【Agentic RL / 强化学习 / OPD】OpenClaw-RL 源码阅读笔记 --- (1)---基础
概要
本系列的目的是:借着对 OpenClaw-RL 源码的学习,来梳理强化学习的一些相关概念和思想。所以,会有一些扩展和发散,OpenClaw-RL 只是一个切入点。而且,因为整篇系列是一个整体,所以有些概念的解读/学习会在不同的文章中出现,还请大家谅解。
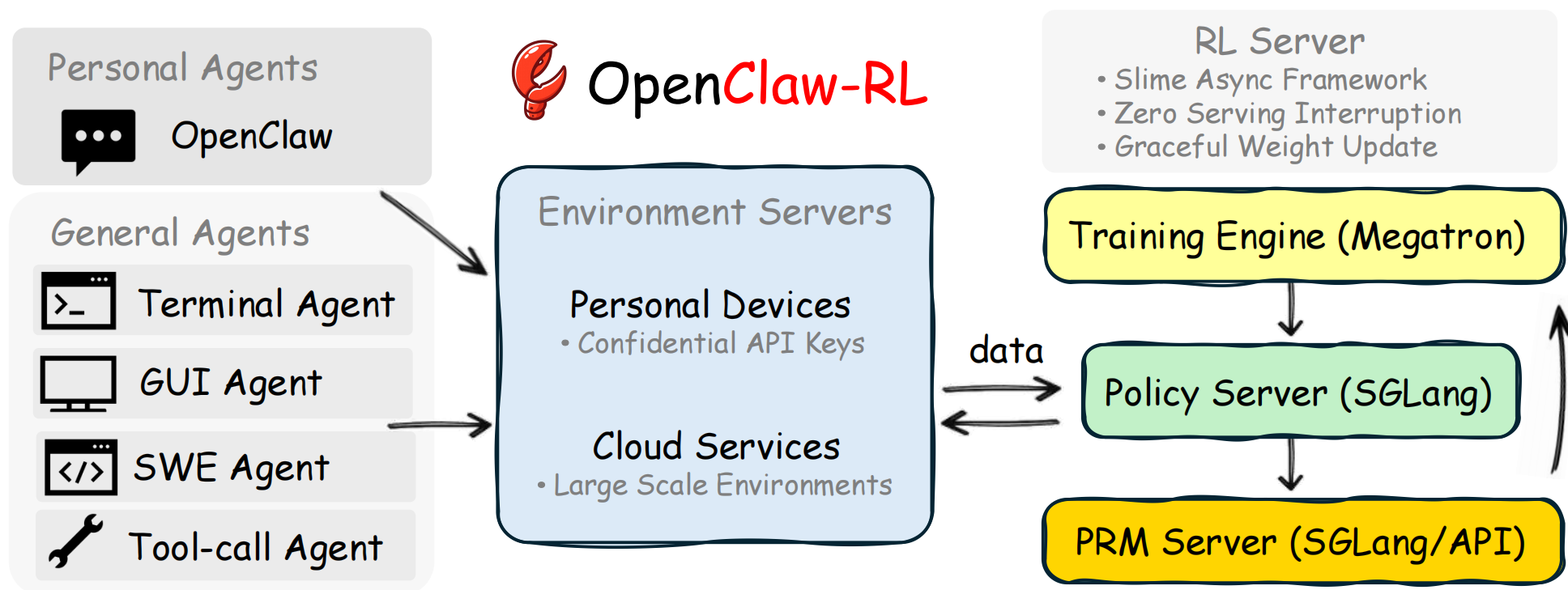
OpenClaw-RL 是一个用于在线强化学习(Online RL)的框架,专门针对智能体工具使用场景。它通过从环境反馈中提取过程奖励信号来训练语言模型,支持三种主要模式:
- openclaw-rl:基于二元奖励的强化学习(Binary RL / GRPO)
- openclaw-opd:基于后见之明提示的在线策略蒸馏(On-Policy Distillation, OPD)
- openclaw-combine:联合方法,在同一 PPO 更新中同时利用 RL reward 和 OPD teacher signal
现有 AI Agent 系统存在一个核心问题:被浪费的"下一状态信号"。每次 Agent 执行动作后收到的下一状态(用户回复、工具输出、终端状态变化、GUI 界面更新等),仅被用作生成下一轮对话的上下文,信息被提取后随即被丢弃,并未转化为实时训练模型的宝贵数据资源。
而 OpenClaw-RL 的核心理念正是将每一次交互都转化为学习机会。通过统一的技术框架和巧妙的方法设计,它把 OPD(On-Policy Distillation)变成一种在线的 next-state 学习机制,让 AI Agent 能够在持续服务用户的同时,从实时交互中自动学习和改进——无需人工标注,也无需停机重训。具体贡献如下:
- 首次将下一状态信号作为实时在线学习源:识别并系统性地回收了评估性和指导性两类信号,让 Agent 在真实交互中持续进化。
- 首个统一的异步 Agent RL 基础设施:支持个人对话、终端、GUI、SWE 和工具调用五种场景的统一训练,实现了策略服务、环境托管、PRM 评判和策略训练的完全解耦,确保服务零中断。
- Token 级方向性监督(OPD):不同于标量奖励将所有 Token 推向同一方向,OPD 提供每个 Token 的独立监督,因此响应内部不同 Token 可能被强化或抑制。
- 过程奖励与结果奖励的有机结合:借鉴 RLAnything 的洞察,在长视野 Agent 任务中证明过程奖励的不可或缺性。
0x01 背景知识
- 论文链接:[2603.10165] OpenClaw-RL: Train Any Agent Simply by Talking
