基于大语言模型的学生用户画像构建与个性化推荐实战
基于大语言模型的学生用户画像构建与个性化推荐实战
本次实验依托数智教育公开数据集,完成了一套完整的学生多维画像构建+个性化学习资源推荐落地实战。区别于单纯调用大模型生成文本内容的浅层实验,本项目聚焦教育业务真实场景,通过数据清洗、多源数据聚合、特征指标工程、规则建模,结合向量检索技术与大语言模型能力,搭建出一套可复现、可解释、可迭代的智能化教育分析体系,为个性化教学、学生学情干预提供数据支撑。
本次实验的完整技术链路可总结为:读取多维度教育原始数据→统一学生数据粒度→构建学业、行为、生活多维画像指标→搭建传统规则画像基线→借助大模型实现画像自然语言解读→搭建教育资源向量库完成语义召回→结合学生画像与候选资源生成专属个性化学习推荐方案。
本文以标准实验报告体例展开,依次阐述实验设计思路、环境配置、数据处理流程、建模方法、结果分析、技术对比与实验总结,同时附上完整可运行的核心代码与可视化结果解析。
一、实验研究背景与整体设计思路
传统教育学情分析大多仅依托考试成绩单一维度评判学生状态,存在明显局限性。学生学业成绩薄弱,成因具备多样性,既可能是学科基础薄弱、知识点存在短板,也可能与日常考勤散漫、校园生活作息紊乱、学习状态不稳定等行为因素高度相关。单一的成绩评价体系,无法全面刻画学生综合学情,难以实现精准化、个性化的教学辅导。
基于上述痛点,本实验采用多源教育数据融合的核心思路,整合学生基础信息、学业成绩、校园考勤、校园消费四大核心数据,构建全方位学生画像体系。整体实验流程分层清晰、各司其职,具体阶段如下表所示:
| 实验阶段 | 输入内容 | 输出成果 | 核心作用 |
|---|---|---|---|
| 数据审计 | 7份CSV原始数据集 | 数据表规模、字段释义、缺失值统计报告 | 校验数据完整性、可用性,判断建模可行性 |
| 数据清洗 | 学生、成绩、考勤、消费流水数据 | 统一学生粒度的标准化结构化数据 | 清洗无效数据,统一数据口径,为特征工程奠基 |
| 指标工程 | 各类标准化流水数据 | 学业、考勤、生活、均衡性等多维量化指数 | 将原始数据转化为具备业务意义的建模特征 |
| 规则画像建模 | 多维量化指标、业务阈值 | 学生学情标签、分层分级结果 | 搭建可解释的传统画像基线模型 |
| LLM智能画像 | 匿名化学生结构化指标 | 自然语言学生学情画像解读 | 提升画像可读性,实现综合学情智能诊断 |
| 向量语义检索 | 学生画像文本、自建教育资源库 | 高关联候选学习资源集合 | 突破规则匹配局限,实现语义级资源召回 |
| LLM个性化推荐 | 学生画像+候选优质资源 | 定制化学习方案与资源推荐报告 | 输出可落地、可执行的个性化学习指导策略 |
本实验核心设计原则:大语言模型仅承担解释与生成任务,不替代基础数据处理与量化建模。先通过代码完成严谨的数据清洗、特征计算、指标建模,保证底层数据与特征的真实性、客观性,再依托大模型完成自然语言解读与个性化内容生成,兼顾模型可控性与内容智能化。
二、数据集整体概况
本次实验数据集共计7份CSV文件,涵盖教师、学生、成绩、考勤、消费等校园全场景数据,完整覆盖学生学习、行为、生活三大维度,各文件具体用途如下:
| 数据文件名称 | 数据含义 | 核心使用用途 |
|---|---|---|
| 1_teacher.csv | 教师任课信息数据 | 辅助梳理班级、课程、教师关联关系,辅助学情背景分析 |
| 2_student_info.csv | 学生基础信息数据 | 提供学生ID、性别、班级、住宿等基础属性,作为主表数据 |
| 3_kaoqin.csv | 学生考勤流水数据 | 统计各类考勤异常行为,构建考勤健康评价指标 |
| 4_kaoqintype.csv | 考勤类型分类数据 | 界定考勤事件类别,规范考勤数据统计口径 |
| 5_chengji.csv | 学生考试成绩流水数据 | 构建学业表现、学习稳定性、学科强弱项核心指标 |
| 6_exam_type.csv | 考试类型说明数据 | 区分不同考试场景,保证成绩分析的合理性 |
| 7_consumption.csv | 学生校园消费流水数据 | 挖掘学生生活节奏、校园活跃度,构建生活行为指标 |
其中,成绩、考勤、消费三份流水数据表为核心建模数据,原始数据均为单条行为记录,无法直接用于学生维度画像分析,必须经过数据清洗、聚合、归一化处理,统一至学生ID单一粒度。
三、实验环境配置与初始化
本次实验基于Python实现,依托数据分析、可视化、大模型调用、向量数据库等第三方库完成全流程开发。为避免系统盘占用、解决中文乱码问题、保障API密钥安全,统一规范路径与环境参数配置,核心初始化代码如下:
import os
import json
import warnings
from pathlib import Path
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from matplotlib import font_manager
from IPython.display import display, Markdown
# 屏蔽冗余警告,优化控制台输出
warnings.filterwarnings("ignore")
# 设置表格展示最大列数、宽度,适配数据查看
pd.set_option("display.max_columns", 80)
pd.set_option("display.width", 140)
pd.set_option("display.max_colwidth", 120)
