企业级AI知识引擎:05音频语音识别
·
音频语音识别——本地离线转文字,构建私人智库
信息爆炸时代,声音是最自然的表达,却最难高效利用。
会议记录、采访录音、灵感碎片散落各处,如沉睡的金矿。
一套私密、可控的离线方案,能将任意音频转化为可搜索、可沉淀的文本资产,汇聚为私人智库。
企业级AI知识引擎:05音频语音识别
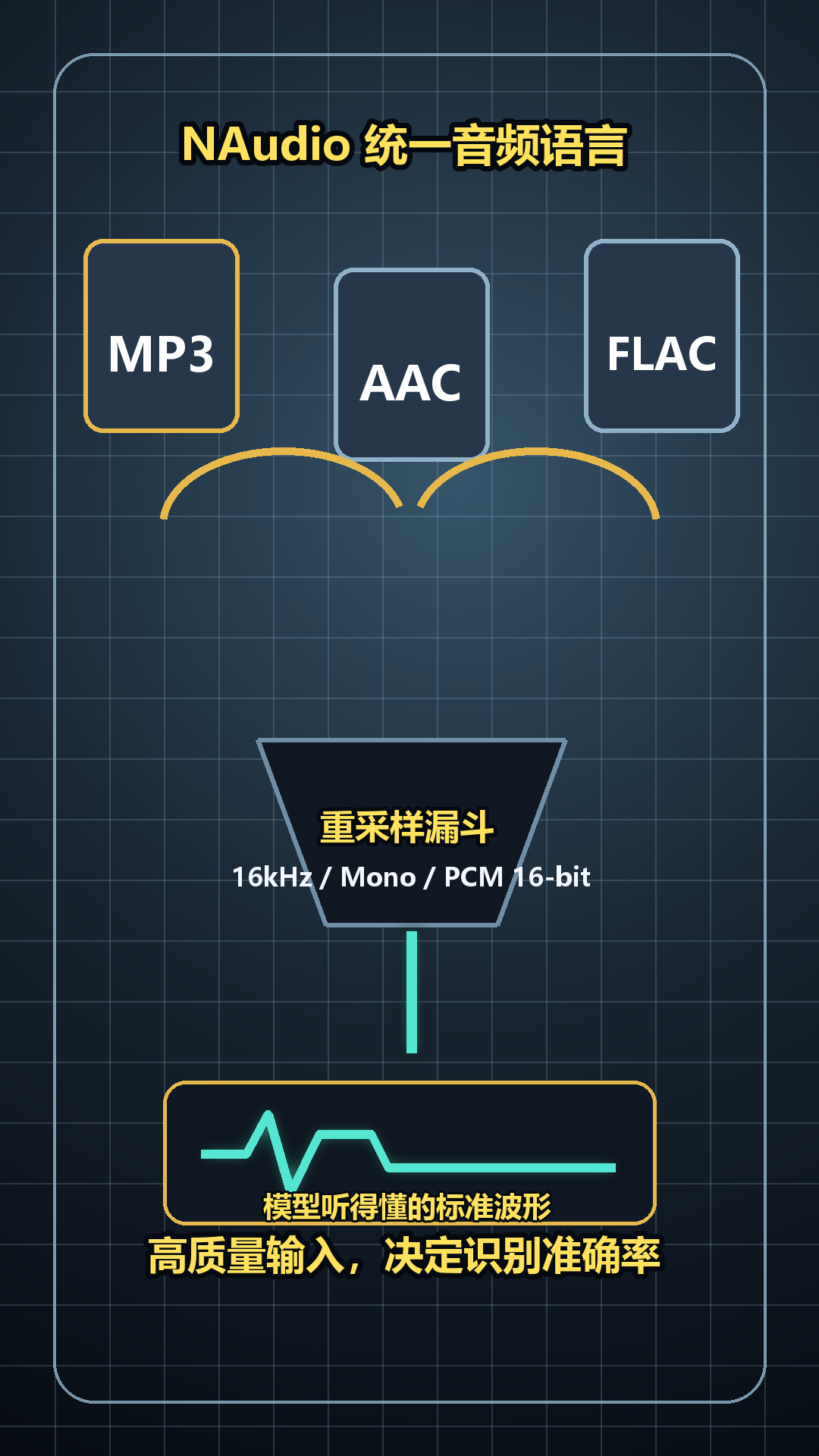
第一步:音频格式统一
音频格式千差万别,而识别模型有严格输入要求。
本地音频处理库无缝解码常见格式,精准转换采样率,合并声道,统一位深。
这步看似细微,实则是识别精度的关键。
全程本地运行,不依赖云端,完全掌控数据流。
第二步:离线识别引擎
开源通用语音识别模型,多语言、强抗噪,是本地部署首选。
跨平台调用,完全离线,模型本地加载,隐私零泄露。
支持GPU与CPU加速,输出带时间戳,便于字幕制作。
自动检测语种,甚至翻译外语。
与音频处理形成闭环,内存交互无需落盘,吞吐量极高。
支持实时流式或批量处理,全本地高速运转。
