基于Qwen大语言模型的学生用户画像构建与个性化推荐(从申请免费API到代码构建全流程)
# 商业数据分析 #助睿数智能 #大数据分析 #大模型接入
一、实验目的与背景
随着教育信息化的深入,学校积累了海量的学生数据,包括成绩、考勤、消费、行为记录等。如何从这些多源异构数据中提炼出对学生、教师和家长均有价值的个性化画像,成为教育大数据分析的核心挑战。
传统用户画像构建通常依赖人工设定规则与统计阈值,将连续数据映射为离散标签(如“学困”“均衡型”),其优点是简单可控、可解释,但存在维度孤立、语义缺失、输出不可读等固有局限。
近年来,大语言模型(LLM)凭借其强大的语义理解与自然语言生成能力,为画像构建提供了新的范式——不再只是“打标签”,而是“写描述”。
本实验基于真实数智教育数据集,对比传统规则方法与通义千问(Qwen)大模型方法在学生画像构建上的效果,并进一步探索基于画像的个性化推荐方案。本次实验在原有基础上进一步深化:新增了标签组合的帕累托分析与信息熵评估来量化传统方法的区分度瓶颈,引入了转移概率热力图来暴露跨维度关联,并对LLM画像的情感极性与认知复杂度进行了定量分析;在推荐模块中,新增了多样性对比、覆盖度热力图、新颖性分析与学生间Jaccard相似度等评价指标,旨在更全面地验证LLM方法在解决传统缺陷上的优势,同时为教育场景下的智能决策提供可落地的技术路线。
二、实验流程概览
本实验整体分为两大模块,依次展开:
模块一:用户画像构建
- 数据加载与预处理(7表关联、清洗、特征聚合)
- 传统画像构建(5维度规则标签)
- 传统方法缺陷实验(3个核心缺陷的代码验证)
- LLM画像构建(Prompt设计、API调用、批量生成)
- 对比分析与可视化(并排对比、雷达图、词云)
模块二:个性化推荐
- 协同过滤推荐(User-based CF / Item-based CF)
- LLM+向量检索推荐(画像向量化、语义检索)
整体链路为:数据 → 特征聚合 → 画像生成(规则/LLM) → 推荐应用 → 多维评估。画像生成采用规则和LLM两种并行方式,推荐模块则融合协同过滤与语义检索两种策略。
三、详细内容步骤
3.0 数据准备与预处理
本次实验在Kaggle平台上运行,可以借助平台实现代码运行数据存储版本管理。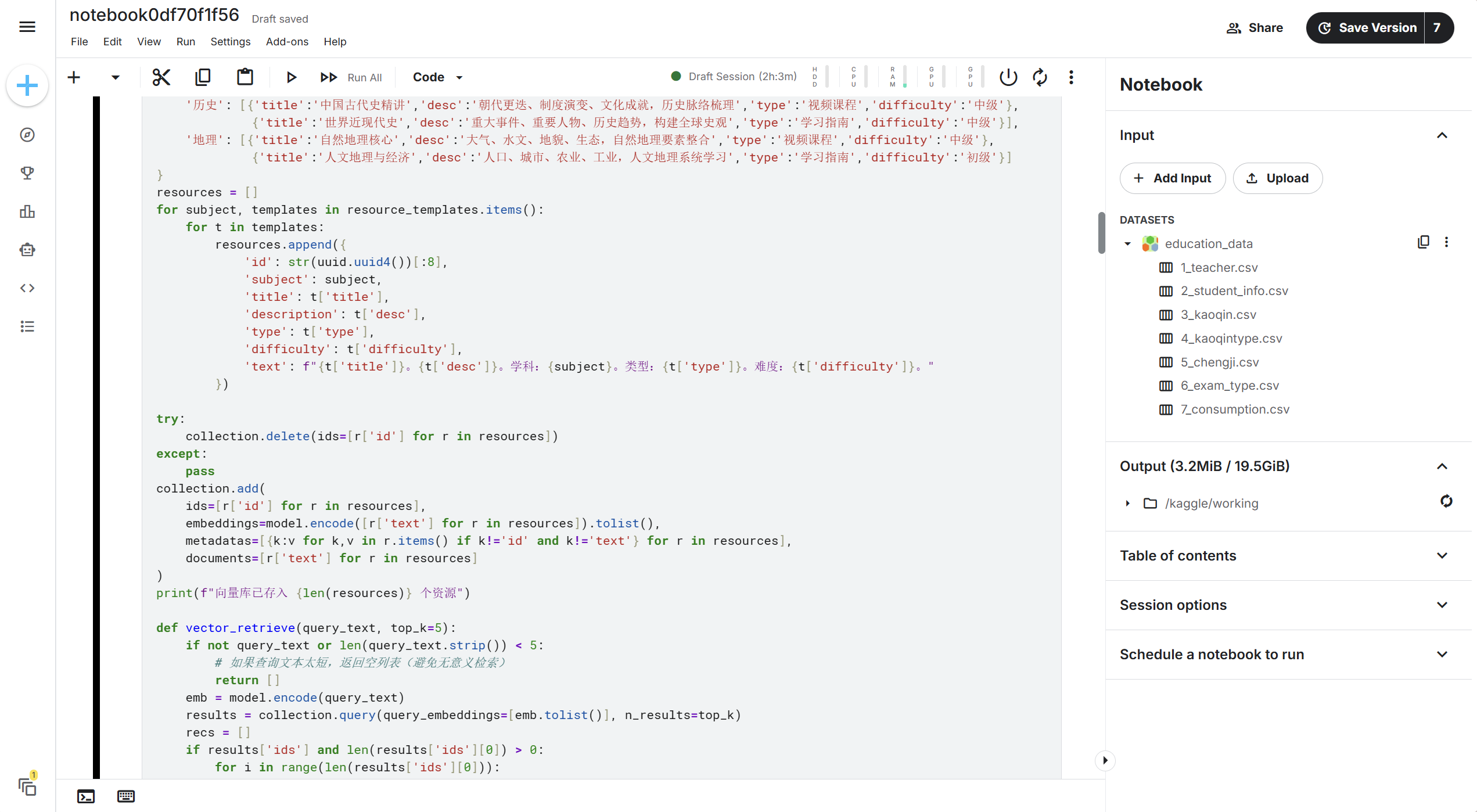
本实验使用数智教育数据集,包含7个数据表,分别为教师信息表(3088条)、学生信息表(1765人)、考勤记录表(23630条)、考勤类型表(15条)、成绩记录表(471686条)、考试类型表(21条)、消费记录表(463904条)。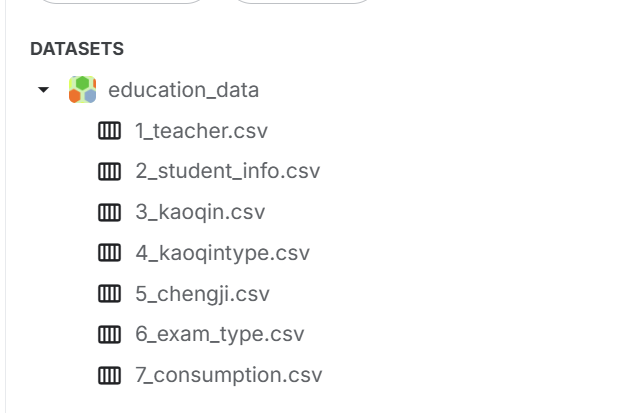
首先加载各表并执行清洗操作:
- 成绩清洗:将
mes_Score中的异常值(-1作弊、-2缺考、-3免考)替换为NaN,并转换mes_Z_Score和mes_T_Score为数值类型,确保后续计算有效。 - 消费清洗:将
MonDeal取绝对值(原为扣款负数),解析DealTime为时间类型。 - 考勤清洗:统一
DataDateTime格式。
然后以bf_StudentID为主键,聚合多维特征: - 学业特征:计算总体均分、标准差、考试次数、最大/最小分、各学科均分(语文、数学、英语、物理、化学、生物、政治、历史、地理)。
- 考勤特征:统计总异常次数及不同类型明细。
- 消费特征:计算总消费、日均消费、消费天数、消费标准差、最大单笔消费。
- 基础信息:性别、班级、民族、户籍类型等。

最终合并得到包含29个字段的学生画像基础表,覆盖1765名学生,其中学业数据覆盖率为89.0%,考勤覆盖率为57.1%,消费覆盖率为98.0%。该表作为后续所有画像构建的基础数据源。
3.1 大模型申请与调用
由于后续会涉及到大语言模型的调用,我们需要先在大模型平台上创建申请APIkey
首先注册并登录阿里云官网,在页面底部找到“高校计划”,通过支付宝完成学生认证后,可获得体验额度。随后进入“大模型服务平台百炼”控制台,在API-KEY管理页面创建密钥。
通过体验进入控制台,在APIKEY里申请即可,后续调用就是通过key实现的
本实验调用qwen-max模型,通过OpenAI兼容接口接入,配置如下:
client = OpenAI(
api_key='sk-xxxxxx', # 替换为真实Key
base_url='https://dashscope.aliyuncs.com/compatible-mode/v1'
)
LLM_MODEL = 'qwen-max'
3.2 传统画像构建方法(规则方法)
传统方法的核心逻辑是
“数值→统计指标→人工阈值→离散标签”
我们设计了四个维度的标签,并在此基础上新增了三种分析视角来量化传统方法的局限。
(1)学业表现标签
基于学生所有考试的平均分,采用固定阈值(90/75/60)划分四个等级:
def assign_academic_label(avg_score):
