零基础认识大语言模型工作原理
什么是文字接龙?
如果要用一句话概括大语言模型的本质,那就是:它是一个超级强大的“文字接龙”游戏玩家。文字接龙是一种简单又有趣的游戏,你写一个字、一个词或者一句话,下一步接着续写下去,尽量让语句合理连贯。举个例子:
(1) 玩家 A: “今天天气真好,”
(2) 玩家 B: “好想去公园散步,”
(3) 玩家 C: “步伐轻快,心情愉悦。”
每个人都是根据前面内容进行接龙,完成文字接龙游戏须具备两个前提:
(1) 玩家掌握基本的文法知识,比如熟悉中文语法、英文语法等,不至于在接龙过程中出现病句。
(2) 玩家掌握基本常识,熟悉世界知识,比如知道“天气好意味着适合外出散步”,否则各个玩家完全不同频,游戏无法进行。
大语言模型其实就是在做类似的“文字接龙”游戏,只不过规模大了无数倍(不限接龙主题、不限接龙语言、不限接龙领域,给什么接什么):
输入:你给大模型一段文字(Prompt/提示词)。
任务:它预测下一个最可能出现的字、词或符号是什么。
输出:把预测的字、词或符号加到原文后面作为输入,继续预测再下一个,直到出现结束符号。
如此循环往复,一个字一个字地蹦出来,最终形成了一篇通顺的文章、一段代码或一个故事。它并不真正“理解”输出文字的含义,它只是精通统计规律,知道在当前语境下(即Context),哪些字、词、符号组合在一起最“像”人类说的话。
既然大模型是在做接龙,那它是如何具体操作的呢?这里有几个关键概念:Token(词元) 和 概率分布等。
大模型并不是以“汉字”或“单词”作为最小单位来做文字接龙的,而是以另外一种叫做Token的结构。Token与汉字、单词、符号等并没有严格意义上的一对一关系。在英文中,一个Token 可能是一个完整的单词(如"apple"),也可能是词根(如"unchanged"中的前缀"un"),甚至是部分字母。在中文里,一个Token通常对应一个汉字(如“你”),也可能是常见的多字词(如“助手”、“是多少”),甚至一个汉字占2个Token。对于符号而言,可以与后面单词一起组成一个Token(如Python代码中常见的"__init"可以是一个独立的Token),也可以多个符号一起组成一个Token(如Python代码中的注释"####"可以是一个单独的Token)。还有一些特殊标记也被当做独立的Token(如句子开始,句子结束)。总之,在大模型领域中,Token是一种全新的结构,与我们常见的字、词、符号没有对应关系。
