张高兴的 Hailo-10 开发指南:(一)实现离线语音识别
UGen300 是什么
ASUS UGen300 外观上和移动硬盘差不多,USB-C 接口,接上去系统就多了一个 Hailo-10H 的设备。Hailo 是以色列的芯片公司,做边缘 AI 推理起家。继 Hailo-8 之后,推出了第二代的 Hailo-10 芯片,算力是 40 TOPS,功耗极低,满载不超过 5W。

和 GPU 跑 Whisper 不同,Hailo 上跑的是预编译的 .hef 文件,模型已经被量化、图优化、编译进去了,运行时直接推送数据进去,不需要框架做任何动态计算(可以参考之前博客的介绍“将自定义模型编译为 Hailo NPU 的 .hef 模型”)。这就决定了它的延迟和功耗都非常稳定,但代价是得用官方提供的模型,或者自己走编译流程。
Hailo 官方 hailo_model_zoo_genai 仓库里已经准备好了 Whisper-Tiny、Whisper-Base、Whisper-Small 三个版本的 .hef 文件,直接下载就能用,这省了很多麻烦。
环境配置
这里使用的是安装了 Raspberry Pi OS 的 Raspberry Pi 5 实现的。
安装 HailoRT
首先要安装 HailoRT,这是 Hailo 的运行时库,包含设备驱动、Python 绑定、命令行工具。可以去 Hailo Developer Zone 注册账号下载,也可以在 ASUS 的官网下载。
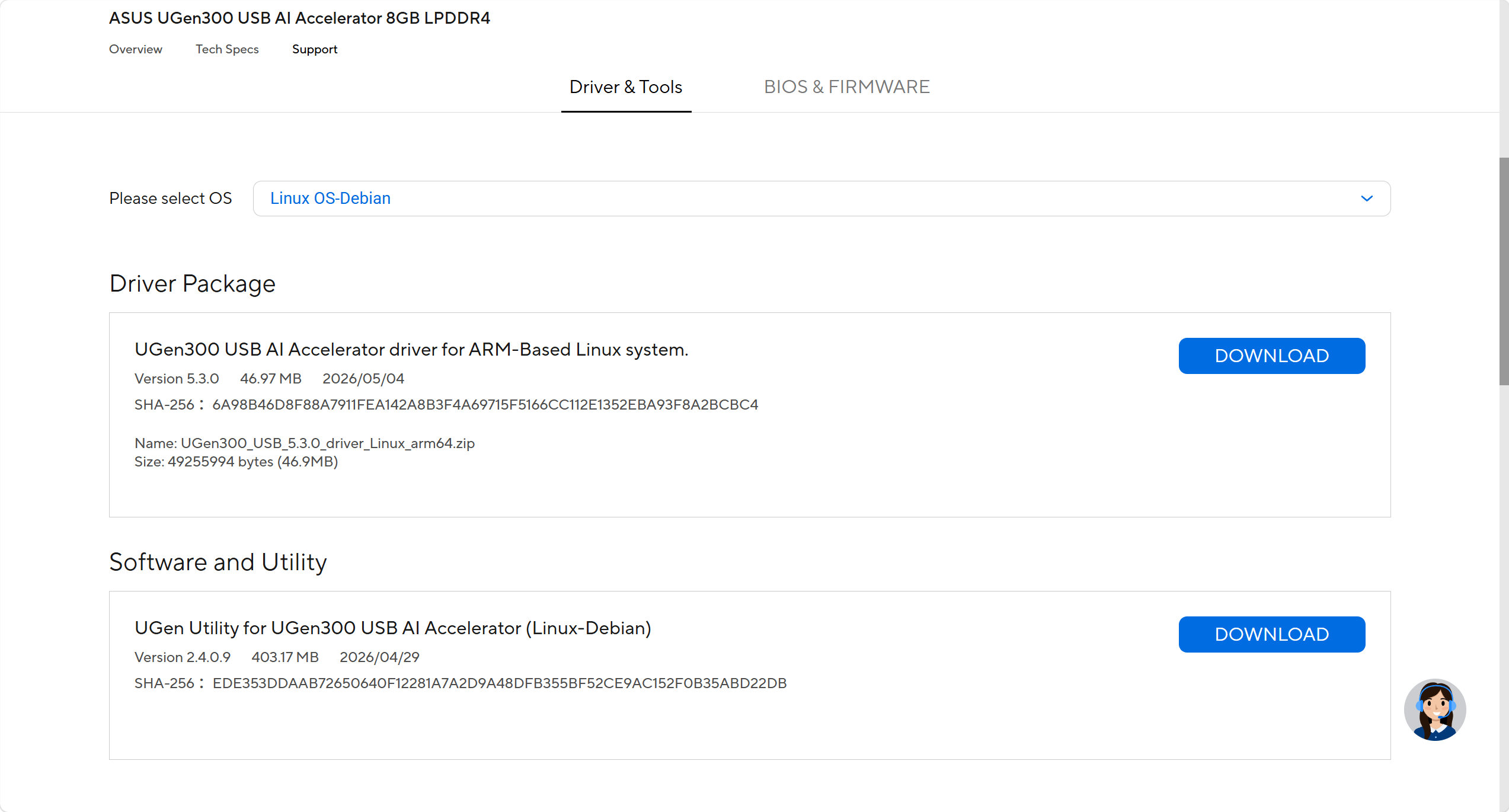
建议下载 UGen Utility for UGen300 USB AI Accelerator,里面有一个一键安装脚本,避免单独安装时出现漏装。解压后有一 ugen-utility-install.sh 脚本,执行即可安装。

