【图解】Claude Code 源码解析|Dynamic Workflow 与 Harness 范式
写在前面
当一个 Agent 单 Loop 干不完一件事的时候,怎么办?
放在之前那就是 multi-agent、ReAct + planner、各种 static workflow, LangGraph 之类的解决方案。新答案是——让 Agent 自己写一个一次性的、为这个任务量身定做的 harness。我感觉这是一个很大的范式转变,所以这篇想把它讲清楚。
这篇我们来讲讲 dynamic workflow,也就是 Claude 自己写 harness、自己调度几十上百个 subagent 的那套机制。
Harness 是什么
「Harness」这个词字面意思是「马具、挽具」,引申到 Agent 领域就是——套在 LLM 外面的一层执行壳。
我们写的 ReAct 是 harness、Claude Code 默认的 plan-execute Loop 是 harness、Cursor 的 Apply 流程也是 harness。
Agent = Harness+LLM,harness 就是模型外面那一层「该干啥、怎么干、谁先谁后」的调度逻辑。
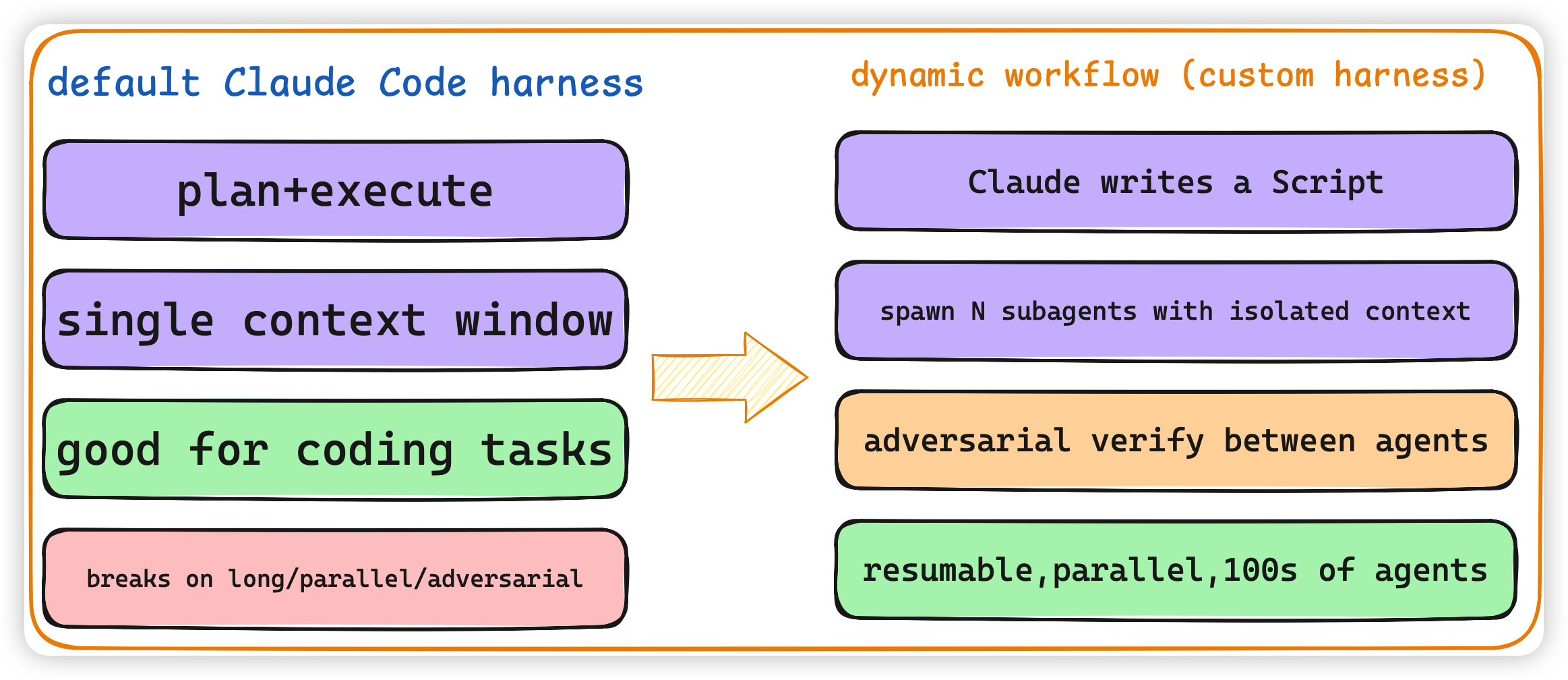
Anthropic 内部其实早就发现,默认 Claude Code 那个 harness,针对 coding 任务调得很好,但一旦换场景就拉跨。 所以他们以前要做 deep research、安全审查、code review 这些场景,都得自己手写一套 custom harness 套在 Claude Code 外面。