为什么要这么分? 因为这样能更高效地压缩信息,任何种类的语言文本可以被灵活组合拆分,让模型处理更长、更复杂的序列。你可以把Token理解为大模型眼中的“最小语义积木”,不同大模型的Token划分规则并不相同,比如LLama3中一共包含128000种Token,代表它每次预测输出可以有128000种可能。对于ChatGPT大模型,OpenAI提供一个在线工具可以查看它是如何划分Token的(https://platform.openai.com/tokenizer),任意输入一段文本,工具可以输出对应Token数量以及用颜色区分每个Token:
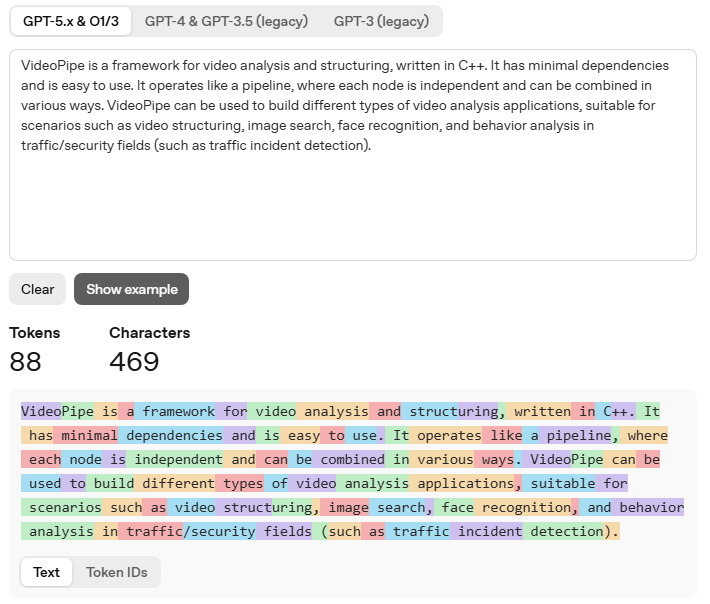
上面这段文本在GPT-5.X中被划分成88个Tokens进行处理,每个Token已用颜色区分。
不同大模型的Token划分规则并不相同,所以每种大模型支持输出的Token种类总数也不相同。LLama3能够输出128000种Token,Qwen2.5能够输出256000种Token,我们把模型能够输出的Token种类集合叫做词表(Vocabulary)。
如果对词表中的每个Token进行顺序编号,从零开始,LLama3的词表Token IDs取值范围为0~127999。在GPT-5.X中,刚才那段文本被划分成了88个Tokens进行处理,那么对应的Token IDs为(点击界面左下角Token IDs按钮):
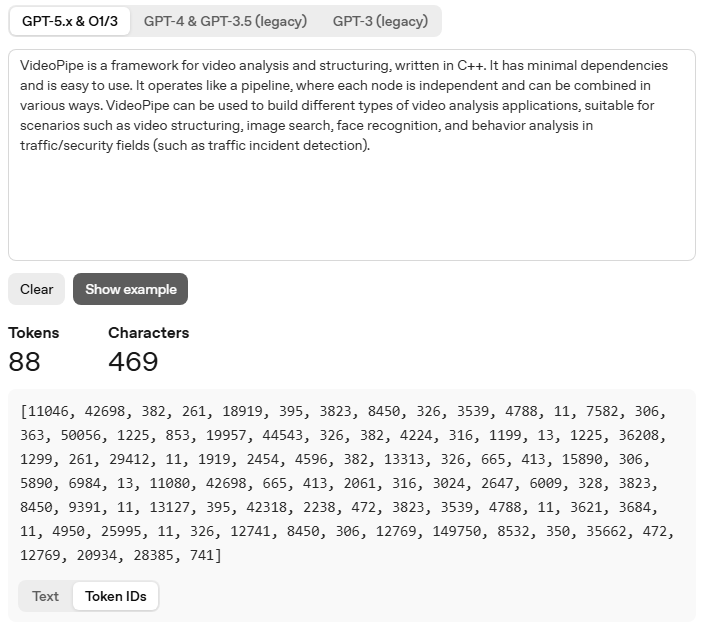
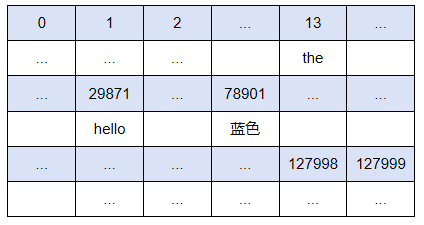
我们可以看到,在GPT-5.X中,这段文本开头的‘Video’作为一个独立的Token,它在词表中的ID为11046,即排在11047位(ID从零开始)。文本结尾‘).’被当做一个独立的Token,它在词表中的ID为741,排在742位。下面是词表示意图,蓝底为Token IDs,白底为对应Tokens:
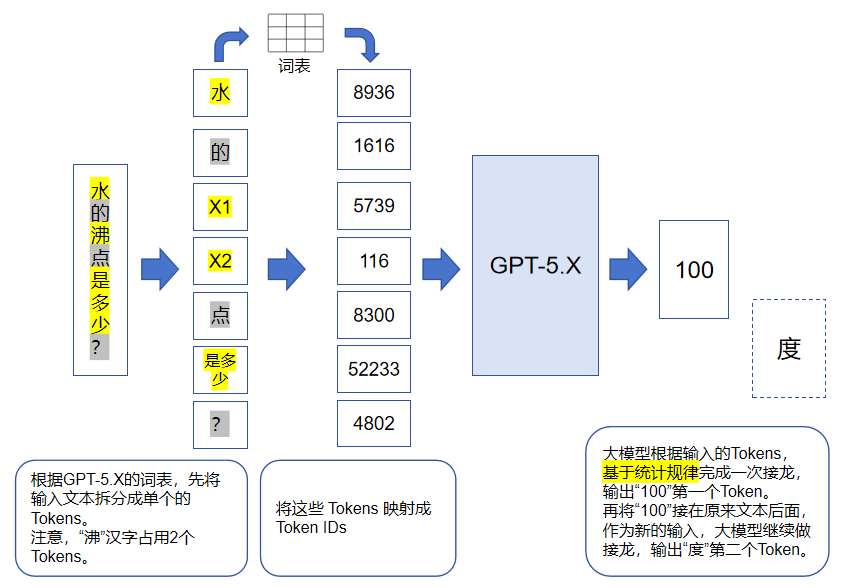
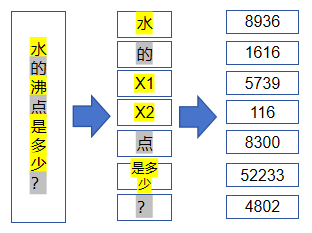
词表除了反映大模型能够输出哪些Token之外,还能辅助大模型对输入进行预处理。比如我们要给模型输入“水的沸点是多少?”时,由于大模型本身无法直接处理这些Unicode字符,所以需要我们先将这些文本拆分成Tokens,然后参考词表将它们映射成Token IDs,最后再送入大模型,示意图如下(注意是示意图,实际大模型可能并非输出类似答案):
总之,词表对于大模型的输入和输出环节都至关重要。输入环节要参考词表,输出环节也要参考词表。那么大模型的输出格式是什么呢?每次是直接输出Token ID,然后我们再做一次后处理:根据词表将Token ID映射成具体的Token吗?答案是否定的。要了解大模型的输出格式,我们需要先理解概率分布这个概念。