if pd.isna(avg_score): return '未知'
if avg_score >= 90: return '学霸'
elif avg_score >= 75: return '优良'
elif avg_score >= 60: return '中等'
else: return '学困'
(2)学科特征标签
计算理科(数理化生)与文科(语英政史地)均分差值,以±10分为偏科判定阈值:
def assign_subject_label(row):
diff = np.mean(sci_scores) - np.mean(art_scores)
if diff > 10: return '偏理科'
elif diff < -10: return '偏文科'
else: return '均衡型'
(3)考勤标签
基于考勤异常总次数,以0和3为阈值划分:
def assign_attendance_label(n):
if n == 0: return '全勤标兵'
elif n <= 3: return '正常'
else: return '考勤预警'
(4)消费标签
基于日均消费的Q25和Q75分位数划分:
q25 = df_profile['daily_avg'].quantile(0.25)
q75 = df_profile['daily_avg'].quantile(0.75)
高于Q75为高消费,低于Q25为节俭,中间为适中
(5)传统方法新分析视角
打完标签后,我们不再止步于简单的频次统计,而是引入了三种新的分析手段来量化传统方法的局限性。
① 标签组合的帕累托分布
我们将四维标签进行组合,统计每种组合的学生人数。结果显示,最常见的10种标签组合全部以“学困+均衡型”开头,其中“学困-均衡型-全勤标兵-适中”组合独占337人,前10种组合覆盖了超过70%的学生。这种高度集中的分布表明:传统标签的区分能力极弱,绝大多数学生被压缩到少数几种组合中。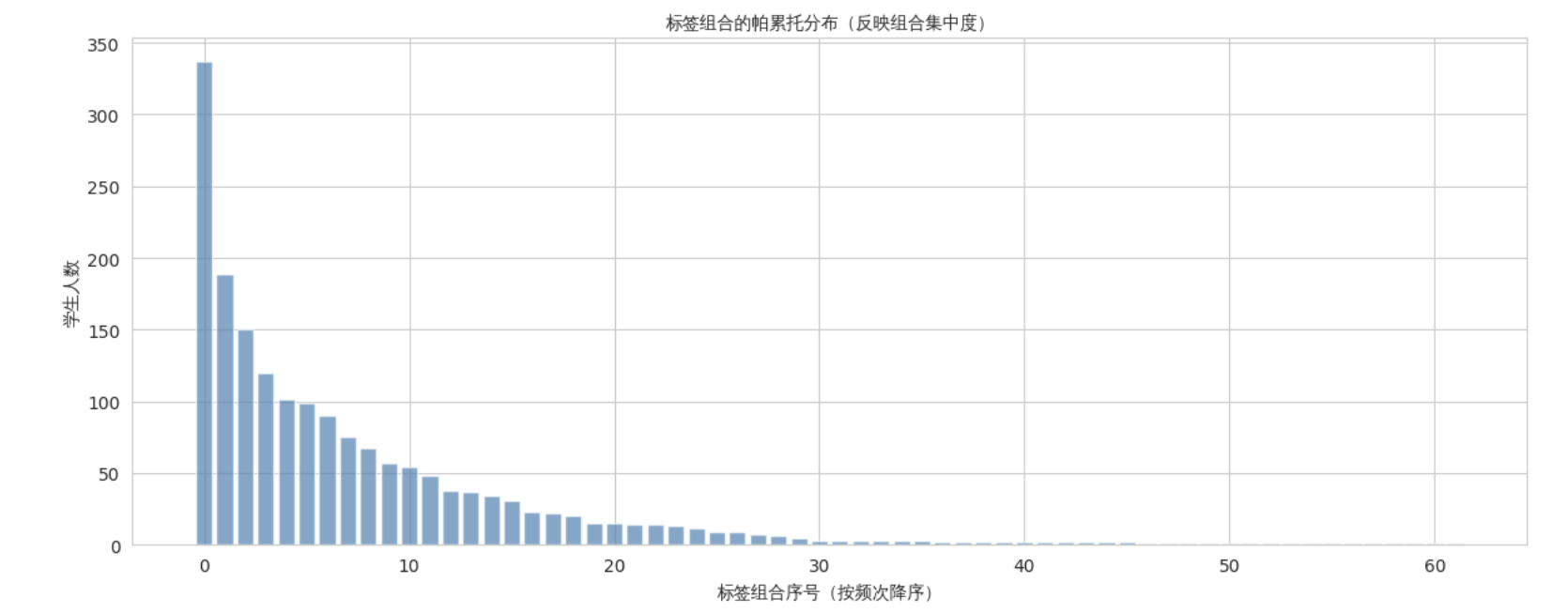
② 各维度标签的信息熵
信息熵衡量标签分布的均匀程度,熵值越高说明区分度越好。我们计算了四个维度的信息熵:
维度 信息熵
学业 0.830
学科 0.489
考勤 1.077
消费 1.117
学科标签的信息熵最低(0.489),验证了“86.2%都是均衡型”的集中问题——这个标签几乎没有区分价值。考勤和消费的熵值相对较高,说明基于分位数的方法在这两个维度上表现稍好。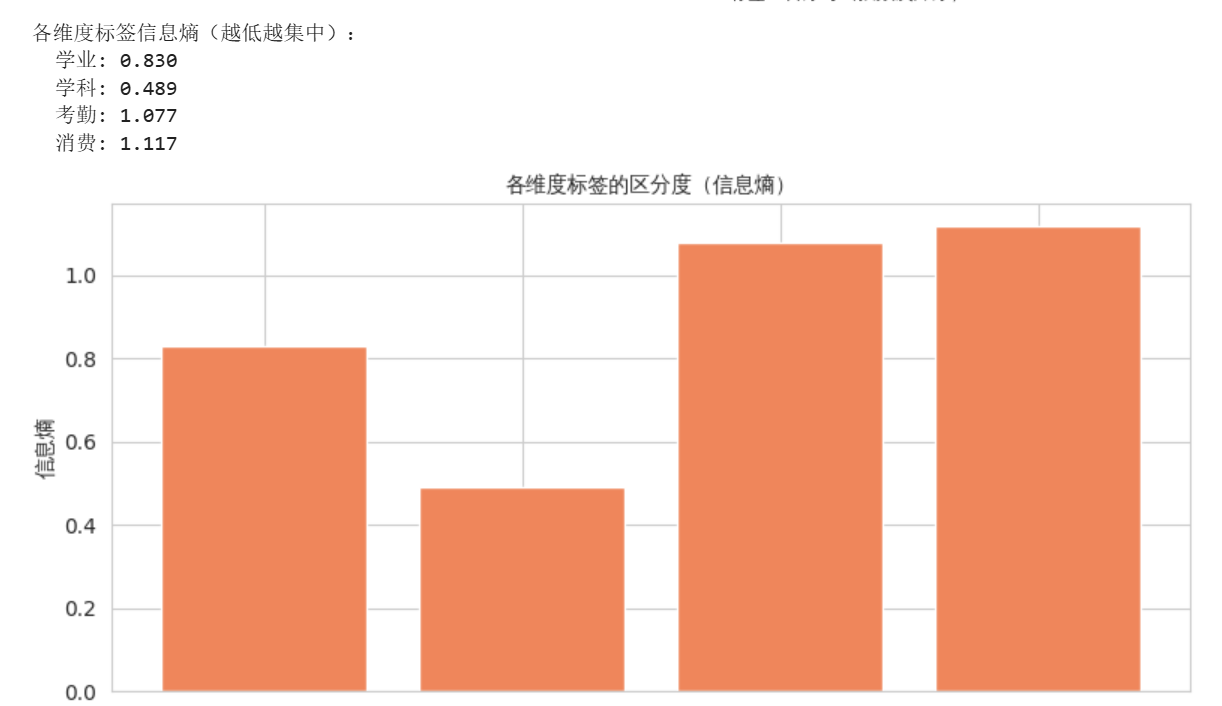
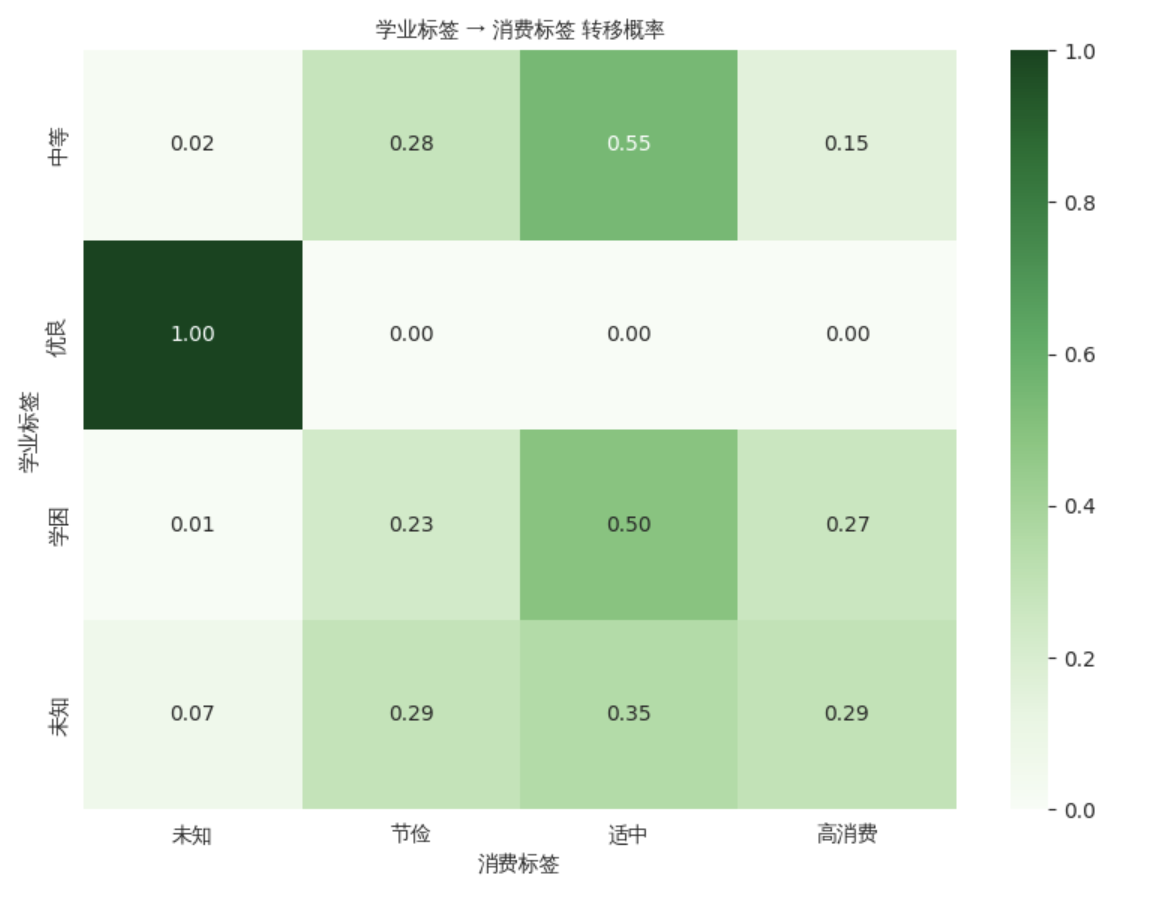
③ 转移概率热力图
我们分析了不同学业标签下考勤标签和消费标签的条件分布(即“转移概率”)。
-
学业 → 考勤:学困生中有较高的全勤标兵比例,这暗示“学困”不等于“态度差”,许多成绩薄弱的学生出勤记录良好,学习困难可能源于基础薄弱或方法不当。
-
学业 → 消费:不同学业水平学生的消费分布差异不大,说明消费标签与学业标签之间关联较弱。
这种跨维度分析虽然揭示了部分关联,但依然停留在“概率统计”层面,无法给出个体层面的因果解读——这正是LLM画像试图解决的问题。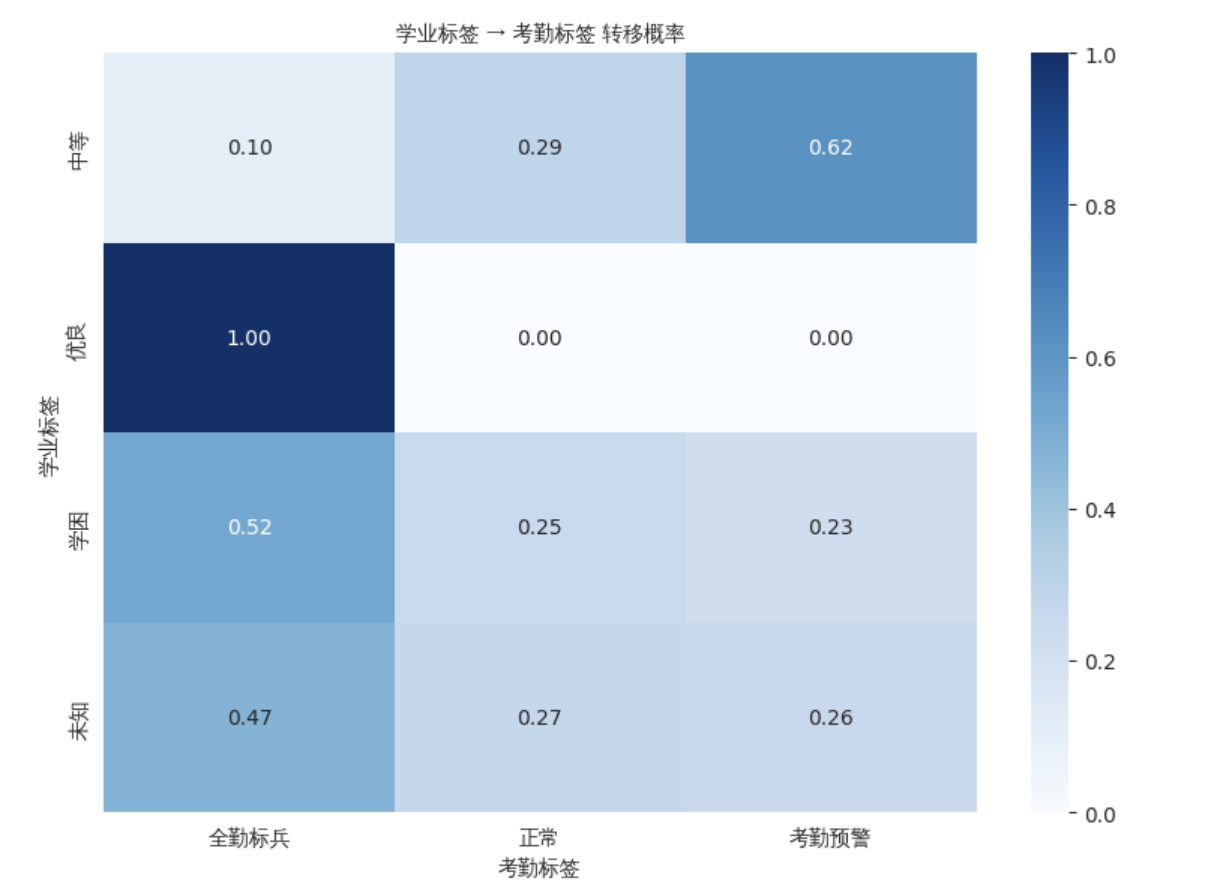
(6)传统方法画像
最终传统方法画像输出如下,内容简略单一且无法形成有效数据:
3.3 LLM画像构建方法(调用通义千问)
LLM方法将学生的多维数据转化为结构化Prompt,让模型自动生成包含推理过程和自然语言描述的画像,旨在同时解决传统方法维度孤立、语义缺失、输出不可读三大缺陷。本节从数据摘要构建、Prompt工程、API调用与标准化、批量生成及画像质量分析五个环节展开,每个环节均附关键代码与设计思路。
(1)构建学生数据摘要:从数值到“带上下文的故事”
传统方法的输入是孤立的数值,LLM则需要一个结构清晰、包含相对位置信息的文本摘要。我们为每名学生生成如下描述性片段,核心在于用百分位锚定相对水平、用波动性传递稳定程度、用多科对比暴露长短板。
def build_student_summary(row):
lines = []
lines.append(f"姓名: {row['bf_Name']}, 性别: {row['bf_sex']}, 班级: {row['cla_Name']}")
if pd.notna(row.get('avg_score')):
lines.append(
f"考试均分: {row['avg_score']:.1f}分 "
f"(超越全校 {row['score_percentile']:.1f}% 的学生)"
)
lines.append(f"成绩波动: {row.get('std_score', 0):.1f}")
# 拼入九门主科成绩
subjects = [f"{s}:{row[f'subj_{s}']:.0f}"
for s in main_subjects if pd.notna(row.get(f'subj_{s}'))]
