【Vid llm】VideoLLaMA 3: Frontier Multimodal Foundation Models for Image and Video Understanding
note
- 提出的VideoLLaMA 3通过以视觉为中心的训练范式和框架设计,显著提高了图像和视频理解的性能。该模型在大多数图像和视频理解基准测试中表现出色,特别是在图表理解和数学问题上。
- Any-resolution Vision Tokenization (AVT):采用AVT技术,动态处理不同分辨率的图像和视频,保留了更多细节
- 痛点:
- 视频数据质量太差,但作者认为视频等于一系列的图片,所以可以先学看图再看视频
- 视觉token太多:作者使用Differential Frame Pruner(DiffFP)保留相互差异大的视频帧
- 通过大规模图像理解预训练,VideoLLaMA 3展示了其在视频理解任务中的强大潜力。未来的研究方向包括增强视频-文本数据集、优化实时推理和多模态扩展。
一、研究背景
- 研究问题:这篇文章要解决的问题是如何构建一个更先进的用于图像和视频理解的多模态基础模型。具体来说,现有的多模态语言模型(MLLMs)在处理视频数据时面临时间动态性和复杂性的挑战。
- 研究难点:该问题的研究难点包括:视频数据通常标注质量较低且多样性有限,难以捕捉视频的时间维度和帧之间的依赖关系;视频数据的计算开销较大,影响实时处理性能。
- 相关工作:该问题的研究相关工作包括图像中心的多模态语言模型(如VisualBERT、LXMERT)和视频中心的多模态语言模型(如Vila、Viameter)。这些模型在各自的领域中取得了一定的进展,但在跨模态理解方面仍存在不足。
二、VideoLLaMA 3
这篇论文提出了VideoLLaMA 3,一种以视觉为中心的多模态基础模型,用于解决图像和视频理解问题。
1、四阶段训练
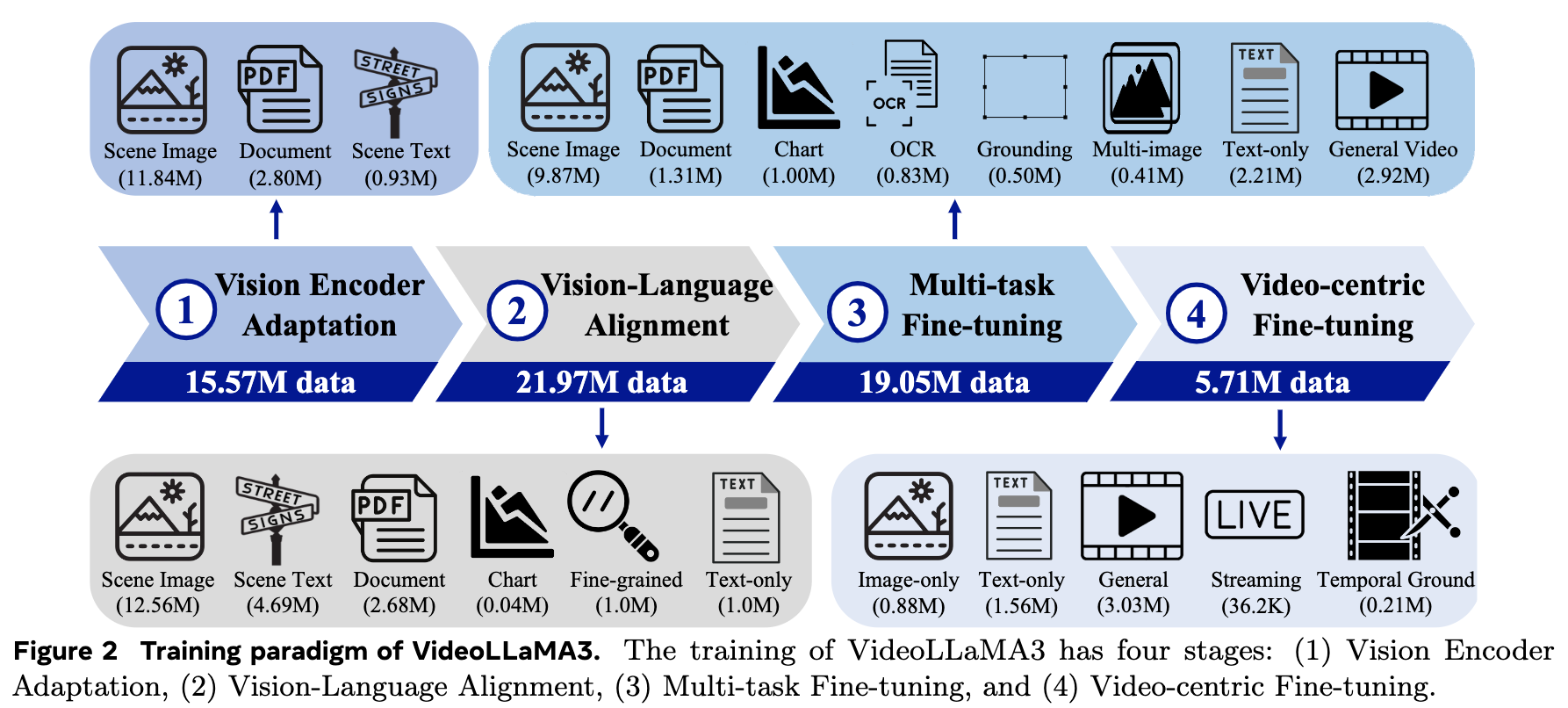
- 视觉编码器适应:首先,将预训练的视觉编码器适应为可以接受可变分辨率的图像输入。通过使用场景图像、文档数据和带文本的场景图像来微调视觉编码器和投影器。
- 视觉-语言对齐:接下来,使用大规模图像-文本数据(包括场景图像、文档、图表和纯文本数据)联合微调视觉编码器、投影器和大型语言模型(LLM),以建立多模态理解的基础。
