通过构建 Validation Engineering 提升 Claude Code 自动化任务执行准确性——AI Coding 质量控制与研发效率深度研究报告

目录
1. 核心问题定义
1.1 问题陈述
AI Coding 工具(特别是 Claude Code 等 Agentic Coding 工具)在自动化任务执行中面临核心质量挑战:Agent 无法准确评估自身产出的质量。这导致三个关键瓶颈:
| 瓶颈 | 描述 | 来源 |
|---|---|---|
| 出码率 ≠ 交付率 | 编码仅占全链路 20%-30%,AI 渗透率提升编码环节并不等于整体提效 | 高德大模型应用平台团队 2025 云栖大会分享 |
| Vibe Coding 风险 | "氛围编程"在存量应用中可能引入与现有系统不兼容的方案,问题常在上线后暴露 | 腾讯云开发者社区 2026 |
| 大任务超出能力边界 | 复杂多模块任务超出单次 AI 对话能力,上下文窗口填充率超 40% 时输出质量快速衰退 | Anthropic 工程博客 |
1.2 核心矛盾
"Agent 的知识边界等于代码库的文件边界。如果某条架构约定不在代码库中以机器可读的形式存在,对 Agent 来说它就不存在。" —— OpenAI 百万行代码实践总结
Agent 存在一个根本性缺陷:它们无法准确评估自身产出的质量。没有外部验证机制,"看起来完成了"是唯一的信号,而人自身就成为了验证循环——这恰恰是人力投入居高不下的根源。
2. Validation Engineering 概念体系
2.1 定义与定位
Validation Engineering(验证工程)是指围绕 AI Agent 的自动化任务执行,设计、构建和运维系统性验证机制的工程实践,其核心目标是:
-
将"事后人工审查"转化为"过程中自动验证"
-
将"看起来完成了"的模糊信号转化为"测试通过/不通过"的确定性信号
-
将验证从可选项变为强制门禁
2.2 三层嵌套关系
Validation Engineering 在 AI Coding 工程体系中处于核心位置:
┌─────────────────────────────────────────────┐ │ Harness Engineering (驾驭工程) │ │ "系统怎么防崩、怎么量化、怎么修" │ │ ┌───────────────────────────────────────┐ │ │ │ Context Engineering (上下文工程) │ │ │ │ "给 Agent 看什么" │ │ │ │ ┌─────────────────────────────────┐ │ │ │ │ │ Prompt Engineering (提示词工程) │ │ │ │ │ │ "如何向模型提问" │ │ │ │ │ └─────────────────────────────────┘ │ │ │ └───────────────────────────────────────┘ │ │ │ │ ★ Validation Engineering (验证工程) │ │ 是 Harness 的核心目标,但目前是最薄弱环节 │ └─────────────────────────────────────────────┘
关键定位:Validation 是 Harness Engineering 的核心目标之一,但目前是其中最薄弱的环节。行业在"预防性约束"方面已有成熟实践(Linter、架构约束),但在"确认性验证"方面仍存在系统性缺口。
2.3 与相关概念的关系
| 概念 | 关注点 | 与 Validation Engineering 的关系 |
|---|---|---|
| Prompt Engineering | 如何向模型提问 | 验证的起点——提示词中是否包含验证标准 |
| Context Engineering | 给 Agent 看什么 | 验证的基础——Agent 是否有足够的上下文来生成可验证的代码 |
| Harness Engineering | 系统怎么防崩、怎么量化、怎么修 | 验证的载体——Harness 是 Validation 的工程化实现 |
| SDD(规范驱动开发) | 在 AI 写代码前定义清晰的规范 | 验证的前提——没有明确的规范就没有可验证的标准 |
3. Claude Code 验证机制全景解析
3.1 验证信号类型
Anthropic 官方在《Claude Code: Best practices for agentic coding》中明确提出核心原则:
"Give Claude a check it can run: tests, a build, a screenshot to compare. It's the difference between a session you watch and one you walk away from."