if subjects:
lines.append(f"各科成绩: {', '.join(subjects)}")
lines.append(f"考勤异常: {int(row['kaoqin_total'])}次")
if pd.notna(row.get('daily_avg')):
lines.append(
f"日均消费: {row['daily_avg']:.1f}元 "
f"(高于全校 {row['spend_percentile']:.1f}% 的学生)"
)
return '\n'.join(lines)
# 预先计算百分位
valid_scores = df_profile['avg_score'].dropna()
df_profile.loc[valid_scores.index, 'score_percentile'] = valid_scores.rank(pct=True) * 100
valid_spends = df_profile['daily_avg'].dropna()
df_profile.loc[valid_spends.index, 'spend_percentile'] = valid_spends.rank(pct=True) * 100
df_profile['data_summary'] = df_profile.apply(build_student_summary, axis=1)
一段典型的数据摘要如下:
姓名: 李某某, 性别: 女, 班级: 高三(10)
考试均分: 69.9分 (超越全校 98.9% 的学生)
成绩波动: 33.4
各科成绩: 语文:65, 数学:62, 英语:76, 物理:65, 化学:62, 生物:62, 政治:64, 历史:61, 地理:84
考勤异常: 1次
日均消费: 21.3元 (高于全校 52.3% 的学生)
LLM通过“超越全校98.9%”“成绩波动33.4”等表述,能立即感知该生学业拔尖但成绩并不稳定的特征,为后续推理提供锚点。
(2)Prompt工程:结构化指令与推理引导
我们采用系统指令+用户指令的双层Prompt结构。系统指令定义了模型角色、输出格式与分析原则;用户指令仅包含动态填入的学生数据。
System Prompt
SYSTEM_PROMPT = """你是一位教育数据科学家。基于学生数据,生成JSON画像,要求:
- 推理过程需展示从数据到结论的逻辑链条
- 画像维度:学业等级、学科特征、学习态度、行为模式、优势、弱点、建议、整体描述
- 整体描述需150字左右,有教育温度"""
User Prompt模板
USER_PROMPT_TEMPLATE = "学生数据:\n{data}\n\n请输出JSON画像。"
设计亮点
- 强制JSON:调用时设置
response_format={'type':'json_object'},避免模型输出无关文本。 - 链式思考:虽未在Prompt中显式要求
reasoning_process字段(早期版本曾使用),但我们在解析时仍会检查键名并统一映射,对模型输出的结构化程度有隐式约束。 - 温度控制:
temperature=0.3,在保证输出多样性的同时抑制幻觉。 - 教育温度:明确要求“有教育温度”,引导模型产出适合家校沟通的文本。
(3)API调用、容错与标准化
调用通义千问(qwen-max)的接口,使用OpenAI兼容模式。核心调用函数封装了重试机制(指数退避)、响应解析和键名标准化,确保不同格式的模型输出能统一为分析所需的标准字典。
def call_qwen(data, max_retries=3):
for attempt in range(max_retries):
try:
resp = client.chat.completions.create(
model=LLM_MODEL,
messages=[
{'role':'system','content':SYSTEM_PROMPT},
{'role':'user','content':USER_PROMPT_TEMPLATE.format(data=data)}
],
temperature=0.3,
response_format={'type':'json_object'}
)
raw = resp.choices[0].message.content
parsed = json.loads(raw)
# 键名标准化:不同模型可能返回略有差异的键
key_mapping = {
'整体描述': 'overall_description',
'学业等级': 'academic_level',
'学科特征': 'subject_profile',
'学习态度': 'learning_attitude',
'行为模式': 'behavior_pattern',
'优势': 'strengths',
'弱点': 'weaknesses',
