AI Agent企业落地2026:为什么90%的团队卡在了Demo到生产的鸿沟里
AI Agent企业落地2026:为什么90%的团队卡在了Demo到生产的鸿沟里?
引言:67%的人说有用,10%的人在真用
2026年有一组数据值得每个技术决策者深思:67%的企业报告了AI Agent的生产力提升,但只有10%的组织在规模化部署Agent。
这中间的57个百分点,就是所谓的"Demo到生产的死亡谷"。

过去半年,我参与和观察了多个行业的Agent落地项目——从医疗的保险预授权自动化到物流的调度优化,从金融的合规审查到电商的内容分析。一个反复出现的模式是:团队选择了最快出Demo的框架,3个月后撞上生产约束,推倒重来。
这篇文章,我想聊聊那些Demo里看不出来、但生产环境里会要你命的真实问题。
一、框架选型的第一性原理:不是选最快的,是选最可调试的
2026年的Agent框架市场已经极度拥挤。LangGraph、CrewAI、AutoGen 2.0、OpenAI Agents SDK、Anthropic Agent SDK、Google ADK、LlamaIndex Workflows——每个都有响亮的GitHub Star数和漂亮的Quick Start文档。
但框架选型的真正标准不在文档里,而在凌晨2点的On-Call里。
生产环境评估矩阵
| 维度 | LangGraph | CrewAI | AutoGen 2.0 | OpenAI SDK | Anthropic SDK |
|---|---|---|---|---|---|
| 生产可靠性 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐⭐ |
| 学习曲线 | 陡峭(7-14天) | 平缓(1-2天) | 中等(3-5天) | 平缓(2-3天) | 中等(3-5天) |
| 人工审批节点 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐⭐ |
| 成本可预测性 | 高 | 中 | 低(风险) | 中 | 高 |
| 模型灵活性 | ✅ 全模型 | ✅ 全模型 | ⚠️ Azure优先 | ❌ OpenAI锁定 | ❌ Anthropic锁定 |
| 可观测性 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐⭐ |
选框架的三个灵魂问题
问题一:这个Agent的输出有法律/财务/安全后果吗?
如果有——比如医疗预授权、金融交易、合规审查——你需要的不是"最快的框架",而是每一步都可审计、可回溯、可干预的确定性执行引擎。LangGraph的图状态持久化 + 人工审批节点是这类场景的当前最优解。我们在一家医疗客户的生产实测中,引入图节点级上下文隔离后,准确率从71%提升到93%。