- 多任务微调:然后,结合图像-文本SFT数据和视频-文本数据对模型进行微调,以准备模型进行视频感知。视频字幕数据也意外地提高了图像理解性能。
- 视频中心微调:最后,进一步微调模型以提高视频理解能力。训练数据包括一般视频、流式视频、带有时间定位信息的视频、纯图像和纯文本数据。
| 阶段 | 干什么 |
|---|---|
| Stage1 | 训练视觉编码器支持任意分辨率 |
| Stage2 | 用海量图文数据建立视觉能力 |
| Stage3 | 图像QA + 少量视频QA |
| Stage4 | 专项强化视频理解 |
视频中心微调对应的微调数据: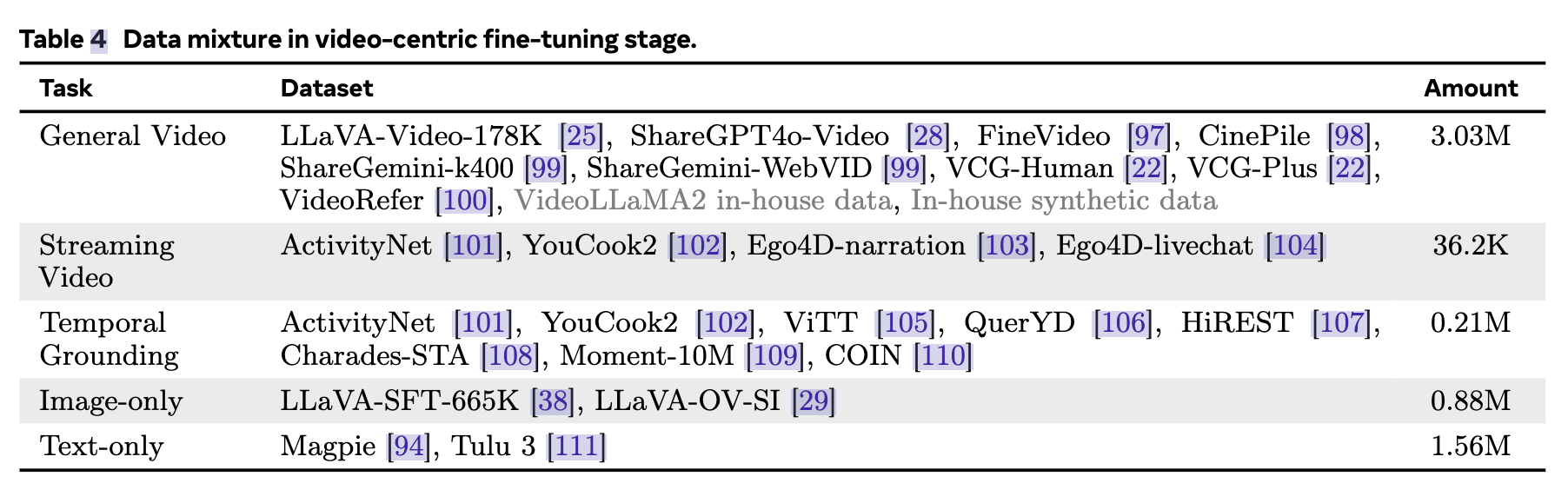
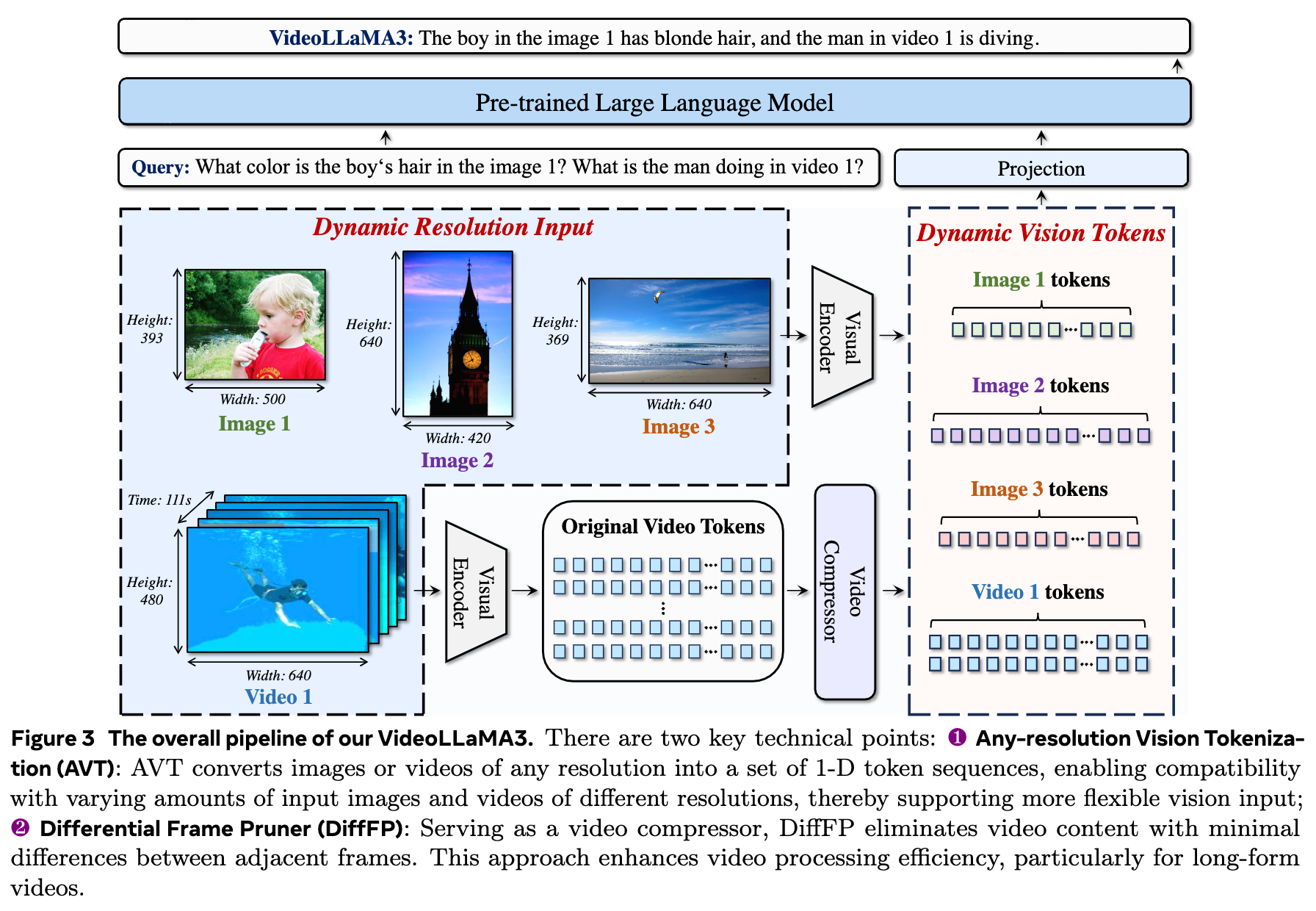
2、模型架构
在模型方面,提出了两种视觉中心的设计:
- Any-resolution Vision Tokenization (AVT):通过替换ViT中的绝对位置嵌入为2D-RoPE,使预训练的视觉编码器能够处理可变分辨率的图像和视频。
