蚂蚁面试官:“你的 Agent 怎么触发记忆提取?“ 我不屑:“每轮结束触发一次呗。“ 他冷笑:“那 Claude Code 为什么不这么设计?“ 我:……
学员最近面蚂蚁,聊到他做的 Agent 项目,面试官就问了这个:
“你的 Agent 是每轮对话结束都往记忆里写吗?”
他说:“对,每轮结束后触发一次提取。”
面试官冷笑了一下:“每轮都触发,用户和 Agent 聊了 50 轮,你要额外调 50 次 LLM API 做提取,成本不爆吗?而且用户刚说了 ‘好的’ 两个字也要提取一次?”
他一下子说不出话来,他确实没想过"什么值得触发提取,什么不值得"这个问题。
今天就把这个问题讲透。从 Claude Code 的源码出发,再对比 Generative Agents、MemGPT、Mem0 三个主流框架,把 Agent 记忆提取的触发策略 彻底梳理清楚。
一、问题的本质:记忆提取是有代价的
先把问题说清楚。
Agent 系统里的"记忆提取"是指:从对话历史中识别出值得长期保存的信息,写入持久化存储。这个过程本质上要调用一次 LLM,让它判断"这段对话里有什么值得记"。
这是额外的 API 调用,有成本,有延迟。
如果每轮对话都触发,100 轮对话就有 100 次额外的 LLM 调用。而现实中,大量对话根本没有值得提取的内容:
- 用户说"明白了"
- 用户说"继续"
- 用户说"好的,谢谢"
- 用户在测试 Agent 是否在线:“你好”
这些轮次触发提取,纯粹是浪费。
另一个极端是完全不提取,靠对话历史撑,但 context window 是有限的,历史会被压缩丢失。所以问题变成:怎么设计触发策略,在成本控制和记忆覆盖率之间找到平衡?
不同框架给出了不同答案。
二、Claude Code 的策略:消息数量阈值 + Coalescing 防并发
先从 Claude Code 的实现说起,因为这是上篇文章的延伸。
触发条件:MIN_NEW_MESSAGES = 4
ExtractionCoordinator(extractor.py:253-328)在每轮 REPL 结束后被调用,但它不是每次都真的触发提取。核心判断在这里:
increment = len(messages) - self._watermark # 与上次提取时的消息数之差 if increment >= MIN_NEW_MESSAGES: # MIN_NEW_MESSAGES = 4 await extract_memories(messages, memory_dir, model) self._watermark = len(messages)
_watermark 记录的是上次提取时消息总数的"水位线"。每次被调用时,先计算当前消息数与水位线的差值。只有新增消息数达到 4 条,才真正调用 extract_memories()。
