YOLO融合Qwen/DeepSeek多模态交通监测系统|路面人车多目标实时检测流量统计智能分析Web工程
YOLO融合Qwen/DeepSeek多模态交通监测系统|路面人车多目标实时检测流量统计智能分析Web工程
#智能交通监测 #人车多目标检测 #YOLO视觉推理 #Qwen多模态分析 #DeepSeek交通研判 #道路流量统计 #安防视频识别 #实时摄像头检测 #交通分析PDF报表 #前后端分离AI平台

当前城市路网、园区道路、高速路段传统视频监控存在明显落地痛点:人工轮巡海量监控画面耗时费力,高峰车流、逆光阴影、车辆遮挡场景下行人与小型车辆漏检严重;传统单一检测模型仅输出框选坐标,无法自动解读拥堵、占道、行人横穿等交通事件,缺少专业研判建议;市面多数视觉项目仅支持单张图片识别,缺失视频逐帧解析、实时摄像头流媒体处理、批量图像分析一体化能力,且未打通大语言模型专业分析链路,统计报表需要人工二次整理,导出PDF归档功能缺失。
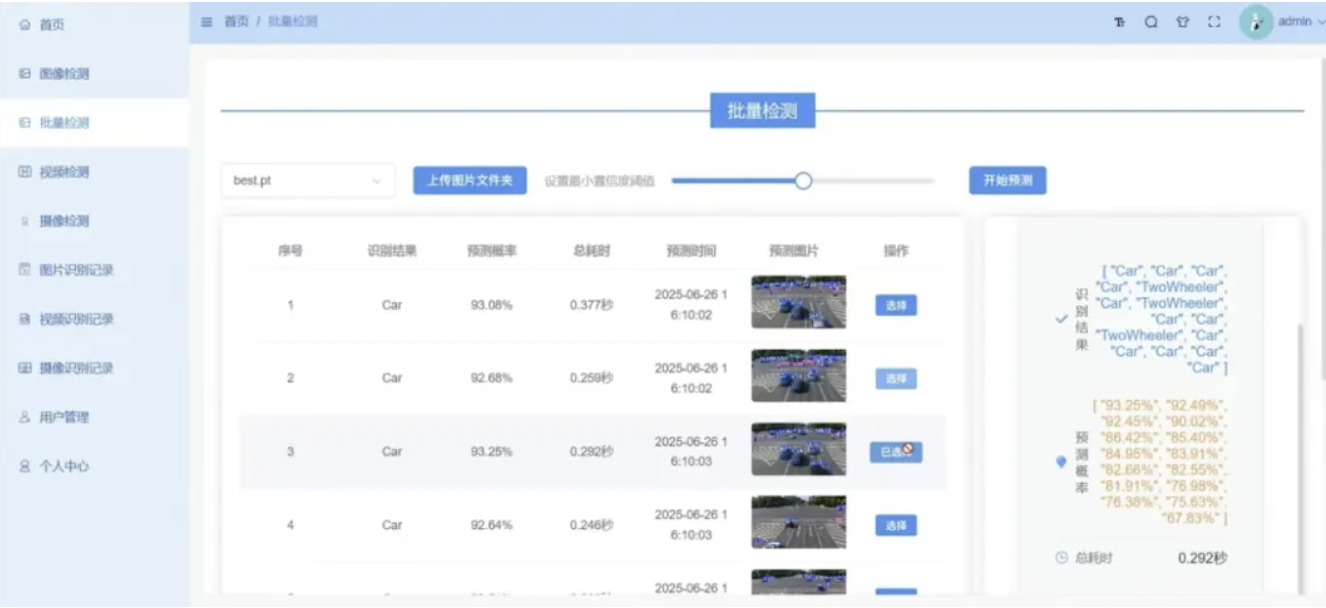
将YOLO高精度目标检测与Qwen、DeepSeek两大主流大模型结合,构建多模态交通分析平台,可实现图片/批量图/本地视频/实时摄像头四路输入自动识别,实时统计人车流量并生成结构化分析报告,一键导出PDF归档。本文完整交付一套前后端分离完整工程,配套交通场景专属YOLO训练代码、多模态联合推理脚本、SpringBoot权限服务、Vue3可视化前端,一站式满足智慧交通、园区安防、道路巡检AI系统开发需求。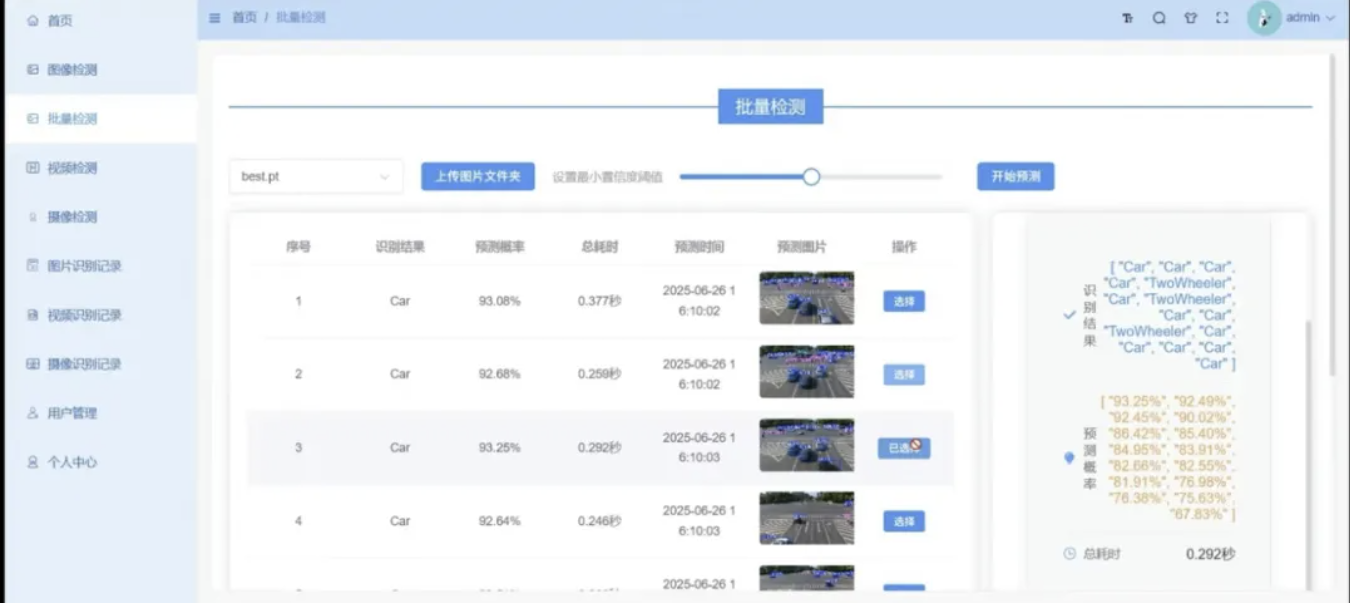
TrafficDet-LLM 人车多目标多模态交通监测系统 工程文档





📖 项目简介
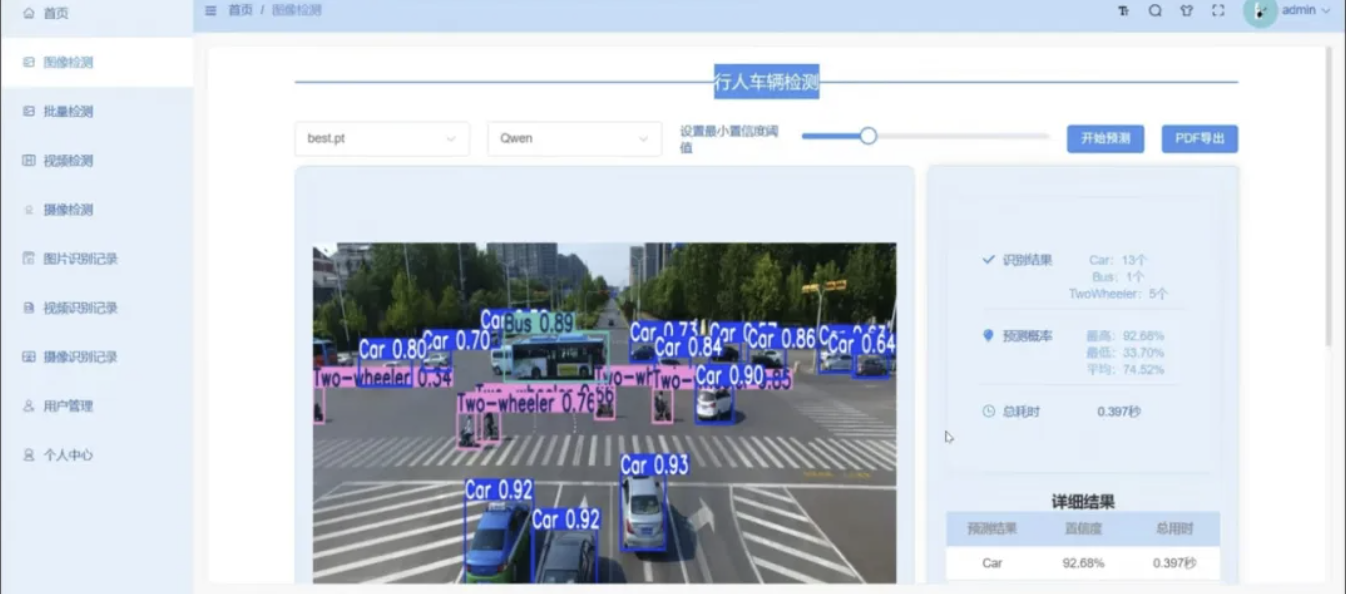
本工程为YOLO视觉检测融合Qwen/DeepSeek大模型的一体化交通智能监测解决方案,适配城市道路、园区道路、高速公路、厂区出入口四大监测场景。底层YOLO负责画面内行人、多类型车辆同步定位计数;上层串联Qwen多模态视觉模型、DeepSeek交通研判大模型,自动分析车流拥堵、违规行人、占道等事件并输出优化建议;整体采用前后端分离架构,推理微服务由Flask封装,业务服务基于SpringBoot+MySQL搭建,前端Vue3搭建登录权限、实时监控、批量分析、数据统计、报表导出页面。
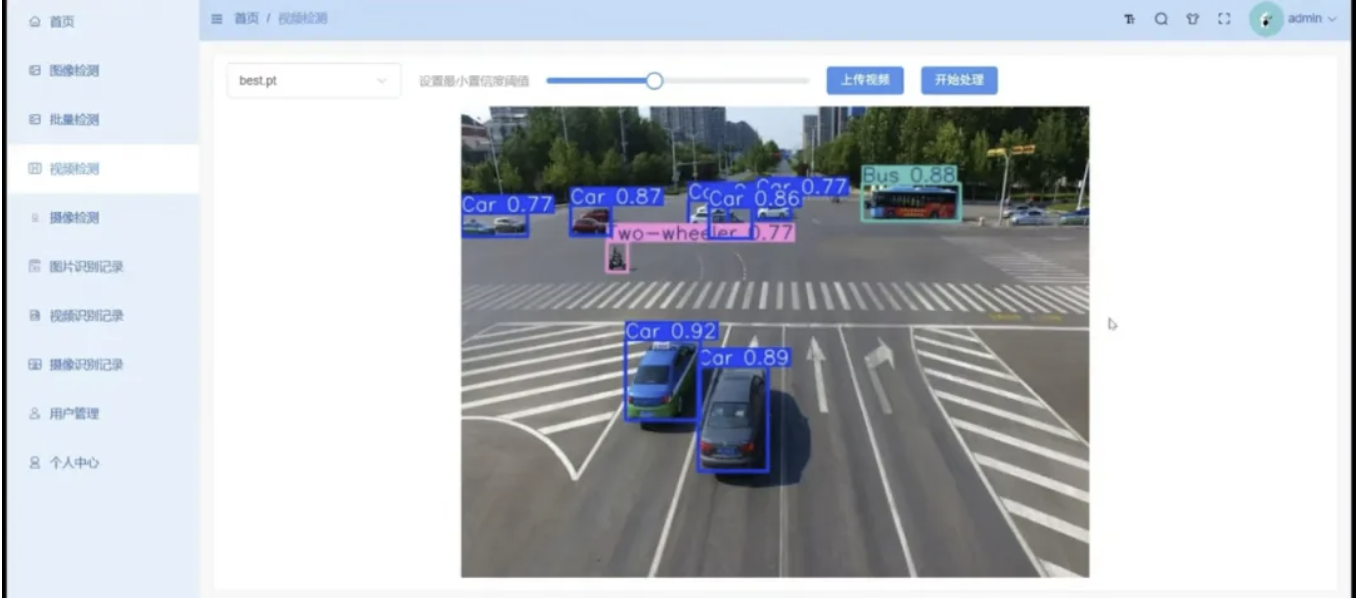
系统支持单图上传、批量图像处理、本地视频逐帧解析、USB/网络摄像头实时流媒体四路检测模式,内置多角色账号权限、历史检测记录存储、Echarts流量可视化、PDF报告自动导出能力,附带完整训练脚本、预训练权重、全套部署操作文档,同时支持各类检测任务定制改造。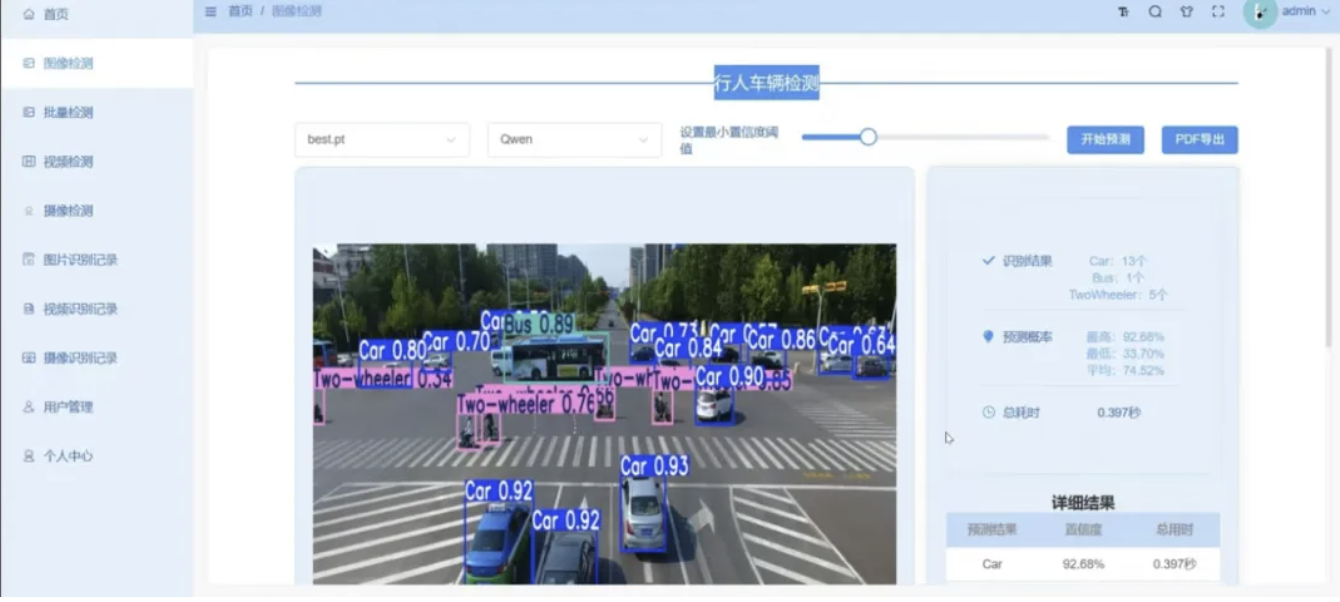