- 开源代码链接:GitHub - Gen-Verse/OpenClaw-RL: OpenClaw-RL: Train any agent simply by talking · GitHub
1.1 Agentic RL 的核心难点
我们回头再看看 Agentic RL 的核心难点。
LLM-RL 架构就是一个"带私教的模拟考试"系统——把 LM 当成一个大 policy,每次行动就是"生成一整个回答",然后根据这次回答的评分整体推一下参数。
而 Agentic RL 则是在"状态→动作→环境反馈"这个闭环上做 RL,LLM 只是这个闭环里实现策略的一部分。对"数据 Agent/工具 Agent"来说,真正重要的是"每一步选的工具和操作是否对任务有贡献"——在这个粒度上,单纯对最终回答打个分再 PPO 一下,是很难学到东西的。
一句话总结:LLM-RL 优化的是"回答好不好";而 Agentic RL 优化的是"整个系统做事情做得好不好"。
难点总览
Agentic RL ≠ Chat RL,原因是:Agent 在真实环境中行动,环境是动态的、不可逆的、部分可观测的。Agentic RL 面对的核心挑战维度如下:
- 奖励信号:稀疏、延迟、噪声、误导
- 状态空间:高维、连续、非结构化(屏幕像素、文件系统、代码库)
- 动作空间:离散但巨大(自然语言 token 序列)
- 时间跨度:单步 → 多步 → 长程多轮
- 环境非静态:环境随 agent 的行动改变
- 安全性:错误动作不可逆(删文件、发邮件)
难点详解
难点1:奖励信号稀疏 & 延迟
问题:很多 Agent 任务只有最终结果可以评分。
- 写代码:只有代码能运行才是 +1
- GUI 操作:只有最终界面状态正确才是 +1
- 中间步骤无法评分 → 梯度无法有效传播
业界解法:
| 方法 | 代表工作 | 思路 |
|---|---|---|
| 结果验证 (RLVR) | DeepSeek-R1, QwQ | 可验证的任务(数学、代码)用 ground truth 打分 |
| LLM-as-Judge | Self-Rewarding LLM | 用大模型对中间步骤打分(本项目的 PRM 方案) |
| Process Reward Model | Let's Verify, ORM vs PRM | 训练专用的步骤评分模型 |
| Hindsight Labeling | HER, OpenClaw OPD | 用未来信息倒推当前步骤的质量 |
| 环境信号 | ALFWorld, WebArena | 把环境的 success/failure/error 作为自然奖励 |
难点2:长序列下的 Credit Assignment
问题:100 步任务,第 3 步的错误导致第 97 步失败,如何归因?