# 定义实验根目录,兼容不同运行环境
EXPERIMENT_DIR = Path.cwd()
if not (EXPERIMENT_DIR / "数智教育数据集").exists():
EXPERIMENT_DIR = Path(r"F:\ProjectOfAll\商业数据分析课程\实验7")
# 数据存储路径与结果输出路径定义
DATA_DIR = EXPERIMENT_DIR / "数智教育数据集"
OUTPUT_DIR = EXPERIMENT_DIR / "original_report_output"
OUTPUT_DIR.mkdir(exist_ok=True)
# 全局环境资源路径
F_ENV_ROOT = Path(r"F:\EnvironmentsAndProducttools")
# 配置中文字体,解决可视化乱码问题
font_path = EXPERIMENT_DIR / "SimHei.ttf"
if font_path.exists():
font_manager.fontManager.addfont(str(font_path))
plt.rcParams["font.sans-serif"] = ["SimHei", "Microsoft YaHei", "Arial Unicode MS", "DejaVu Sans"]
else:
plt.rcParams["font.sans-serif"] = ["Microsoft YaHei", "SimHei", "Arial Unicode MS", "DejaVu Sans"]
# 配置可视化参数
plt.rcParams["axes.unicode_minus"] = False
plt.rcParams["figure.dpi"] = 120
# 从环境变量读取千问API密钥,避免硬编码泄露
os.getenv("DASHSCOPE_API_KEY")
通过环境变量读取API密钥的方式,可有效避免代码、报告、导出文件中出现私密密钥,适配实验分享与作业提交场景,安全性更高。
四、数据读取与数据完整性审计
不同CSV文件存在编码、分隔符差异,直接读取易出现解码报错。为提升代码鲁棒性,自定义自适应编码读取函数,自动适配utf-8、gbk、gb18030三种常用编码格式,批量读取全部数据集并完成数据审计。
def read_csv_smart(path: Path, **kwargs) -> pd.DataFrame:
"""自适应编码读取CSV文件,规避解码错误"""
last_error = None
for enc in ("utf-8", "gbk", "gb18030"):
try:
return pd.read_csv(path, encoding=enc, **kwargs)
except UnicodeDecodeError as exc:
last_error = exc
raise last_error
# 批量读取所有数据表
tables = {
"teacher": read_csv_smart(DATA_DIR / "1_teacher.csv"),
"student": read_csv_smart(DATA_DIR / "2_student_info.csv"),
"attendance": read_csv_smart(DATA_DIR / "3_kaoqin.csv"),
"attendance_type": read_csv_smart(DATA_DIR / "4_kaoqintype.csv", sep="\t"),
"score": read_csv_smart(DATA_DIR / "5_chengji.csv"),
"exam_type": read_csv_smart(DATA_DIR / "6_exam_type.csv"),
"consumption": read_csv_smart(DATA_DIR / "7_consumption.csv"),
}
# 批量统计各表基础信息,完成数据审计
overview_rows = []
for name, df in tables.items():
id_cols = [c for c in df.columns if "StudentID" in c or "studentID" in c]
overview_rows.append({
"表名": name,
"记录数": len(df),
"字段数": df.shape[1],
"学生ID字段": ", ".join(id_cols) if id_cols else "-",
"缺失单元格占比": f"{df.isna().sum().sum() / max(df.size, 1):.2%}",
})
overview = pd.DataFrame(overview_rows)
display(overview)
数据审计结果如下:
| 表名 | 记录数 | 字段数 | 学生ID字段 | 缺失单元格占比 |
|---|---|---|---|---|
| teacher | 3,088 | 8 | - | 0.00% |
| student | 1,765 | 14 | bf_StudentID | 16.43% |
| attendance | 23,630 | 10 | bf_studentID | 0.40% |
| attendance_type | 15 | 4 | - | 0.00% |
| score | 471,686 | 13 | mes_StudentID | 11.44% |