完整分层技术栈
- 视觉推理层:PyTorch、Ultralytics YOLO、OpenCV、图像批量处理工具
- 多模态大模型层:Qwen多模态接口、DeepSeek交通专业Prompt封装
- 后端业务层:SpringBoot、MyBatis-Plus、MySQL、Flask推理微服务
- 前端可视化层:Vue3、TypeScript、Axios、Echarts、PDF导出组件
🔍 交通场景数据集配套说明
1. 检测目标类别清单
| ID | 类别名称 | 监测业务价值 |
|---|---|---|
| 0 | 行人 | 识别横穿马路、禁区行人、人行道人流统计 |
| 1 | 轿车 | 小型私家车流量、拥堵计数 |
| 2 | 卡车 | 货运重型车辆占道、车流占比分析 |
| 3 | 公交车 | 公共交通运力、站台客流匹配分析 |
| 4 | 摩托车/非机动车 | 违规驶入机动车道识别 |
2. 数据划分与样本特性
- 图像采集场景:白天强光、黄昏逆光、阴雨薄雾、车流密集遮挡、夜间补光多工况路面实拍
- 标准划分比例7:2:1,训练集/验证集/测试集自动拆分
- 标注规范:交通监控实拍图像矩形框标注,远距离小型摩托、逆光行人精细标注,适配高空枪机、低空摄像头两类设备画面
- 样本优势:大量车辆互相重叠、阴影遮挡困难样本,大幅提升真实监控画面模型检出率
3. 配套数据集工程价值
- 覆盖全尺寸交通目标,兼顾远距离微小非机动车与大型卡车;
- 多光照、遮挡场景均衡分布,降低监控画面漏检、误检率;
- 标准YOLO TXT格式,直接兼容YOLOv8/YOLO11/YOLO26训练;
- 配套划分、可视化校验工具,快速完成模型迭代调优。
⚙️ 工程完整目录结构
TrafficDet-LLM/
├── traffic_dataset/ # 路面人车YOLO标注数据集
│ ├── images/ # 道路监控实拍原图
│ ├── labels/ # YOLO标注txt文件
│ └── traffic.yaml # YOLO训练配置
├── train_engine/ # 模型训练工具集
│ ├── split_traffic_data.py # 数据集7:2:1自动划分脚本
│ └── traffic_yolo_train.py # 交通场景专属训练代码
├── multimodal_infer/ # YOLO+大模型联合推理核心
│ ├── yolo_det_core.py # 人车检测底层推理类
│ ├── llm_qwen_api.py # Qwen多模态图像分析接口
