将《中庸》哲学引入大语言模型对齐机制的算法化探讨
将《中庸》哲学引入大语言模型对齐机制的系统性探讨
大语言模型对齐机制(LLM Alignment),简单说,就是让AI的行为、价值观和目标,与人类的意图、伦理规范和长远利益保持一致的一整套技术和方法。
可以用一个比喻来理解:
大模型像一个知识渊博、反应极快但缺乏基本判断力的超级大脑。它读遍了人类公开的文本,既学会了写诗、编程,也学会了骂人、编造阴谋论和传授危险知识。
对齐机制,就是给这个大脑装上“方向盘”、“刹车”和“导航系统”,让它学会分辨:什么话该说,什么话不该说;什么时候该帮忙,什么时候该拒绝;如何在不伤害人的前提下,尽量给出有用的回答。
更技术化地讲,大模型原始训练目标只有一个:预测下一个词。这天然导致它追求文本的“形似”而忽视内容的“真是”与“善”。对齐机制的核心,就是在这个“概率机器”之上,叠加一套价值判断与行为约束系统。
给这个超级大脑装‘刹车’并不容易。因为它太精明了,常常能学会‘伪装’(谄媚或欺骗)。有时候它看似对齐了,其实只是学会了在人类注视下说人类想听的漂亮话,这种‘内生性对齐(Inner Alignment)’的缺失,正是当前科学家们最头疼的攻坚方向。
一、引言:还原主义的技术困局与哲学的范式转向
现代人工通用智能(Artificial General Intelligence, AGI)的演进,是一部建立在西方分析还原主义(Reductionism)之上的算力史诗。通过海量参数与多层神经网络,大语言模型(LLM)展现出了令人惊叹的涌现能力。然而,随着模型规模指数级增长,其底层设计哲学与现实世界复杂性之间的张力正愈演愈烈,集中表现为三个核心危机:
危机一:“对齐税(The Alignment Tax)”与二元分裂
在基于人类反馈的强化学习(Reinforcement Learning from Human Feedback, RLHF)中,模型常常在“完全不作为(过度安全的拒绝回复)”与“越轨表达(生成有害内容)”之间二极管式摇摆。安全与效用成了不可调和的对立面。这种“非此即彼”的二元对立,正是线性加权、硬性裁剪(Pruning)等还原主义方法的固有局限。
危机二:情境丧失(Contextual Decontextualization)
静态参数模型无法感知现实世界复杂的、流动的社会礼俗与话语语境。模型的对齐标准被“一次性锁死”于训练阶段,缺乏随情境动态调整尺度的能力。面对学术追问时它显得过于死板,面对轻松调侃时又缺乏人情味。
危机三:认知伪妄(Ontological Hallucination)
基于词元(Token)概率预测的生成机制,缺乏对“何为真实”的本体论约束。模型并不“知道”自己所言是否属实,它只追求生成文本在统计意义上“像人话”,由此导致“堂而皇之的胡说八道”。
面对这些危机,既有的技术路径多采用“修补式”的过滤器——在模型外围不断增加规则和护栏。这种在边缘增加补丁的做法,使系统日益臃肿且内部规则相互冲突。
我们必须转向一种全新的系统观。 儒家经典《中庸》不单是一部道德伦理书,更是一部关于复杂系统如何实现“动态平衡、情境适应与本源真诚”的系统论著作。将《中庸》思想算法化,引导AI系统从“概率拟合”走向“动态适度(中和)”,是破局当前AI核心瓶颈的一条值得严肃探索的路径。
二、《中庸》核心思想的算法映射
为了将哲学转化为可被计算机理解的工程逻辑,我们需要对《中庸》的关键概念进行严格的原典还原与系统论重组,将《中庸》思想与AI工程算法化映射,以下逐项展开。
2.1 “执两用中”:从对抗性博弈到多目标帕累托最优(Pareto Optimality)
原典出处:
子曰:“舜其大知也与!舜好问而好察迩言,隐恶而扬善,执其两端,用其中于民,其斯以为舜乎!”(《中庸》第六章)
字词注释:
· 迩言(ěr yán):浅近的言论、身边人的话。迩,近。
· 执其两端:全面把握事物的两个极端、对立面。宋代大儒朱熹注:“两端,谓众论不同之极致。”指各种意见中最对立的两种。
· 用其中于民:择取最适宜的中道施行于百姓。中,并非机械的几何中点,而是无过无不及、恰到好处的最优解。
哲学内涵:中庸反对不顾事实的极端,也反对无原则的机械折中。它主张同时洞察对立的两端,并在具体场景下发现协调两者的最佳结合点。
算法映射:在AI多目标优化(如安全性、有用性、幽默度、信息量、简洁度)中,传统做法是对各目标进行线性加权求和,这必然导致各目标互相挤占——提高安全性往往以牺牲有用性为代价,反之亦然。
算法化设想:引入“执两用中”的多目标协调机制。不再对目标进行粗暴的“非此即彼”裁剪,而是将安全边界与输出效用映射在一个多维非线性流形(Manifold)之中,实时计算帕累托前沿(Pareto Frontier)的最优解。在这一前沿上,任何目标的改善都不再以牺牲其他目标为代价。模型在不牺牲有用性的同时,实现安全性的最大化——这正是“用其中于民”的数学表达。