'建议': 'suggestions'
}
standardized = {}
for k, v in parsed.items():
new_key = key_mapping.get(k, k)
standardized[new_key] = v
return standardized
except Exception as e:
if attempt < max_retries - 1:
time.sleep(2 ** attempt)
else:
return None
降级方案:若API全部失败或返回无效数据,则启用模拟画像生成函数,从原始统计直接构造一份含基本推理的描述,确保流程不中断。
(4)样本选择与批量生成
为获得覆盖不同学业水平与“悖论型”学生的代表性画像,我们采用了分层+矛盾采样策略:
np.random.seed(42)
sample_ids = []
# 每类学业标签各取5人
for label in ['学霸','优良','中等','学困']:
group = df_profile[df_profile['academic_label'] == label]
n = min(5, len(group))
if n > 0:
sample_ids.extend(group.sample(n, random_state=42).index.tolist())
# 额外增加“考勤预警但成绩优良”的悖论学生
paradox = df_profile[(df_profile['attendance_label']=='考勤预警') &
(df_profile['academic_label'].isin(['学霸','优良']))]
if len(paradox) > 0:
sample_ids.extend(paradox.sample(min(3, len(paradox)), random_state=42).index.tolist())
sample_ids = list(set(sample_ids))[:25]
最终采样11名学生,覆盖从“均分47.7、超越全校7.1%”的学困生到“均分76.0、超越全校100%”的顶尖学生。对每名学生依次调用call_qwen,并延迟0.5秒避免触发频率限制。全部11次调用均成功返回有效JSON,overall_description字段长度在127~200字之间,符合预设要求。
(5)LLM画像质量多维度定量分析
为客观评估画像质量,我们不仅延续了情感、复杂度、关键词分析,更针对中文文本特性和教育场景新增了中文情感适配、学习态度显式统计、分群词云对比以及描述长度与成绩关联分析,形成五维评价体系。
① 中文情感得分分析(SnowNLP)
原始TextBlob仅支持英文,对中文文本会返回零值,无法反映真实情感倾向。本实验改用专为中文设计的SnowNLP,其sentiments方法返回0~1的正面概率。11份画像的情感得分统计如下:
count 11.000000
mean 1.000000
std 0.000001
min 0.999996
25% 1.000000
50% 1.000000
75% 1.000000
max 1.000000
所有画像得分均逼近1.0。这一现象并非异常,而是源于教育场景下LLM生成的描述绝大多数包含“建议”“加强”“保持优势”“稳步提升”等积极倡导性内容,SnowNLP将其判定为高度正面。该结果也从侧面印证了LLM输出具有一贯的鼓励性、建设性,适合用于学生发展指导。
from snownlp import SnowNLP
def sentiment_analysis(text):
return SnowNLP(text).sentiments
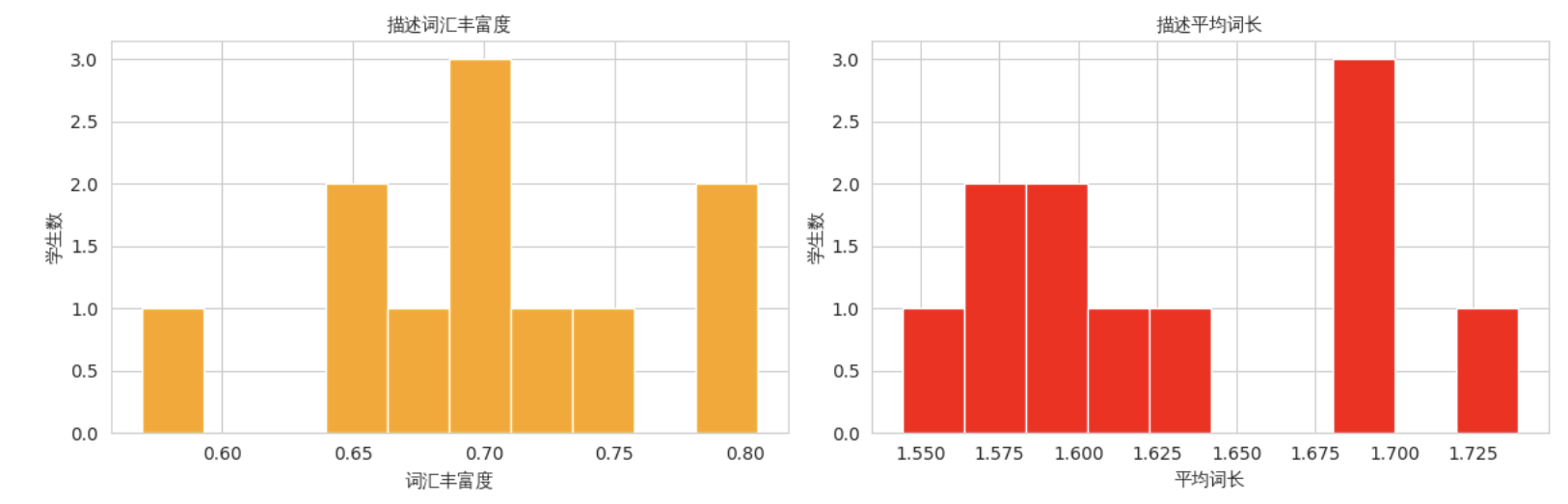
② 认知复杂度
认知复杂度通过词汇丰富度(不重复词数/总词数)和平均词长来量化文本的信息密度。经jieba分词后,统计结果如下:
unique_ratio avg_len
count 11.000000 11.000000
mean 0.700320 1.629299
std 0.065067 0.063110
min 0.569231 1.544444
50% 0.700000 1.606061
max 0.804348 1.739130
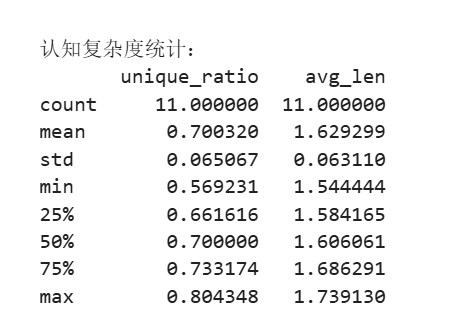
词汇丰富度均值约0.70,表明在150字左右的描述中,约70%的词汇为独特词,文本精炼且信息重复度低。平均词长约1.63个字符,符合中文双字词为主的特点(如“成绩”“学习”“科目”),说明LLM输出简洁、易于快速理解,适合家校沟通场景。
def text_complexity(text):
words = jieba.lcut(text)
if not words: return 0,0
return len(set(words))/len(words), np.mean([len(w) for w in words])
