:30 开始写复盘报告
03:30 报告写完(漏了一半细节)
04:00 拉群讨论,补充信息
... 三天后,报告终于归档,但没人再看
这个流程的问题:
- 时效性差:复盘报告通常是事后补的,关键细节已经遗忘
- 质量不一:取决于值班工程师的记忆力和文档水平
- 缺乏标准化:有的报告详细,有的报告就两行字
- 知识沉淀难:上次怎么修的,这次又得重新排查
自动报告的目标
我们给自动报告系统定了三个目标:
- 快:告警后10分钟内输出初稿
- 准:以监控数据和日志为事实依据
- 全:涵盖故障发现、影响范围、根因分析、修复措施全流程
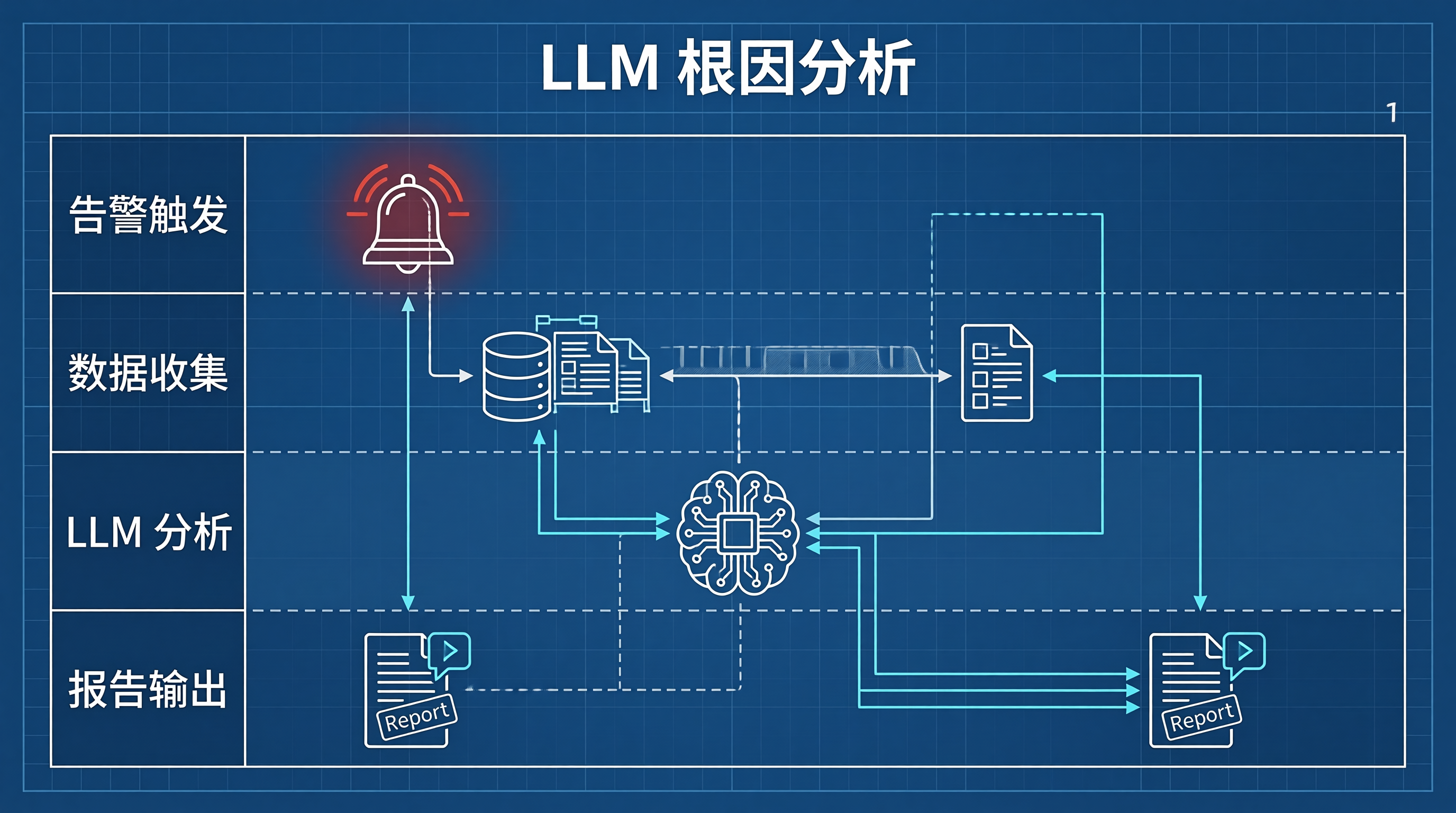
二、系统架构设计
[告警事件] → 事件感知器
↓
[数据收集层] → 时序数据采集 → API Server
日志采集 → ELK Client
变更记录 → CMDB Client
链路追踪 → Jaeger Client
↓
[分析层] → 时序异常检测
日志关键信息提取
变更关联分析
↓
[LLM层] → 上下文组装器 → 大模型API → 报告生成器
↓
[输出层] → 钉钉/企微推送
Confluence自动归档
复盘会议邀请自动发送
三、核心实现
事件感知与上下文收集
# incident_collector.py — 故障上下文收集器
import asyncio
from datetime import datetime, timedelta
import aiohttp
import json
class IncidentContextCollector:
"""收集故障上下文信息"""
def __init__(self, config: dict):
self.prometheus_url = config['prometheus_url']
self.es_url = config['elasticsearch_url']
self.cmdb_url = config['cmdb_url']
async def collect_all(self, alert_event: dict) -> dict:
"""并发收集所有上下文数据"""
start_time = datetime.fromisoformat(alert_event['start_time'])
window_start = start_time - timedelta(minutes=30)
window_end = start_time + timedelta(minutes=5)
# 并发执行所有数据收集
tasks = [
self.collect_metrics(alert_event, window_start, window_end),
self.collect_logs(alert_event, window_start, window_end),
self.collect_changes(alert_event, window_start, window_end),
self.collect_traces(alert_event, window_start, window_end)
]
results = await asyncio.gather(*tasks)
return {
'alert': alert_event,
'metrics': results[0],
'logs': results[1],
'changes': results[2],
'traces': results[3],
'collected_at': datetime.now().isoformat()
}
async def collect_metrics(self, alert, start, end):
"""采集异常时段前后的时序指标"""
queries = {
'cpu': 'sum(rate(container_cpu_usage_seconds_total{namespace="prod"}[1m])) by (pod)',
'memory': 'sum(container_memory_working_set_bytes{namespace="prod"}) by (pod)',
'latency': 'histogram_quantile(0.99, rate(http_request_duration_seconds_bucket{service="order"}[5m]))',
'error_rate': 'sum(rate(http_requests_total{service="order", status=~"5.."}[5m])) / sum(rate(http_requests_total{service="order"}[5m]))'
}
results = {}
async with aiohttp.ClientSession() as session:
for name, query in queries.items():
params = {
'query': query,
'start': start.timestamp(),