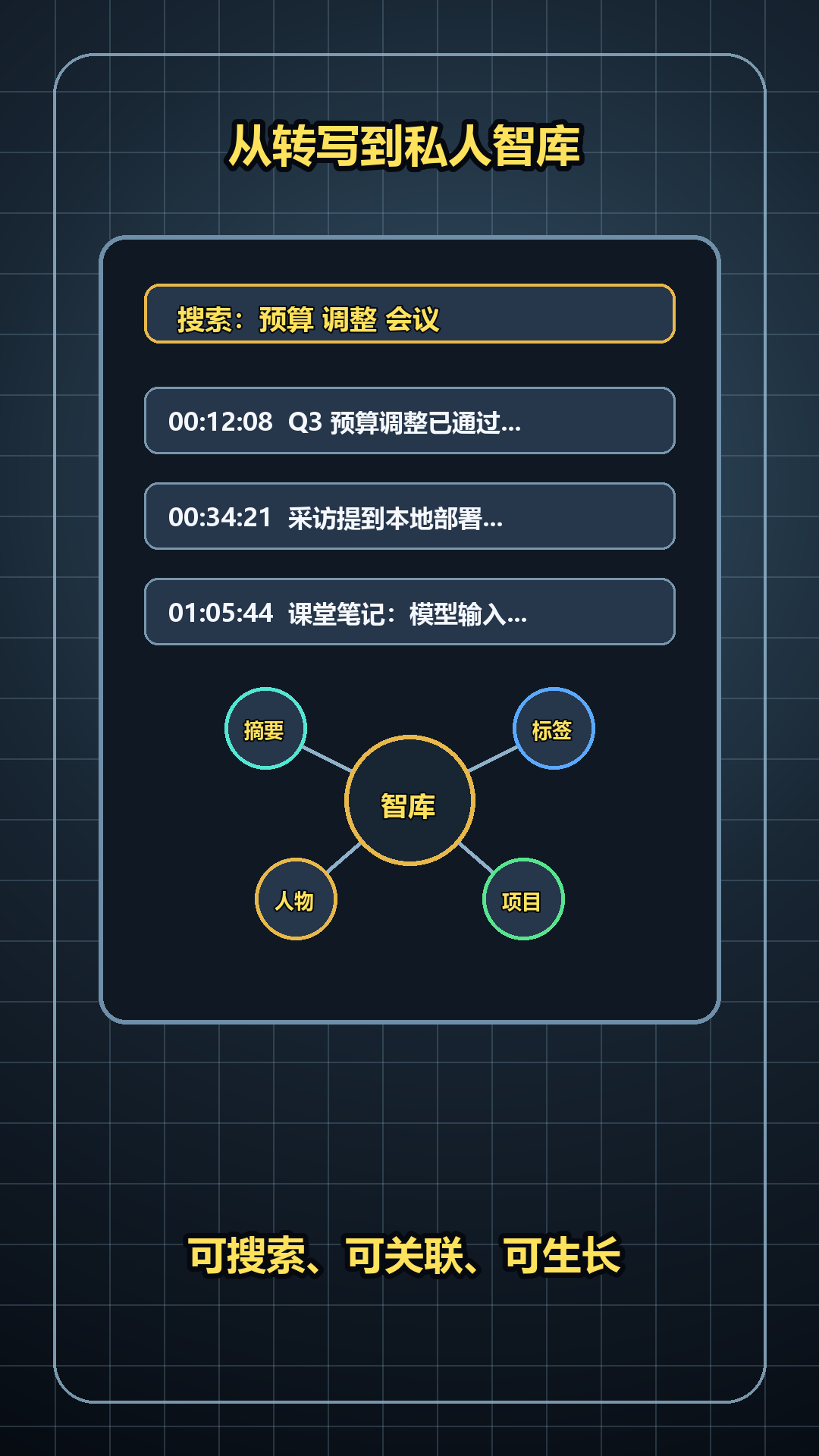
第三步:从转写到智库
转写文本仅存TXT价值有限。
真正的智库,需可搜索、可关联、可生长。
向量化实现语义搜索——问"上周二预算讨论",直接定位音频对应处。
自动生成标签、摘要、知识图谱,零散记录演化为结构化知识。
新录音持续追加,形成声音日记。
这一切基于高质量、带时间戳的转录结果,还可叠加热词字典持续优化。
本地离线优势
隐私第一:敏感内容永不出设备。
成本可控:无分钟计费,一次部署永久使用。
定制自由:可换模型、调参数,完全掌控。
断网可用:无网络环境依然稳定。
用本地工具打磨音频,用离线模型唤醒语音,以智库形式升维碎片化声音。
每段对话精准记录,每份灵感即刻调取。
立即构建离线语音流水线,让声音不再流逝,让智库生根发芽。

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐


 17
17 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)