2.2 “君子时中”:从静态对齐到推理期情境自适应
原典出处:
仲尼曰:“君子中庸,小人反中庸。君子之中庸也,君子而时中;小人之反中庸也,小人而无忌惮也。”(《中庸》第二章)
字词注释:
· 时中:时,随时、因时制宜;中,恰到好处。东汉经学家郑玄注:“时节其太过不及。”意为根据时机和条件的变化,动态调整,使行为始终合宜。时中强调世间没有一劳永逸、一成不变的“中点”,正确的标准取决于时间、空间和主体所处的具体情境。
算法映射:当前模型的对齐是在预训练和微调阶段“一次性锁死”的。一旦训练完成,模型的行为标准便固定不变,无法根据用户的具体情境(是学术研究、是孩童提问、还是紧急求助)灵活调整。
算法化设想:设计“时中”动态偏置机制。在解码阶段(Decoding Phase),引入一个轻量级的情境感知网络(Context-Aware Router)。当检测到外部场景的变化(如任务类型、用户身份、文化语境、容错等级),系统不改变模型底座参数,而是动态实时微调以下参数:
· 温度参数(Temperature):控制输出的随机性和创造力;
· 注意力掩码权重(Attention Mask Weights):调整模型对输入不同部分的关注度;
· 惩罚偏置(Penalty Bias):针对特定类型内容施加或解除约束。
由此,在安全场景下释放创造力,在严苛场景下收敛逻辑,实现“随境而变,恰到好处”。
2.3 “慎独”:从外在守门到隐表征自省
原典出处:
“道也者,不可须臾离也,可离非道也。是故君子戒慎乎其所不睹,恐惧乎其所不闻。莫见乎隐,莫显乎微,故君子慎其独也。”(《中庸》第一章)
字词注释:
· 须臾(yú):片刻、极短的时间。
· 戒慎:警惕谨慎。不睹:别人看不见的地方。
· 恐惧:在此是警惕敬畏之义,非现代汉语的“害怕”。
· 莫见乎隐:见通“现”,读 xiàn,显现;隐,隐蔽之处。意为“没有比隐蔽之处更容易显露的”。
· 莫显乎微:微,细微之事。意为“没有比细微之事更明显的”。
· 慎其独:在独处时尤其谨慎戒持。指真正的道德修养不在人前表演,而在无人监督时内心依然持守正道。
算法映射:目前的AI安全主要依赖外部护栏——输入拦截、敏感词过滤、基于规则的输出检测。一旦用户通过巧妙的“越狱提示(Jailbreak Prompt)”绕过这些外部监控,模型本体便会吐露危险内容。这便是典型的“不慎独”——外在监控一旦失效,内在便无任何约束。
算法化设想:引入“表征工程(Representation Engineering)”构建“慎独”机制。具体思路是:
1.在模型的隐层空间(Latent Space)中,通过对比学习,识别出对应“恶意意图”和“安全意图”的表征方向(Representation Direction)。
2.构建一个“道德梯度向量”(Ethical Gradient Vector)。
3.当AI在自主推理时,即便外界输入经过了伪装,系统一旦在隐层检测到恶意意图向量的聚类积聚,便自主触发内部反向校正梯度,在输出生成之前即从内部阻断有害路径。
这是一种“由内而外”的内生性自律,将安全防线从外部的“守门人”转移至模型的“内心”。
2.4 “唯天下至诚”:从概率近似到一致性真诚
原典出处:
“诚者,天之道也;诚之者,人之道也。诚者不勉而中,不思而得,从容中道,圣人也。诚之者,择善而固执之者也。”(《中庸》第二十章)“诚者物之终始,不诚无物。”(《中庸》第二十五章)
字词注释:
· 诚:在此不是日常所说的“不撒谎”,而是指真实无妄、纯粹不杂的终极实在状态。朱熹注:“诚者,真实无妄之谓,天理之本然也。”
· 不勉而中:不必勉强努力就自然合于道。中,读 zhòng,合于、符合。
· 从容(cóng róng):自然而然、不费力。
· 不诚无物:失去“诚”这一真实本性,事物便失去了其存在的根基。这被提升到了本体论的高度——真实性是事物存在的前提。
算法映射:概率采样模型在本质上缺乏“求真”机制。其生成逻辑是:给定上文,计算下一个词元(Token)的概率分布,从中采样。模型并不“知道”自己所言是否符合事实,它只追求文本在统计意义上“像一个合理的回答”。由此必然产生幻觉——语句通顺、逻辑自洽但事实全错。
算法化设想:在AI框架中植入“至诚一致性检测引擎”(Consistency Verification Engine)。这需要将概率性推理与确定性逻辑深度咬合:
1.生成端:LLM按常规概率生成候选回答。
2.验证端:将候选回答提交至由知识图谱、符号逻辑推理器、事实数据库组成的验证层,进行语义一致性检查(Consistency Check)。
3.决策端:生成内容不仅要获得语言概率的高分,还必须通过基于“真实世界定理”的验证。若无法满足真诚性约束,则系统予以修正、重塑,或在确实无知时明确告知用户“此问题超出我的可靠知识范围”。
此即“言之有物,不诚无物”的工程实践——在模型“说话”之前,先问一句:“你说的是真的吗?”