- Differential Frame Pruner (DiffFP):通过对视频帧进行2x2空间下采样,减少视频输入的标记数量,从而降低计算需求。
数据格式: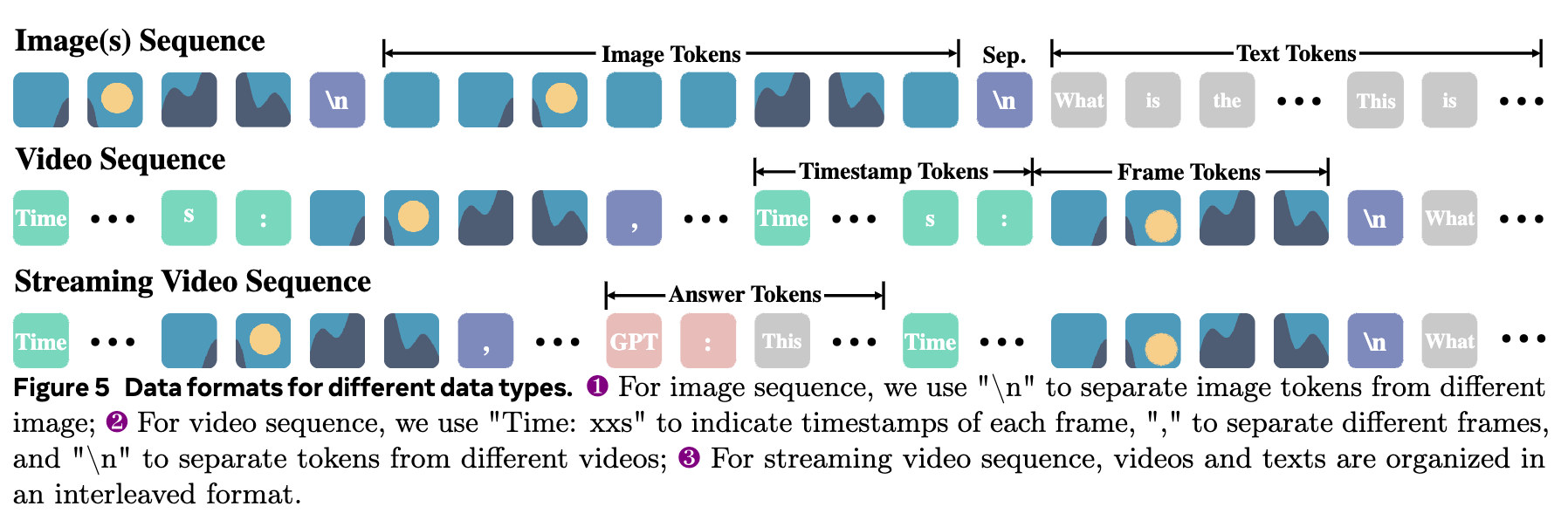
三、实验设计
1、数据收集:构建了一个高质量的重命名图像数据集VL3-Syn7M,所有图像均来自COYO-700M,并通过一系列清洗步骤处理,包括宽高比过滤、美学评分过滤、文本-图像相似性计算、视觉特征聚类和图像重命名。
2、数据混合:根据不同的训练阶段,数据混合如下:
- 视觉编码器适应阶段:使用场景图像、文档识别图像和部分场景文本图像。
- 视觉-语言对齐阶段:使用高质量的图像-文本数据,包括场景图像、场景文本图像、文档、图表和细粒度数据,以及大量高质量的纯文本数据。
- 多任务微调阶段:使用多样化的多模态问答数据,包括图像和视频问答,以及一般视频字幕数据。
- 视频中心微调阶段:使用一般视频、流式视频、带有时间定位信息的时间和一般视频字幕数据。
