Java 程序员第 41 阶段04:企业智能问答机器人落地,搭建内部智能客服系统,FAQ问答与精确检索
1 概述
FAQ(Frequently Asked Questions)问答系统是企业智能客服的核心组件之一,主要解决用户常见问题的自动问答。与多轮对话不同,FAQ问答通常是单轮匹配过程:用户输入问题,系统从知识库中匹配最相似的问答对并返回答案。本篇文章详细介绍FAQ知识库设计、语义匹配模型选型、关键词精确匹配、答案置信度与排序策略,以及未知问题处理与转人工机制。
2 FAQ知识库设计
2.1 问答对构建原则
高质量的FAQ知识库是问答系统效果的基础。问答对应满足以下原则:
**问题覆盖度**:覆盖用户常见问题,考虑不同表达方式
**答案准确性**:答案内容准确、完整、易懂
**结构规范性**:统一格式,便于管理和检索
@Data
@Entity
@Table(name = "faq_knowledge_base")
public class FaqPair {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Column(nullable = false)
private String question; // 标准问题
@Column(nullable = false, length = 2000)
private String answer; // 标准答案
@Column
private String category; // 分类: 售后/订单/产品
@Column
private Integer priority; // 优先级
@Column
private String synonyms; // 同义问题(JSON数组)
@Column
private String keywords; // 关键词(JSON数组)
@Column
private String state; // 状态: active/inactive
@Column
private LocalDateTime createTime;
@Column
private LocalDateTime updateTime;
}
2.2 同义问题扩展
同一意图的问题往往有多种表达方式,系统应支持同义问题映射:
{
"标准问题": "如何申请退货",
"同义问题": [
"怎么退货",
"退货流程是什么",
"我想退货怎么办",
"退货怎么操作"
],
"关键词": ["退货", "申请", "流程", "操作"]
}
2.3 知识库管理界面设计
企业级FAQ系统需要完善的后台管理功能:
|
功能模块 |
描述 |
|
FAQ增删改查 |
标准问题、答案、同义词的CRUD操作 |
|
分类管理 |
FAQ分类的创建、修改、排序 |
|
批量导入 |
支持Excel/CSV批量导入问答对 |
|
状态管理 |
FAQ上下线、有效期设置 |
|
效果统计 |
点击率、满意度、匹配率统计 |
3.1 SimBERT模型

SimBERT是追一科技开源的语义相似度模型,基于BERT联合训练句子的语义表示和相似度判别任务。
**模型特点**:
- 中文优化,适合中文FAQ匹配
- 支持相似句子生成
- 预训练+微调范式
@Service
public class SimBertMatcher {
@Autowired
private SimBertModel simBertModel;
public double computeSimilarity(String text1, String text2) {
// 编码
Vector vec1 = simBertModel.encode(text1);
Vector vec2 = simBertModel.encode(text2);
// 余弦相似度
return cosineSimilarity(vec1, vec2);
}
public List<CandidateResult> matchTopK(String query, List<String> candidates, int k) {
Vector queryVec = simBertModel.encode(query);
return candidates.stream()
.map(candidate -> {
Vector candidateVec = simBertModel.encode(candidate);
double score = cosineSimilarity(queryVec, candidateVec);
return new CandidateResult(candidate, score);
})
.sorted(Comparator.comparingDouble(CandidateResult::getScore).reversed())
.limit(k)
.collect(Collectors.toList());
}
}
3.2 Sentence-BERT模型
Sentence-BERT(SBERT)是BERT的衍生模型,专门优化了句子级别的语义表示,支持高效的向量检索。
**模型选择建议**:
3.3 向量数据库选型
大规模FAQ检索需要向量数据库支持:
@Service
public class FaissVectorStore {
private IndexFlatIP index; // 内积索引(支持余弦相似度)
public void buildIndex(List<FaqPair> faqPairs) {
// 1. 编码所有问题
List<Vector> vectors = faqPairs.stream()
.map(faq -> simBertModel.encode(faq.getQuestion()))
.collect(Collectors.toList());
