5.震撼! Langgraph中的Subgraphs最详细拆解
大家好,本篇文章给大家分享一些在langgraph中Subgraphs的使用方法以及里面的一些概念的理解,本篇文章以Langgraph的官方文档作为主要参考同时我会用通俗的词藻解释一些晦涩难懂的概念。
在第四章内容分享的时候,在讲解Command的是就分析过graph这个参数,感兴趣的朋友可以去看一下。Subgraph(子图)这个概念我们先来理解一下,实际上我们可以把子图概念看成是低代码平台中的一个独立的工作流,无论是使用低代码平台还是使用Langgraph框架,我们都很难做到用一个流程就完成一个项目,对大多数项目来说都是mutil-agent systems,需要构建很多的子流程,这样来构建不仅系统开发起来比较容易,同时耦合度比较低,易于我们去调试和维护。
在理清楚Subgraphs这个概念之后,我们来说说它的用途:1、构建多智能体系统;2、在多个graph中复用一组node(这里可以理解为一个能复用的组件);3、分布式开发:当希望不同的团队独立地处理graph中的不同部分时,可以将每个部分定义为一个子图。只要遵循子图的接口(输入输出模式),就可以在不了解子图的任何细节的情况下构建父图。
在应用场景搞清楚了之后,我们怎么在实际工作过程的时候去使用它呢?首先我们需要考虑子图的通信!最基本的就是“在节点中调用子图”。因为在Langgraph中node是Graph执行的最小单元,我们可以在node里面调用子图。这种方式实际上就是解耦的一种体现,他的本质上是实现图的模块化和层级化的一种手段,我们可以把一个已经编译好的子图当作一个普通的“node”插入到父图当中。举个例子,一般对于一个多智能体系统,通常情况下都会有一个主流程,在主流程中又会有很多个小的子流程,这些子流程实际上我们就可以是子图,当父图运行到一个子图封装的节点的时候,便会触发子图的执行,知道子图达到其定义的END状态。但是这里我们需要注意,这样的方式是子图在执行时有自己的State,那么这就意味着在节点中调用子图,父图需要将当前的State信息“传递”给子图,子图执行完毕后,将结果更新回到父图的State中。
第二种方式就是直接将子图作为单个节点添加到父图当中,这种方式和前面的方式区别在于他们之间的通信方式不同,前者是父图和子图具有不同的State,而这种方式是父图和子图共享State。这两种方式的最终的结果实际上是相同的,只是使用方式和场景有细微的差别,第一种方式是我们需要写一个函数并在函数内部调用子图,这种方式的使用场景是当你需要对子图的输入进行转换,或者在子图执行前后需要运行额外的逻辑(如过滤、日志记录、状态转换)时。如下:
# 定义一个节点函数
def call_subgraph(state: ParentState, config: RunnableConfig):
# 直接在节点内调用子图
result = my_subgraph.invoke(state, config)
# 返回更新后的状态(合并到父图状态)
return {"some_key": result["some_key"]}
# 在父图中像使用普通节点一样添加它
builder.add_node("subgraph_node", call_subgraph)第二种方式我们完全将子图视为一个黑盒节点,无需编写像上面一样的函数体,这种使用方式场景是在当子图的输入/输出与父图State结构完全契合,或者不需要复杂的预处理/后处理逻辑时去使用。“Add a subgraph as a node(将子图作为单个节点添加)” 是 LangGraph 提供的一种高阶组合模式。它把你原本需要通过“编写函数 -> 在函数里 invoke 子图”的繁琐过程,简化为直接声明“这个节点就是这个图”。这体现了 LangGraph 强大的结构化设计思想:复杂的 Agent 系统不过是多个简单图的嵌套与组合。
以上是我们在使用子图是首先要去进行确定一件事情,接下来我们来说说Subgraph persistence(子图持久化)。说实话,所以我必须吐槽一下,在Langgraph中有些概念是在是过于抽象了,不太好理解。如果我这里只来单纯的解释Subgraph persistence的相关内容,容易造成阅读起来更加抽象的结果,所有说这个之前我先给各位讲一下Langgraph本身的“persistence能力(持久化能力)”,当然这里我会用通俗的话来解释,实际上我们将这些概念抽出来理解是很容易理解的,只不过官方对这些概念的解释写得很抽象,不过到目前也没有中文版本的官方文档,社区版本的翻译也没有,我真想来做一下这个事情。看英文的技术文档(英文不够好)有时候用浏览器上的一些翻译实在是翻译的不准确,还容易造成对概念误解。也希望早日有符合国人的文档出来吧!