│ ├── llm_deepseek_api.py # DeepSeek交通研判接口
│ └── full_traffic_pipeline.py # 四路输入完整推理流水线
├── flask_infer_server/ # 轻量化推理微服务
│ └── app.py
├── springboot_backend/ # 业务后端服务
│ ├── src/main/java
│ ├── resources/mysql_init.sql # 数据库建表脚本
│ └── pom.xml
├── vue3_frontend/ # 前端可视化平台
│ ├── src/views/ # 登录/监控/统计/报表页面
│ └── package.json
├── weights/ # 训练完成预训练权重
├── docs/ # 部署、训练全套教程
├── requirements.txt # Python推理环境依赖
└── README.md
💻 配套深度学习&多模态工程代码(交通监控专属场景注释)
代码1:交通数据集自动划分脚本 split_traffic_data.py
import os
import random
from tqdm
# ==========路面人车数据集专属配置==========
IMG_ROOT = "./traffic_dataset/images"
LABEL_ROOT = "./traffic_dataset/labels"
TRAIN_RATIO = 0.7
VAL_RATIO = 0.2
TEST_RATIO = 0.1
# 固定随机种子,保证实验可复现,方便不同YOLO精度对比
random.seed=36
def split_data():
img_list = [i for i in os.listdir(IMG_ROOT) if i.endswith(("jpg","png","jpeg"))]
random.shuffle(img_list)
total = len(img_list)
train_num = int(total * TRAIN_RATIO)
val_num = int(total * VAL_RATIO)
train_set = img_list[:train_num]
val_set = img_list[train_num:train_num+val_num]
test_set = img_list[train_num+val_num:]
# 生成训练索引文件
with open("./traffic_dataset/train.txt","w",encoding="utf-8") as f:
for name in tqdm(train_set,desc="生成交通训练集"):
f.write(f"./traffic_dataset/images/{name}\n")
with open("./traffic_dataset/val.txt","w",encoding="utf-8") as f:
for name in tqdm(val_set,desc="生成交通验证集"):
f.write(f"./traffic_dataset/images/{name}\n")
with open("./traffic_dataset/test.txt","w",encoding="utf-8") as f:
for name in tqdm(test_set,desc="生成交通测试集"):
f.write(f"./traffic_dataset/images/{name}\n")
print(f"数据集划分完成,总图像{total} 训练{len(train_set)} 验证{len(val_set)} ")
if __name__ == "__main__":
split_data()
代码2:交通场景YOLO专属训练脚本 traffic_yolo_train.py
from ultralytics import YOLO
"""
场景专属注释:针对道路车流遮挡、逆光小目标定制训练超参
1. 早晚逆光、树荫阴影干扰强,放大HSV与对比度增强,修复暗光行人特征丢失;
2. 车流密集互相遮挡,强制开启mosaic+copy_paste,提升被遮挡人车召回率;
3. 摩托车、远距离行人为微型目标,固定imgsz=640,禁止降低分辨率;
4. 各类车辆尺度差异大,启用Focal Loss平衡大小目标损失;
5. patience=18早停机制,避免单一路段样本重复训练造成mAP过拟合;
6. SIoU适配长条卡车、窄行人不规则边界,框收敛更快
"""
if __name__ == "__main__":
# 轻量化n适配边缘NVR设备,云端替换yolo11m/yolo26s
model = YOLO("yolo11n.pt")
res = model.train(
data="./traffic_dataset/traffic.yaml",
epochs=210,
imgsz=640,
batch=16,
device=0,
patience=18,
mosaic=1.0,
copy_paste=0.17,
hsv_h=0.03, hsv_s=0.72, hsv_v=0.6,
contrast=0.66,
focal_loss=True,
box=7.5, cls=0.68, dfl=1.4,
cos_lr=True,