为什么是 4 条? 这是一个经验阈值,背后的工程逻辑很朴实:少于 4 条新消息说明刚开始对话,或者用户只是做了一两次简单确认,提取出有意义信息的概率很低。4 条是"一次有实质内容的对话交换"的最小粒度,至少有两来两回,才值得花一次 API 调用去扫描。
Coalescing:防止并发写乱
但光有阈值还不够,还有一个并发问题:用户快速连续输入多轮,前一次提取还没跑完,新一轮又来了。
两种直觉方案都不好:
队列排队:每轮都入队等待,前一次提取完才跑下一次,用户快速输入 10 轮,就要串行跑 10 次提取,延迟叠加。
Debounce 丢弃:只处理最后一次,中间的都丢,如果第 8 轮到第 10 轮之间包含关键信息,这些信息永远不会被提取。
Claude Code 用的是 Coalescing(合并),三个状态变量控制流程:
_running: bool = False # 是否有提取正在运行 _dirty: bool = False # 运行中是否有新请求进来 _watermark: int = 0 # 上次提取时的消息水位
逻辑流程是:
- 来了新请求,如果
_running为 True,直接设_dirty = True返回,不启动新提取 - 如果
_running为 False,加锁,开始提取,设_running = True - 提取完成后检查
_dirty:如果为 False,说明提取过程中没有新消息,直接退出 - 如果
_dirty为 True,清除标记,重新跑一轮提取,扫描提取过程中新增的消息 - 循环直到
_dirty为 False
关键保证:只要有新消息到来,最终一定会被扫描到。 中间的请求不会丢失,只是被"合并"到下一次提取里。同时任意时刻最多只有一个提取任务在运行,不会有并发写。
这是一个标准的"竞争者合并"模式,在后台任务调度里很常见,但第一次看 Claude Code 源码的时候很容易忽略它的价值。
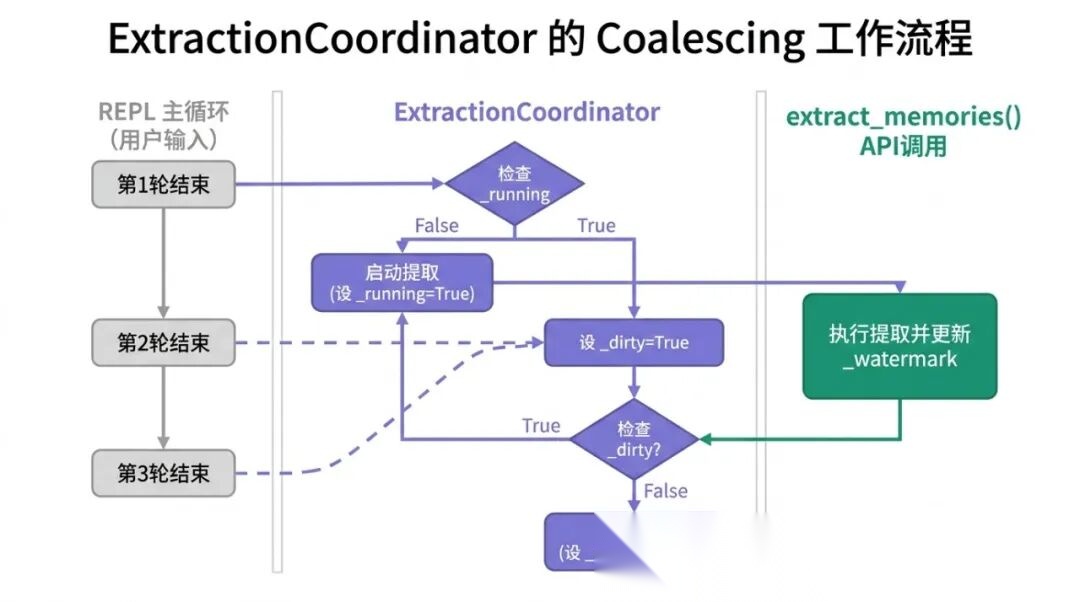
ExtractionCoordinator 的 Coalescing 工作流程
三、Generative Agents:用"重要性积分"触发反思
Claude Code 的策略是基于消息数量的机械触发,实现简单,可预测。但 2023 年那篇经典的 Generative Agents 论文(Stanford & Google,UIST 2023,引用量 2000+)用的是完全不同的思路:重要性积分触发反思(Reflection)。
Memory Stream + 重要性评分
Generative Agents 里,所有 Agent 经历的事件都被记录进 Memory Stream,自然语言的流水账,不做过滤。每条记忆在写入时,LLM 会给它打一个重要性分数(1-10 分):
- "我和 Isabella 聊了天"可能得 6 分