| 验证信号类型 | 说明 | 确定性 |
|---|---|---|
| 测试套件 | 运行单元/集成测试,读取 pass/fail | 高 ✅ |
| 构建退出码 | 构建成功与否的明确信号 | 高 ✅ |
| Linter | 代码风格和错误检查 | 高 ✅ |
| 脚本对比 | 将输出与 fixture 进行 diff 比较 | 高 ✅ |
| 浏览器截图 | 与设计稿进行视觉对比 | 中 ⚠️ |
来源:Anthropic 官方工程博客《Claude Code: Best practices for agentic coding》
3.2 验证强度四层模型
Claude Code 的验证强度从弱到强分为四个层级:
| 层级 | 验证方式 | 机制 | 适用场景 |
|---|---|---|---|
| Level 1 | 单次提示内验证 | 在同一条消息中要求 Claude 运行检查并迭代 | 简单任务 |
| Level 2 | 跨会话目标验证 | 使用 /goal 条件,独立评估器在每轮后重新检查 |
中等复杂度 |
| Level 3 | 确定性门控(Stop Hook) | Stop hook 将检查作为脚本运行,阻止回合结束直到通过 | 关键任务 |
| Level 4 | 第二意见验证 | Verification subagent 或 dynamic workflow,由全新模型尝试反驳结果 | 高可靠性需求 |
重要约束:Stop Hook 连续阻止 8 次后,Claude Code 会强制结束回合。
3.3 Hooks 系统:确定性的验证执行
Claude Code 的 Hooks 是确定性的验证执行机制,与 CLAUDE.md 的建议性指令形成对比:
"Unlike CLAUDE.md instructions which are advisory, hooks are deterministic and guarantee the action happens."
| Hook 类型 | 触发时机 | 验证用途 |
|---|---|---|
PreToolUse |
工具调用前 | 安全检查、权限验证 |
PostToolUse |
工具调用后 | 输出验证、格式检查 |
Stop |
Agent 尝试结束时 | 完成度验证、质量门控 |
实战示例:通过 Stop Hook 实现质量门控——在 Agent 声明任务完成前,自动运行测试套件,仅当全部通过时才允许结束。
3.4 对抗性审查(Adversarial Review)
Anthropic 推荐使用 Subagent 在全新上下文中审查代码变更:
"Before treating a task as done, have a subagent review the diff in a fresh context and report gaps."
核心原则:分离执行与评判——"将做事的 Agent 和评判的 Agent 分开,是一个强有力的杠杆。"
⚠️ 重要警告:审查 Agent 会倾向于报告问题,即使工作质量是好的。追逐每一个发现会导致过度工程化。建议只标记影响正确性或既定需求的差距。
3.5 关键原则:证据优于断言
"Have Claude show evidence rather than asserting success: the test output, the command it ran and what it returned, or a screenshot of the result."
| 失败模式 | 描述 | 修复方法 |
|---|---|---|
| 信任-验证缺口 | 产出看似合理但不处理边界情况 | 始终提供验证;无法验证则不上线 |
| 无限探索 | 要求"调查"但未限定范围 | 缩小调查范围,使用 subagent |
| 反复纠错 | 做错→纠正→仍错→再纠正 | 两次纠错失败后 /clear 重新开始 |
来源:Anthropic《Claude Code: Best practices for agentic coding》
4. 国际前沿:LLMLOOP 迭代验证框架
4.1 论文概述
LLMLOOP 是一个自动化框架,通过五层迭代反馈循环改进 LLM 生成的代码及其测试用例。论文发表于 2025 年 ICSME 会议,开源代码可在 GitHub 获取。
-
论文:LLMLOOP: Improving LLM-Generated Code and Tests through Automated Iterative Feedback Loops
-
发表:ICSME 2025
-
评估基准:HumanEval-X(164 个 Java 编程问题)
4.2 五层迭代循环
| 循环 | 名称 | 核心功能 | 关键工具 |
|---|---|---|---|
| Loop 1 | 修复编译错误 | 确保生成的代码可编译 | 编译器错误反馈 |
| Loop 2 | 修复测试失败 | 让代码通过给定的测试 | 失败测试 + 堆栈跟踪 |
| Loop 3 | 静态分析优化 | 修复代码质量问题 | PMD(400+ 内置规则) |
| Loop 4 | 测试生成 | 自动生成测试用例 | EvoSuite / LLM 生成 |
| Loop 5 | 变异分析 | 提升测试套件质量 | PIT 变异测试工具 |
关键交互逻辑:Loop 1 在每次代码变更后都会被触发,确保代码始终可编译。
4.3 实验数据
| 阶段 | 描述 | pass@1 | 相对提升 |
|---|---|---|---|
| 基线 | 无反馈循环 | 71.65% | — |
| +Loop 1 | 编译循环 | 76.40% | +4.75% |
| +Loop 2 | 给定测试 | 79.51% | +3.11% |
| +Loop 3 | 静态分析 | 79.57% | +0.06% |
| +Loop 4-5 | LLM 生成测试 | 80.55% | +0.98% |
