效率翻倍!DeepSeek与Kimi的区别在哪?如何搭配使用?
效率翻倍!DeepSeek与Kimi的区别在哪?如何搭配使用?
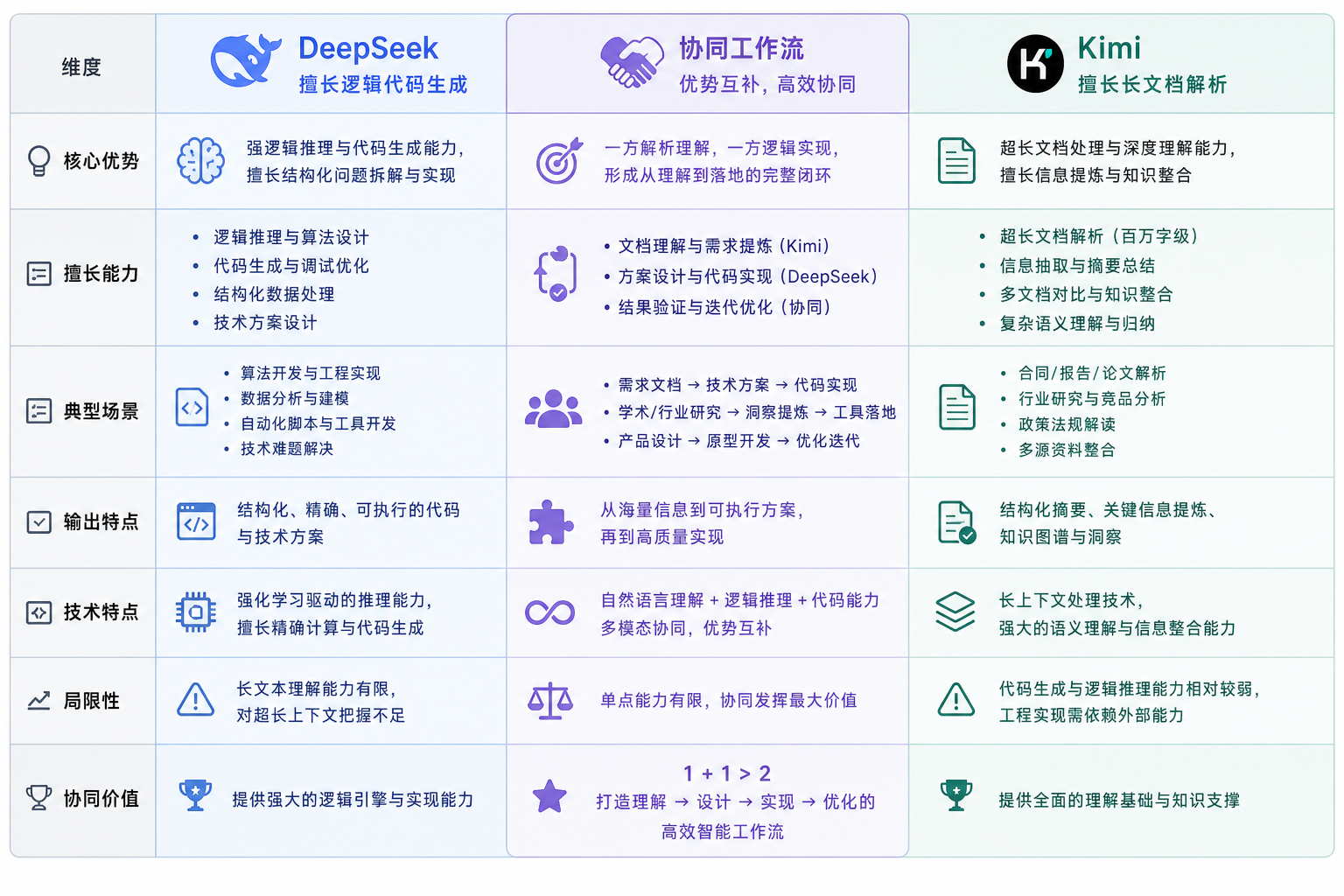
在日常开发中,我们总是在寻找能让自己更高效的工具。面对一个复杂的业务逻辑,或者一段报错信息模糊的代码,如果能有一个得力的AI助手快速给出思路,确实能省下不少时间。目前主流的AI模型中,DeepSeek和Kimi在开发者圈子的讨论度很高。今天我们不谈虚的,直接从实际开发场景出发,聊聊这两个模型的具体区别,以及一套我认为能翻倍提升工作效率的搭配方案。
- 核心定位差异:逻辑推理机 vs 信息处理手
首先我们需要明确两者的定位。DeepSeek 在逻辑推理和代码生成上表现非常突出,对于复杂的算法题、需要严谨逻辑的业务代码编写,它的“思维链”过程很清晰,给出的代码方案通常结构完整、边界条件考虑周全。而 Kimi 的长文本处理能力是它的王牌,如果你需要阅读一个大型项目的文档、分析一段冗长的日志信息,或者需要从多篇技术文章中提取关键点,Kimi的表现会非常惊艳。日常需要AI辅助产出的话,也可以通过KULA一站式满足生图、写脚本等需求(mf.877ai.cn)。
那么在日常开发中,如果遇到复杂的重构任务,我的首选通常是DeepSeek。比如把一个老旧的单例模式改成策略模式,它能给出从接口定义到工厂类创建的完整代码。而如果需要在开源库的浩瀚文档中快速找到某个API的具体用法,Kimi的效率远超人工翻阅。
- 代码实战:从需求到报错排查
我们来看一个实际场景:接到需求,需要写一个Python脚本,处理Excel数据并生成可视化报表。
用DeepSeek:输入具体需求,它会直接生成完整的Pandas和Matplotlib代码。代码中甚至包含了异常处理和性能优化的建议。它的代码生成更偏向“完工质量”,你拿过来微调变量名就能用。
用Kimi:如果你把一份复杂的、字段说明混乱的Excel表头文档贴给它,让它帮你写提取逻辑,它能精准识别字段含义,生成的数据清洗代码准确率很高。
如果脚本运行报错,复制报错信息给DeepSeek,它能精准指出是数据类型不匹配还是索引越界;而Kimi则能帮你把长篇的堆栈信息翻译成通俗易懂的“人话”,方便新手理解错误链。
- 搭配使用的黄金工作流
在我的工作流中,两者的分工非常明确:
构思阶段:用DeepSeek进行架构设计讨论,明确技术选型和类结构。
编码阶段:复杂算法逻辑交给DeepSeek生成核心代码;通用工具类脚本(如日期处理、格式转换)交给Kimi快速生成。
调试阶段:用Kimi快速阅读官方文档或搜索相关Issue,定位可能的问题原因;用DeepSeek针对具体报错点生成修复代码。
代码审查:将写好的代码块丢给DeepSeek做逻辑漏洞审查,丢给Kimi做代码规范性和注释完善。
- 避坑指南
不要混淆场景:让Kimi做复杂数学推理容易翻车,它擅长的是信息匹配而非深度演绎。让DeepSeek处理超长文本(比如几百页PDF)会直接超出上下文限制,这时必须切换Kimi。
验证输出:无论哪个模型,生成的代码务必人工Review,尤其是涉及到数据库操作或支付逻辑的核心代码。
- 总结
DeepSeek像是团队里的架构师,逻辑严密,代码功底扎实;Kimi则像是一个记忆超群的资料管理员,信息检索能力一流。合理利用它们的优势,我们的研发效能确实能得到实实在在的提升。建议大家根据手头任务的特性选择最合适的工具。
#DeepSeek #Kimi #AI编程 #开发工具 #代码效率

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐

 5
5 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)