说到persistence的内容,我们首先说一下Threads(线程),这个还是比较好理解的,我们就把它理解成为我们在和Agent对话时他的会话ID就可以了,这个会话ID是唯一的。只不过它不会再我们做好的一个graph中自动生成,是需要我们认为去设置的,这个需要着重注意一下。接下来是Checkpoints(检查点),官方对它的解释是:线程再特定时间点的状态称为检查点。那么这个特定时间点的状态又由什么来表示呢---StateSnapshot(状态快照),实际上这个StateSnapshot就是在一个graph中,里面的每个node在工作结束之后就会有一个状态快照,它长这个样子:
StateSnapshot(
values={'foo': 'b', 'bar': ['a', 'b']},#本次检查点对应的状态通道取值
next=(),# 接下来要执行的节点名称,空()表示graph已经完成
config={'configurable': {'thread_id': '1', 'checkpoint_ns': '', 'checkpoint_id': '1ef663ba-28fe-6528-8002-5a559208592c'}},# 包含thread_id,checkpoint_ns,checkpoint_id
metadata={'source': 'loop', 'writes': {'node_b': {'foo': 'b', 'bar': ['b']}}, 'step': 2},# 执行元数据,包含 source ( "input" 、 "loop" 或 "update" )、 writes (节点输出)和 step (超级步骤计数器)。
created_at='2024-08-29T19:19:38.821749+00:00',# 时间戳
parent_config={'configurable': {'thread_id': '1', 'checkpoint_ns': '', 'checkpoint_id': '1ef663ba-28f9-6ec4-8001-31981c2c39f8'}}, tasks=() # 前一个检查点的配置。第一个检查点 None 。
)从对于的值的注释我们就可以看到,这个快照中包含了整个graph执行需要的所以参考,这就有点像在低代码平台里面每个节点都会返回东西,只是平台将返回的结果进行了封装,我们看不到,而使用Langgraph这个框架,我们就能够看到所有的信息。这样是不是就很好理解了!所有这里我们应该将Checkpoints和StateSnapshot结合起来理解才行。接下来在说说Super-steps,中文翻译超级步骤,简称超步,这里我们其实可以将他理解为一个执行步骤就可以了,那么Langgraph的最小执行步骤是什么呢,就是一个node,这个node在执行结束后会产生一个StateSnapshot。以上说的相关概念在下面这幅图中由比较形象的解释,如下:
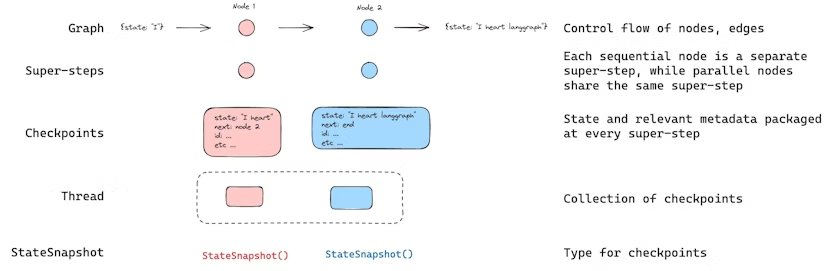
上面只是简单的说了一下Langgraph关于persistence(持久性)的最基本概念,也是为了方便各位理解Subgraph persistence的内容,后续我会专门出一篇文章来讲解一下在Langgraph的Persistence这个特性,敬请期待!回到文章的主题,在 LangGraph 中,Subgraph persistence(子图持久化)的核心在于决定子图在多次调用之间是否需要保留内部数据(如对话历史、上下文、临时进度等)。这个能力有三种模式,当你在父图中调用子图时,通过在子图编译阶段设置 .compile(checkpointer=...)来进行使用。
| 模式 | 特点 | 行为 | 适用场景 |
|---|---|---|---|
|
Per-invocation(默认模式 - 推荐) |
“每次调用都是全新的”。 | 子图继承父图的检查点(用于支持 interrupt() 和崩溃恢复),但每次调用子图时,它内部的状态都会重置(编译时默认checkpointer为None) |
多智能体协作中,子智能体作为“工具”处理一次性任务。例如,父图调用一个“天气查询专家”子图,不需要记住上次查询的天气,每次都是独立的。 |
|
Per-thread(持久化模式) |
“上下文记忆” | 子图的状态会随线程(Thread)跨调用持续累积。这意味着如果父图在同一个线程 ID 下多次调用该子图,子图会记得上一次中断或执行结束时的状态。(编译时设置 checkpointer=True。) |
需要长期上下文的辅助智能体。例如,一个“研究助手”子图,通过多次调用积累研究进度和上下文信息。 |
|
Stateless(无状态模式) |
“纯函数,无持久化”。 | 完全不保存检查点,不具备持久化执行能力。如果程序中途崩溃,子图无法恢复,必须从头运行。(编译时设置 checkpointer=False。) |
需要极致性能且逻辑简单、无需中断或长时记忆的任务。 |
要理解Subgraph Persistence 就像在配置“记忆力”:
- Per-invocation 是“金鱼的记忆”(每次都当新任务做);
- Per-thread 是“长期的记忆”(保留之前的进展);
- Stateless 是“临时计算”(断电即丢失)。
根据你的业务需求选择合适的模式,可以有效平衡系统性能与上下文管理的需求。
好的,关于本章的内容就写到这里了,一个字一个字的来手敲确实太耗费时间了,实际上我也是去看官方文当然后在理解了之后将我对理解给总结了下来,同时还需要再实际工作中去使用才能融汇贯通,谢谢各位!

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐

 15
15 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)