AI Agent时代的数据库需求演变:数据沙箱如何破解智能体并发与状态管理困局
想象一个厨房,五位厨师同时要做同一道菜的改良版。有人多放盐,有人换酱料,有人调整火候——每个人都想独立尝试,但又不能互相干扰,更不能把公共厨房的食材糟蹋干净。做完之后,还要能快速恢复原状,让下一位厨师从零开始。
这就是当下AI Agent在数据库上面临的现实写照。图灵奖得主Michael Stonebraker曾直言:“AI Agent的发展,最后全都是数据库问题。”一语道破了智能体爆发背后,一个被长期忽视的技术底座正在被重新审视——AI Agent数据库不再只是”存数据”的地方,而是智能体高效协作与安全试错的核心基础设施。
一、为什么AI Agent需要全新的数据库范式?
传统数据库的设计哲学可以概括为”串行、静态、中心化”。一个业务流程走完,下一个流程再排队执行;数据结构确定后,变更需要层层审批;所有操作围绕一个中心节点展开。这套逻辑在传统业务场景中运转了几十年,毫无问题。
然而,AI解决问题的方式截然不同。智能体高度并行、探索试错、极具动态性——它可能在毫秒级内同时发起数十条SQL查询,每条查询指向不同的数据分支;它可能反复推翻自己的方案,需要快速回滚到上一个状态;多个智能体协作时,各自的数据空间必须完全隔离,否则一个Agent的失误会导致整个系统崩溃。
这种”毫秒级试错”的需求,直接碰上了传统数据库的架构天花板。2025年,Databricks以10亿美元收购数据库创业公司Neon,其背后暴露出一个关键信号:Neon平台上每5个数据库中有4个由AI Agent创建,占比高达80%。数据库的增长驱动力,正快速从”人类业务操作”转向”AI智能体自动创建”。谁能提供秒级创建隔离环境的能力,谁就拿到了AI Agent时代的数据底座入场券。
在此背景下,数据沙箱作为一种新兴的数据库技术架构,正在成为解决AI Agent并发与状态管理困局的关键路径。
二、核心概念:什么是数据沙箱?
数据沙箱,是指在数据库内核层面,通过写时拷贝等技术手段,在极短时间内为用户或应用程序创建一个与生产环境完全隔离的、可独立读写的数据库副本环境。它与传统的数据库副本、逻辑备份有着本质区别——传统方式需要完整复制数据,耗时从数小时到数天不等;而数据沙箱几乎”零延迟”即可就绪,且仅在实际写入时才分配额外存储空间。
与之紧密关联的另一个核心概念是数据库分支。类似代码开发中的Git分支机制,数据库分支允许用户基于某个时间点的数据快照,创建一个独立的分支版本,在该分支上自由执行读写操作,而不影响主库或其他分支的数据。分支之间彼此隔离,又可随时合并或回退。
智能体状态管理则是指对AI Agent在推理和决策过程中的数据状态进行记录、隔离、恢复的能力。AI Agent的每一次推理都可能产生中间状态数据,这些数据需要在安全的环境中生成和管理,既不能污染生产数据,也不能被其他Agent的操作意外覆盖。
三者的关系可以简单理解为:数据沙箱是技术实现,数据库分支是管理手段,智能体状态管理是应用目标。
三、技术原理:数据沙箱如何实现毫秒级隔离?
