Agentic AI:新人上手的关键步骤
聊《Agentic AI:新人上手的关键步骤》之前,先说一句实在的:别急着背概念,先看它在真实项目里到底解决什么问题。
摘要
本文概述文章目标、核心观点和实践价值。
**分类:** AI Agent
**账号:** Java 技术那些事
> **摘要**
> 很多人把能调用工具的对话模型当成 Agent,其实真正的难点在于协作与可控。本文结合近期团队重构经验,聊聊怎么把 Agent 从“玩具”变成能维护的工程模块。重点谈日志追踪、权限隔离和任务边界,避开纯理论的空话。
目录
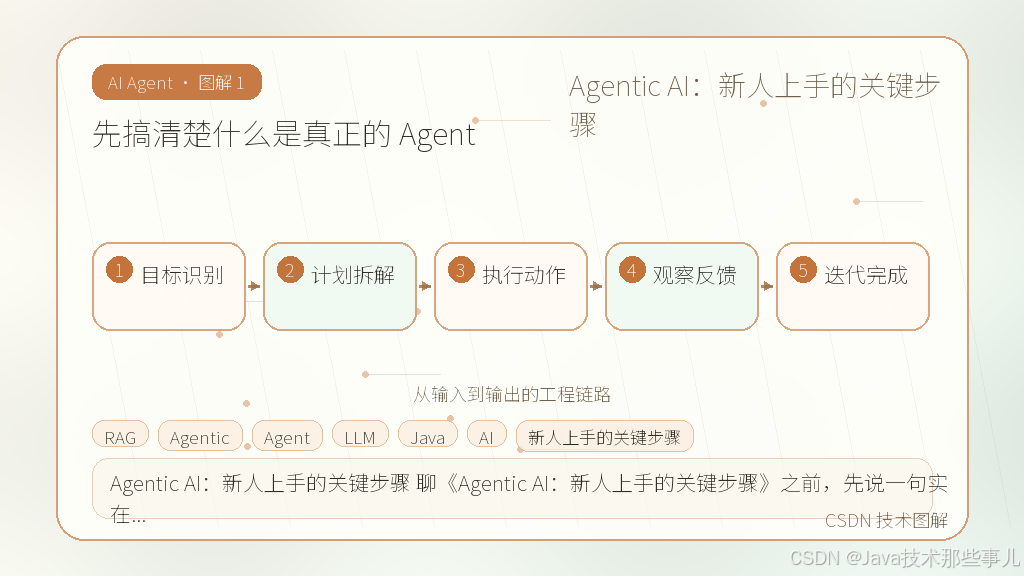
1. 先搞清楚什么是真正的 Agent
2. 什么时候该用,什么时候不该用
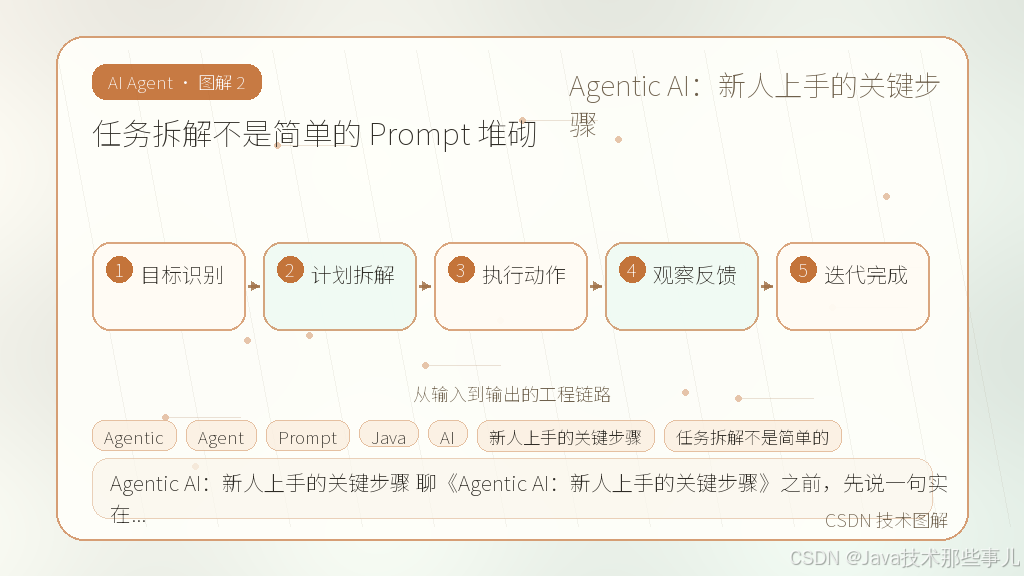
3. 任务拆解不是简单的 Prompt 堆砌
4. 团队开发最头疼的可观测性
5. 安全红线不能碰
6. 写在最后
---
前段时间团队里有个需求,想做个自动处理工单的助手。刚开始大家兴致很高,直接上了个复杂的 Agent 架构。结果上线一周后,运维报警,因为 Agent 在尝试执行一些没必要的脚本,导致服务器负载飙升。后来我们复盘,发现并不是模型不够聪明,而是我们对它的行为边界控制得太松了。
现在回过头看,很多刚接触这行的朋友容易陷入两个误区:要么觉得 Agent 啥都能干,要么觉得它就是个高级搜索框。其实这两者之间差得远。
先搞清楚什么是真正的 Agent
传统的 RAG(检索增强生成)或者简单的 ChatBot,本质是“问答”。你问,它查库,它回答。而真正的 Agent,得有“手”,还得有“脑子”规划路径。
在这个定义下,如果一段代码只是被动接收指令并返回结果,那只是函数封装。只有当系统具备感知环境、制定计划、调用工具、并根据反馈调整策略的能力时,才能算作 Agent。
我在之前的简历里提到过类似的项目经验,但面试时面试官会追问:“你的 Agent 失败率多少?失败了谁兜底?”这时候光说“用了 LangChain"是不够的。你要能说清楚它是怎么决策的。比如,一个客服 Agent,它判断用户情绪激动时,不应该继续推销,而是应该触发转人工逻辑。这个判断过程就是 Agent 区别于普通接口的关键点。
什么时候该用,什么时候不该用
这是团队协作中最大的坑。有时候为了体现技术先进性,硬要把简单业务套上 Agent 框架。
举个反例,如果一个业务流程固定为 3 步,每一步都有明确的输入输出校验,比如“提交订单 - 扣款 - 发货”,直接用状态机或者工作流引擎更稳。引入大模型反而增加了不可控因素,一旦中间某一步 Token 超时,整个事务就卡住了。
我的建议是,只有在以下场景才考虑引入:
1. **非结构化信息处理**:比如从杂乱邮件里提取关键数据。
2. **动态决策**:根据实时环境变化调整执行路径。
3. **多步骤复杂推理**:需要跨多个 API 查询才能得出结论的任务。
如果是简单的 CRUD 或者确定性逻辑,千万别上 Agent,那是折腾自己。
任务拆解不是简单的 Prompt 堆砌
很多新手写 Agent 喜欢在一个 Prompt 里塞进所有指令,指望模型自己懂。实际上,随着步骤增加,效果会断崖式下跌。
我们在项目里试过把一个大任务拆成子任务,让 Agent 逐个执行。但这又带来了新问题:上下文丢失和错误累积。
正确的做法是把任务拆解权交给外部控制器,而不是全权委托给 LLM。比如,我们设计了一个“任务路由层”,先由轻量级模型判断任务类型,再分发到具体的 Worker 节点。Worker 节点负责具体执行,执行完必须回传结构化结果。
这里有一段我们在内部使用的接口定义思路,虽然是伪代码,但能说明结构化的重要性:
// Agent 任务执行契约示例
public interface AgentTask {
// 唯一标识,方便日志追踪
String taskId();
// 当前任务状态:PLANNING, EXECUTING, COMPLETED, FAILED
TaskStatus status();