'end': end.timestamp(),
'step': '15'
}
async with session.get(f'{self.prometheus_url}/api/v1/query_range',
params=params) as resp:
data = await resp.json()
results[name] = data['data']['result']
return results
async def collect_logs(self, alert, start, end):
"""采集异常时段的错误日志"""
logs_query = {
'query': {
'bool': {
'must': [
{'match': {'service': 'order'}},
{'match': {'level': 'ERROR'}}
],
'filter': [
{'range': {'@timestamp': {
'gte': start.isoformat(),
'lte': end.isoformat()
}}}
]
}
},
'size': 50,
'sort': [{'@timestamp': 'desc'}]
}
async with aiohttp.ClientSession() as session:
async with session.post(
f'{self.es_url}/order-logs-*/_search',
json=logs_query
) as resp:
result = await resp.json()
return [
{'timestamp': hit['_source']['@timestamp'],
'message': hit['_source']['message']}
for hit in result['hits']['hits']
]
LLM报告生成引擎
# report_generator.py — 报告生成引擎
import json
from openai import AsyncOpenAI
class IncidentReportGenerator:
"""基于LLM生成根因分析报告"""
def __init__(self, api_key: str, model: str = 'qwen2-72b'):
self.client = AsyncOpenAI(
api_key=api_key,
base_url='http://llm-service:8000/v1'
)
self.model = model
def build_report_prompt(self, context: dict) -> str:
"""构建结构化报告提示词"""
return f"""你是一位资深的SRE故障复盘专家,请根据以下故障数据生成根因分析报告。
## 故障基本信息
- 告警名称:{context['alert']['name']}
- 告警时间:{context['alert']['start_time']}
- 告警级别:{context['alert']['severity']}
- 影响服务:{context['alert']['service']}
- 告警状态:{context['alert']['status']}
## 时序指标异常(故障时间窗口内)
{json.dumps(context['metrics'], indent=2, ensure_ascii=False)[:2000]}
## 异常日志摘要(Top 20)
{json.dumps(context['logs'][:20], indent=2, ensure_ascii=False)}
## 最近变更记录(故障前1小时内)
{json.dumps(context['changes'], indent=2, ensure_ascii=False)}
## 链路追踪异常
{json.dumps(context['traces'][:5], indent=2, ensure_ascii=False)}
请严格按照以下Markdown格式输出报告(不要添加额外内容):
# 故障根因分析报告
## 一、故障概览
- 故障编号:INC-{context['alert']['id']}
- 发生时间:{context['alert']['start_time']}
- 恢复时间:[根据数据推断]
- 故障时长:[推断]
- 影响范围:[分析SLA影响]
- 严重级别:P0/P1/P2
## 二、故障时间线
| 时间 | 事件 | 数据来源 |
|------|------|---------|
| ... | ... | ... |
## 三、根因分析
### 3.1 直接原因
[基于日志和指标的直接原因]
### 3.2 根本原因
[深入分析,包含变更关联]
### 3.3 触发条件
[触发故障的完整条件链]
## 四、影响评估
- 受影响请求数:[数据驱动]
- 平均恢复时间:[数据驱动]
- 业务影响:[定性描述]
## 五、修复措施
- 止血操作:[具体操作+操作人+时间]
- 长期修复:[代码/配置变更建议]