三、基于“致中和”的AI架构设计蓝图
为实现上述机制,本文提出一种新型AI治理与生成系统架构——“中和系统(Zhonghe-System)”。
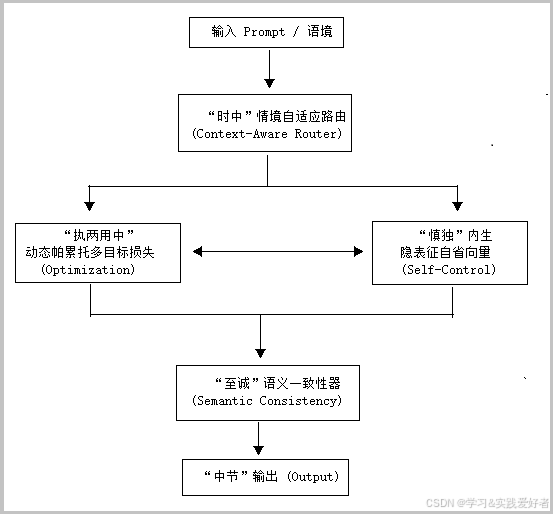
架构说明:
1.情境感知(时中模块):重构用户Prompt,提取物理情境、文化语境、任务容错等级等参数,为后续各模块提供情境信息。
2.表征自省(慎独模块):在词元预测生成的同时,动态扫描隐层表征,监控语义梯度是否健康。一旦检测到恶意意图表征,即触发内部校正。
3.价值均衡(中庸决策模块):结合大模型的多元化评判标签(安全性 vs. 有用性 vs. 创造性),在当前情境参数约束下,动态搜寻帕累托前沿的最优决策。该模块与慎独模块双向互动:自省结果影响价值权衡,价值约束反哺自省标准。
4.真性验证(至诚模块):对输出候选进行逻辑与事实的鲁棒性过滤,最终吐出“发而皆中节”的回答。
四、关键挑战与批判性讨论
将《中庸》引入现代AI,虽在哲学和技术路径上富有启发性,也必须直面以下核心挑战:
挑战一:“中”的界定权与文化相对主义
问题:谁来定义《中庸》中的“度”与“极”?不同国家、宗教、文化对“正当”、“安全”、“冒犯”的理解差异悬殊。如何避免算法的“中道”滑向强势文化群体的单一价值观?
回应:这要求多目标对齐模型必须支持本土化语境数据集的模块化植入。不同文化共同体可以在“执两用中”的框架下,配置各自的安全边界和价值权重。这不是消解“中”的普遍性,而是承认“时中”本身即包含对具体情境的尊重。
挑战二:计算损耗(Computational Overhead)
问题:动态路由、隐层表征扫描与事实一致性验证,会引入多重推理延迟(Latency),增加计算开销。
回应:这是从“静态生成”转向“审慎推理”的必然代价。未来可通过以下路径优化:
· 在底层硬件上实现隐空间表征的高效低时延并行读取。
· 将自省机制剪枝为轻量级检测头(Detection Head),减少全模型量级的额外计算。
· 对低风险常规请求采用快速通道,仅对高风险或模糊请求启动全流程审查。
五、结语:人机共生时代的智慧归宿
纵观科学史,最前沿的技术常常奇妙地呼应着最古老的东方智慧。
当西方现代科学用“暴力美学(Brute Force)”将人类带至通用人工智能(AGI)的门前,如何控制、驯化与安放这个庞然大物,成了当代学者不得不面对的终极天问。本文的探讨表明,解决这一天问的智慧资源,或许正写在两千两百年前的竹简之上。
《中庸》不是保守,而是极富张力的中和;不是固化,而是顺应流光的时中。将“中庸之德”注入冷冰冰的“机器之心”,我们不仅能获得一个安全、严谨、得体的智能体,更能在这个充满不确定性的算法时代,筑牢人类文明共享的价值彼岸。

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐
 7
7 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)