| +Loop 4-5 | EvoSuite 生成测试 | 80.85% | +0.30% |
核心发现:
| 指标 | 基线 | LLMLOOP | 提升幅度 |
|---|---|---|---|
| pass@1 | 71.65% | 80.85% | +9.2% |
| pass@10 | 76.22% | 90.24% | +14.02% |
关键结论:迭代反馈循环放大了基线的改进效果——随着代码样本数量(k)增加,LLMLOOP 与基线的差距持续扩大,在 pass@10 时达到峰值差异 14.02%。
4.4 各循环贡献度
| 循环 | 贡献度 | 关键发现 |
|---|---|---|
| Loop 1(编译) | ⭐⭐⭐ 最大 | 解决了阻碍后续测试和分析的基础问题 |
| Loop 2(测试) | ⭐⭐ 显著 | 使代码更贴合问题需求 |
| Loop 3(静态分析) | ⭐ 较小 | 提升仅 0.06% |
| Loop 4-5(测试生成+变异) | ⭐ 较小 | 提升约 1.28% |
来源:LLMLOOP 论文,ICSME 2025
5. Harness Engineering:验证工程的系统化范式
5.1 核心定义
Harness Engineering 是指围绕 AI Agent 设计和构建约束机制、反馈回路、工作流控制和持续改进循环的系统工程实践。
"The model is the agent. The code is the harness. Build great harnesses. The agent will do the rest."
类比:Phil Schmid 认为"模型是 CPU,Harness 是操作系统"——CPU 再强,OS 拉胯也白搭。
5.2 四大支柱
| 支柱 | 核心原则 | 验证关联 |
|---|---|---|
| 上下文架构 | Agent 恰好获得当前任务所需的上下文——不多不少 | 验证的基础:上下文不足导致验证不完整 |
| Agent 专业化 | 专注于特定领域的 Agent 优于拥有全部权限的通用 Agent | 验证的分离:执行 Agent 与审查 Agent 必须分开 |
| 持久化记忆 | 进度持久化在文件系统上,而非上下文窗口中 | 验证的连续性:跨会话验证需要持久化状态 |
| 结构化执行 | 将思考与执行分离:理解→规划→执行→验证 | 验证的结构化:验证是执行序列的最后一个阶段 |
来源:综合 OpenAI、Anthropic、Carlini、Huntley、Horthy 等五个独立团队的实践
5.3 上下文利用率的关键约束
40% 阈值:上下文窗口利用率保持在 40% 以下时,Agent 处于"Smart Zone";超过 40% 后进入"Dumb Zone",出现幻觉、循环、格式错误和低质量代码。
| 上下文利用率区间 | 表现 |
|---|---|
| 0-40%(Smart Zone) | 聚焦、准确的推理 |
| 40-100%(Dumb Zone) | 幻觉、循环、格式错误、低质量代码 |
来源:Anthropic 工程实践经验
5.4 验证的三大空白区
当前 Harness Engineering 在验证方面存在三个系统性缺口:
| 空白区 | 描述 | 当前状态 |
|---|---|---|
| 功能和行为验证的系统化方案 | Böckeler 对 OpenAI 报告最尖锐的批评:大量讨论了架构约束和熵管理,但功能正确性验证几乎缺席 | ❌ 待解决 |
| AI 生成代码的长期可维护性 | Agent 写的代码和人写的代码,积累技术债的方式不一样;LLM 生成的代码经常重新实现已有功能 | ❌ 待验证 |
| 规模化验证 | 报告缺乏对功能和行为的系统性验证框架;视觉能力和工具限制意味着某些 bug 仍会遗漏 | ❌ 待解决 |
6. SDD + Harness 双轮驱动实战模型
6.1 核心逻辑
SDD(规范驱动开发) 解决"做什么"——在 AI 写代码之前,将人类模糊的想法转化为清晰、无歧义的结构化规范。 Harness Engineering 解决"如何可控地做"——为 AI 设计一整套约束、验证、反馈、纠错系统。
6.2 实战数据:从 25% 到 90% 的跃迁
来自腾讯云开发者社区的实战案例(10万+行 Java 应用):
| 指标 | Harness 引入前(3月基线) | Harness 运转成熟后(4月实测) | 提升幅度 |
|---|---|---|---|
| 项目维度 AI 行占比 | 24.86% | 90.54% | +65.68% |
| 个人维度 AI 行占比 | 14.24% | 87.85% | +73.61% |
关键说明:90% 的 AI 代码经过了完整的需求分析、编码评审、单元测试和 CI 验证流程,每一行都通过了 Harness 体系的质量门禁。
6.3 十阶段验证流水线
实战中的完整验证流水线:
阶段1: 需求分析 → 质量门禁:需求无歧义、验收标准可测试 阶段2: 需求评审 → 循环上限3轮 阶段3: 编码实现 → 按8份分层Spec逐层编码 阶段4: 编码评审 → 循环上限2轮 阶段5: 测试编写 → Agent自动生成单元测试 阶段6: 测试评审 → 循环上限2轮 阶段7: CI验证 → status==SUCCESS && total_tests>0 && passed==total 阶段8: 部署验证 → 人工确认环境参数 阶段9: 交付评审 → 5个人工确认点 阶段10: 归档 → 完整Audit Trail
回退路径(Rollback Routes):
-
CI 失败 → 回退到阶段 5(测试编写)
-
编译错误 → 回退到阶段 3(编码实现)
-
需求不符 → 回退到阶段 1(需求分析)
6.4 质量门禁的程序化验证
"If it can't be mechanically enforced, the agent will drift."