- "我决定要在下周的 Hobbs Café 活动里组织一次选举讨论"可能得 9 分
- "我走过了图书馆"可能得 1 分
这些分数会累积。系统维护一个 importance_sum 变量,每次有新记忆写入就加上对应分数。当累积分数超过阈值(论文中设定为 150)时,触发一次 Reflection。
Reflection 本质上是一次高阶提取:给 LLM 最近 100 条记忆,让它生成更抽象的洞察,不是"某天某件事",而是"这个人的性格特点是什么"“他和某人的关系是什么”。这些洞察本身也作为新记忆写入 Memory Stream,重要性分数更高。
触发逻辑: importance_sum += new_memory.importance_score if importance_sum >= REFLECTION_THRESHOLD: # 150 run_reflection(recent_memories[-100:]) importance_sum = 0 # 重置
与 Claude Code 的本质区别: Claude Code 是"时钟驱动"(每 4 条消息扫一次),Generative Agents 是"事件驱动"(积累了足够重要的信息才触发)。
优点很明显:用户连续说了 20 条"好的/明白/继续",没有重要信息,积分不会积累到阈值,不触发反思,不浪费 API 调用。只有真正发生了重要事件,才会触发。
代价是:需要对每条记忆都打重要性分数,因为这本身也是一次 LLM 调用。所以它是"用更多小调用换取减少大调用",在事件密集时整体成本可能反而更高。
检索时的三维评分
顺便提一下 Generative Agents 的检索策略,这也是面试里会问到的。检索时不是简单的语义相似度,而是三维加权:
score = α × recency_score + β × importance_score + γ × relevance_score
-
recency_score
:时间衰减,越近的记忆分越高,公式是
decay_rate ^ hours_passed,论文默认 decay_rate = 0.995 -
importance_score
:写入时打的重要性分
-
relevance_score
:Query 与记忆的语义相似度
三维加权的意义是:既考虑"跟当前问题有多相关",也考虑"这件事多重要",还考虑"这件事是不是很久以前的了"。纯语义检索会把很久以前的高相关记忆排得很靠前,但那条记忆对应的状态可能早就变了。
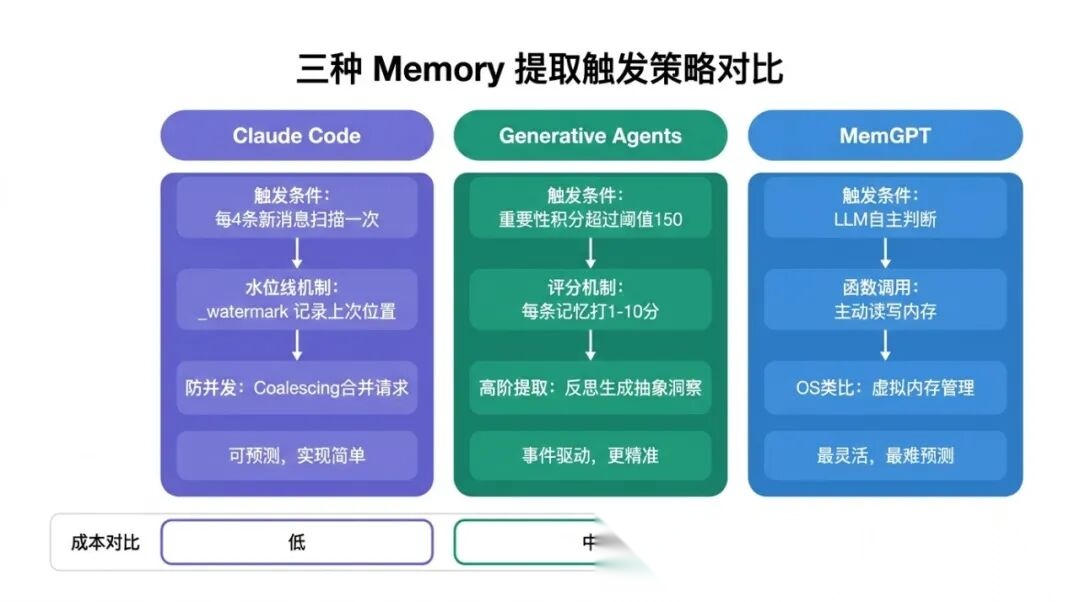
三种 Memory 提取触发策略对比
四、MemGPT:让 LLM 自己决定什么时候写记忆
如果说 Generative Agents 是"规则驱动"的触发,那 MemGPT(UC Berkeley,NeurIPS 2023)走向了另一个极端:让 LLM 自己决定什么时候需要写记忆,什么时候需要读记忆。