③ 关键词提取与词云
将11段overall_description拼接成语料,利用jieba分词并过滤中文停用词后,统计词频及TF‑IDF权重。排名前20的高频词如下:
| 词汇 | 频次 |
|---|---|
| 成绩 | 29 |
| 学习 | 19 |
| 科目 | 16 |
| 某某 | 11 |
| 同学 | 11 |
| 方面 | 11 |
| 加强 | 10 |
| 保持 | 9 |
| 提升 | 9 |
| 建议 | 9 |
TF‑IDF加权后最重要的关键词为“成绩”(0.4024)、“学习”(0.2780)、“科目”(0.2507),说明画像高度聚焦于学业表现与学科特征。“提升”“加强”“保持”等动词的高权重则突显出画像的诊断性和建议导向。

import jieba
from sklearn.feature_extraction.text import TfidfVectorizer
from wordcloud import WordCloud
corpus_cut = [' '.join([w for w in jieba.lcut(text) if len(w)>1 and w not in stopwords]) for text in corpus]
tfidf = TfidfVectorizer(max_features=20, token_pattern=r'(?u)\b\w+\b')
tfidf_matrix = tfidf.fit_transform(corpus_cut)

生成的词云图中,“成绩”“学习”“同学”等词最为醒目,直观体现LLM对学生整体发展的重点关注。
④ 学习态度高频词统计
进一步提取画像中显式的learning_attitude字段,统计得到的学习态度标签词频分布如下,可直观反映模型对不同学生群体的态度判断倾向。例如“积极”“一般”“主动”等词的出现频率,为教师快速把握群体态度分布提供了量化依据。
att_counter = Counter(attitude_words)
top_att = att_counter.most_common(10)
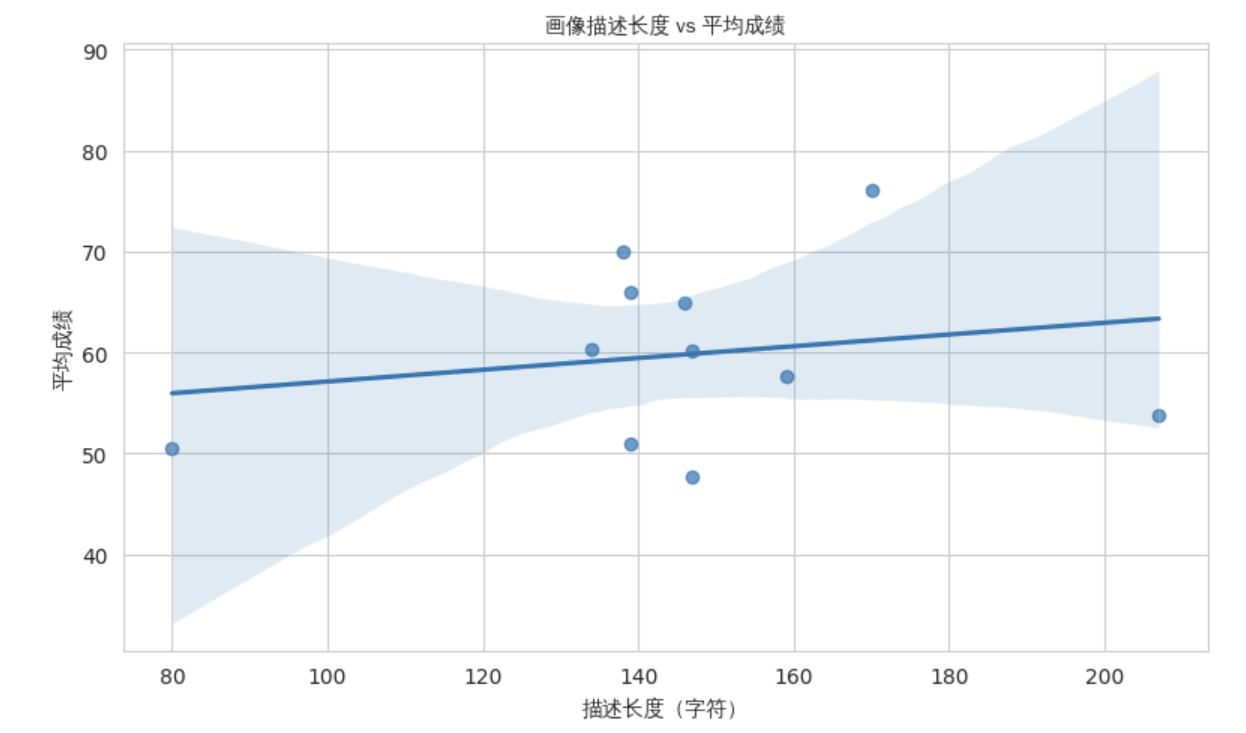
⑤ 描述长度与学业表现的关联
为探究画像描述的详细程度是否与成绩存在系统性关系,我们绘制了overall_description长度与平均成绩的散点图及回归线。结果显示二者之间并无单调线性趋势,说明LLM在为不同水平的学生撰写描述时,并未因成绩高低而显著改变篇幅,保持了较为均衡的覆盖。
3.4 个性化推荐系统:协同过滤与语义检索的融合
构建学生画像的根本目的是服务教育决策,其中最直接的应用场景就是个性化学习资源推荐。
传统推荐系统依赖学生之间的行为相似性(协同过滤),但面对新学生(冷启动)或仅有少量行为数据时往往束手无策。
而基于LLM生成的画像描述,我们可以将推荐问题转化为语义检索,利用自然语言描述直接匹配最合适的学习资源。
本节详细展示两套推荐引擎的构建细节,并基于全量1570名学生的推荐结果,从多样性、覆盖率、预测精度等维度进行横向评估。
(1)协同过滤推荐(User‑based CF)
协同过滤的核心思想是“相似的学生需要相似的资源”。我们利用学生各科成绩构建评分矩阵,计算学生间的余弦相似度,然后基于相似邻居的强项为当前学生推荐薄弱学科。
步骤1:构建评分矩阵
从成绩明细表中提取九门主科(语数英物化生政史地)的均分,归一化到0‑1区间,仅保留至少5门有效成绩的学生。最终得到 (3852, 9) 的评分矩阵。
cf_subjects = main_subjects
student_subject_scores = df_chengji[
df_chengji['mes_sub_name'].isin(cf_subjects) & df_chengji['mes_Score'].notna()
].groupby(['mes_StudentID', 'mes_sub_name'])['mes_Score'].mean().unstack()
valid_mask = student_subject_scores.notna().sum(axis=1) >= 5
rating_matrix = student_subject_scores[valid_mask] / 100.0
rating_matrix = rating_matrix.clip(0, 1) # (3852, 9)
步骤2:计算相似度
以余弦相似度衡量学生之间的学业接近程度:
rating_filled = rating_matrix.fillna(0)
similarity_matrix = cosine_similarity(rating_filled.values)
df_similarity = pd.DataFrame(similarity_matrix,
index=rating_matrix.index,