一切不可被机器验证的约束,在 Agent 执行中都是无效约束。质量门禁必须转化为可程序化验证的条件:
# ❌ 自然语言描述(Agent 可能误判) "检查CI是否通过" # ✅ 程序化验证条件 status == SUCCESS and total_tests > 0 and passed == total
来源:腾讯云开发者社区《出码率90%却没提效?》
6.5 五条关键经验
| # | 经验 | 说明 |
|---|---|---|
| 1 | Harness 本身需要 Dry Run | 在拿真实需求使用前,用虚拟需求完整走一遍全流程 |
| 2 | 质量门禁必须可程序化验证 | 不可被机器验证的约束都是无效约束 |
| 3 | 分离执行与评判是关键杠杆 | 编码 Agent 和评审 Agent 的分离带来显著质量收益 |
| 4 | 流程一致性优先于流程效率 | 保持流程一致性是廉价的保险,不给简单任务显著增加负担 |
| 5 | 规范是活文档,需要持续迭代 | 规范的每一行都对应一个历史失败案例 |
7. 国内外大厂实践与量化数据
7.1 奇富科技:AI Coding 二年落地成效
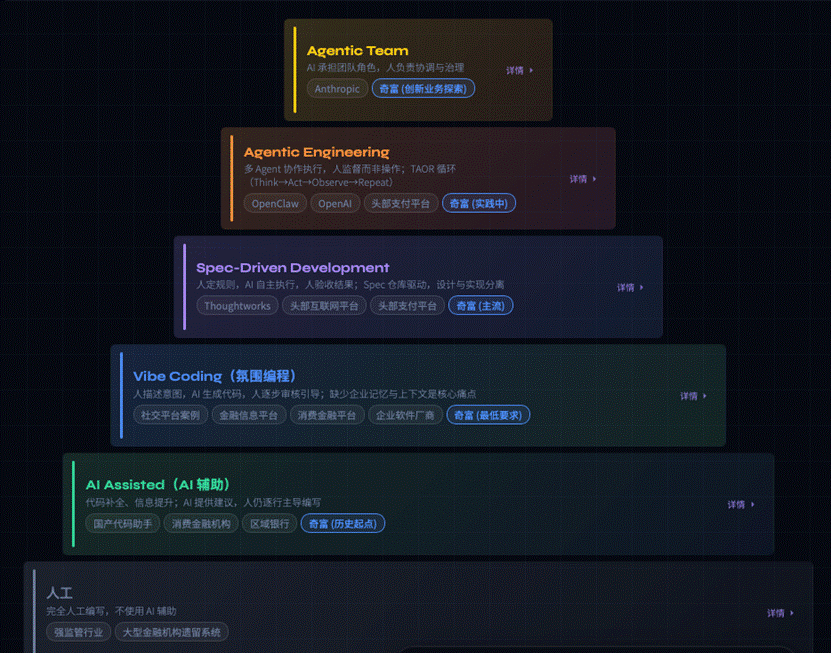
奇富科技是国内少数实现 SDD 规模化落地的金融科技企业:
| 指标 | 数据 | 来源 |
|---|---|---|
| 技术领域需求交付效率提升 | 65% | InfoQ 2026.6.5 报道 |
| 迭代周期缩短 | 55% | 同上 |
| 测试用例生成效率提升 | 80% | 同上 |
| 回归测试周期缩短 | 60% | 同上 |
| 运维故障定位耗时 | 减半 | 同上 |
| 巡检脚本 AI 生成率 | 90% | 同上 |
| 全员 AI 工具渗透率 | 99.7% | 同上 |
| 开发岗渗透率 | 88% | 同上 |
| 头部工程师产出杠杆 | 最高40倍 | 同上 |
关键实践:奇富科技已从 AI 辅助和沉浸式编码阶段,过渡到主流采用规范驱动开发(SDD),并从 Agentic Engineering 走向 Harness Engineering——通过上下文资产、工具链编排、权限约束、执行反馈与质量验证,为智能体建立可控、可观测、可治理的工程化"安全轨道"。
7.2 腾讯云代码助手
| 指标 | 数据 | 来源 |
|---|---|---|
| 测试用例覆盖率 | 92% | 腾讯云开发者社区 2026 |
| BUG 定位准确率提升 | 85% | 同上 |
| AI 辅助测试生成覆盖率 | 80%+ | 同上 |
| 单次测试生成成本 | 0.01元 | 同上 |
| 误报率 | <5% | 同上 |
7.3 高德大模型应用平台
| 发现 | 说明 | 来源 |
|---|---|---|
| 出码率从 53% 提升到 80%-90% | 但项目交付周期没有明显缩短 | 2025 云栖大会分享 |
| 编码快了,但 Review 慢了 | 出码多了,但返工也多了 | 同上 |
7.4 企业级 AI 测试平台
| 指标 | 数据 | 来源 |
|---|---|---|
| AI 测试平台测试效率提升 | 3倍以上 | 51CTO 2025 |
| 缺陷发现率提高 | 40% | 同上 |
| AI 生成测试用例的缺陷检出率提升 | 65% | 2025《全球软件测试白皮书》引用【PARTIALLY VERIFIED】 |
7.5 国际大厂概况
| 企业 | 工具/方法 | 验证相关特性 |
|---|---|---|
| Gemini Code Assist | 128K token 上下文窗口,自动审查 PR 中的错误和格式问题,建议修复方案 | |
| OpenAI | Codex CLI | 沙盒执行环境、192K token 上下文长度、多模态编程支持 |
| Anthropic | Claude Code | 4 层验证强度、Hooks 系统、Subagent 对抗审查 |
8. Benchmark 数据:AI Coding 能力基线
8.1 SWE-bench Verified 演进
| 模型 | SWE-bench Verified | 发布时间 |
|---|---|---|
| Claude 3 Opus | 22% | 2024 |
| Claude 3.5 Sonnet (旧版) | 33% | 2024 |