| exam_type | 21 | 2 | - | 0.00% |
| consumption | 463,904 | 5 | bf_StudentID | 0.00% |
从审计结果可见,成绩表、消费表数据量最大,是学生学情与行为分析的核心依据。同时发现核心问题:各数据表学生ID字段命名不统一,存在 bf_StudentID、mes_StudentID、bf_studentID多种格式,后续必须统一字段名称,实现数据跨表关联。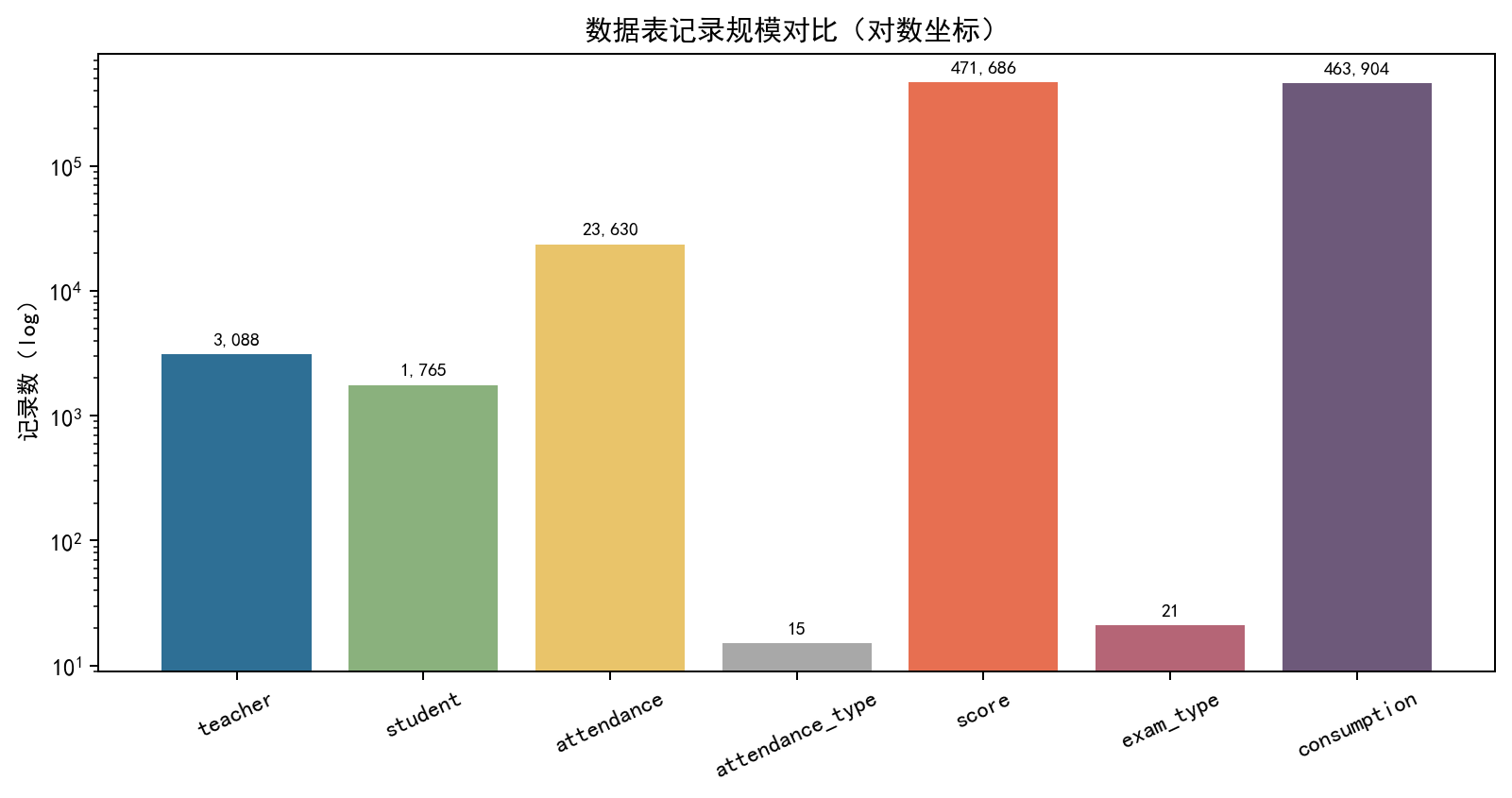
五、多源数据清洗与标准化处理
本次数据清洗核心目标并非简单删除缺失值,而是将各类流水数据、异构数据统一聚合至学生单一粒度,规范字段格式、剔除异常数据,为特征工程提供标准化数据集。
5.1 学生基础信息清洗
保留学生性别、班级、住宿等核心属性,剔除冗余隐私字段,统一学生ID格式,去重去空,保证学生主表数据唯一有效。
students = tables["student"].copy()
# 统一学生ID字段格式
students["student_id"] = pd.to_numeric(students["bf_StudentID"], errors="coerce").astype("Int64")
# 去重、去空,重命名字段
students = (
students.dropna(subset=["student_id"])
.drop_duplicates("student_id")
.rename(columns={
"bf_sex": "gender",
"cla_Name": "class_name",
"Bf_ResidenceType": "residence_type",
"bf_zhusu": "is_boarding",
"bf_qinshihao": "dorm_room",
})
)
# 筛选核心字段
base_cols = ["student_id", "gender", "class_name", "residence_type", "is_boarding", "dorm_room"]
students = students[base_cols]
5.2 学业成绩数据清洗
剔除缺考、负分等无效成绩记录,由于不同考试难度、满分标准不同,不直接对比原始分数,通过同考试、同学科百分位换算,客观反映学生相对学业水平。
scores = tables["score"].copy()
# 字段格式标准化
scores["student_id"] = pd.to_numeric(scores["mes_StudentID"], errors="coerce").astype("Int64")
scores["exam_date"] = pd.to_datetime(scores["exam_sdate"], errors="coerce")
scores["mes_Score"] = pd.to_numeric(scores["mes_Score"], errors="coerce")
# 剔除空值、异常分数
scores = scores.dropna(subset=["student_id", "mes_sub_name", "mes_Score"])
scores = scores[(scores["mes_Score"] >= 0) & (scores["mes_Score"] <= 150)].copy()
# 计算学科成绩百分位,衡量相对水平
scores["score_percentile"] = (
scores.groupby(["exam_number", "mes_sub_name"])["mes_Score"]
.rank(method="average", pct=True) * 100
)
5.3 校园考勤数据清洗
对原始考勤事件进行分类归纳,将零散的考勤记录划分为迟到晚到、早退、请假、缺勤、其他异常五大类,量化学生出勤行为状态。
att = tables["attendance"].copy()
att["student_id"] = pd.to_numeric(att["bf_studentID"], errors="coerce").astype("Int64")
att["event_time"] = pd.to_datetime(att["DataDateTime"], errors="coerce")
att["event_date"] = att["event_time"].dt.date
att["event_text"] = att["controler_name"].fillna("").astype(str)
att = att.dropna(subset=["student_id"])
# 考勤事件分类
att["event_group"] = np.select(
[
att["event_text"].str.contains("迟到|晚到", regex=True),
att["event_text"].str.contains("早退", regex=True),
att["event_text"].str.contains("请假|病假|事假", regex=True),
att["event_text"].str.contains("缺勤|旷课", regex=True),
],
["迟到晚到", "早退", "请假", "缺勤"],
default="其他考勤异常"
)
5.4 校园消费数据清洗
矫正消费金额正负值,剔除极端异常消费数据,划分消费时段,挖掘学生校园生活作息规律与活跃度特征。