cd ~/ugen-utility_2.4.0-9_arm64_usb
bash ugen-utility-install.sh
装完用这个命令验证设备是否识别:
hailortcli fw-control identify
例如:
pi@raspberrypi:~$ hailortcli fw-control identify
Executing on device: usb/002:002
Identifying board
Control Protocol Version: 2
Firmware Version: 5.3.2 (release,app)
Logger Version: 0
Device Architecture: HAILO10H
Python 环境
如果你使用系统自带的 Python,则需要的包已经随 HailoRT 一起装好。如果你使用的是虚拟环境,则还需要在虚拟环境内安装 hailort 包。
cd ~/ugen-utility_2.4.0-9_arm64_usb
pip install hailort-5.3.0-cp312-cp312-linux_aarch64.whl
音频支持
如果你想实现麦克风实时采集,还需要安装音频相关的工具。工具很多,任选一种即可。
sudo apt install alsa-utils pulseaudio-utils pavucontrol
语音转文字
模型下载
所有 Whisper 模型均以 .hef 格式预编译,音频采样率固定为 16 kHz,每次处理窗口为 10 秒,使用混合精度量化。
| 模型 | 参数量 | 文件大小 | WER | 最低 HailoRT |
|---|---|---|---|---|
| Whisper-Tiny | 39M | 78 MB | 48.14% | ≥ 5.2.0 |
| Whisper-Base | 74M | 155 MB | 25.32% | ≥ 5.2.0 |
| Whisper-Small | 244M | 388 MB | 10.61% | ≥ 5.2.0 |
模型 .hef 文件下载地址见官方 MODELS 页面。将下载的 .hef 文件放入 models/ 目录。例如:
models/
└── Whisper-Tiny.hef
代码实现
核心流程很简单:麦克风 → PCM 数据 → Hailo 推理 → 文字。下面新建 minimal_demo.py 文件。
0. 引用相关包
import subprocess
import numpy as np
from hailo_platform import VDevice
from hailo_platform.genai import Speech2Text, Speech2TextTask
1. 录音
用 parec 直接输出 float32 的 PCM 流,16kHz 单声道,录 3 秒。--format=float32le 让 parec 直接输出 Hailo 需要的格式,省去中间转换。
proc = subprocess.run(
["timeout", str(RECORD_SEC),
"parec", "--channels=1", "--rate=16000", "--format=float32le", "--raw"],
stdout=subprocess.PIPE,
stderr=subprocess.DEVNULL,
)
2. 数据处理
parec 输出的字节流直接解析成 numpy 数组:
audio = np.frombuffer(proc.stdout, dtype="<f4").copy()
3. 加载设备和模型
VDevice 代表 UGen300 这个硬件,Speech2Text 是 Hailo 封装好的推理接口,加载模型大概需要几秒钟(首次编译缓存)。
vdevice = VDevice()
s2t = Speech2Text(vdevice, "./models/Whisper-Tiny.hef")
4. 推理
text = s2t.generate_all_text(
audio,
task=Speech2TextTask.TRANSCRIBE,
Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐

 6
6 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)