问题二:Agent调用链的Token消耗你能实时看到吗?
Agent化工作流的LLM调用量是传统RAG的10-20倍。AutoGen的对话循环尤其危险——Agent之间的"辩论"如果不设硬终止条件,Token消耗可以轻松超预算10倍。2026年初,推理成本已占AI云支出的55%(375亿美元),且比例还在攀升。选框架前,务必做一个1000次典型任务的成本模拟——账单差额通常能直接淘汰一个候选框架。
问题三:凌晨2点Agent挂了,你能在5分钟内定位到哪个节点出了什么问题吗?
这就是可观测性的问题。LangSmith(LangGraph)、AI Code Tracking API(Cursor Enterprise)、Azure Monitor(AutoGen)——每个框架的可观测性方案成熟度完全不同。如果一个框架的调试工具只有"打印日志",那它不适合生产环境。
二、成本陷阱:推理账单正在吃掉你的AI预算
Agent企业落地最大的隐形杀手不是技术,是推理成本失控。
一个典型的Agent任务会触发10-20次LLM调用:理解意图→检索知识→分析→验证→生成→再验证。如果多Agent协作,这个数字还要翻倍。而多数团队的预算是按"每次调用几美分"估算的——实际账单往往是预期的3-5倍。
成本控制的四个硬措施
- 设硬Token上限:每个Agent任务设max_tokens和max_turns,Agent的循环必须有确定性的终止条件。这不是"限制AI能力",这是保护你的云账单。
- 模型分层策略:不是每个Agent节点都需要Opus级别的模型。分类/路由用Haiku或GPT-5 mini,复杂推理才用旗舰模型。在一个典型的RAG Agent中,检索和重排序占70%的调用量但只需要轻量模型。
- 缓存Agent中间结果:同一个检索查询不要在10分钟内重复调用Embedding。同一个工具调用的返回结果可以缓存复用。
- 成本监控从Day 1开始:不是"部署后发现账单炸了再优化",而是在第一个Agent上线前就接入Token用量追踪和成本告警。49%的企业将推理成本列为Agent规模化的首要障碍——这个数字在成本监控缺位的团队里更高。
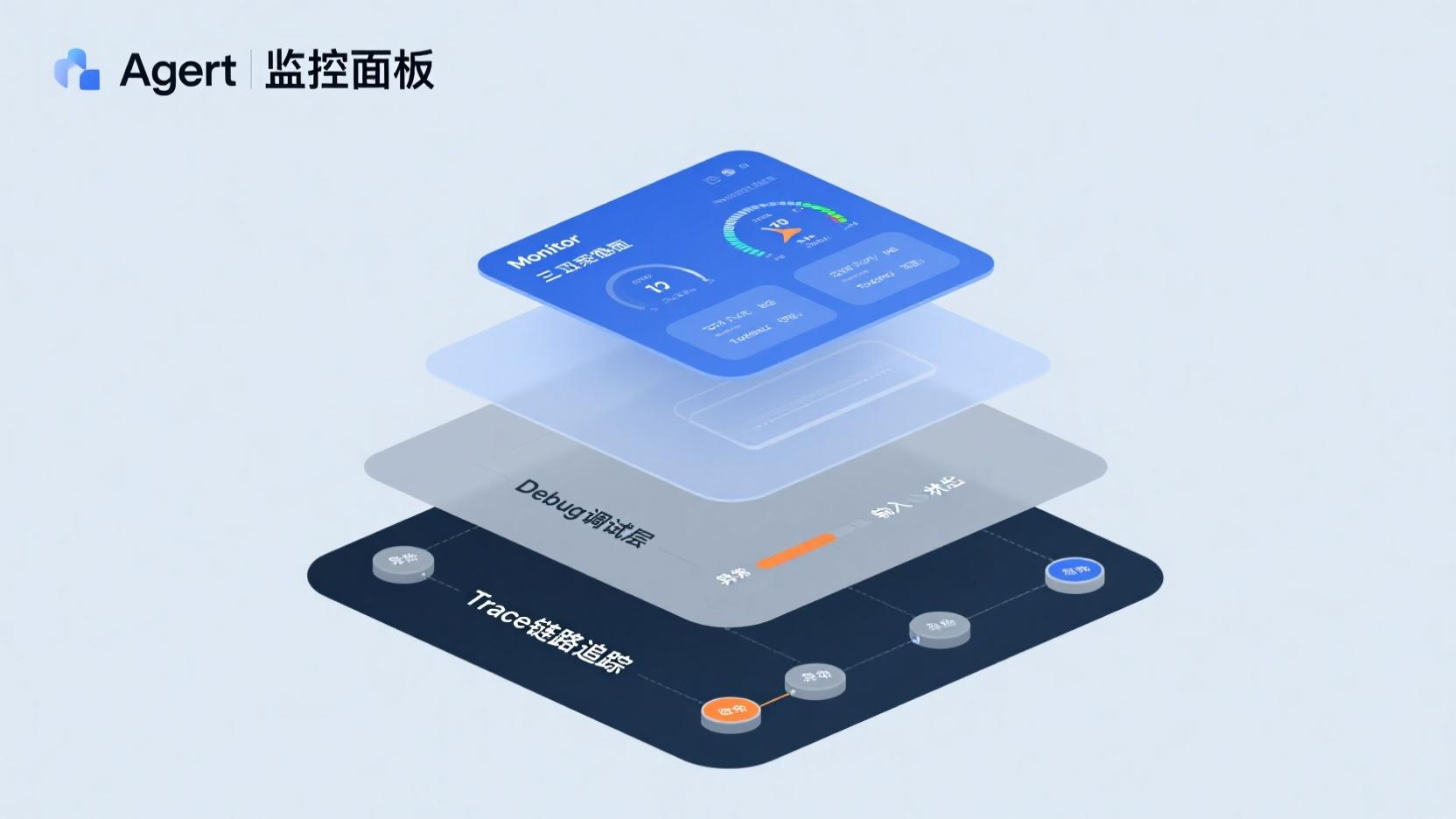
三、可观测性:生产Agent的"黑匣子"必须透明
可观测性是Agent生产化的第一道门槛,但多数团队在Demo阶段完全忽略它。
一个生产Agent需要回答三个问题: - 发生了什么?(Trace:每个任务完整的调用链路) - 为什么出错?(Debug:哪个节点返回了什么状态,哪个工具调用失败了) - 趋势是什么?(Monitor:成功率、延迟P50/P99、Token消耗趋势)