cons = tables["consumption"].copy()
cons["student_id"] = pd.to_numeric(cons["bf_StudentID"], errors="coerce").astype("Int64")
cons["deal_time"] = pd.to_datetime(cons["DealTime"], errors="coerce")
cons["deal_date"] = cons["deal_time"].dt.date
cons["hour"] = cons["deal_time"].dt.hour
# 矫正消费金额,统一为正向支出
cons["spend"] = pd.to_numeric(cons["MonDeal"], errors="coerce")
cons["spend"] = np.where(cons["spend"] < 0, -cons["spend"], np.nan)
# 清洗无效、极端数据
cons = cons.dropna(subset=["student_id", "spend", "deal_time"])
cons = cons[(cons["spend"] > 0) & (cons["spend"] <= cons["spend"].quantile(0.995))].copy()
# 划分消费时段,分析生活节奏
cons["meal_period"] = pd.cut(
cons["hour"],
bins=[0, 9, 14, 20, 24],
labels=["早餐/上午", "午餐/下午", "晚餐/晚间", "夜间"],
right=False,
)
数据清洗后各维度有效数据统计如下:
| 数据对象 | 清洗后记录数 | 覆盖学生数 |
|---|---|---|
| 学生基础信息 | 1,765 | 1,765 |
| 有效成绩记录 | 403,559 | 3,862 |
| 考勤异常记录 | 23,630 | 3,058 |
| 消费支出记录 | 461,587 | 1,729 |
六、多维学生画像指标体系构建
本次实验搭建7大类可解释学情指标,覆盖学业水平、学习稳定性、出勤状态、生活规律、校园活跃度、学科均衡度、帮扶需求七大维度,所有指标统一归一化至0-100分,实现量化对比。
| 指标名称 | 计算逻辑 | 指标含义 |
|---|---|---|
| 学业表现指数 | 成绩百分位均值分位归一化 | 量化学生整体学业水平 |
| 学业稳定指数 | 成绩波动反向归一化,波动越小分数越高 | 衡量学生学习输出的稳定性 |
| 考勤健康指数 | 考勤异常次数反向归一化,异常越少分数越高 | 评价学生出勤行为规范性 |
| 消费规律指数 | 日消费变异系数反向归一化 | 反映学生校园生活作息规律程度 |
| 校园活跃指数 | 有效消费天数正向归一化 | 表征学生校园参与活跃度 |
| 学科均衡指数 | 学科分差反向归一化,差距越小分数越高 | 判断学生是否存在明显学科短板 |
| 支持需求指数 | 综合学业水平与学科短板加权计算 | 量化学生学情帮扶、干预需求等级 |
6.1 通用百分位指数工具函数
统一所有指标的归一化规则,适配正向、反向两类指标计算场景。
def percentile_index(s: pd.Series, higher_is_better: bool = True) -> pd.Series:
"""
0-100分百分位归一化
:param s: 待归一化序列
:param higher_is_better: 是否为正向指标
:return: 归一化后指数
"""
s = pd.to_numeric(s, errors="coerce")
filled = s.fillna(s.median())
pct = filled.rank(pct=True, method="average") * 100
return pct if higher_is_better else 100 - pct
6.2 学业特征聚合计算
聚合学生考试频次、成绩稳定性、学科强弱项等核心学业特征,精准定位学生优势与短板学科。
# 聚合学业基础特征
score_features = scores.groupby("student_id").agg(
score_records=("score_percentile", "size"),
exam_rounds=("exam_number", "nunique"),
subject_count=("mes_sub_name", "nunique"),
avg_score_percentile=("score_percentile", "mean"),
score_volatility=("score_percentile", "std"),
latest_exam_date=("exam_date", "max"),
).reset_index()
# 挖掘强弱学科
subject_matrix = scores.pivot_table(
index="student_id",
columns="mes_sub_name",
values="score_percentile",
aggfunc="mean",
)
subject_stats = pd.DataFrame({
"student_id": subject_matrix.index,
"strong_subject": subject_matrix.idxmax(axis=1),