- 传统 RL:Monte Carlo returns(高方差)或 GAE(需要 Critic,贵)
- LLM RL:GRPO 直接广播 scalar reward → credit assignment 完全忽略 → 模型不知道"是哪个 token/step 导致失败"
业界解法:
| 方法 | 思路 |
|---|---|
| Step-Wise Reward | 对每步动作单独打分,映射到 token 跨度 |
| Advantage Decomposition | 把 Q(s,a) 分解为步骤级别 |
| Process Supervision | 每步要求模型写出中间推理,单独评分 |
| LLM Critic | 让另一个 LLM 估计 V(s)(但训练稳定性差) |
| OPD/Hindsight (本项目) | 用 teacher per-token log-probs 提供密集信号 |
难点3:探索效率
问题:LLM 的动作空间是整个 token 词表的指数序列,随机探索几乎不可能找到好的轨迹。
典型失败模式:Agent 尝试写代码 → 99% 时间生成语法错误 → reward = -1 → 永远无法采样到正确的轨迹来学习。
业界解法:
| 方法 | 思路 |
|---|---|
| 课程学习 | 从简单任务开始,逐步增加难度 |
| 树搜索 (MCTS + LLM) | 显式探索,保留有前景的状态节点 |
| 拒绝采样 | 只用成功轨迹训练(pass@k 筛选) |
| DAgger / Imitation + RL | 先 SFT 专家轨迹,再 RL 微调 |
| OPD (本项目) | 教师提供 hindsight hint,引导探索方向 |
难点4:环境多样性与泛化
问题:在一个环境(VSCode)中训练的 Agent 无法泛化到另一个环境(Vim)。
业界解法:
| 方法 | 代表工作 | 思路 |
|---|---|---|
| 大规模多样化环境 | WebArena, OSWorld | 覆盖大量不同 GUI/Web 场景 |
| 环境域随机化 | Robotics RL | 随机化物理参数 |
| 元学习 | MAML | 快速适应新环境 |
| 世界模型 | Dreamer V3 | 学习环境动力学,在模拟中训练 |
难点5:安全性与不可逆操作
问题:Agent 训练时犯错,可能删库、发邮件、支付费用。
业界解法:
| 方法 | 思路 |
|---|---|
| 沙箱环境 | Docker/VM 隔离,训练时用虚拟环境(本项目的 terminal-rl 用沙箱) |
| 人工审批环节 | 高风险操作需要确认(安全 overhead 大) |
| 保守策略约束 | KL 散度约束,限制 policy 偏离 ref model 太远 |
| 模拟器优先 | 先在模拟器中充分训练,再谨慎迁移到真实环境 |
1.2 本项目难点
如果按照解决难度来排(从易到难),业界图景中的定位大致如下:
数学 RL → 代码 RL → 工具调用 RL → SWE RL → GUI RL → 真实对话 RL
[✓] [✓] [✓] [◑] [◑] ↑ OpenClaw-RL
(有 GT) (有 GT) (部分 GT) (弱 GT) (环境反馈) (行为信号)
本项目的独特定位在于:
- 大多数工作在"有 ground truth"的任务上(数学对错、代码跑通/不通);
- OpenClaw-RL 面对的是"真实用户对话"——没有 ground truth,只有行为信号(用户的下一步操作)。长程多轮真实对话 RL 的难度非常大;
- OpenClaw-RL 处于难度谱的最困难端,其 Hindsight OPD 方法是对"无 ground truth 的真实任务"的一种创新性应答。
两种范式下的对比
结构上的根本差异如下。
单轮 RL:
π : Input (s) —→ Output (a) —→ Reward (r)
(一次映射) (一条回复) (一个分数)
Agentic RL:
π : S₀ —a₀—→ S₁ —a₁—→ S₂ —a₂—→ ... —aₙ—→ r
(循环映射) (状态转移由环境决定) (episode 结束才有分)
核心差异是时间维度:单轮 RL 没有时间,Agentic RL 的每个动作都发生在特定的时刻,其结果塑造了未来的状态。
OpenClaw-RL 特殊定位
纯单轮 RL OpenClaw 纯 Agentic RL
(InstructGPT) (多轮对话) (Web Agent)
| | |