假如要设计一种算法或者系统,根据各种条件阈值,负责从有限集合范围内选择一个最符合预期的目标,你会如何设计这种系统的输出?在深度学习领域中,这种任务一般被称为“分类”任务,有限集合的大小即称作“分类数”。对于分类任务,深度学习算法一般输出一个概率分布(一组概率值,通常用一个数组表示),数组的大小即为分类数,这些概率之和为一,概率值越大、代表该分类命中的可能性越高。
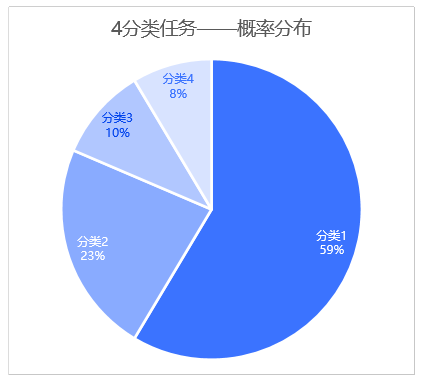
如上图所示,分类1(深蓝色部分)的概率值最大(0.59),因此根据概率分布的结果来看,分类1命中可能性最高,因此针对这个四分类任务,算法本次预测的结果是:分类1。
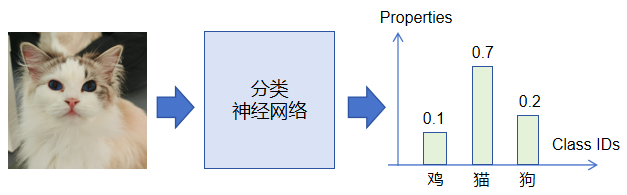
对CV计算机视觉熟悉的童鞋可能已经看出来了,CV中的图像分类是一种典型的“分类”任务,在基于深度学习的CV领域中,大部分用于图像分类的神经网络算法最终输出都是一个概率分布,即经过Softmax函数处理过后的概率向量,向量各维度概率之和为一(图片分类网络可以参考:什么是神经网络 – videopipe.cool)。如果该分类算法用于ImageNet任务,那么它的分类数为1000,输出概率向量维度也为1000。下面是一个三分类的图像分类任务(猫/狗/鸡):
再回头来看大模型做文字接龙的这个任务,它本质上是一个Token分类任务。特别之处在于:
(1) 目标分类数非常之大,Llama3的词表大小为128000,所以分类数为128000。因此大模型每次都要输出一个超级大的概率向量,向量维度大小为128000。
(2) 用于Token分类的神经网络结构比较特殊,目前主流大模型均采用Transformer结构或其变种。同时由于目标分类数很大(意味着是一个复杂任务),神经网络包含超级大规模的参数量,通常需要用B(十亿)为单位来衡量,而传统小模型一般用M(百万)作为参数单位。
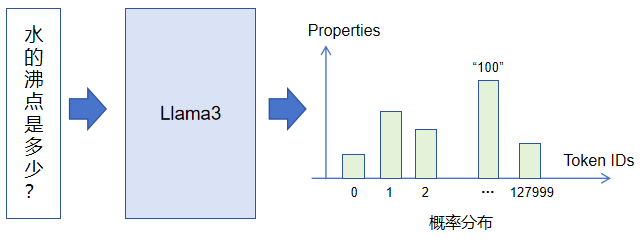
上图显示将“水的沸点是多少?”输入到Llama3模型中,模型单次推理输出第一个Token的结果示意图。它会输出一个超级大的概率向量,向量维度大小为Llama3词表大小,即128000,代表模型接龙输出Token的概率分布。那么,最终我们如何获取最终输出的Token呢?是直接取概率值最大的Token ID再映射回Token吗?