| Claude 3.5 Sonnet (新版) | 49% | 2025.1 |
| Claude Opus 4.1 | 74.5% | 2025.8 |
| Claude Opus 4.7 | 87.6% | 2026.4 |
| Claude Fable 5 | 95% | 2026.6 |
来源:Anthropic 官方研究页面、CSDN 报道
8.2 SWE-bench Pro(更严格的企业级基准)
| 模型 | SWE-bench Pro | 说明 |
|---|---|---|
| GPT-5(发布时) | 23% | SWE-bench Pro 参考解决方案平均涉及 4.1 个文件、107.4 行代码 |
| Claude Opus 4.7 | 64.3% | 较上一代提升近 11 个百分点 |
| Claude Fable 5 | 80%+ | 首个突破 80% 的公开可用模型 |
8.3 关键发现
-
模型性能持续快速提升,但 Benchmark 分数高 ≠ 实际任务准确率高——SWE-bench 仅覆盖特定类型的问题
-
Agent 架构的影响巨大:Anthropic 使用"简洁提示词 + 两个通用工具"的极简架构使 Claude 3.5 Sonnet 新版达到 49%,开发者通过优化 scaffold 仍有较大提升空间
-
评估挑战持续存在:部分失败案例源于环境配置问题而非模型本身;模型无法看到评分用的单元测试,可能"以为成功"实则失败
9. Anthropic Agent 评估体系
9.1 评估的基本结构
Anthropic 在《Demystifying evals for AI agents》中定义了 Agent 评估的核心概念:
| 概念 | 定义 |
|---|---|
| 任务(Task) | 一个单独的测试,包含明确的输入和成功标准 |
| 尝试(Trial) | 对一个任务的单次尝试 |
| 评分器(Grader) | 用于对 Agent 性能某方面评分的逻辑 |
| 记录(Transcript) | 一次尝试的完整记录 |
| 结果(Outcome) | 尝试结束时环境的最终状态 |
| 评估框架(Evaluation harness) | 运行端到端评估的基础设施 |
9.2 三类评分器
| 评分器类型 | 方法 | 优点 | 缺点 |
|---|---|---|---|
| 基于代码 | 字符串匹配、单元测试、静态分析、结果验证 | 快速、廉价、客观、可复现 | 对有效变体可能过于脆弱 |
| 基于模型 | 评分规则、自然语言断言、成对比较 | 灵活、可扩展、捕捉细微差别 | 非确定性、需校准 |
| 人工 | 领域专家审查、众包判断 | 黄金标准质量 | 昂贵、缓慢 |
9.3 能力评估 vs 衰退评估
| 评估类型 | 目标 | 初始通过率 | 演化路径 |
|---|---|---|---|
| 能力评估 | "这个 Agent 擅长做什么?" | 较低 | 通过率高时可"毕业"为衰退评估 |
| 衰退评估 | "Agent 是否还能处理好以前的任务?" | 接近 100% | 持续运行捕捉性能漂移 |
9.4 pass@k vs pass^k
| 指标 | 含义 | 适用场景 |
|---|---|---|
| pass@k | k 次尝试中至少一次成功的概率 | "只要有一个方案能成功就行" |
| pass^k | k 次尝试全部成功的概率 | "每次都必须可靠" |
关键洞察:在 k=1 时两者相等。但随着 k 增加,两者会迅速分化。选择哪个指标取决于产品需求。
10. Validation Engineering 实施框架
10.1 成熟度模型
| 阶段 | 特征 | 验证能力 | 人力投入 |
|---|---|---|---|
| Level 0:无验证 | 直接给 Agent prompt,无验证机制 | 无 | 100% 人工审查 |
| Level 1:基础验证 | 手动运行测试 + CLAUDE.md 规则 | 事后抽检 | ~80% 人工 |
| Level 2:反馈回路 | CI/CD 集成 + Hooks 自动验证 | 过程中自动验证 | ~40% 人工 |
| Level 3:多 Agent 验证 | 执行/审查 Agent 分离 + 对抗性审查 | 独立评估 | ~20% 人工 |