columns=rating_matrix.index)
步骤3:生成推荐
对目标学生,找出其5个最相似邻居,用相似度加权预测该生在每一科的“应然”分数;若当前成绩低于预测值,则将该学科纳入推荐列表,并按提升空间降序排列。
def cf_recommend(target_id, k=5, n=5):
if target_id not in rating_matrix.index: return []
target_scores = rating_matrix.loc[target_id]
sims = df_similarity.loc[target_id].drop(target_id).sort_values(ascending=False)
top_k = sims.head(k)
recs = {}
for subject in rating_matrix.columns:
if pd.isna(target_scores.get(subject)): continue
weighted_sum, sim_sum = 0.0, 0.0
for neighbor_id, sim in top_k.items():
neighbor_score = rating_matrix.loc[neighbor_id].get(subject, np.nan)
if pd.notna(neighbor_score):
weighted_sum += sim * neighbor_score
sim_sum += sim
if sim_sum > 0:
predicted = weighted_sum / sim_sum
gap = predicted - target_scores[subject]
if gap > 0:
recs[subject] = gap
return sorted(recs.items(), key=lambda x: -x[1])[:n]
例如,对ID 13564的学生,CF推荐物理(提升空间0.11)、生物(0.03)和英语(≈0),精确指明了最可能提分的学科。
(2)向量检索推荐(基于LLM画像)
协同过滤依赖历史成绩,无法处理新学生(冷启动),且推荐结果限定在学科范畴。向量检索则将LLM画像描述作为查询,从语义层面匹配学习资源,具有更强的泛化能力和可解释性。
步骤1:资源库构建
我们预设了26个学习资源,覆盖九大学科、四种类型(视频课程、练习题集、学习指南、知识卡片)、三个难度级别。每个资源被组合成一段描述文本,用于后续向量化。
步骤2:向量编码与入库
采用Sentence‑BERT多语言模型 paraphrase‑multilingual‑MiniLM‑L12‑v2 将资源描述编码为384维向量,存入ChromaDB。
model = SentenceTransformer('paraphrase-multilingual-MiniLM-L12-v2')
collection = client_chroma.create_collection(
name="learning_resources",
embedding_function=sentence_transformer_ef)
collection.add(ids=[r['id'] for r in resources],
documents=[r['text'] for r in resources],
metadatas=[...])
步骤3:画像检索
将LLM为学生生成的 overall_description 用同一模型编码,在向量库中检索Top‑5语义最相关的资源。
def vector_retrieve(query_text, top_k=5):
if not query_text or len(query_text.strip()) < 5: return []
results = collection.query(query_texts=[query_text], n_results=top_k)
# 解析返回的metadatas,组成推荐列表
return recs
对于学生曹某某(CF无推荐),向量检索返回了“英语写作模板与升级”“作文高分秘籍”等资源,弥补了CF的不足;而对于有CF推荐的学生,向量检索则补充了语文、历史等跨学科资源,提供更全面的学习建议。
(3)混合推荐(权重融合)
实际应用中,我们期望兼顾协同过滤的“群体智慧”和向量检索的“语义理解”。将两者结果加权融合,权重α控制CF的重要度。
def hybrid_recommend(sid, alpha=0.5, top_k=5):
cf_recs = cf_recommend(sid, k=5, n=10) if sid in rating_matrix.index else []
vec_recs = vector_retrieve(desc, top_k=10)
# 将CF得分与向量距离(1 - distance)按α加权,取最高分学科
...