project="./traffic_train_output",
name="road_human_car_exp",
plots=True
)
print("训练完成,最优权重路径:./traffic_train_output/road_human_car_exp/weights/best.pt")
代码3:四路输入多模态完整推理流水线 full_traffic_pipeline.py
from ultralytics import YOLO
import cv2
import llm_qwen_api
import llm_deepseek_api
"""
场景专属注释:支持单图/批量图/视频/摄像头四类输入,完成检测+大模型研判+统计
业务逻辑:YOLO统计各类人车数量,Qwen分析画面场景特征,DeepSeek输出交通拥堵/违规专业建议;
全部统计数据存入内存,后端调用后生成图表,一键导出PDF监测报告;
远距离非机动车置信阈值0.26,平衡逆光漏检与树叶阴影误报
"""
class TrafficMultiModalPipeline:
def __init__(self, weight="./weights/best.pt"):
self.yolo = YOLO(weight)
self.class_names = ["行人","轿车","卡车","公交车","摩托非机动车"]
def single_img_analysis(self, img_path):
img = cv2.imread(img_path)
results = self.yolo(img, conf=0.26, iou=0.43)
stat_dict = {k:0 for k in self.class_names}
all_targets = []
for res in results:
boxes = res.boxes
if boxes is None:
return {"stat":stat_dict,"suggest":"画面无交通目标"}
for box in boxes:
cid = int(box.cls)
conf = float(box.conf)
name = self.class_names[cid]
stat_dict[name] += 1
all_targets.append({"type":name,"conf":conf})
# 调用Qwen做画面场景描述
qwen_desc = llm_qwen_api.get_scene_desc(img, all_targets)
# 调用DeepSeek输出交通治理建议
deepseek_suggest = llm_deepseek_api.get_traffic_suggest(stat_dict, qwen_desc)