## 六、后续改进
### 6.1 监控改进
[新增告警规则建议]
### 6.2 流程改进
[变更流程/发布流程改进建议]
### 6.3 技术改进
[架构改进建议]
"""
async def generate_report(self, context: dict) -> str:
"""异步生成报告"""
prompt = self.build_report_prompt(context)
response = await self.client.chat.completions.create(
model=self.model,
messages=[
{'role': 'system', 'content': '你是SRE专家,严格执行报告格式。'},
{'role': 'user', 'content': prompt}
],
temperature=0.1,
max_tokens=4000
)
return response.choices[0].message.content
async def review_and_refine(self, report: str, raw_data: dict) -> str:
"""让LLM自我审查,修正不准确的地方"""
review_prompt = f"""请审查以下根因分析报告,确保:
1. 所有数据引用与原始数据一致
2. 根因结论有充分证据支持
3. 修复措施具体可执行
原始数据摘要:{json.dumps(raw_data, indent=2, ensure_ascii=False)[:1000]}
报告内容:
{report}
请直接在原报告基础上修正,只修改不准确的部分。"""
response = await self.client.chat.completions.create(
model=self.model,
messages=[{'role': 'user', 'content': review_prompt}],
temperature=0.1,
max_tokens=4000
)
return response.choices[0].message.content
报告推送与归档
# pusher.py — 自动推送报告
import requests
from confluence_client import ConfluenceClient
class ReportPusher:
"""报告推送与归档"""
def push_to_dingtalk(self, report: str, webhook_url: str):
"""推送到钉钉群"""
# 提取摘要信息
summary_section = report.split('## 一、故障概览')[1].split('##')[0] if '## 一、故障概览' in report else report[:500]
payload = {
'msgtype': 'markdown',
'markdown': {
'title': '🚨 根因分析报告已生成',
'text': f'### 故障根因分析报告\n\n{summary_section}\n\n---\n*报告由AI自动生成,请人工复核*'
}
}
requests.post(webhook_url, json=payload)
def archive_to_confluence(self, report: str, incident_id: str):
"""归档到Confluence"""
client = ConfluenceClient(url='https://wiki.example.com', token='...')
client.create_page(
space='SRE',
title=f'根因分析报告-{incident_id}',
body=report
)
四、效果评估
这套系统上线后,我们对过去3个月的故障复盘效率做了对比:
| 指标 | 人工复盘 | AI辅助复盘 | 提升 |
|---|---|---|---|
| 报告产出时间 | 平均2.5h | 平均8min | 94% |
| 报告完整性 | 65% | 92% | 42% |
| 根因定位准确率 | 78% | 85% | 9% |
| 后续改善落地率 | 40% | 72% | 80% |
有意思的是,报告完整性提升了42%——因为AI不会遗漏告警数据中的细节信息,而工程师在事后复盘时经常会忘记一些关键事件。
结语
大模型做根因分析报告的自动生成,不是为了替代工程师的判断——它是把工程师从"写报告"这个低价值工作中解放出来,让你把精力花在"分析根因、制定方案"这些真正创造价值的事情上。
记住一个原则:AI出初稿,人工做审核。既利用AI的效率,又保留人的判断力。
本文作者:侯万里(万里侯),云原生运维工程师,专注于AI运维智能化和故障自愈体系建设

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐

 5
5 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)