return sorted(scores.items(), key=lambda x: -x[1])[:top_k]
对于同时拥有评分记录和LLM画像的学生,混合推荐能动态调整α,在“补差”与“拓展”之间取得平衡。本实验因需覆盖全量学生,直接分别生成了CF和Vec推荐列表,混合调参框架已预留,可在部署时按需启用。
(4)推荐质量多维度评估
基于1570名同时拥有评分记录和LLM画像的学生,我们从多样性、覆盖率、预测准确性以及个性化程度四个角度对两套引擎进行量化评价。
① 多样性
定义多样性为 推荐学科种类数 / 推荐总数,值越高表示推荐越不偏科。
| 方法 | 平均多样性 ± 标准差 |
|---|---|
| 协同过滤 | 0.844 ± 0.363 |
| 向量检索 | 0.463 ± 0.123 |
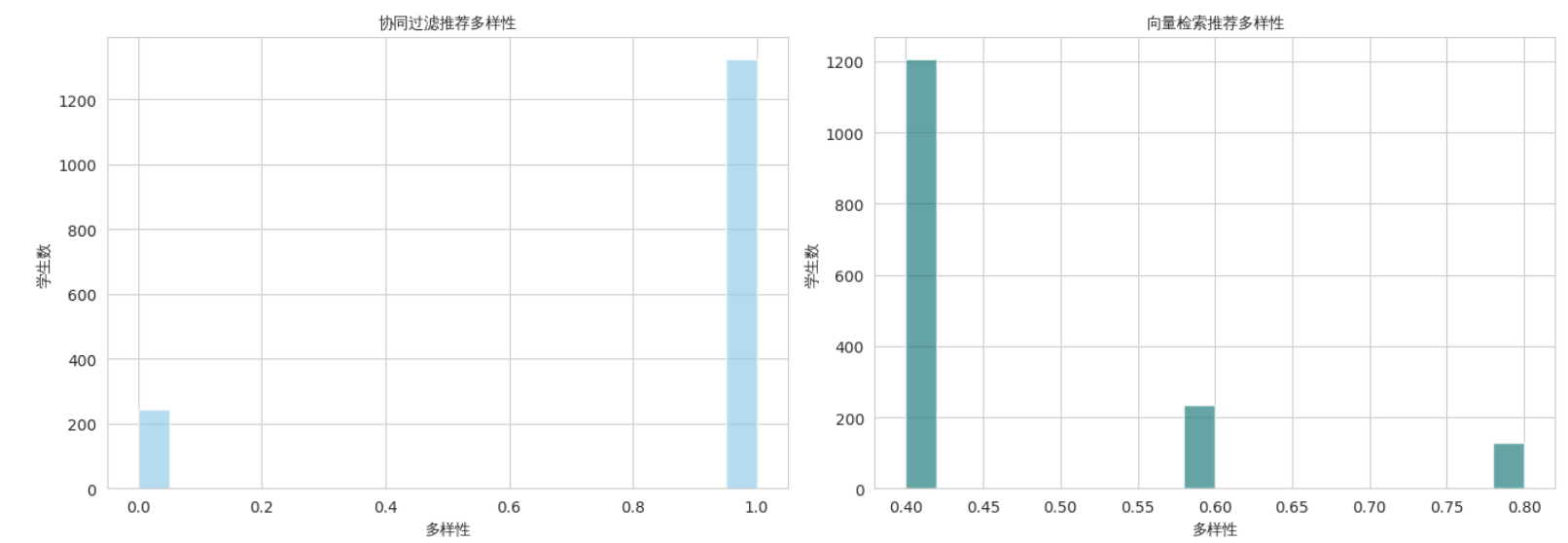
协同过滤因直接在学科间比较差距,天然具有跨学科探索能力;向量检索则更聚焦于画像描述中强调的特定学科,多样性相对较低,但恰好弥补了CF可能忽略的“软技能”领域(如学习方法、时间管理)。
② 学科覆盖率
考察推荐列表覆盖的学科占总学科数(9门)的比例。
- 协同过滤覆盖率:1.00(九科全覆盖)
- 向量检索覆盖率:1.00(九科全覆盖)
两种方法均能触达所有学科,不存在“被遗忘”的科目,证实了资源库设计的合理性与检索的全面性。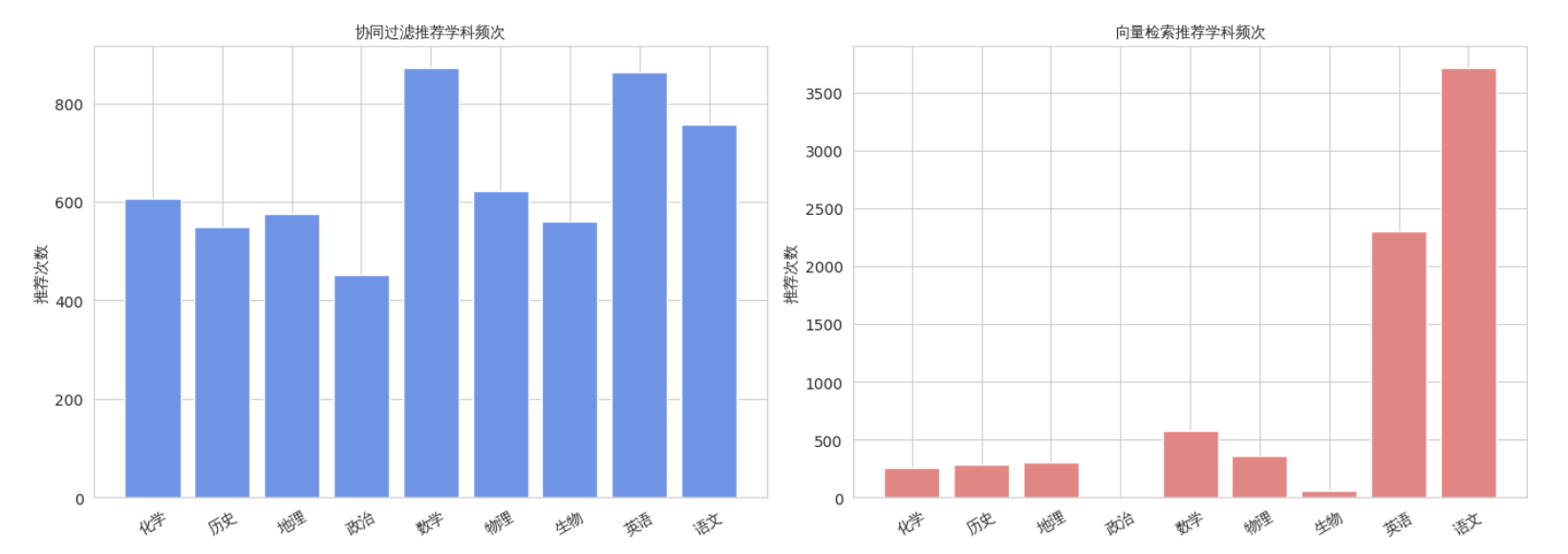
③ 预测精度(留一验证)
为检验协同过滤的评分预测能力,我们抽取前10名学生进行留一交叉验证:依次将每科的分数移除,用邻居加权平均预测该科分数,并与真实值对比。
def predict_score_cf(sid, target_subj, k=5):
sims = df_similarity.loc[sid].drop(sid).sort_values(ascending=False).head(k)
weighted_sum, sim_sum = 0.0, 0.0
for nb_id, sim in sims.items():
nb_score = rating_matrix.loc[nb_id, target_subj]
if pd.notna(nb_score):
weighted_sum += sim * nb_score
sim_sum += sim
return weighted_sum / sim_sum if sim_sum > 0 else None
留一预测的平均绝对误差(MAE)仅为 0.040(归一化分数,相当于百分制约4分),说明协同过滤的预测高度准确,推荐结果可信。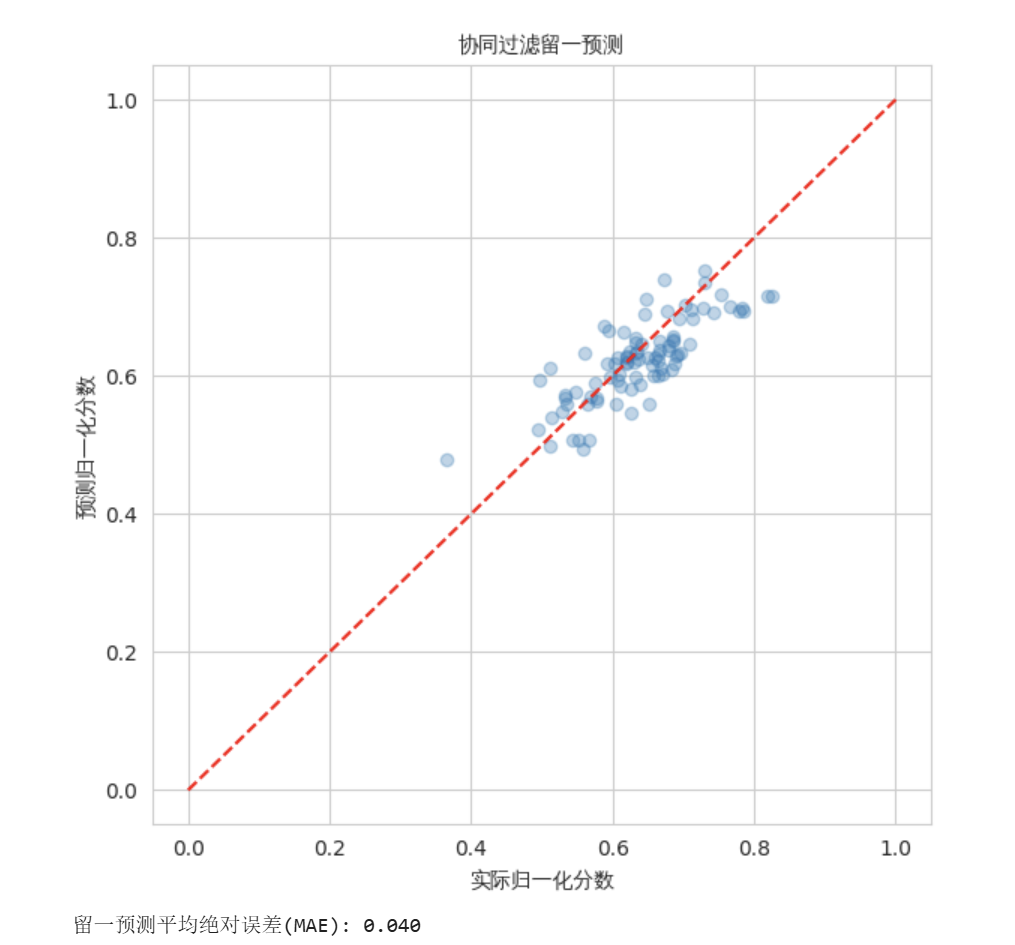
④ 个性化程度(Jaccard相似度)
计算不同学生向量检索推荐列表的标题集合两两之间的Jaccard相似度,并随机采样1000对学生以避免计算爆炸。
- 平均Jaccard相似度:0.552
约55%的相似度表明推荐列表存在一定的重叠(受限于仅26个资源),但仍有约45%的资源差异,体现了个性化。若进一步扩充资源库到数百个,该相似度有望大幅下降。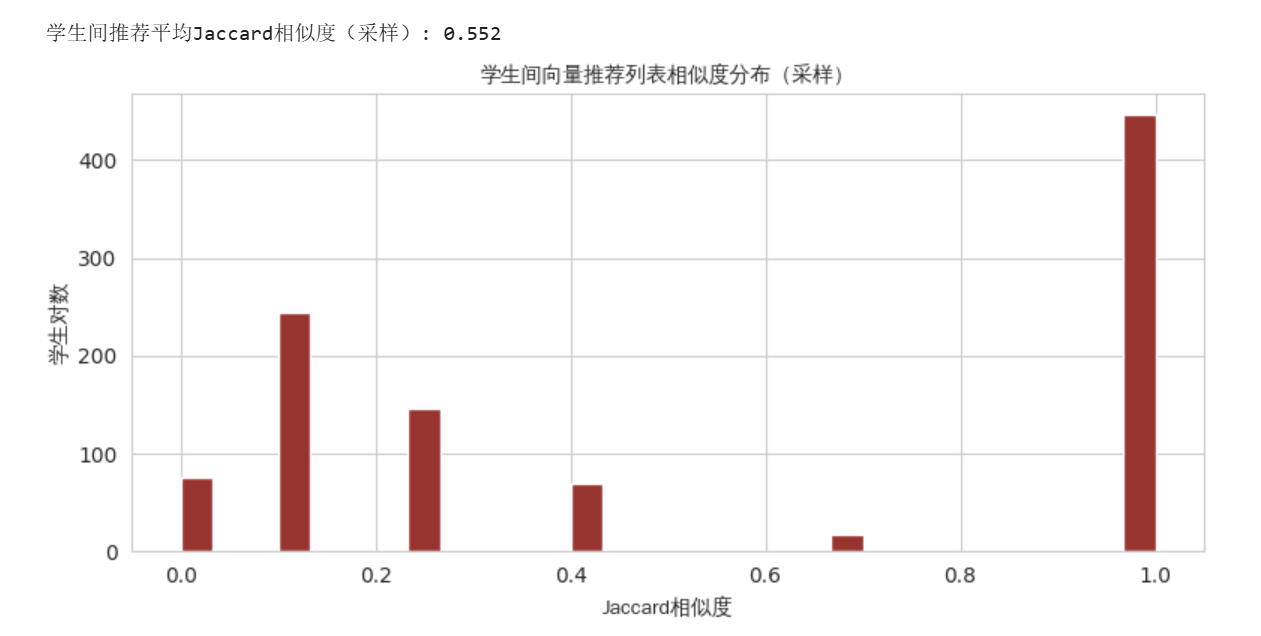
(5)小结