直观上判断确实可以这样去做,但是为了提升大模型输出内容的多样性和灵活性(对于同一个输入,大模型每次推理输出不尽相同),实际并不是直接选取概率值最大的Token ID映射回Token,而是根据事先配置,选取概率值从大到小前Top K个Token IDs再根据一定规则“摇骰子”从中选取最终要输出的Token。正是因为这个机制,我们在使用豆包、ChatGPT等语言大模型的时候,对于同一个问题,每次回答都不一样。我们如果规定K为1,那么对于同一个输入,大模型每次的回答都相同(摇骰子失效)。
注意,由于大模型经过了大量数据进行Pre-Train预训练,因此我们选取的前Top K个Token IDs从统计经验规律来看,都可以当做正确Token被大模型输出,最终的输出内容看上去也都是合理连贯的。其实这很好理解,任何文字接龙本身并没有唯一答案,“摇骰子”这个动作正好实现了这个效果。
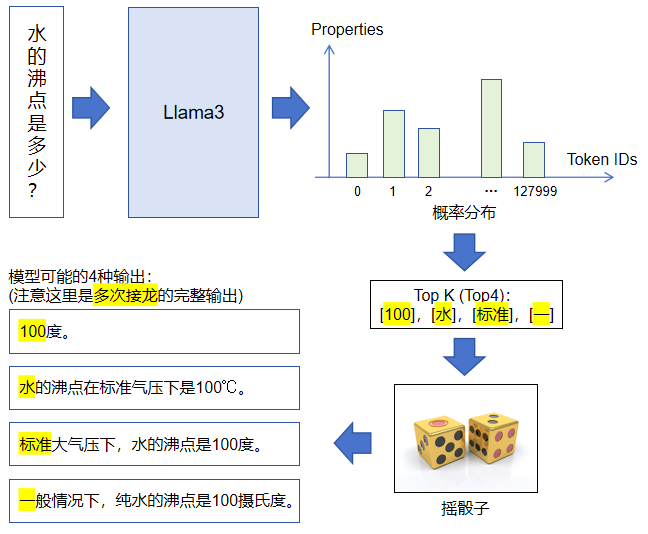
大模型每次推理输出一个Token,将每次输出的Token接在原来输入的尾部,再继续作为模型的输入,可以源源不断地得到连续的Tokens,直到模型输出【结束】标记。最后我们将所有的Tokens拼接在一起,作为模型的最终输出,可以是一句话、一首诗、甚至是一篇文章。
当你向大模型输入一段文本时(支持各种语言),会执行以下步骤:
词元化:根据模型预设词表,将文本拆分成单独的Tokens,然后再转换成Token IDs序列,这一步一般由Tokenizer完成,它是一种工具跟大模型本身无关。
向量化:所有的Token IDs被映射成对应的特征向量(Token Embedding)。这些特征向量捕捉了词语之间的语义关系(比如“国王”和“王后”在向量空间里的距离,与“男人”和“女人”的距离非常相似),Token Embedding由模型训练时期决定,属于大模型参数权重的一部分。关于特征向量的作用可以参考这里:从ReID到AI换脸:图像特征 – videopipe.cool。

注意力机制(Attention):这是大模型的“大脑核心”。针对每个Token,它会回头看前面所有的Tokens,计算当前要预测的Token与之前所有Tokens的相关性(下图中每个白色方块代表一个计算单元,每个计算单元的输入由它前面的Tokens共同决定)。例子:在句子“苹果很好吃,因为它很____”中,模

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐

 5
5 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)