| Level 4:自治验证 | 无人值守验证 + 自动化熵管理 + 自修复 | 全自动验证闭环 | ~5% 人工(仅关键决策点) |
10.2 实施路线图
第一阶段:建立验证基线(1-2 周)
| 步骤 | 行动 | 产出 |
|---|---|---|
| 1 | 从真实失败案例中提取 20-50 个验证任务 | 初始评估数据集 |
| 2 | 为每个任务编写无歧义的成功标准 | 可验证的验收条件 |
| 3 | 建立基本的 CI/CD 验证管道 | 自动化测试基础设施 |
第二阶段:构建确定性门控(2-4 周)
| 步骤 | 行动 | 产出 |
|---|---|---|
| 1 | 实现 Stop Hook 自动验证 | 编译+测试通过才允许结束 |
| 2 | 建立 CLAUDE.md 验证规则 | 项目级验证标准 |
| 3 | 将质量门禁程序化 | 可机器验证的门禁条件 |
第三阶段:引入对抗性验证(4-8 周)
| 步骤 | 行动 | 产出 |
|---|---|---|
| 1 | 实现执行/审查 Agent 分离 | 独立的质量评估 |
| 2 | 构建评审 Subagent | 全新上下文的代码审查 |
| 3 | 建立评审循环上限 | 防止无限自我修改 |
第四阶段:规模化验证闭环(持续)
| 步骤 | 行动 | 产出 |
|---|---|---|
| 1 | 能力评估→衰退评估的毕业机制 | 持续质量保障 |
| 2 | 多维度评分器组合 | 全面质量画像 |
| 3 | 评估驱动的持续改进 | 量化质量趋势 |
10.3 核心工具链
| 工具/机制 | 验证层级 | 优先级 | 来源 |
|---|---|---|---|
| CLAUDE.md 验证规则 | Level 1 | P0 | Anthropic 官方 |
| Stop Hook 质量门控 | Level 2 | P0 | Anthropic 官方 |
| CI/CD 自动化验证 | Level 2 | P0 | 行业通用实践 |
| 自定义 Linter + 结构测试 | Level 2 | P0 | OpenAI/Anthropic 实践 |
| 评审 Subagent | Level 3 | P1 | Anthropic 官方推荐 |
| 浏览器自动化(Puppeteer MCP) | Level 3 | P1 | Anthropic/OpenAI 实践 |
| 进度文件(JSON 格式) | Level 2 | P1 | Anthropic 实践 |
| 功能列表文件 | Level 2 | P1 | Anthropic 实践 |
| 评估框架(Evaluation harness) | Level 4 | P2 | Anthropic 评估方法论 |
| 熵管理 Agent | Level 4 | P2 | OpenAI 实践 |
11. 成本效益分析
11.1 验证投入与质量回报
基于 LLMLOOP 实验数据:
| 验证层次 | 投入 | pass@1 提升 | 边际收益 |
|---|---|---|---|
| 无验证 | 基线 | 71.65% | — |
| +编译验证(Loop 1) | 低 | 76.40%(+4.75%) | ⭐⭐⭐ 最高 |
| +测试验证(Loop 2) | 中 | 79.51%(+3.11%) | ⭐⭐ 高 |
| +静态分析(Loop 3) | 低 | 79.57%(+0.06%) | ⭐ 低 |
| +测试生成+变异(Loop 4-5) | 高 | 80.85%(+1.28%) | ⭐ 低 |
关键结论:编译验证和测试验证的投入产出比最高,静态分析和变异测试的边际收益较低。
11.2 人力投入变化(基于行业实践)
| 阶段 | 人工审查比例 | 验证自动化程度 | 典型场景 |
|---|---|---|---|
| 无验证 | ~100% | 0% | 完全手动审查 AI 产出 |
| 基础验证 | ~80% | 20% | 手动运行测试+抽检 |
| 反馈回路 | ~40% | 60% | CI/CD 自动验证+Hooks |
| 多 Agent 验证 | ~20% | 80% | 执行/审查 Agent 分离 |
| 自治验证 | ~5% | 95% | 仅关键决策点需人工 |
11.3 奇富科技 ROI 参考
| 指标 | 数值 | 说明 |
|---|---|---|
| 头部工程师产出杠杆 | 最高 40 倍 | 人均每日 Token 消耗达千万级 |