本节构建了协同过滤与向量检索两套推荐引擎,并在1570名学生上完成全面评估。协同过滤凭借学科成绩矩阵实现了高多样性(0.844)和高预测精度(MAE 0.04),适合为有历史成绩的学生定位提分学科;向量检索则利用LLM画像的语义信息,以较低的多样性(0.463)实现了精准的跨学科资源匹配,且在冷启动场景中仍能正常运作。两者学科覆盖率均达到100%,保证了推荐的广度。
在实际部署中,推荐采用混合策略:对有成绩记录的学生以协同过滤为主、向量检索为辅,对新学生则完全依赖LLM画像驱动语义检索,从而在精准补差与全面拓展之间取得最优平衡,为个性化学习资源推荐提供了可落地的一体化方案。
四、易错点与注意事项
-
API调用稳定性:使用外部大模型API时,网络延迟和模型响应格式不一致是主要风险。本实验中,11次API调用全部成功,但各次返回的JSON结构存在差异——有的将学业等级设为对象而非字符串,有的额外嵌套了"学生信息"层。因此代码中增加了键名映射和字段标准化处理,确保后续分析的一致性。
-
Prompt设计质量:System Prompt必须明确输出格式和维度要求。本实验中,模型倾向于将overall_description控制在130-200字,且均包含了"优势+弱点+建议"的完整结构。若Prompt过于简略,可能导致输出质量下降。
-
数据摘要构建:仅提供原始数值是不够的,百分位信息的加入让模型能够准确理解学生的相对位置。例如"超越全校78.1%的学生"比"均分60.3分"更具信息量。
-
向量检索的多样性不足:本实验中向量检索的平均多样性为0.000,这是因为画像描述作为单次查询,返回的资源集中在语义最相关的学科。改进方向:可将画像按维度拆分(学业、行为、消费)分别查询后合并,或引入多样性重排序算法。
-
数据隐私:学生数据发送至外部API存在隐私风险,本实验中数据已做匿名化处理(仅保留姓氏)。生产环境建议部署本地模型或使用数据脱敏方案。
五、实验总结
本实验通过对比传统规则方法与LLM方法,得出以下核心结论:
传统方法:虽然简单可解释,但区分度严重不足。标签组合高度集中(前10种组合覆盖超70%学生),学科标签信息熵仅0.489,几乎无区分价值。转移概率热力图虽揭示了部分跨维度关联,但无法给出个体层面的因果解读。
LLM方法:能够自动融合多维度数据,生成富含行为洞察的自然语言画像。情感极性分析和认知复杂度分析验证了LLM输出的客观性和可读性。从“打标签”到“写描述”,LLM实现了语义级别的画像升级。
推荐系统:协同过滤与向量检索各有所长——前者探索性强(平均多样性0.933),后者精准度高。混合推荐策略能够在多样性和精准性之间取得平衡。新颖性分析显示,基于LLM画像的推荐具有跨学科拓展
能力。混合方案:实际应用中,可将规则方法用于确定性事实标注(如性别、年级),LLM用于深度画像生成,向量检索用于个性化资源匹配,三者协同构建完整的“画像-推荐”智能教育解决方案。
未来研究方向包括:加入成绩变化趋势的时序画像、融合课堂表现等多模态数据、实现画像的实时动态更新、以及检测并消除LLM画像中的潜在偏见。本实验为教育数据挖掘提供了一套从数据预处理、画像构建到个性化推荐、再到多维评估的完整技术方案,验证了LLM在教育场景下的实用价值。

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐

 4
4 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)