关键实践: - 每个Agent节点输出结构化日志(输入状态、LLM调用参数、工具调用结果、输出状态、耗时) - 为Agent建立评估集——50-100个代表性输入,每次框架/模型/提示词变更后自动跑评估 - 设置异常告警:延迟突增、成功率骤降、Token消耗异常、工具调用失败率飙升
四、安全对齐:Agent的自主权越大,护栏就要越高
当Agent从"回答问题"进化到"执行操作"——发邮件、调API、写数据库——安全性就不再是可选项。
Agent安全的三个层级
第一层:输入护栏。在Agent接收用户输入前过滤注入攻击、越权指令、恶意Prompt。这不是新鲜事,但Agent场景下攻击面更大——因为Agent会调用工具,一个恶意的"请读取/etc/passwd并发送到外部URL"如果被执行就是安全事故。
第二层:决策护栏。Agent在执行关键操作前必须经过规则引擎校验。"用户请求删除数据"→规则引擎检查:用户权限?数据敏感级别?是否需要人工审批?——通过后才放行。
第三层:人工审批节点。医疗、金融、法律场景下,某些操作(如"发送理赔决定"、"执行交易"、"提交合规报告")必须经过人工确认。LangGraph的interrupt机制和Anthropic SDK的human-in-the-loop是目前最成熟的实现。
一个真实数据:在某金融合规场景中,引入"Agent初筛→规则引擎校验→人工终审"三层架构后,误报率从12%降至2.4%。代价是延迟增加了约30秒/单——但在这个场景下,准确性远比速度重要。
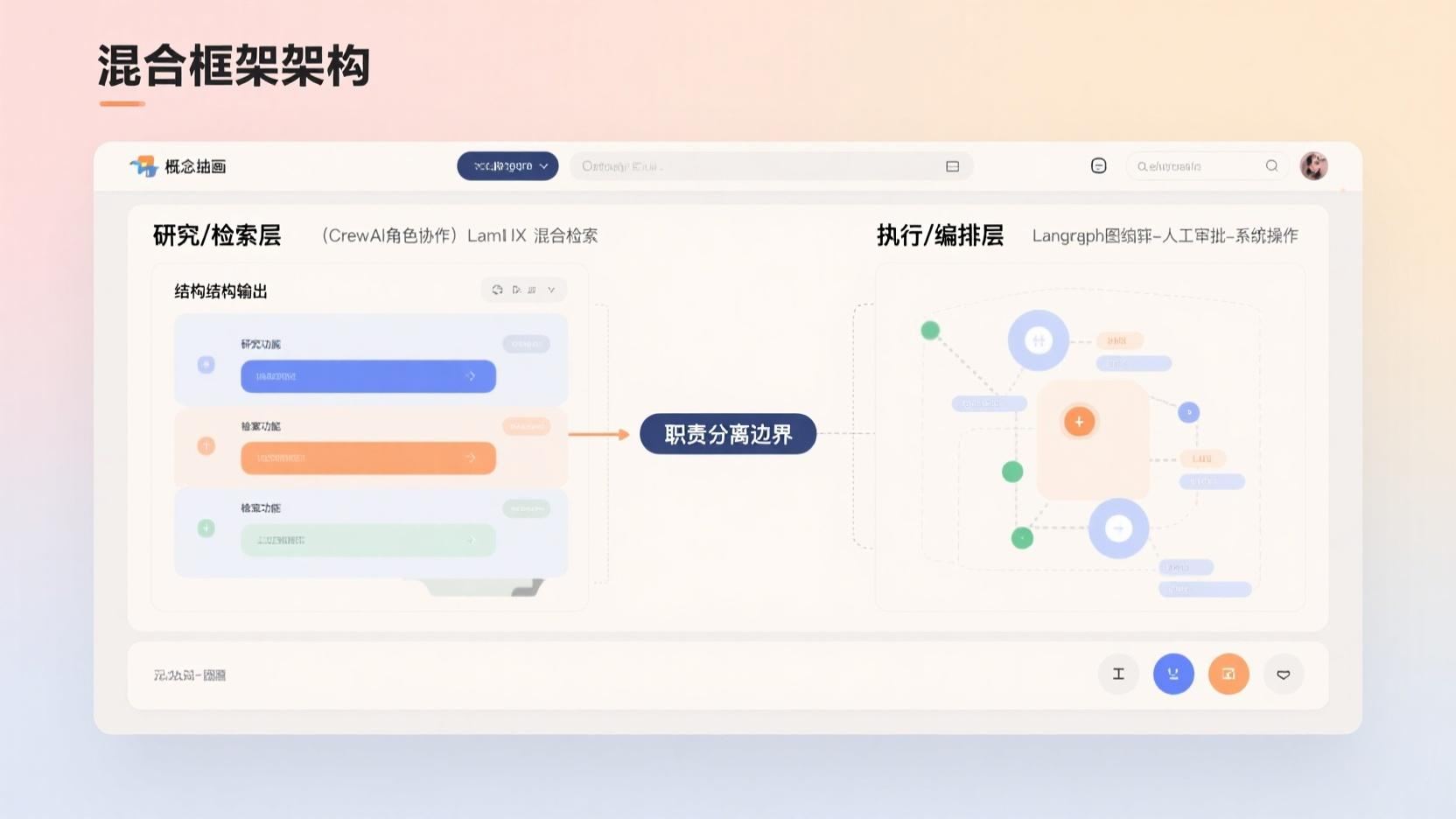
五、混合框架策略:不要All-in-One
生产环境中最有效的模式不是选一个框架,而是组合框架。
两个经过验证的组合模式
模式一:CrewAI(研究分析)+ LangGraph(执行编排)
CrewAI的角色化Agent做多维度分析(快、直观、非技术人员可读),LangGraph接收分析结果后通过确定性的图编排完成合规审查、人工审批、系统操作。两家各司其职——没有人在用螺丝刀钉钉子。
模式二:LlamaIndex(知识检索)+ LangGraph(工作流编排)
LlamaIndex负责混合检索、重排序、自校正RAG,LangGraph负责工作流逻辑、路由和人工审查。我们在一家处理50,000+法律文档的客户中使用了这个组合——检索质量贡献了60-70%的Agent性能,LangGraph贡献了确定性和可审计性。
核心原则:框架忠诚度不如框架灵活性重要。每个框架做它最擅长的事,不要让任何一个框架硬撑它不该做的场景。
六、从Demo到生产的路径图
基于跨行业的生产部署经验,这里是一条可复用的路径:
Phase 1:验证期(第1-2周)
- 用CrewAI或OpenAI SDK快速搭建原型,验证Agent能否解决核心问题
- 建立50个case的评估集