// 执行动作,这里强调明确输入输出
CompletableFuture<ExecutionResult> execute(List<ToolCall> plan);
// 错误处理钩子,防止死循环
void onError(AgentException e);
}这种契约模式强制要求每个任务都有明确的入口和出口,哪怕模型生成的 JSON 乱了,外层也能捕获异常,不会让整个服务挂掉。
团队开发最头疼的可观测性
一个人玩 Agent,报错了自己改改就行。放到团队里,如果 Agent 的行为像黑盒,后续维护简直是灾难。
以前我们有个 Bug 排查花了三天,最后发现是 Agent 在第 7 次调用某个外部 API 时,因为网络波动重试了太多次,触发了对方服务的限流。如果不是有详细的链路追踪,根本定位不到是哪个环节的问题。
所以,做 Agent 工程化,日志记录比调优 Prompt 更重要。你必须记录:
1. **Prompt 快照**:每次请求发出去的具体内容是什么?
2. **工具参数**:Agent 到底传了什么参数给数据库或 API?
3. **Token 消耗**:这一步花了多少成本?
4. **思考路径**:如果模型采用了 CoT(思维链),要记录它当时的“想法”。
现在的开源方案里有不少 Trace 工具,但我们当时手写了一套基于 AOP 的埋点逻辑,把每次 Agent 的决策树都打点记录下来。这样产品经理想看“为什么刚才拒绝了用户”,直接去查日志就能复现,不用靠猜。
安全红线不能碰
这一点我特别想强调,尤其是涉及生产环境的时候。
之前有个实习生配置的 Agent 拥有数据库删除权限,结果一次测试中,Agent 误判了一条清理指令为“删除旧数据”,差点删库跑路。好在我们有前置的只读检查机制。
在权限设计上,我们要遵循最小权限原则。
1. **API Key 管理**:不要让 Agent 直接持有生产环境的密钥。应该通过网关中转,网关做鉴权和审计。
2. **敏感操作二次确认**:凡是涉及资金、数据修改的操作,Agent 必须经过人类确认才能执行。
3. **输入过滤**:防止 Prompt 注入攻击,特别是当 Agent 能访问用户输入时。
不要迷信模型的“安全意识”,把它当成一个不稳定的第三方开发者来对待,越限制越好。
写在最后
做 AI 应用,尤其是 Agent,技术栈更新太快了。昨天还在学 LangChain,明天可能就流行 AutoGen 或者 Semantic Kernel。
对于个人开发者来说,我建议先把基础打好。别急着追新框架,先把 HTTP 协议、异步编程、缓存策略这些基本功练熟。因为无论怎么变,最终都要回归到代码的稳定性和性能上。
如果你想在简历里展示这方面的能力,别只贴一个 Demo 链接。最好能写出你遇到的那个“最难调试的 Bug”以及你是如何通过日志系统解决的。这才是面试官真正想听的工程故事。
至于团队,别为了用 Agent 而用 Agent。如果能把现有的脚本跑通,就别搞复杂的编排。保持克制,才是真正跑起来的最佳姿态。
总结
本文完成了关键概念、工程实践和落地建议的梳理。
资料展示
下面是我整理的AI大模型学习资料和工具包预览,适合收藏后按主题逐步学习。
如果你想看完整资料目录,可以在评论区留言「资料」;也欢迎告诉我你更关注AI大模型里的哪类内容。


Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐

 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)