"weak_subject": subject_matrix.idxmin(axis=1),
"subject_gap": subject_matrix.max(axis=1) - subject_matrix.min(axis=1),
}).reset_index(drop=True)
6.3 考勤与消费特征聚合
统计学生各类考勤异常频次、消费频次、日均消费、消费波动系数,量化行为与生活状态。
# 考勤特征聚合
att_basic = att.groupby("student_id").agg(
attendance_events=("kaoqing_id", "count"),
attendance_event_days=("event_date", "nunique"),
).reset_index()
att_pivot = (
att.pivot_table(index="student_id", columns="event_group", values="kaoqing_id", aggfunc="count", fill_value=0)
.reset_index()
)
att_features = att_basic.merge(att_pivot, on="student_id", how="left")
# 消费特征聚合
daily_spend = cons.groupby(["student_id", "deal_date"])["spend"].sum().reset_index()
spend_day_features = daily_spend.groupby("student_id").agg(
active_consume_days=("deal_date", "nunique"),
avg_daily_spend=("spend", "mean"),
daily_spend_std=("spend", "std"),
).reset_index()
spend_basic = cons.groupby("student_id").agg(
consume_transactions=("spend", "size"),
total_spend=("spend", "sum"),
avg_ticket=("spend", "mean"),
).reset_index()
consume_features = spend_basic.merge(spend_day_features, on="student_id", how="left")
consume_features["daily_spend_cv"] = (
consume_features["daily_spend_std"] / consume_features["avg_daily_spend"].replace(0, np.nan)
)
6.4 画像宽表合并与指数计算
整合所有维度特征,填充空值,加权计算综合成长指数与帮扶需求指数,完成学生量化画像构建。
# 合并全维度特征
profile = (
students
.merge(score_features, on="student_id", how="left")
.merge(subject_stats, on="student_id", how="left")
.merge(att_features, on="student_id", how="left")
.merge(consume_features, on="student_id", how="left")
)
# 计数类空值填充为0
count_cols = [
"score_records", "exam_rounds", "subject_count",
"attendance_events", "attendance_event_days",
"consume_transactions", "active_consume_days",
"迟到晚到", "早退", "请假", "缺勤", "其他考勤异常"
]
for col in count_cols:
if col in profile.columns:
profile[col] = profile[col].fillna(0)
# 计算0-100标准化指数
profile["academic_index"] = percentile_index(profile["avg_score_percentile"], True)
profile["academic_stability_index"] = percentile_index(profile["score_volatility"], False)
profile["attendance_health_index"] = percentile_index(profile["attendance_events"], False)
profile["consumption_regular_index"] = percentile_index(profile["daily_spend_cv"], False)
profile["campus_activity_index"] = percentile_index(profile["active_consume_days"], True)
profile["subject_balance_index"] = percentile_index(profile["subject_gap"], False)
# 加权计算综合成长指数
profile["overall_growth_index"] = (