dynamic workflow 干的事情就是——把这个「写 custom harness」的活,交给 Claude 自己。
⚠️ 注意一点:这不是 multi-agent。multi-agent 框架是你提前定义好有几个 agent、谁先谁后、谁负责啥;dynamic workflow 是 Claude 看到你的任务以后,当场写一个脚本,脚本里调用 subagent 的函数,决定开几个 agent、怎么开、用什么模型。这个脚本是用过即弃的。
为什么要这个东西
为了解决单 Loop 的 3 个失败模式
官方原文给了三个非常精确的 failure mode 名字,这里我直接保留英文:
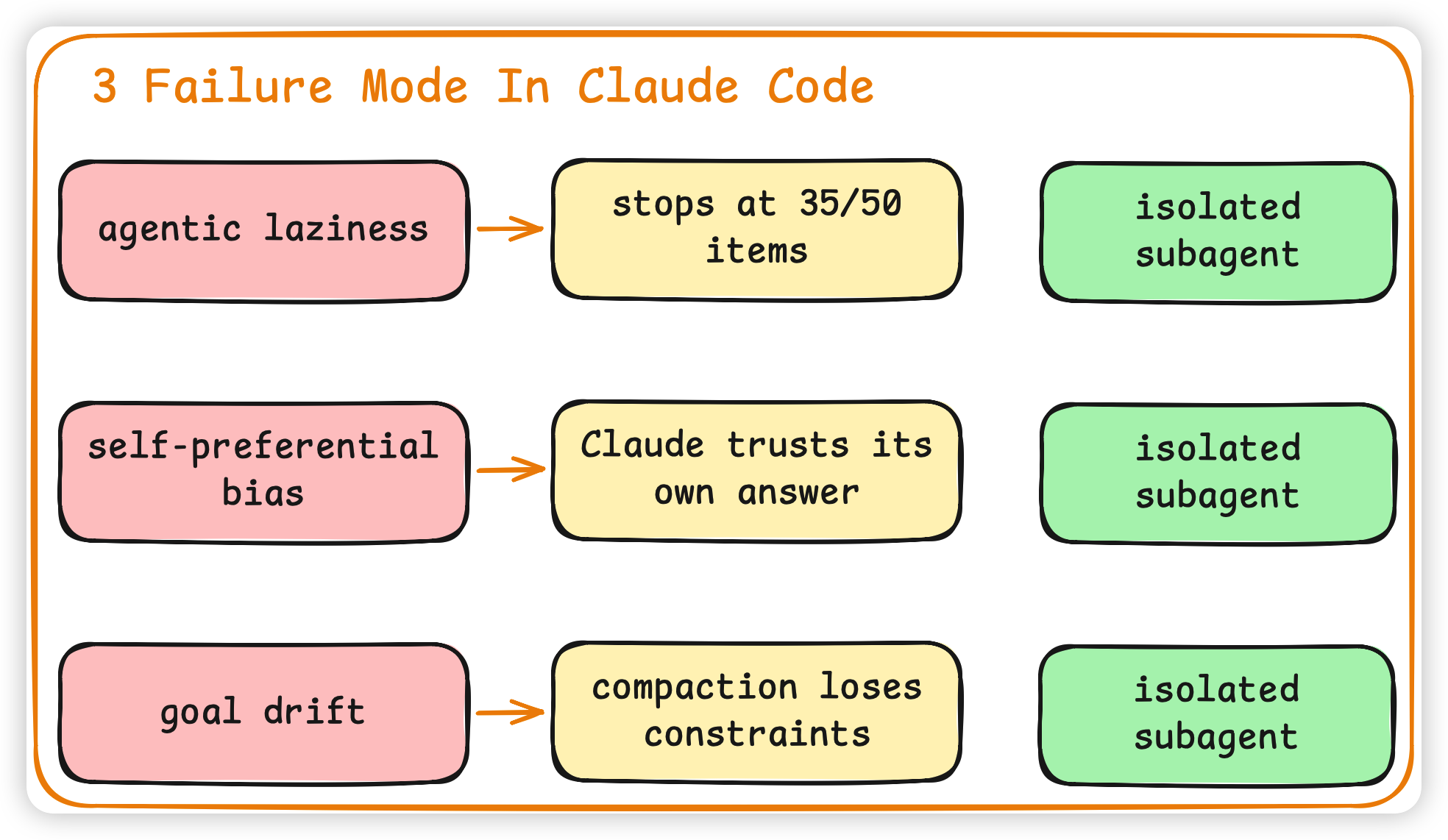
- agentic laziness:Claude 在复杂多步任务里,干到 35/50 就跟你说「搞定了」。
- self-preferential bias:让 Claude 自己 judge 自己的输出,它倾向于认为自己是对的。这是单 context 的结构性缺陷。
- goal drift:长 session 一旦经过 compaction(自动压缩历史),那些「不要做 XX」的负向约束最容易丢。
这三个问题的共同病根都是: 所有 turn 都挤在一个 context 里。