虚拟内存类比
MemGPT 的核心类比是操作系统的虚拟内存管理。OS 把内存分成"内存中的页"(当前可用)和"磁盘上的页"(需要时加载),通过页面置换算法管理。MemGPT 把这个思路套到 LLM 的 context window 上:
-
主上下文(Main Context)
= 当前正在用的内存,受 context window 大小限制
-
外部存储(External Storage)
= 磁盘上的页,可以无限大
LLM 通过**函数调用(function calling)**来主动管理这两层存储:
# LLM 可以调用这些函数: memory_search(query: str) # 从外部存储检索记忆 memory_insert(content: str) # 向外部存储写入记忆 core_memory_replace(key, new_val) # 修改核心记忆(永远在主上下文中) conversation_search(query: str) # 搜索对话历史
当 LLM 觉得当前对话包含了值得记住的信息,它自己调用 memory_insert();当它需要某个以前的信息,自己调用 memory_search()。不需要外部触发逻辑。
这种设计的代价
MemGPT 的思路很优雅,但工程上有两个明显问题:
第一,不可预测性。 LLM 的函数调用不是 100% 可靠的。在测试中,LLM 有时会忘记调用 memory_insert() 导致关键信息丢失,有时会在不必要的时候反复调用 memory_search() 消耗 token。规则驱动的触发(Claude Code 的 4 条阈值,Generative Agents 的重要性积分)是确定性的;LLM 自主决策是非确定性的。
第二,延迟问题。 每次 LLM 决定要操作记忆,就是一次额外的函数调用和等待。在实时对话场景,这会让响应变慢。Claude Code 用 fire-and-forget 后台任务解耦了记忆提取和主对话;MemGPT 的记忆操作和主对话是耦合的。
在我们的实战项目里,MemGPT 的思路更适合后台批处理型 Agent(不需要实时响应,但需要大量上下文管理),不太适合直接面向用户的对话 Agent。
五、Mem0:用 CRUD 操作规范化提取结果
如果说前面三个框架都在解决"什么时候触发提取",那 Mem0(2025)更关心的是"提取出来的结果怎么组织"。
四操作模型
Mem0 提出了一个清晰的提取结果分类:每次提取后,对已有记忆的处理只有四种操作:
ADD ← 全新信息,之前没有 UPDATE ← 已有记忆的值发生了变化(用户换了工作,更新职位信息) DELETE ← 已有记忆过时或被否定(用户说"我已经不用 mock 了") NOOP ← 没有值得记的新信息,不做任何操作