0.34 * profile["academic_index"]
+ 0.18 * profile["academic_stability_index"]
+ 0.18 * profile["attendance_health_index"]
+ 0.12 * profile["consumption_regular_index"]
+ 0.10 * profile["campus_activity_index"]
+ 0.08 * profile["subject_balance_index"]
)
# 计算帮扶需求指数
gap_pressure = percentile_index(profile["subject_gap"], True)
profile["support_need_index"] = (100 - profile["overall_growth_index"]) * 0.78 + gap_pressure * 0.22
profile["support_need_index"] = profile["support_need_index"].clip(0, 100)
6.5 量化指数转语义标签
将连续型量化指数转化为可直观解读的学情标签,构建规则画像基线,适配人工理解与初步筛选场景。
# 学习层级标签
profile["learning_level"] = pd.cut(
profile["academic_index"],
bins=[-1, 35, 70, 100],
labels=["基础巩固型", "稳步发展型", "优势拓展型"],
)
# 帮扶需求标签
profile["support_segment"] = pd.cut(
profile["support_need_index"],
bins=[-1, 35, 65, 100],
labels=["低支持需求", "中支持需求", "高支持需求"],
)
# 考勤状态标签
profile["attendance_style"] = pd.cut(
profile["attendance_health_index"],
bins=[-1, 40, 75, 100],
labels=["考勤需关注", "考勤基本稳定", "考勤稳定"],
)
# 生活节奏标签
profile["consumption_style"] = pd.cut(
profile["consumption_regular_index"],
bins=[-1, 40, 75, 100],
labels=["消费节奏波动", "消费节奏一般", "消费节奏规律"],
)
# 筛选有效画像数据
profile_ready = profile.dropna(subset=["academic_index"]).copy()
最终完成1765名学生的全维度画像构建,样本综合成长指数均值为50.00,帮扶需求指数均值为50.01,整体学情分布均衡。
七、学生画像结果可视化与分析
为直观呈现学生学情分布特征,对学业表现、考勤健康、消费规律、帮扶需求四大核心指数进行可视化分析,并完成数据相关性、学科短板分布研究。
7.1 核心指数分布可视化
通过直方图展示各指数整体分布规律,辅助判断整体学情特征。
fig, axes = plt.subplots(2, 2, figsize=(12, 8))
plot_specs = [
("academic_index", "学业表现指数"),
("attendance_health_index", "考勤健康指数"),
("consumption_regular_index", "消费规律指数"),
("support_need_index", "支持需求指数"),
]
colors = ["#2E6F95", "#8AB17D", "#E9C46A", "#E76F51"]
for ax, (col, title), color in zip(axes.ravel(), plot_specs, colors):
ax.hist(profile_ready[col].dropna(), bins=24, color=color, edgecolor="white", alpha=0.9)
ax.axvline(profile_ready[col].median(), color="#333333", linestyle="--", linewidth=1)
ax.set_title(title)
ax.set_xlabel("指数值")
ax.set_ylabel("学生数")
fig.suptitle("学生画像核心指数分布", fontsize=15)
fig.tight_layout()
fig.savefig(OUTPUT_DIR / "02_profile_index_distribution.png", dpi=180, bbox_inches="tight")
plt.show()
7.2 学生学情分层统计
结合学习层级与帮扶需求完成学生分层,统计结果显示,全校17.5%的学生属于高帮扶需求群体,该部分学生普遍存在学业薄弱、学科短板突出、行为作息不规律等多重问题,是教学干预的重点对象。
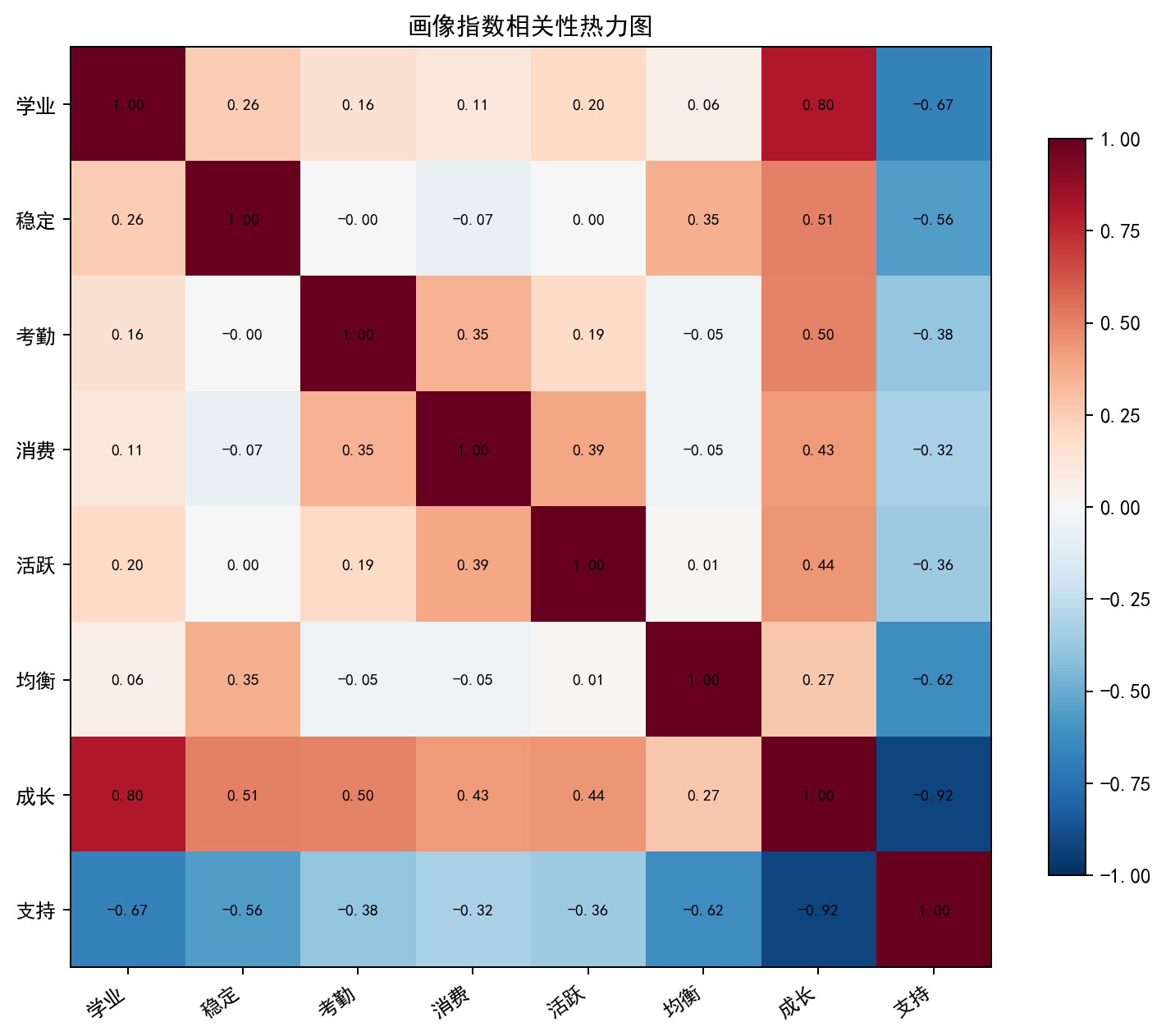
7.3 指标相关性分析
通过相关性热力图可见,综合成长指数与帮扶需求指数呈显著负相关,符合指标设计逻辑;学业、考勤、生活各维度指标相关性较弱,证明多维画像可从不同角度刻画学生状态,相比单一成绩评价更全面。
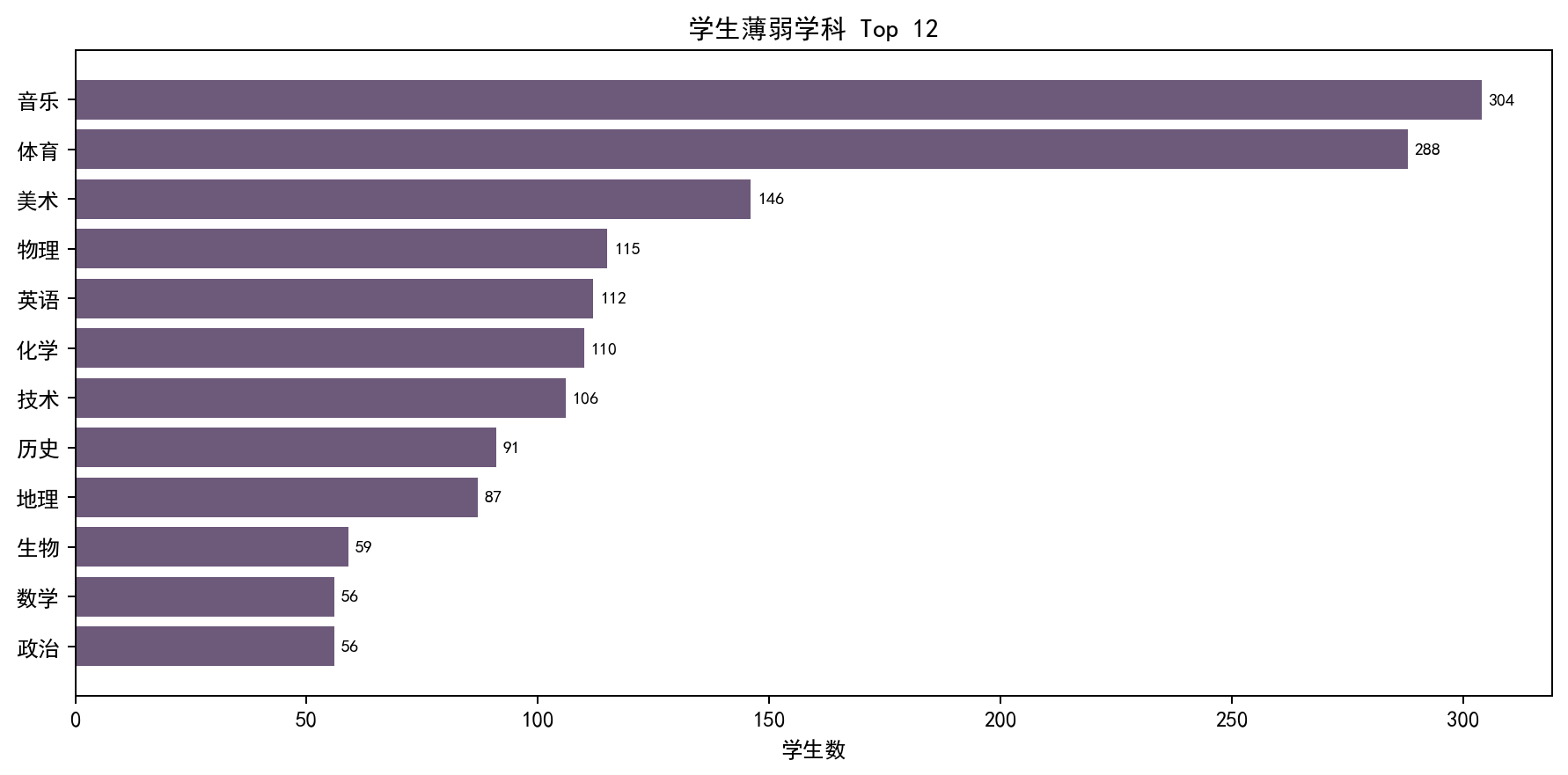