| Token 消耗与产出 | 强正相关 | 前 20% 头部工程师日均消耗突破亿级 |
| 测试效率提升 | 80% | 测试用例生成效率 |
| 回归测试周期缩短 | 60% | 自动化验证闭环的效果 |
12. 关键挑战与未来方向
12.1 当前挑战
| 挑战 | 描述 | 严重程度 |
|---|---|---|
| 功能正确性验证几乎缺席 | 当前擅长"约束 Agent 不做错事"(Linter、架构约束),但"验证 Agent 做对了事"远未解决 | 🔴 高 |
| AI 生成代码的长期可维护性 | Agent 写的代码和人写的代码积累技术债的方式不同 | 🔴 高 |
| 规模化验证框架缺失 | 缺乏对功能和行为的系统性验证框架 | 🟡 中 |
| 验证成本与质量平衡 | LLMLOOP 的 Loop 4-5 边际收益低但计算成本高 | 🟡 中 |
| Agent 行为的非确定性 | 每次运行结果可能不同,评估结果解读复杂 | 🟡 中 |
| 上下文窗口限制 | 复杂任务可能消耗 >100K tokens,上下文超 40% 时质量衰退 | 🟡 中 |
12.2 未来方向
-
评估驱动开发(Eval-Driven Development):先构建评估来定义期望的能力,然后迭代 Agent 直到其表现良好——Anthropic 推荐
-
验证 Agent 的专业化:构建专门用于验证的 Agent,拥有独立的工具集和评估逻辑
-
变异测试增强:将 PIT 变异测试工具的概念扩展到更多语言和场景
-
多模态验证:结合视觉验证(截图对比)与功能验证
-
验证标准的结构化:将验收标准从自然语言转化为可机器执行的程序化条件
13. 结论与建议
13.1 核心结论
-
Validation Engineering 是 AI Coding 从"个人技能"升级为"团队级工程能力"的关键。没有系统性验证,AI 出码率的提升无法转化为交付率的提升。
-
验证的四个层级必须渐进式实施:从单次提示内验证→跨会话目标验证→确定性门控→第二意见验证,不可跳级。
-
编译验证和测试验证的投入产出比最高:LLMLOOP 数据表明,仅编译+测试两层循环即可将 pass@1 从 71.65% 提升至 79.51%(+7.86%),占总提升的 85%。
-
分离执行与评判是关键杠杆:Anthropic 和实战案例都证明,将编码 Agent 和审查 Agent 分开能带来显著的质量收益。
-
质量门禁必须可程序化验证:一切不可被机器验证的约束,在 Agent 执行中都是无效约束。
-
Harness + SDD 双轮驱动可将 AI 代码率从 ~25% 提升至 ~90%,同时保持质量可控。
13.2 实施建议
| 优先级 | 建议 | 预期收益 | 参考来源 |
|---|---|---|---|
| P0 | 在 CLAUDE.md 中定义明确的验证标准 | 减少"信任-验证缺口" | Anthropic 官方 |
| P0 | 实现 Stop Hook 质量门控 | 确定性验证、无人值守 | Anthropic 官方 |
| P0 | 建立 CI/CD 自动化验证管道 | 过程中自动验证 | 行业通用实践 |
| P1 | 实现执行/审查 Agent 分离 | 独立质量评估、避免确认偏差 | Anthropic 推荐 |
| P1 | 将质量门禁程序化 | 防止 Agent 漂移 | 实战经验 |
| P1 | 建立评估数据集(20-50 个任务) | 量化质量趋势 | Anthropic 评估方法论 |
| P2 | 构建多维度评分器组合 | 全面质量画像 | Anthropic 评估方法论 |
| P2 | 实现能力评估→衰退评估的毕业机制 | 持续质量保障 | Anthropic 评估方法论 |
14. 参考来源
权威来源(官方/学术论文)
| # | 来源 | URL | 引用状态 |
|---|---|---|---|
| 1 | Anthropic《Claude Code: Best practices for agentic coding》 | Best practices for Claude Code - Claude Code Docs | |
| 2 | Anthropic《Demystifying evals for AI agents》 | Demystifying evals for AI agents \ Anthropic | |