数据沙箱技术的核心在于写时拷贝(Copy-on-Write, CoW)机制。当系统创建一个数据沙箱时,并不真正复制底层数据文件,而是为该沙箱创建一个指向原始数据的逻辑映射。只有在沙箱内首次对某个数据块执行写操作时,系统才会将该数据块复制一份到沙箱专属的存储空间中。这意味着,无论底层数据量是1GB还是1TB,沙箱的创建时间几乎恒定——通常在毫秒级完成,存储开销也仅为实际修改部分的增量数据。
以崖山数据库(YashanDB)的数据沙箱实现为例,其技术架构包含以下几个关键层次:
四层隔离体系
崖山数据库在内核原生层面实现了完整的四层隔离机制:
存储隔离:每个沙箱拥有独立的存储空间标识,底层数据块的修改仅在沙箱内部可见,物理层面与其他沙箱和主库完全隔离。
事务隔离:沙箱内的事务操作独立于主库事务体系,确保并发实验时事务状态互不干扰。
连接隔离:每个沙箱维护独立的连接上下文,Agent的数据库连接与会话状态在沙箱边界内封闭运行。
权限隔离:基于DBMS_BRANCH机制,可以为不同沙箱设定差异化的访问权限,实现细粒度的安全管控。
完整的生命周期管理
数据沙箱并非”一次性”的临时环境,而是具备完整生命周期的数据库对象。崖山数据库提供了涵盖CREATE(创建)、CHECKOUT(检出)、DELETE(删除)、RESET(重置)、RESTORE(恢复)、FREEZE(冻结)、ACTIVATE(激活)在内的全生命周期管理能力。
其中,RESET可以在秒级内将沙箱恢复到创建时的初始状态,RESTORE则支持将沙箱恢复到任意指定的时间点。这两项能力对AI Agent的高频试错场景尤为重要——智能体可以在一个沙箱中反复进行实验,每次失败后秒级回退,完全不影响其他沙箱或生产环境的运行状态。
Time Travel时光机
除了沙箱自身的状态管理,崖山数据库还内置了Time Travel”时光机”功能,支持闪回查询(查询历史时刻的数据状态)、DDL闪回(回退表结构变更)和DML闪回(回退数据修改)。这为AI Agent在实验过程中误操作数据或结构变更提供了额外的安全兜底。
在资源管理方面,数据沙箱支持弹性伸缩——按需分配存储与计算资源,运行时动态调整,空闲时自动释放。单实例最多可支持8192个数据沙箱同时存在,满足大规模AI并发实验的资源需求。
四、应用场景:数据沙箱在AI Agent时代的实战价值
场景一:AI并行实验——毫秒级多分支验证
在AI模型训练与调优过程中,研究人员往往需要同时验证多种不同的数据方案或参数组合。传统做法需要为每组实验准备独立的数据库实例或数据副本,耗时耗力。
借助数据沙箱技术,系统可以在毫秒级内基于同一份数据创建多个独立分支,每个分支运行不同的实验方案。例如,一个金融风控模型需要同时测试5种特征工程方案,只需创建5个沙箱,各自独立执行,互不干扰。实验完成后,选取最优方案合并到主库即可。相比传统方式,并行效率可提升数倍,资源利用率显著改善。
场景二:多智能体协同——隔离空间保障安全
在多智能体协同场景中,多个AI Agent可能同时访问和修改数据库中的数据。如果没有隔离机制,一个Agent的异常操作可能连锁影响其他Agent的决策逻辑,甚至导致系统崩溃。
数据沙箱为每个Agent分配独立的数据空间,Agent之间的读写操作完全隔离。即使在极端情况下某个Agent执行了危险操作(如误删全表),其影响也仅限于该Agent所在的沙箱,不会波及其他Agent或生产环境。这种隔离能力是企业级AI落地过程中不可或缺的安全保障。
场景三:Schema变更预演——降低生产风险
数据库表结构变更(DDL操作)是企业IT运维中的高风险环节。一次不当的表结构修改可能导致线上服务中断。在金融AI场景中,涉及交易数据的核心表结构变更更是容不得半点差错。
数据沙箱允许在隔离环境中先执行Schema变更预演,全面验证变更对应用程序、查询性能和数据一致性的影响,确认无误后再在生产环境中执行。结合Time Travel的DDL闪回功能,即使预演过程中发现问题,也可以秒级回退到变更前的状态,极大降低了生产环境的风险。