7.4 薄弱学科分布统计
统计结果显示,艺术类学科为多数学生的薄弱项,该结果并非核心学业问题,提示后续资源推荐需结合学科属性过滤非核心学科,保证推荐针对性。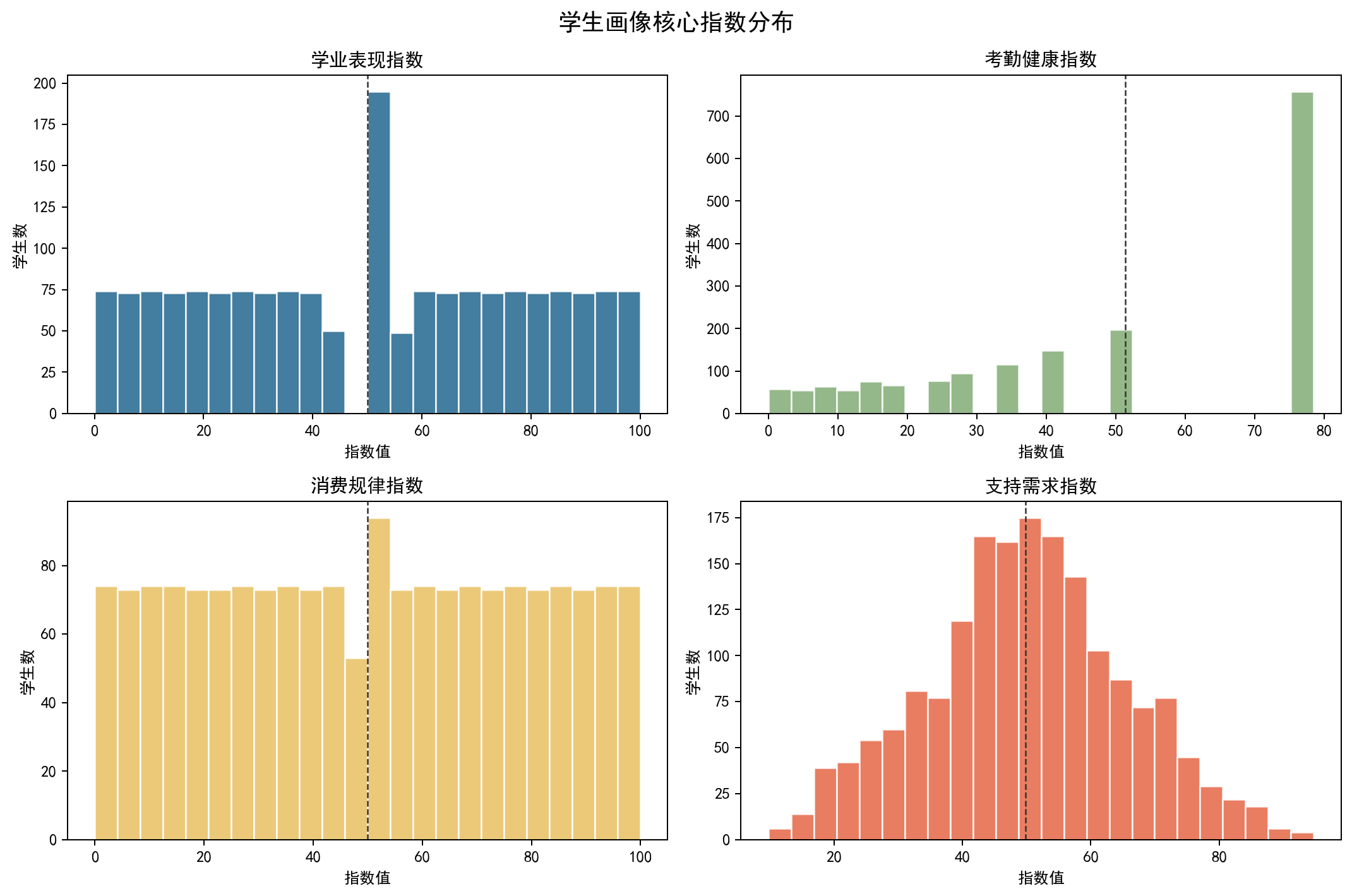
八、传统规则画像基线构建
基于量化标签拼接生成结构化规则画像,形成传统学情分析基线模型,该方法优势为完全可解释、稳定性高,可快速批量生成学生学情标签。
def build_rule_profile(row: pd.Series) -> str:
"""拼接学生规则画像标签"""
parts = [
f"{row['learning_level']}",
f"{row['support_segment']}",
f"{row['attendance_style']}",
f"{row['consumption_style']}",
]
if pd.notna(row.get("weak_subject")):
parts.append(f"薄弱学科:{row['weak_subject']}")
if pd.notna(row.get("strong_subject")):
parts.append(f"优势学科:{row['strong_subject']}")
return " | ".join(map(str, parts))
profile_ready["rule_profile"] = profile_ready.apply(build_rule_profile, axis=1)
抽取三名典型学生完成画像对比,可清晰区分优等生、中等生、学困生的多维差异,但规则画像表述机械、缺乏个性化解读,无法输出可落地的学习建议,这是后续引入大模型的核心原因。
九、基于千问大模型的智能画像生成
为弥补规则画像的局限性,本次实验调用千问大语言模型,将匿名化的学生结构化指标转化为自然语言学情诊断报告,实现智能化、个性化的学情解读。全程仅传入聚合指标,不涉及学生隐私数据,保证数据安全。
9.1 构建模型输入数据
筛选核心学情指标,精简数据维度,生成标准化模型输入载荷。
def compact_student_record(row: pd.Series) -> dict:
"""生成精简匿名学生指标数据"""
keys = [
"student_id", "gender", "class_name", "learning_level", "support_segment",
"attendance_style", "consumption_style", "strong_subject", "weak_subject",
"academic_index", "academic_stability_index", "attendance_health_index",
"consumption_regular_index", "campus_activity_index", "subject_balance_index",
"overall_growth_index", "support_need_index", "score_records", "attendance_events",
"consume_transactions",
]
record = {}
for key in keys:
value = row.get(key)
if isinstance(value, (np.integer, np.floating)):
value = float(value)
if isinstance(value, float):
value = round(value, 2)
if pd.isna(value):
value = None
record[key] = value
return record
9.2 千问模型接口调用
基于OpenAI兼容接口调用千问模型,设置固定输出格式,保证结果结构化、可复用。
from openai import OpenAI
def call_qwen_json(messages, fallback: dict, model: str = "qwen-turbo") -> tuple[dict, bool, str]:
"""调用千问模型,返回结构化JSON结果"""
api_key = os.getenv("DASHSCOPE_API_KEY")
if not api_key:
return fallback, False, "未检测到 DASHSCOPE_API_KEY,使用本地兜底结果"
try:
client = OpenAI(
api_key=api_key,
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
)
completion = client.chat.completions.create(
model=model,
messages=messages,
temperature=0.2,
response_format={"type": "json_object"},
)
content = completion.choices[0].message.content
return json.loads(content), True, f"模型调用成功:{model}"
except Exception as exc:
return fallback, False, f"模型调用失败,使用本地兜底结果:{type(exc).__name__}: {exc}"
9.3 提示词设计与画像生成