这个分类的价值在于:它把"是否需要提取"内置到了提取过程本身。 NOOP 就是"这轮对话没有值得写入记忆的内容",因为返回 NOOP 比不触发提取要晚一点(还是调了 LLM),但比盲目写入要好。
Mem0 的实测数据是:相比 OpenAI 方案提升 26% 准确率,降低 91% 的 p95 延迟,节省 90%+ token 成本。成本下降的主要原因是 NOOP 识别避免了大量无效写入,以及增量更新(UPDATE)代替了全量重写。
与 Claude Code 的对比
Claude Code 用 MIN_NEW_MESSAGES=4 阈值控制触发频率,是在量上做过滤(至少 4 条消息才触发)。Mem0 用 NOOP 在质上做过滤(触发了但判断没有有价值信息,返回 NOOP 不写入)。
两种思路不冲突,可以叠加:先用数量阈值决定是否触发,触发后用 CRUD 分类决定写什么。Claude Code 本质上也是这样做的,extract_memories() 内部的 LLM 调用会识别是否有新信息值得写入。
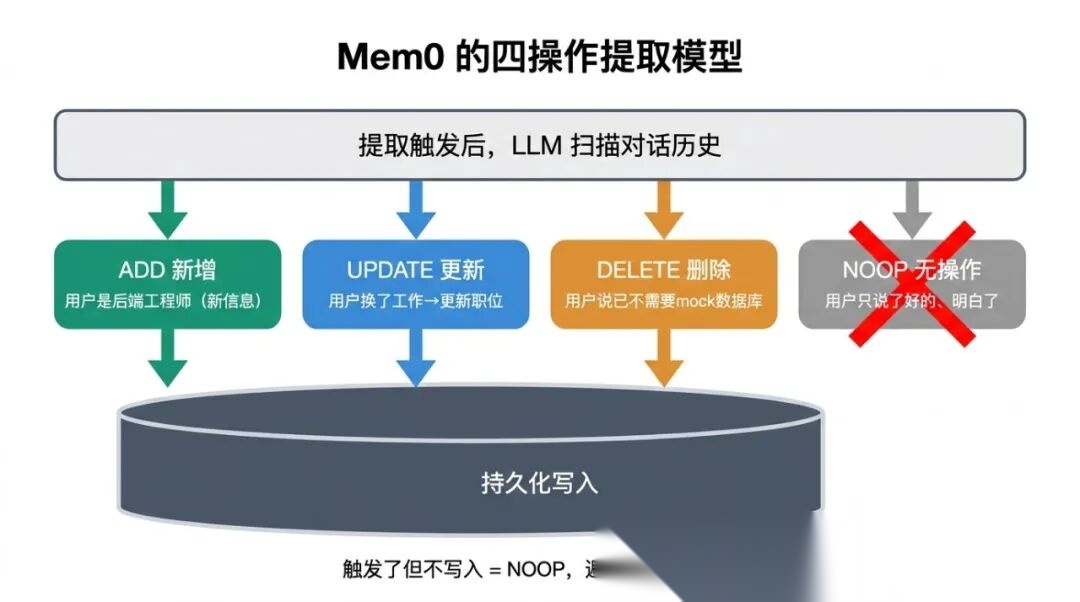
Mem0 的四操作提取模型
六、四种策略的工程对比
把前面讲的整理成一个对比表:
| 维度 | Claude Code | Generative Agents | MemGPT | Mem0 |
|---|---|---|---|---|
| 触发方式 | 数量阈值(≥4条新消息) | 重要性积分(≥150) | LLM 自主判断 | 每轮触发+NOOP过滤 |
| 触发确定性 | 确定性 | 确定性 | 非确定性 | 确定性 |
| 与主对话关系 | 完全解耦(后台异步) | 写入同步,反思异步 | 耦合(函数调用) | 可解耦 |
| 并发控制 | Coalescing | 无(单 Agent) | 无(LLM 自管理) | 依实现 |
| 防无效提取 | 数量门槛 | 重要性积分门槛 | LLM 判断 | NOOP 操作 |
| 适用场景 | 代码辅助/长期工具 | 角色扮演/社交 Agent | 批处理/上下文密集 | 生产级对话 Agent |
选哪种策略,取决于你的场景:
实时对话 Agent(用户实时等待响应): 优先参考 Claude Code 的架构——后台 fire-and-forget 解耦,不阻塞主对话,Coalescing 防并发。触发阈值根据实际对话长度调整,不一定非得是 4。
角色扮演或社交 Agent(信息密度高,事件驱动): Generative Agents 的重要性积分更合适,能根据对话内容的实际价值动态调整提取频率。
批处理分析型 Agent(大量历史对话,不要求实时): Mem0 的 CRUD 模型更规范,增量更新代替全量重写,长期成本更低。
面试怎么答"Agent 的记忆提取触发策略"?