场景四:高危操作回退——秒级恢复保障业务连续性
在日常数据库运维中,批量数据更新、删除等高危操作一旦执行失误,恢复成本极高。传统方案依赖全量备份恢复,耗时动辄数小时。
数据沙箱的RESTORE和RESET功能可以在秒级内完成回退操作。系统将高危操作限定在沙箱内执行,验证通过后再应用到生产库;若验证失败,一键回退,业务连续性不受影响。这种”先试后做”的运维模式,正在成为AI驱动的自动化数据库运维的标准实践。
五、数据沙箱与传统方案对比
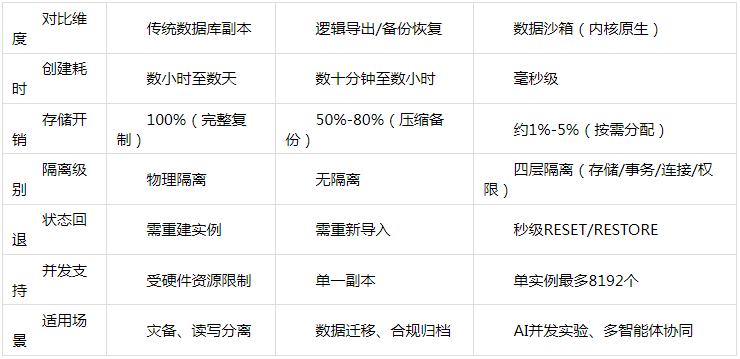
从上表可以看出,数据沙箱在创建速度、存储效率、隔离能力和状态管理等方面,均展现出传统方案难以比拟的优势。尤其在高并发、高频试错的AI Agent场景下,数据沙箱的性能差异呈指数级放大。
六、行业趋势与代表产品
政策驱动:智能体规范应用加速落地
2025年,三部门联合印发《智能体规范应用与创新发展实施意见》,明确提出到2027年智能体应用普及率超过70%的目标。文件要求智能体应用做到”分类分级、安全围栏、数字身份、严格备案”。这从政策层面为数据沙箱技术提供了明确的需求牵引——“安全围栏”的实现,离不开数据库层面的隔离能力。
市场信号:AI驱动数据库架构革新
Databricks以10亿美元收购Neon的交易,是AI Agent重塑数据库市场格局的一个标志性事件。Neon的实践表明,“Try Everything”模式——让AI Agent瞬间创建隔离数据库环境、快速试错、择优保留——正在成为新一代数据库的必备能力。某国外数据库厂商也开始在其云服务中引入类似的分支与克隆功能,但受限于架构设计,其隔离粒度和创建速度仍有提升空间。
某国产数据库厂商则选择了在外围工具层面实现数据隔离能力,通过逻辑导出和容器化技术模拟沙箱环境。这种方式虽然实现门槛较低,但在创建速度、隔离深度和资源效率上,与内核原生实现存在本质差距。
崖山数据库(YashanDB):内核原生的数据沙箱实践
崖山数据库(YashanDB)的数据沙箱能力从设计之初就定位为内核原生实现,而非外围封装。这种架构选择带来的优势是全方位的:毫秒级的分支创建、四层隔离体系、完整的生命周期管理、8192个沙箱的并发承载能力,以及与Time Travel时光机的无缝集成。
在企业级AI落地的安全管控层面,崖山数据库(YashanDB)推出了YashanClaw企业级智能体管控方案,实现了基础设施、数据、模型算法、应用执行四维安全体系。YashanClaw通过独立进程沙箱与最小化权限机制,保障智能体执行环境的安全性;通过向量检索与全文检索融合的记忆管理机制,有效降低Token消耗,支撑10万+并发访问规模。
七、结语:数据沙箱是AI Agent时代的必选项
AI Agent的爆发正在重新定义数据库的使命。从”支撑业务运行”到”赋能智能试错”,数据库的角色正在经历根本性的转变。图灵奖得主的判断正在被市场验证——AI Agent的发展,终归要回到数据库层面来解决问题。
数据沙箱技术以其毫秒级创建、四层隔离、秒级回退的核心能力,为AI Agent的并发实验、状态管理和安全协同提供了切实可行的技术底座。无论是AI并行实验中的多分支验证,还是多智能体协同中的隔离保障,抑或是Schema变更预演中的风险防控,数据沙箱都展现出传统方案无法替代的价值。
随着2027年智能体应用普及率超过70%的政策目标逐步临近,数据沙箱将从”可选能力”转变为”必备能力”。对于正在推进AI转型的企业而言,在数据库选型阶段就评估其数据沙箱能力,将是一项具有前瞻性的技术决策。

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐
 8
8 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)