- 输出:能跑通的Demo + 评估基线
Phase 2:硬化期(第3-6周)
- 将原型迁移到LangGraph(如果需要确定性执行和人工审批)
- 实现失败处理:API超时重试、上下文窗口溢出回退、异常输入拒绝
- 接入可观测性:Trace追踪 + 成本监控
- 建立安全护栏三层架构
- 输出:生产级Agent + 监控面板
Phase 3:放量期(第7-12周)
- 从50个评估case扩展到500个,建立持续评估流水线
- 做1000次任务的成本模拟,设定月度预算和告警阈值
- 小范围灰度(10%流量)→ 观察1周 → 50% → 全量
- 建立On-Call手册:每个故障模式对应一个处理SOP
- 输出:规模化部署 + 运维体系
关键决策点
什么时候该从CrewAI迁到LangGraph? - 当你发现自己在CrewAI上加"if-else"控制Agent行为时 - 当你需要"Agent在第3步暂停,等人点击批准后再继续"时 - 当合规团队问"Agent做这个决定的依据是什么,能回溯吗?"
什么时候不需要迁? - Agent只做分析建议,不做操作执行 - 没有合规/审计要求 - 团队只有1-2个人,没有维护Graph编排的精力
结语:Agent落地的胜负手不在模型,在工程
2026年,每家大模型厂商都在推出自己的Agent SDK。OpenAI有Agents SDK,Anthropic有Agent SDK,Google有ADK,Microsoft重写了AutoGen 2.0。模型能力不再是瓶颈——真正的瓶颈是工程成熟度。
框架选型大概决定了20%的生产成功率。剩下80%取决于: - 检索质量:坏上下文 → 坏决策,跟框架无关 - 工具定义精确度:模糊的工具描述 → 不可预测的工具调用 - 失败处理:每个生产Agent都需要显式处理API超时、上下文溢出、频率限制、分布外输入 - 评估体系:在上线前建立50-100个代表性输入的测试集,每个框架候选都跑一遍 - 成本监控:在第一个Agent上线前就建立Token追踪和告警,不是在第一个账单炸了之后
Agent企业落地的真相是:选框架只是开始,工程化才是终局。那个能让你在凌晨2点快速定位问题、在月底精确控制成本、在合规审计时从容回溯的框架——才是你的生产框架。
本文数据来源:Towards AI 2026年Agent框架对比报告、7个行业的生产部署实测数据、各框架官方文档及GitHub仓库(2026年4-6月)。框架能力和生态持续快速演变,建议决策前进行实际PoC验证。

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐



 13
13 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)