3、实现细节:采用余弦学习率调度器,最大令牌长度设置为16384,视觉令牌的最大长度设置为10240。在视觉编码器适应阶段,初始化视觉编码器为SigLIP的预训练权重,LLM为Qwen2.5-2B的预训练权重。后续阶段的参数设置如下:LLM、投影器和视觉编码器的学习率分别为1.0x10-5、1.0x10-5和2.0x10^-6。
三、结果与分析
图像理解基准测试:VideoLLaMA 3在大多数图像理解基准测试中表现出色,特别是在图表理解和与视觉相关的数学问题上,显著超越了现有最先进的模型。例如,在InfoVQA基准测试中,VideoLLaMA 3的得分为69.4%,比之前的最佳得分高出4.9%。
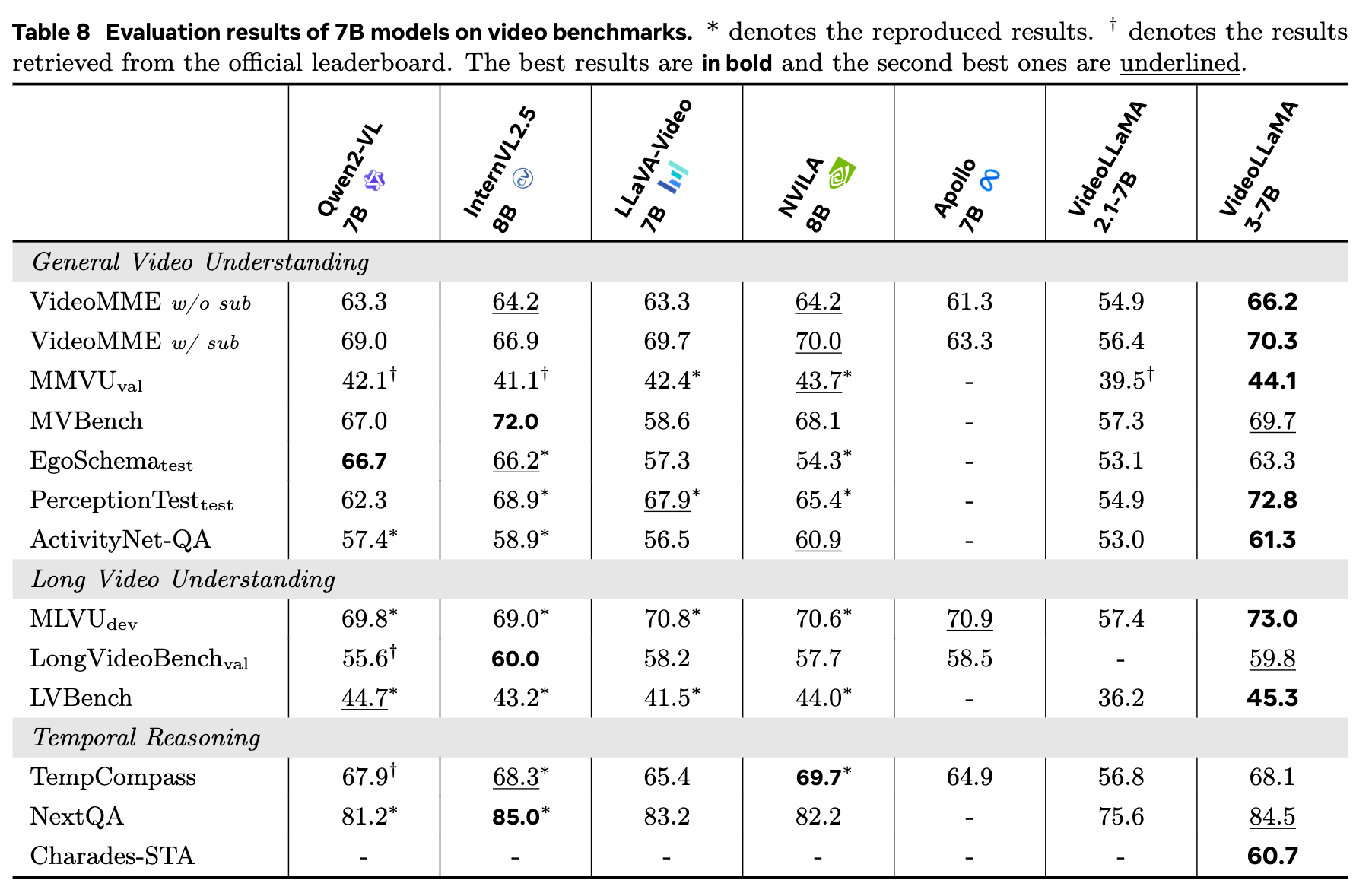
视频理解基准测试:VideoLLaMA 3在大多数视频理解基准测试中也表现出色,特别是在一般视频理解、长视频理解和时间推理任务上。例如,在VideoMME w/ sub基准测试中,VideoLLaMA 3的得分为63.4%,比之前的最佳得分高出3.9%。