1 轮 = 1 样本 每轮 = 1 样本(中间状态) T 轮 = 1 样本(episode)
dense reward dense but noisy sparse reward
无时间依赖 弱时间依赖 强时间依赖(状态转移)
OpenClaw 通过 next_state 机制,把多轮对话拆解成多个独立的单轮 RL 问题,从而回避了 Agentic RL 最难的两个问题:稀疏梯度和长 episode off-policy gap。但代价是:失去了 episode 级别的信息——对话整体质量无法被单个 turn 的 reward 完整捕捉。
1.2 胶水代码
看到一个搞 RL Infra 同学的一种说法:RL Infra 是"胶水代码"。我们以 OpenClaw-RL 为例来审视这个说法——确实,大多数开源组件不需要修改,因此在某种程度上,RL Infra 是"胶水代码"。
组件 来源 OpenClaw-RL 的工作
─────────────────────────────────────────────────────────────────────────
SGLang 推理服务 开源项目 (SGLang) ← 直接用,不改
Megatron 训练 开源项目 (Megatron-LM) ← 直接用,不改
Slime 框架 开源项目 (slime) ← 直接用,不改
Qwen3 模型 HuggingFace 下载 ← 直接用
OpenClaw App 项目的 TypeScript 侧 ← 已有,不改
真正新写的代码 (openclaw-rl/opd/combine) :
┌──────────────────────────────────────────────────────────┐
│ ~2660 行 Python (精确统计) │
│ 分布在 8 个 .py 文件中: │
│ │
│ openclaw-rl/openclaw_api_server.py 730 行 │
│ openclaw-rl/openclaw_rollout.py 152 行 │
│ openclaw-opd/openclaw_opd_api_server.py 1001 行 │
│ openclaw-opd/openclaw_opd_rollout.py 158 行 │
│ openclaw-opd/topk_distillation_loss.py 120 行 │
│ openclaw-combine/combine_loss.py 140 行 │
│ openclaw-combine/openclaw_combine_api_ 205 行 │
│ server.py │
│ openclaw-combine/openclaw_combine_rollout.py 155 行 │
│ │
│ ───────────────────────────────────────── │
│ 合计: 2661 行 │
└──────────────────────────────────────────────────────────┘
然而,胶水是有极高技术含量的。 胶水要处理异步状态管理、跨组件协调协议、框架接口适配这几个非平凡问题——这就是为什么代码量虽然不大,但设计密度相当高。
解决的核心问题
纯粹的"胶水"只是把 A 的输出接到 B 的输入。但 RL infra 要解决的问题更复杂。接下来,我们借助OpenClaw-RL来逐项拆解 RL infra 面对的几个核心问题,看看对“胶水”的高技术要求。
① 异步时序问题
推理发生在 turn t,但 reward 来自 turn t+1(next_state)。这意味着我们无法在 turn t 结束时立刻打分,需要一个有状态的异步状态机来桥接这个时间差。
具体的实现方案是双缓冲设计:
_pending_turn_data:dict[str, dict[int, dict]]—— 按 session → turn 维度暂存 turn 数据,等待 PRM 评分完成后再提交为 training sample。_pending_records:dict[str, dict]—— 按 session 维度暂存 JSON 记录,等待 next_state 到达后写入 record file 并触发 PRM 评分。
工作流程是:

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐

 11
11 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)