从 Hermes Agent 架构中提炼出的第11个 LangGraph 设计模式:Self-Improving Agent
从 Hermes Agent 架构中提炼出的第11个 LangGraph 设计模式:Self-Improving Agent
拆解 Nous Research 最新开源项目的学习闭环,用 LangGraph 实现一个会自我进化的 Agent
这两天 Nous Research 发布了 Hermes Agent,一个号称"会随你成长的 AI Agent"。28k+ GitHub stars(现在有33.1k了),社区讨论热度很高。
我花了几天时间深入分析了它的源码,发现最有价值的可能不在于它的40+工具或14个平台接入,反而是它的学习闭环架构——Agent 完成复杂任务后,自动将方法提取为可复用的 Skill,下次遇到类似问题直接调用并改进,当然这也是 Hermes Agent 的核心卖点。
我觉得这个设计理念十分不错,再结合自身的开源项目 AgentFlow,完全可以用 LangGraph 的 StateGraph 来实现。于是我把它提炼成了 AgentFlow 的第11个设计模式:Self-Improving Agent。
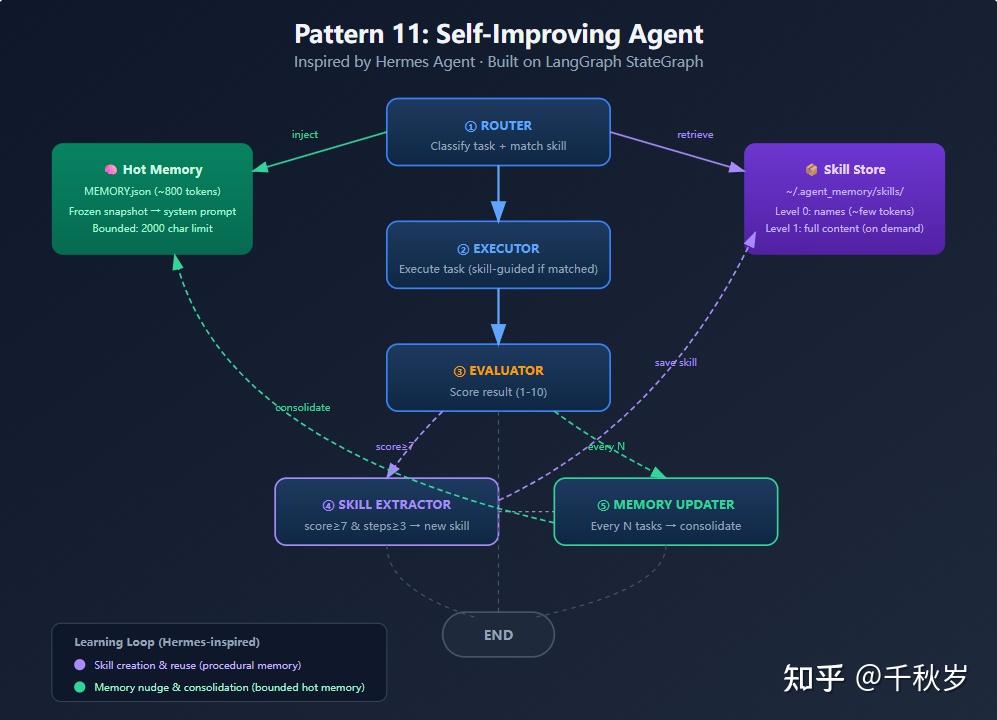
一、Hermes 的核心设计:四层记忆 + 学习闭环
1.1 四层记忆架构
传统 Agent 的做法是把所有历史对话塞进 context window。问题很明显——token 线性增长,几轮对话后要么截断(丢失信息),要么全塞(费钱且注意力稀释)。
Hermes 的解法是把记忆按访问频率进行分层,和计算机的 CPU缓存/内存/磁盘 是完全相同的思路:
| 层级 | 存储 | 大小 | 加载时机 |
|---|---|---|---|
| Layer 1 | MEMORY.md | ~800 tokens | 每次对话开始,冻结快照注入 system prompt |
| Layer 2 | USER.md | ~500 tokens | 同上,记录用户偏好和沟通风格 |
| Layer 3 | SQLite FTS5 | 无限 | 按需检索,"上周讨论的 X 是什么?" |
| Layer 4 | Skills/ | 渐进加载 | Level 0 只加载名称(~3k tokens),Level 1 按需加载全文 |
这样设计有几点好处:
- 有界热记忆:MEMORY.md 限制 2200 字符,满了必须先整合再添加、跟 Claude Code 相反,当然这肯定不是 bug,而是 feature——强制记忆保持高信噪比。
- 渐进式技能加载:643+ 个 skill 不可能全塞进 context window,所以默认只看名字,匹配到才加载全文。
- 冻结快照:session 开始时冻结记忆快照,避免高频 LLM 调用时每次都重建 system prompt,配合 Anthropic 的 prompt caching 省 token。
1.2 学习闭环
任务完成 → 评估质量 → 高分(≥7) + 复杂(≥5步)
↓
提取方法为 Skill Markdown
↓
下次遇到类似任务 → 加载 Skill 指导执行
↓
根据新结果更新 Skill(自我改进)每15个任务触发一次 Periodic Nudge:Agent 全局评估自己的记忆,整合重复条目,清理过期信息。
核心在于:Hermes 记住的是方法,而不是事实。它把成功的工作流转化为可复用的程序,这就是所谓的 Procedural Memory(程序性记忆)。
二、LangGraph 实现:Self-Improving Agent
我用 LangGraph StateGraph 实现了这个模式,5个节点:
Router → Executor → Evaluator → Skill Extractor → Memory Updater2.1 核心 State 定义
class AgentState(TypedDict):
messages: Annotated[list, add_messages]
task: str
task_type: str
matched_skill: Optional[dict] # 从 Skill Store 检索到的技能
execution_steps: list[str] # 执行步骤记录
result: str
evaluation_score: float # 1-10 质量评分
should_create_skill: bool # 是否需要提取技能
should_update_memory: bool # 是否触发记忆整合
task_count: int # 任务计数器(控制 nudge 频率)2.2 MemoryStore:双层持久化
class MemoryStore:
"""
Layer 1 - Hot Memory: 有界(2000字符), 每次注入 system prompt
Layer 2 - Skill Store: 渐进加载, JSON markdown 文件
"""
def get_memory_snapshot(self) -> str:
"""冻结快照,注入 system prompt"""
def get_skill_index(self) -> list[dict]:
"""Level 0: 只返回名称和描述"""
def get_skill(self, name: str) -> dict:
"""Level 1: 加载完整技能内容"""
def save_skill(self, skill: dict):
"""保存新技能或更新已有技能"""
def consolidate_memory(self, entries: list[str]):
"""Nudge: 整合记忆,替换所有条目"""2.3 关键条件边:什么时候触发技能提取?