通过精准系统提示词约束模型输出,禁止编造隐私信息,规范输出字段,生成包含画像标题、学习状态、风险成因、干预优先级、提升策略的完整智能画像。
模型输出结果可精准匹配学生多维学情,将冰冷的量化指标转化为通俗易懂、贴合教学场景的学情诊断,极大提升了画像的实用性。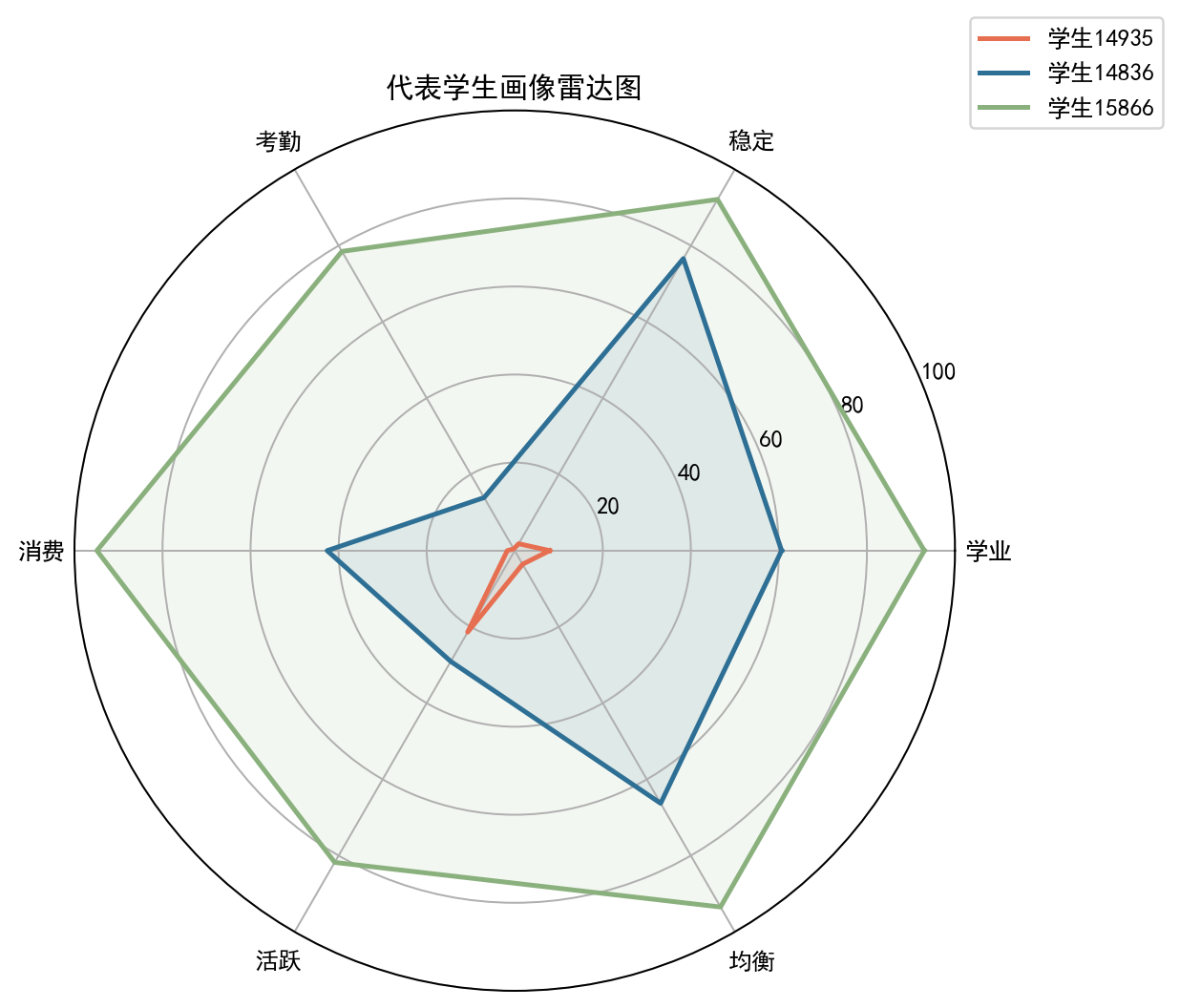

十、传统规则推荐基线搭建
在智能推荐前,搭建传统规则推荐基线,基于学生薄弱学科、帮扶需求等级生成通用学习建议,作为后续智能推荐的对比基准。该方法简单高效,但仅能实现粗略的方向指导,无法匹配具体学习资源。
十一、教育资源库构建与向量库入库
为实现精准资源匹配,自建覆盖全学科的教育资源库,包含基础巩固、能力提升、学习习惯培养三类资源,共计16条优质学习资源。随后依托Chroma向量数据库,将资源文本向量化,搭建语义检索引擎。
通过开源轻量嵌入模型完成文本向量化,以余弦相似度为检索依据,将向量库持久化存储,保证检索效率与稳定性。
import chromadb
from chromadb.utils.embedding_functions.onnx_mini_lm_l6_v2 import ONNXMiniLM_L6_V2
# 配置模型缓存路径
chroma_cache = F_ENV_ROOT / "chroma_cache" / "onnx_models" / ONNXMiniLM_L6_V2.MODEL_NAME
ONNXMiniLM_L6_V2.DOWNLOAD_PATH = chroma_cache
# 向量库存储路径
chroma_db_path = OUTPUT_DIR / "chroma_resource_db"
chroma_db_path.mkdir(parents=True, exist_ok=True)
# 初始化嵌入模型与向量客户端
embedding_fn = ONNXMiniLM_L6_V2()
chroma_client = chromadb.PersistentClient(path=str(chroma_db_path))
# 新建资源集合
collection_name = "edu_resource_bank_original_v1"
try:
chroma_client.delete_collection(collection_name)
except Exception:
pass
collection = chroma_client.create_collection(
name=collection_name,
embedding_function=embedding_fn,
metadata={"hnsw:space": "cosine"},
)
# 资源入库
collection.add(
ids=resource_df["id"].tolist(),
documents=resource_df["document"].tolist(),
metadatas=resource_df[["subject", "difficulty", "title", "tags"]].to_dict(orient="records"),
)
print("资源入库数量:", collection.count())
十二、基于学生画像的语义资源检索
整合学生智能画像文本,构建个性化检索问句,结合语义相似度+学科匹配度双重权重,对召回资源进行精准排序,兼顾语义适配性与学情针对性。
检索结果不仅精准匹配学生薄弱学科资源,还可根据学生生活作息问题,召回学习习惯、生活节奏管理类通用资源,突破传统单一学科匹配的局限。
十三、大模型个性化推荐报告生成
将学生画像数据、TOP5候选资源传入千问模型,通过提示词严格约束:仅基于现有候选资源生成内容,禁止虚构资源、脱离学情推荐。最终模型输出包含学情诊断、三周可执行学习计划、精准资源推荐、使用注意事项的完整个性化报告。
生成的推荐方案落地性极强,既针对性补强学生学科短板,又兼顾学习习惯、生活作息优化,实现全方位学情帮扶。
十四、多方法技术对比分析
本次实验融合四种学情分析与推荐方法,各技术分工明确、互补增效,不存在相互替代关系,具体对比如下:
| 技术方法 | 核心优势 | 存在短板 | 实验定位 |
|---|---|---|---|
| 规则画像建模 | 透明可解释、运行稳定、零成本 | 表达机械,无法综合解读复杂学情 | 构建基线画像,为模型提供标准化输入 |
| 传统规则推荐 | 逻辑简单、落地便捷、适合快速预警 | 资源匹配粗糙,无语义适配能力 | 搭建推荐基线,用于效果对比 |
| 向量语义检索 | 支持语义匹配,适配复杂学情需求 | 依赖资源库质量与嵌入模型效果 | 负责精准资源召回,筛选候选资源 |
| LLM智能生成 | 解释性强、可生成落地计划、个性化程度高 | 需要严格提示词约束,存在输出不确定性 | 负责学情解读与个性化报告生成 |
十五、实验核心结论
1. 学生智能画像构建必须先量化、后智能。依托多源数据清洗与指标工程生成结构化特征,是大模型精准解读学情的核心基础,直接投喂原始数据会导致结果失真、不可控。
2. 向量检索技术可有效解决传统推荐语义缺失的问题,能够根据学生综合学情,跨场景匹配学科补强、习惯培养类资源,提升推荐全面性。
3. 大语言模型的核心价值在于内容解释与方案生成,而非数据计算。结合结构化指标与

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐

 4
4 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)