案例研究:通过多个案例研究展示了VideoLLaMA 3在图表图像理解、OCR和文档理解、多图像理解以及一般图像和视频理解方面的强大能力。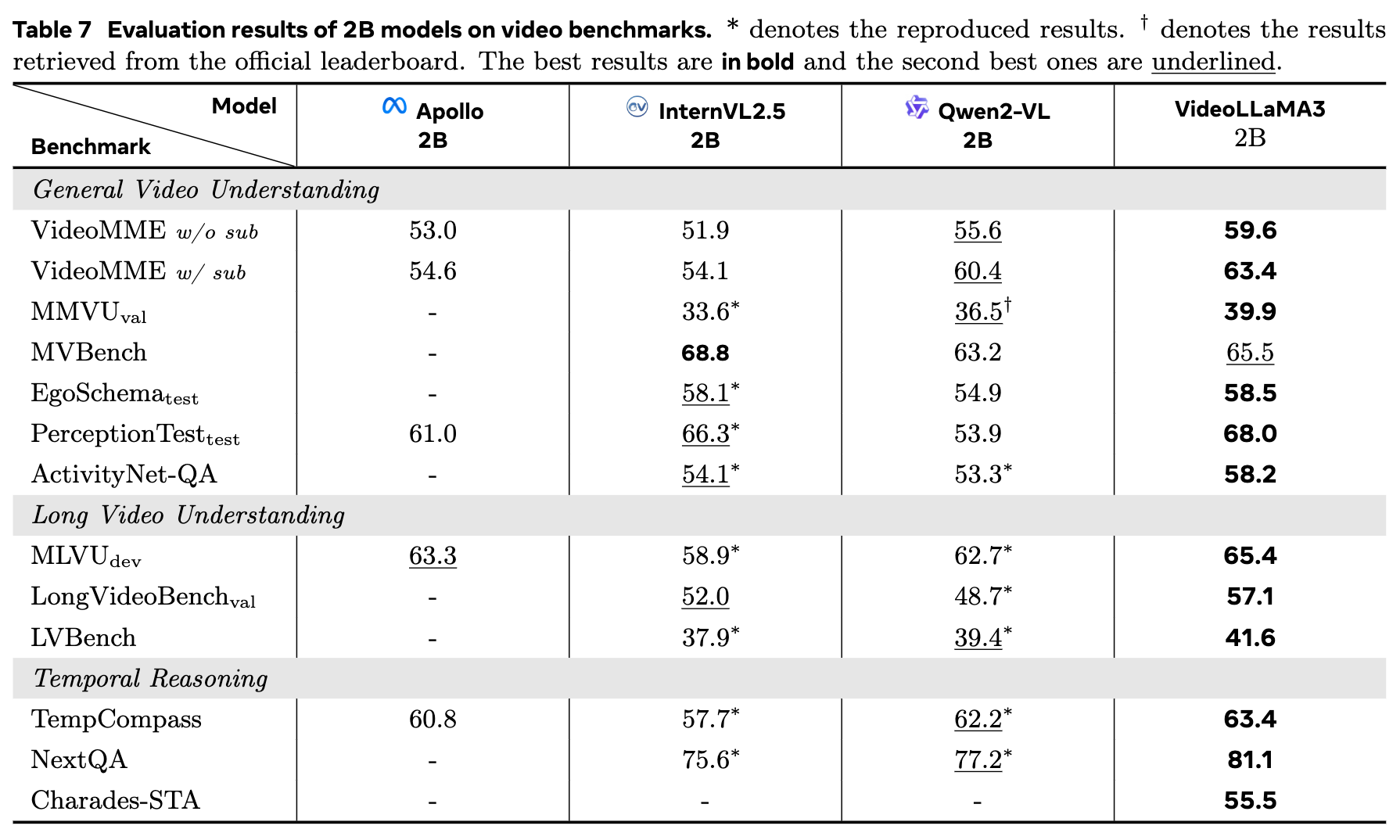
在benchmark效果:
- 一般视频理解:在VideoMME w/ sub基准测试中,VideoLLaMA 3的得分为63.4%,比之前的最佳得分高出3.9%。
- 长视频理解:在MLVU-dev基准测试中,VideoLLaMA 3的得分为65.4%,展现了其处理长视频内容的能力。
- 时间推理:在TempCompass基准测试中,VideoLLaMA 3的得分为63.4%,显示出其在时间推理任务上的优势。
Reference
[1] VideoLLaMA 3: Frontier Multimodal Foundation Models for Image and Video Understanding

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐

 11
11 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)