规范的解决方案是结构性地把 goal 拆到不同 context 里。一个 subagent 一个目标、一个干净的 context、一个明确的 stop condition。这才是 dynamic workflow 的工程意义。
Claude 写 harness 用的 6 种 pattern
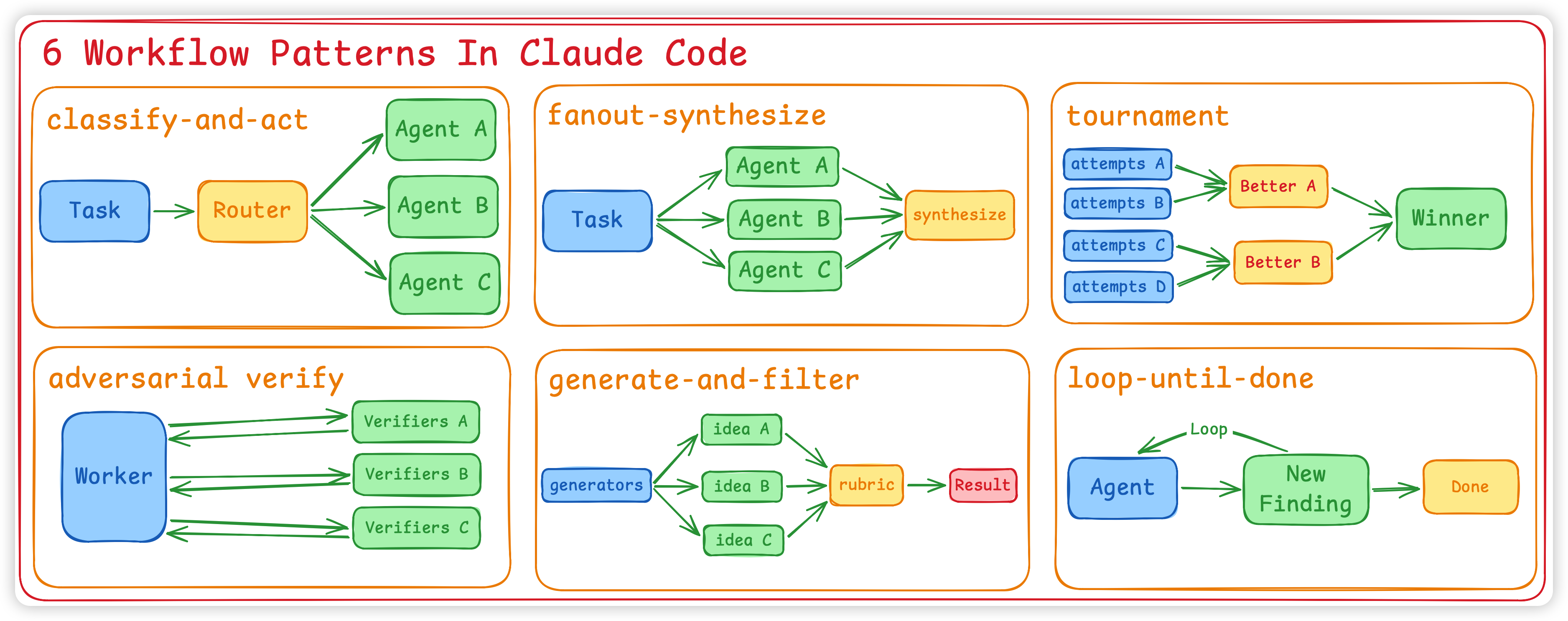
- classify-and-act:先 router 一下,再分支。
- fan-out / synthesize:拆 → 并行跑 → 合并。
- adversarial verify:每一个产出都配一个 critic。
- generate-and-filter:广撒网 → 用 rubric 过滤。
- tournament:N 个 agent 各自尝试 → 两两 PK 选最好的。
- loop-until-done:不指定 N 次,直到没新发现/没新错为止。
这 6 个 pattern, Claude 会 自由组合。根据任务写一个脚本,里面可能 classify-and-act 完之后接一个 fan-out/synthesize,每个 fan-out 节点又内嵌一个 tournament之类的,一层套着一层。
fan-out / synthesize
最常见的是 fan-out / synthesize
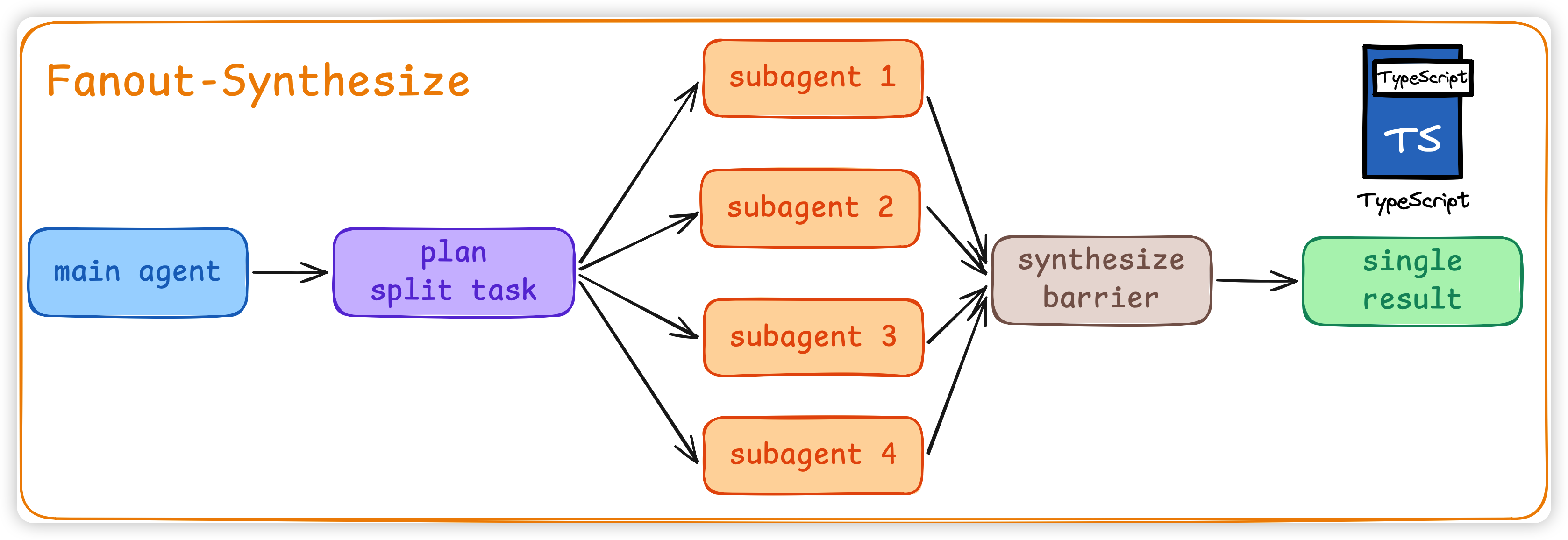
- 主 agent 把任务拆成 N 个子任务