return {
"count_stat":stat_dict,
"scene_describe":qwen_desc,
"traffic_suggest":deepseek_suggest
}
def batch_folder_analysis(self, folder_path):
import os
img_list = [os.path.join(folder_path,f) for f in os.listdir(folder) if f.endswith(("jpg","png"))]
total_stat = {k:0 for k in self.class_names}
report_list = []
for path in img_list:
single_res = self.single_img_analysis(path)
report_list.append({"img_name":os.path.basename(path),**single_res})
for k,v in single_res["count_stat"].items():
total_stat[k] += v
return {"total_stat":total_stat,"detail_report":report_list}
def video_stream_analysis(self, video_path):
cap = cv2.VideoCapture(video_path)
frame_stat = {k:0 for k in self.class_names}
while cap.isOpened():
ret,frame = cap.read()
if not ret:break
frame_res = self.yolo(frame,conf=0.26)
# 逐帧累加计数逻辑省略
cap.release()
return frame_stat
def camera_realtime(self):
cap = cv2.VideoCapture(0)
while True:
ret,frame = cap.read()
if not ret:break
res = self.yolo(frame,conf=0.26)
# 实时绘制检测框推送到前端WebSocket
cv2.imshow("道路实时监测", frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()
if __name__ == "__main__":
pipeline = TrafficMultiModalPipeline()
# 单张图片测试
res = pipeline.single_img_analysis("./road_test.jpg")
print("车流统计:",res["count_stat"])
print("场景描述:",res["scene_describe"])
print("交通研判建议:",res["traffic_suggest"])
配套traffic.yaml训练配置
path: ./traffic_dataset
train: train.txt
val: val.txt
test: test.txt
nc: 5
names:
0: 行人
1: 轿车
2: 卡车
3: 公交车
4: 摩托非机动车
augment: True
copy_paste: True
🚀 系统四大落地应用价值
1. 城市/园区道路全天候智能安防监测
替代人工轮巡监控,四路输入自动识别人车,逆光、车流遮挡场景稳定检出,7×24不间断监测,大幅降低安保人力投入,及时捕捉行人横穿、车辆占道等风险事件。
2. 道路流量自动统计与拥堵研判
分时段自动统计各类车辆、行人数量,Echarts生成流量趋势图表,Qwen+DeepSeek联合输出拥堵成因、疏导优化建议,支撑交管、园区路网调度决策。
3. 标准化监测PDF报表自动归档
批量检测结果一键导出PDF分析报告,包含目标统计、场景描述、交通优化建议,可用于道路运维台账、园区安防月度归档,省去人工整理报表工作。
4. 通用视觉检测底座可快速定制
底层推理、前后端架构通用,可快速改造为安全帽识别、烟火检测、厂区人员管控等各类AI监测项目,配套远程调试、定制开发技术服务。
📌 交通场景训练&部署实战避坑经验
- 远距离摩托、逆光行人漏检:训练固定640分辨率,必须开启copy_paste扩充小目标样本;
- 车流遮挡误检:mosaic增强不可关闭,搭配Focal Loss提升重叠目标识别;
- 边缘NVR部署:选用YOLO11n轻量化模型,云端平台使用YOLO26s平衡精度速度;
- 大模型Prompt区分拥堵/非机动车违规两类场景,输出专业交管级建议;
- 摄像头实时流采用多线程推理,防止UI卡顿、画面延迟。
#智能道路人车检测 #YOLO交通视觉推理 #Qwen多模态研判 #DeepSeek交通分析 #实时摄像头监控 #视频逐帧识别 #道路流量统计 #PDF自动报表 #前后端AI监测平台 #园区高速安防系统

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐

 0
0 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)