should_create = (
score >= 7.0 # 高质量完成
and num_steps >= 3 # 非平凡任务(至少3步)
and not state["matched_skill"] # 没有使用已有技能(避免重复创建)
)这直接借鉴了 Hermes 的设计:只有"足够复杂"且"做得足够好"的任务才值得提取为技能。Hermes 用的阈值是 5+ tool calls,我这里简化成 3 步,当然可以按需设置。
2.4 Skill 的数据结构
{
"name": "python_code_review",
"description": "Review Python code for bugs, security issues, and style",
"task_type": "code_review",
"procedure": "1. Check for security issues...\n2. Check logic bugs...\n3. Check performance...",
"pitfalls": "Don't just look at syntax, check for race conditions in async code",
"verification": "Ensure every finding has a concrete fix suggestion",
"use_count": 3,
"avg_score": 8.2
}这里需要注意三个字段:
- procedure — 核心,记录的是方法不是结论。"先查安全→再查逻辑→最后看性能",这个执行顺序本身就是知识。
- pitfalls — 记录踩过的坑,防止下次犯同样的错。
- verification — 怎么验证结果是对的。没有这个字段,skill 就只是一堆指令,没有质量保障。
2.5 Skill 的复用与自我改进
在 Executor 节点,匹配到的 skill 会被注入到 prompt 中引导执行:
def executor(state: AgentState) -> AgentState:
skill_guidance = ""
if state.get("matched_skill"):
skill = state["matched_skill"]
skill_guidance = f"""
You have a relevant skill to guide you:
Procedure: {skill['procedure']}
Pitfalls to avoid: {skill['pitfalls']}
Verification: {skill['verification']}
"""
# skill_guidance 注入 prompt,引导 LLM 按已验证的方法执行这里并不是硬编码——LLM 仍然可以偏离 skill 的步骤。但有了 skill 指导,输出质量和一致性会显著提高。
当已有技能被复用时,根据新评分更新统计:
def update_skill_stats(self, skill_name: str, score: float):
skill["use_count"] += 1
skill["avg_score"] = running_average(old_avg, new_score)低分技能自然淘汰(Router 优先匹配高分技能),高分技能持续强化——简化版"自然选择"。
三、与 Hermes 原版的对比
| 特性 | Hermes Agent | AgentFlow 实现 |
|---|---|---|
| 记忆层数 | 4层 + 可插拔外部 provider | 2层(Hot Memory + Skill Store) |
| 技能格式 | http://agentskills.io Markdown 标准 | JSON(更适合程序化处理) |
| 技能加载 | 渐进式 Level 0/1/2 | 简化版 Level 0/1 |
| Nudge 频率 | 每15个任务 | 可配置(默认5) |
| 编排引擎 | 同步单循环 (run_agent.py) | LangGraph StateGraph(声明式) |
| User Modeling | Honcho 辩证用户建模 | 未实现(可扩展) |
关键差异:Hermes 是一个完整产品(9200行核心代码),而我的实现是一个可组合的设计模式(~300行),可以嵌入到任何 LangGraph 项目中。
四、适用场景
- 重复性知识工作:代码审查、数据分析、报告生成——做过一次的事不应该从零开始
- 个人 AI 助手:积累用户偏好,越用越懂你
- 自动化运维:把排障流程沉淀为技能,新人也能用
- 教育场景:Agent 记住学生的薄弱点,调整教学策略
五、如何集成到你的项目
from self_improving_agent import create_self_improving_agent
agent = create_self_improving_agent(
llm=your_llm,
storage_dir="./my_agent_memory",
nudge_interval=10,
skill_threshold=7.0,
)
result = agent.invoke({
"messages": [HumanMessage(content="你的任务")],
"task": "你的任务",
"task_type": "",
"matched_skill": None,
"execution_steps": [],
"result": "",
"evaluation_score": 0,
"should_create_skill": False,
"should_update_memory": False,
"task_count": current_count,
})六、总结
Hermes Agent 最值得学习的不是它的40+工具,而是它的架构思想:
- 有界热记忆 > 无限上下文窗口——强制高信噪比
- 程序性记忆 > 陈述性记忆——记住方法,不是事实
- 渐进式加载 > 全量注入——用 token 预算换技能规模
- 周期性自省 > 被动积累——定期整理才能保持记忆质量
这些原则适用于任何 Agent 系统,不仅仅是 Hermes。

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐



 7
7 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)