// 2. 构建FAISS索引
index = new IndexFlatIP(vectors.get(0).dimension());
for (Vector vec : vectors) {
index.add(vec);
}
}
public List<Long> search(Vector queryVec, int k) {
return index.search(queryVec, k);
}
}
4.1 Elasticsearch配置
Elasticsearch提供强大的关键词匹配能力,支持fuzzy匹配和短语匹配:
@Configuration
public class ElasticsearchConfig {
@Bean
public RestHighLevelClient restHighLevelClient() {
return new RestHighLevelClient(
RestClient.builder(new HttpHost("localhost", 9200))
);
}
}
@Service
public class EsKeywordMatcher {
@Autowired
private RestHighLevelClient esClient;
public List<SearchResult> fuzzyMatch(String query, int topK) throws IOException {
SearchRequest searchRequest = new SearchRequest("faq_index");
// 构建查询
BoolQueryBuilder boolQuery = QueryBuilders.boolQuery();
// 1. should: 匹配问题字段
boolQuery.should(QueryBuilders.matchQuery("question", query)
.fuzziness("AUTO")
.boost(2.0f));
// 2. should: 短语匹配
boolQuery.should(QueryBuilders.matchPhraseQuery("question", query)
.boost(3.0f));
// 3. should: 同义词匹配
boolQuery.should(QueryBuilders.matchQuery("synonyms", query)
.boost(1.5f));
// 4. should: 关键词匹配
List<String> keywords = extractKeywords(query);
for (String keyword : keywords) {
boolQuery.should(QueryBuilders.termQuery("keywords", keyword));
}
searchRequest.source(new SearchSourceBuilder()
.query(boolQuery)
.size(topK));
SearchResponse response = esClient.search(searchRequest, RequestOptions.DEFAULT);
return Arrays.stream(response.getHits().getHits())
.map(hit -> new SearchResult(
hit.getId(),
hit.getScore(),
hit.getSourceAsMap()
))
.collect(Collectors.toList());
}
}
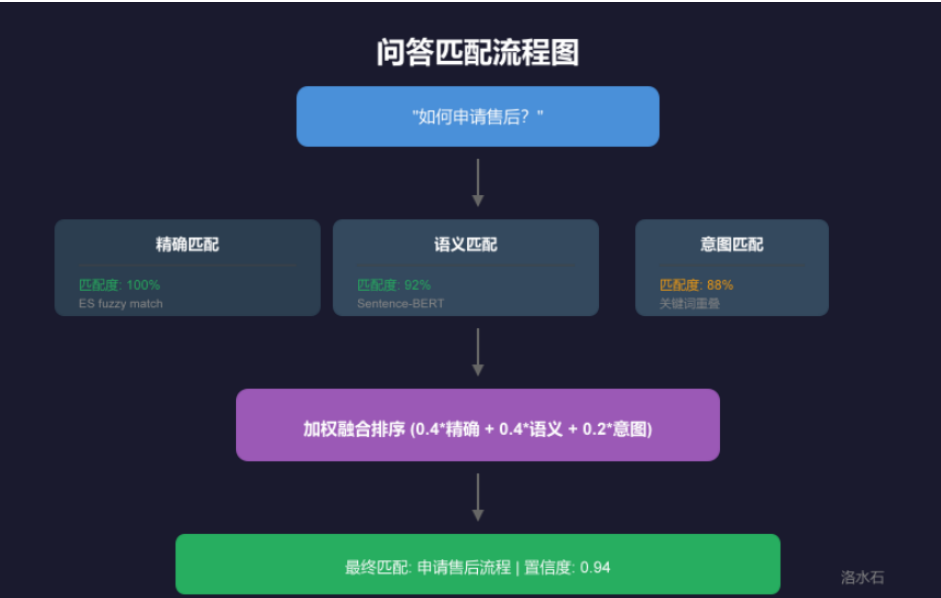
4.2 匹配策略组合
实际系统中,关键词匹配与语义匹配通常组合使用:
@Service
public class HybridMatcher {
@Autowired
private EsKeywordMatcher keywordMatcher;
@Autowired
private SimBertMatcher semanticMatcher;
public MatchResult hybridMatch(String query, List<FaqPair> faqPairs) {
// 1. 关键词匹配
List<SearchResult> keywordResults = keywordMatcher.fuzzyMatch(query, 20);
// 2. 语义匹配
List<CandidateResult> semanticResults = semanticMatcher.matchTopK(
query,
faqPairs.stream().map(FaqPair::getQuestion).collect(Collectors.toList()),
20
);
// 3. 结果融合
Map<Long, Double> fusedScores = new HashMap<>();
// 关键词得分 (归一化)
for (SearchResult result : keywordResults) {
fusedScores.put(result.getId(), result.getScore() * 0.4);
}
// 语义得分 (归一化)
for (CandidateResult result : semanticResults) {
Long id = findFaqId(faqPairs, result.getText());
fusedScores.merge(id, result.getScore() * 0.6, Double::sum);
}
// 4. 排序返回
return fusedScores.entrySet().stream()