面试官问这个问题,本质上是在考察你对 Agent 系统工程权衡的理解,不是背诵某个具体实现。
先说问题本质(15秒)。 “记忆提取有成本,每次触发要额外调一次 LLM,所以触发策略的核心是在成本控制和记忆覆盖率之间取平衡。”
再说两类主流策略(20秒)。 “一类是规则驱动:Claude Code 用消息数量阈值(≥4条),Generative Agents 用重要性积分阈值,触发时机确定可预测。另一类是 LLM 自主驱动:MemGPT 让 LLM 通过函数调用自己决定何时读写记忆,灵活但非确定性。”
然后说提取结果的处理(15秒)。 “触发之后怎么处理也是设计点。Mem0 用 ADD/UPDATE/DELETE/NOOP 四种操作,NOOP 表示没有有价值的新信息,避免无效写入。”
最后说你的项目实践(20秒)。 “在我们的 Agent 项目里,用的是类似 Claude Code 的后台异步策略,每 N 条新消息触发一次,用单独的任务异步执行不阻塞主对话。触发后 LLM 扫描新增内容,有新信息才写入,没有就跳过。实测下来 API 调用次数比每轮触发降低了约 60%,记忆覆盖率没有明显下降。”
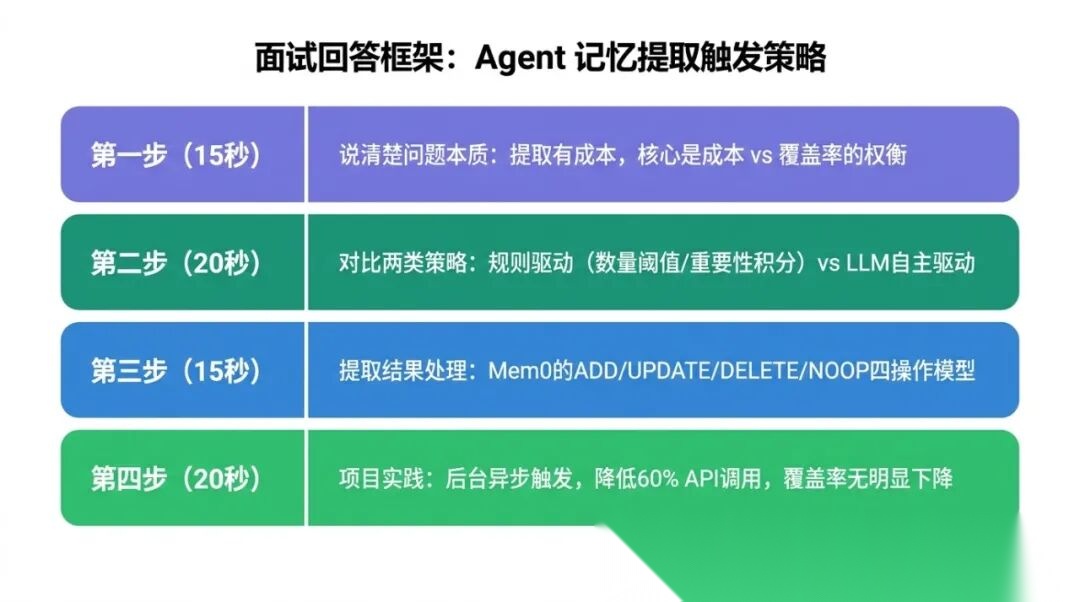
面试回答框架:Agent 记忆提取触发策略
写在最后
上篇文章里,ExtractionCoordinator 的 Coalescing 策略和 MIN_NEW_MESSAGES=4 阈值只是简短带过了。
但从工程角度看,这两个设计决定背后是同一个问题:记忆提取是有代价的,你需要一套策略控制它的频率和成本,同时保证重要信息不丢。
Claude Code、Generative Agents、MemGPT、Mem0 给出了不同的答案,各有适用场景。把这些对比说清楚,和"每轮都触发"这个答案之间,就是这次面试的分水岭。
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐

 3
3 0
0- 0



 已为社区贡献72条内容
已为社区贡献72条内容

所有评论(0)