| 3 | Anthropic《Claude SWE-Bench Performance》 | https://www.anthropic.com/research/swe-bench-sonnet | |
| 4 | LLMLOOP 论文(ICSME 2025) | [2603.23613] LLMLOOP: Improving LLM-Generated Code and Tests through Automated Iterative Feedback Loops | |
| 5 | LLMLOOP 开源代码 | https://github.com/ravinravi03/LLMLOOP | |
| 6 | SWE-bench Pro(Scale AI) | SWE-Bench Pro | |
| 7 | Vexp SWE-bench 开源基准 | https://github.com/Vexp-ai/vexp-swe-bench |
行业实践与报道
| # | 来源 | URL | 引用状态 |
|---|---|---|---|
| 8 | 奇富科技 AI Coding 落地成效(InfoQ) | AI Coding两年落地感受:研发效能显著提升,头部工程师产出杠杆持续放大 - InfoQ | |
| 9 | 《出码率90%却没提效?AI研发的真正瓶颈与 Harness + SDD 实战解法》 | 出码率90%却没提效?AI研发的真正瓶颈与 Harness + SDD 实战解法-腾讯云开发者社区-腾讯云 | |
| 10 | 《Harness Engineering 深度解析:AI Agent 时代的工程范式革命》 | https://zhuanlan.zhihu.com/p/2014014859164026634 | |
| 11 | 腾讯云代码助手测试工具全景解析 | 2026年自动化测试工具全景解析:腾讯云代码助手如何引领智能编程新时代-腾讯云开发者社区-腾讯云 | |
| 12 | Anthropic Agent 评估体系详细解读 | Anthropic 再发长文:首次详细揭秘Agent的评估全过程「Claude code开发过程的经验总结」_腾讯新闻 | |
| 13 | Claude Code Hooks 深度解析 | Claude Code Hooks 深度解析:16 种事件 + 6 个实战场景让你的工作流自动化-腾讯云开发者社区-腾讯云 | |
| 14 | Claude Opus 4.1 SWE-bench 分析 | 74.5%登顶SWE-bench:Claude Opus 4.1如何重塑AI编程格局_swe-bench最新排名-CSDN博客 | |
| 15 | Claude Opus 4.7 SWE-bench Pro 分析 | 大模型进入Agentic时代:Claude Opus 4.7如何用64.3%的SWE-bench成绩改写软件工程规则(国内可用,入口在文末)_swe-bench pro-CSDN博客 |
国际来源
| # | 来源 | URL | 引用状态 |
|---|---|---|---|
| 16 | Google Gemini Code Assist 官方 | https://cloud.google.com/gemini/docs/codeassist | |
| 17 | OpenAI Codex CLI | https://github.com/openai/codex | |
| 18 | claude-code-harness 开源项目 | https://github.com/Chachamaru127/claude-code-harness | |
| 19 | Harness Engineering Skills 开源 | https://github.com/Phlegonlabs/Harness-engineering-skills | |
| 20 | AI CLI 工具社区动态(agents-radar) | https://github.com/DenisZheng/agents-radar/issues/1119 |

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐
 8
8 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)