.sorted(Map.Entry.<Long, Double>comparingByValue().reversed())
.findFirst()
.map(entry -> new MatchResult(entry.getKey(), entry.getValue()))
.orElse(MatchResult.noMatch());
}
}
5.1 多维度置信度计算
答案置信度由多个因素综合决定:
@Data
public class AnswerConfidence {
private double finalScore; // 综合得分
private double semanticScore; // 语义匹配分
private double keywordScore; // 关键词匹配分
private double exactMatchBonus; // 精确匹配加分
private int frequencyBonus; // 高频问题加分
private String matchType; // 匹配类型
public static AnswerConfidence calculate(
double semanticScore,
double keywordScore,
boolean isExactMatch,
int queryFrequency) {
double exactMatchBonus = isExactMatch ? 0.1 : 0;
double frequencyBonus = Math.min(queryFrequency / 1000.0, 0.05);
double finalScore = semanticScore * 0.5
+ keywordScore * 0.3
+ exactMatchBonus
+ frequencyBonus;
return AnswerConfidence.builder()
.finalScore(finalScore)
.semanticScore(semanticScore)
.keywordScore(keywordScore)
.exactMatchBonus(exactMatchBonus)
.frequencyBonus(frequencyBonus)
.matchType(determineMatchType(semanticScore, keywordScore))
.build();
}
}
5.2 排序策略实现
@Service
public class AnswerRanker {
private static final double HIGH_CONFIDENCE_THRESHOLD = 0.8;
private static final double LOW_CONFIDENCE_THRESHOLD = 0.5;
public RankedAnswer rank(String query, List<CandidateAnswer> candidates) {
// 1. 计算置信度
List<ScoredAnswer> scored = candidates.stream()
.map(c -> new ScoredAnswer(
c,
AnswerConfidence.calculate(
c.getSemanticScore(),
c.getKeywordScore(),
c.isExactMatch(),
c.getQueryFrequency()
)
))
.sorted(Comparator.comparingDouble(
s -> s.getConfidence().getFinalScore()).reversed())
.collect(Collectors.toList());
// 2. 选取最佳答案
ScoredAnswer best = scored.get(0);
// 3. 判断响应策略
ResponseStrategy strategy = determineStrategy(best.getConfidence());
return RankedAnswer.builder()
.answer(best.getAnswer())
.confidence(best.getConfidence())
.strategy(strategy)
.alternatives(scored.subList(1, Math.min(3, scored.size())))
.build();
}
private ResponseStrategy determineStrategy(AnswerConfidence confidence) {
if (confidence.getFinalScore() >= HIGH_CONFIDENCE_THRESHOLD) {
return ResponseStrategy.DIRECT_ANSWER;
} else if (confidence.getFinalScore() >= LOW_CONFIDENCE_THRESHOLD) {
return ResponseStrategy.ASK_CONFIRMATION;
} else {
return ResponseStrategy.TRANSFER_HUMAN;
}
}
}
5.3 排序策略类型
6.1 未知问题识别
当所有候选答案的置信度都低于阈值时,判定为未知问题:
@Service
public class UnknownQuestionHandler {
private static final double UNKNOWN_THRESHOLD = 0.3;
public boolean isUnknownQuestion(MatchResult matchResult) {
if (matchResult.getBestScore() < UNKNOWN_THRESHOLD) {
return true;
}
// 检查是否所有候选答案都低于阈值
long lowConfidenceCount = matchResult.getCandidates().stream()
.filter(c -> c.getScore() < 0.4)
.count();
return lowConfidenceCount == matchResult.getCandidates().size();
}
public UnknownQuestionResponse handle(String question, MatchResult matchResult) {
// 1. 记录未知问题
saveUnknownQuestion(question);
// 2. 尝试推荐相似问题
List<String> similarQuestions = recommendSimilarQuestions(question);
// 3. 决定是否转人工
if (shouldTransferHuman(question)) {
return UnknownQuestionResponse.builder()
.type(ResponseType.TRANSFER_HUMAN)
.message("抱歉您的问题我暂时无法解答,已为您转接人工客服")
.similarQuestions(similarQuestions)
.build();
}
// 4. 返回兜底话术
return UnknownQuestionResponse.builder()
.type(ResponseType.FALLBACK)
.message("抱歉您的问题我暂时无法解答,您可能想问:")
.similarQuestions(similarQuestions)
.build();
}
}
6.2 转人工机制
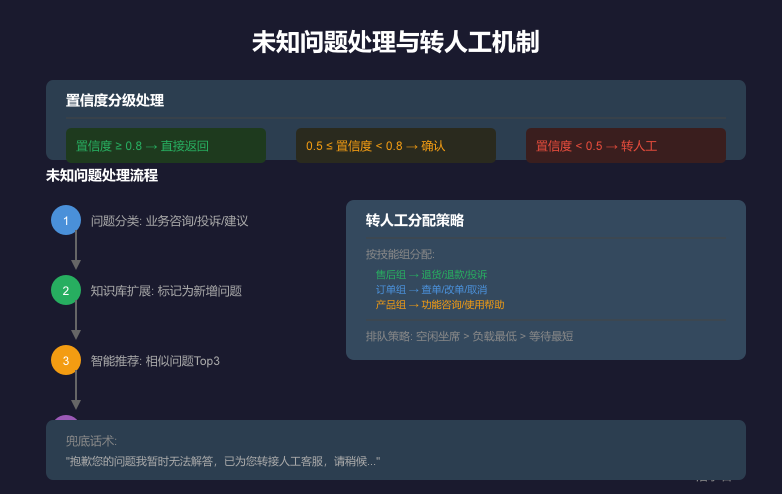
转人工服务需要考虑坐席分配和排队策略:
@Service
public class TransferToHumanService {
@Autowired
private HumanAgentPool agentPool;
public TransferRequest transfer(String sessionId, String question, String category) {
// 1. 确定转接技能组
String skillGroup = determineSkillGroup(category);
// 2. 获取可用坐席
List<Agent> availableAgents = agentPool.getAvailableAgents(skillGroup);
if (availableAgents.isEmpty()) {
// 进入排队
return createWaitingRequest(sessionId, question, skillGroup);
}
// 3. 选择最优坐席
Agent selectedAgent = selectBestAgent(availableAgents);
// 4. 执行转接
return executeTransfer(sessionId, selectedAgent, question);
}
private Agent selectBestAgent(List<Agent> agents) {
// 负载最低优先
return agents.stream()
.min(Comparator.comparingInt(Agent::getCurrentLoad))
.orElseThrow(() -> new RuntimeException("No available agents"));
}
}
6.3 知识库持续优化
未知问题处理后应进入知识库优化流程:
**知识库扩展流程**:
1. 未知问题记录到问题池
2. 运营人员定期审核
3. 编写标准问答对
4. 上线并验证效果
@Service
public class KnowledgeBaseOptimization {
public void optimizeUnknownQuestions() {
// 1. 统计未知问题频率
List<UnknownQuestionStat> stats = unknownQuestionRepository
.findTopUnknownQuestions(LocalDateTime.now().minusDays(7));
// 2. 高频问题优先处理
for (UnknownQuestionStat stat : stats) {
if (stat.getCount() > 10) {
// 标记需要新增FAQ
flagForFaqCreation(stat);
}
}
// 3. 生成优化报告
generateOptimizationReport(stats);
}
}
本篇文章介绍了FAQ问答与精确检索的完整方案:
1. **FAQ知识库设计**:结构化FAQ存储、同义问题扩展、配套管理功能
2. **语义匹配模型**:SimBERT、Sentence-BERT等模型的选型与使用
3. **关键词精确匹配**:Elasticsearch的fuzzy匹配和短语匹配能力
4. **置信度排序**:多维度置信度计算与分级响应策略
5. **未知问题处理**:未知问题识别、转人工机制、知识库持续优化
FAQ问答系统与多轮对话系统相辅相成,共同构成企业智能客服的完整解决方案。

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐
 9
9 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)