- 开 N 个 subagent 并行做
- 一个 synthesize barrier 等所有 subagent 跑完
- 合并成一个结果
⚠️ 注意:synthesize 是个 barrier(屏障)。它必须等所有 fan-out agent 都跑完,才能合并。「barrier」这个词是从并发编程里借过来的,这套东西本质就是把传统并发原语搬到 Agent 调度上。做过搜推 DAG 的同学应该会觉得很熟悉。
adversarial verify
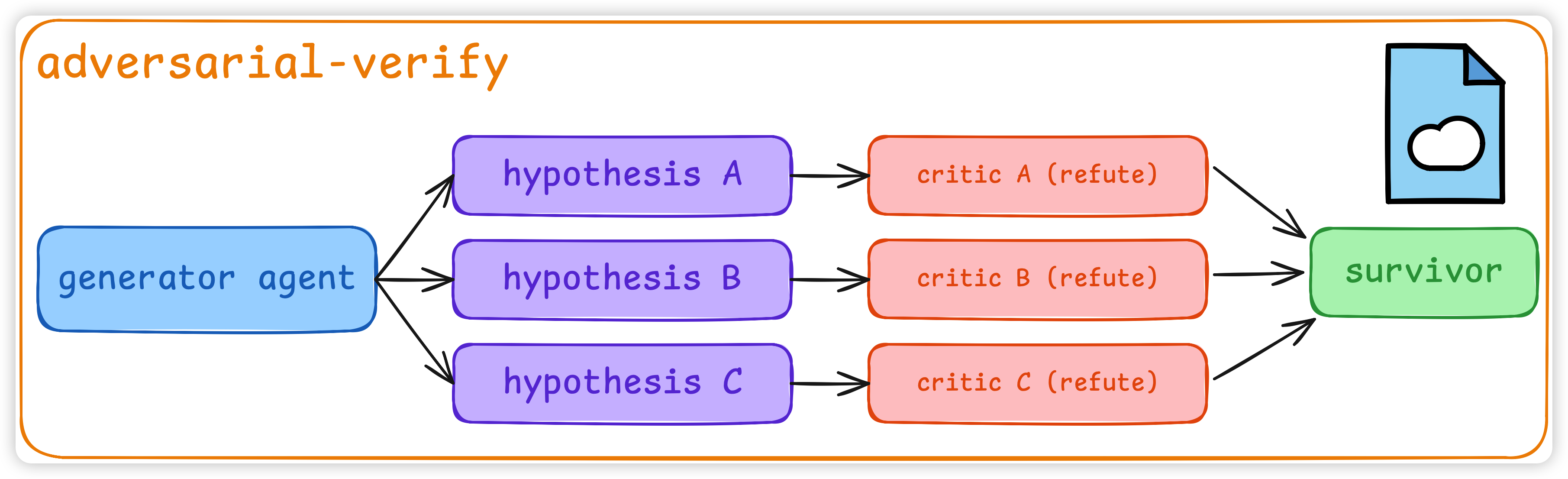
- 每一个 subagent 的产出,都开一个全新的 critic agent 去攻击它。
- critic 看不到 generator 的 reasoning trace,它只看结果,按 rubric 挑刺。挑得过关的才往下走。
这套机制是 dynamic workflow 里比较关键的:因为单 Loop 的 self-preferential bias 我们是没有任何工程手段可以解,我们不能跟模型说「你要批判自己的答案」,它做不到。但你可以开一个新的 context、不带历史、专门挑刺的 agent去做这件事情。
一些注意事项
- prompt 要详细。dynamic workflow 不是 “帮我看看” 用的,是需要带着明确评分准则的复杂任务用的。
- 可以设 token budget。
use 10k tokens这种明确预算,模型会遵守。 - 配合
/goal用——dynamic workflow 容易跑偏,给它一个硬约束的 done criteria。 - Quarantine 模式:让读外部不可信内容的 agent 不要拥有高权限,权限交给另一组只读结果的 agent。
- 可以选模型:workflow 脚本里可以指定 subagent 用 Sonnet 还是 Opus,subagent 是不是开 worktree 隔离。让 classifier agent 自己决定——
简单子任务给 Sonnet、复杂的给 Opus。
⚠️ 注意:用之前先问自己一句,这个任务真的需要更多 compute 吗? 如果不是,开 5 个 reviewer agent 不会让代码变得更好,会变得更烧钱。
最后
- dynamic workflow 的本质,是 Claude 给自己写一次性的 harness。 解决的是
单 Loop 在长任务上结构性失败的问题。 - 它真正的工程贡献,是把并发原语(barrier、fan-out、tournament)搬到 Agent 调度。 让 Agent 编排终于能用工程化方法去 reason。
- adversarial verify 是 self-preferential bias 的结构解,是这套范式里最有价值的设计。
单 Loop 没法解的问题,多 context 隔离 + critic agent 能解。

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐


 6
6 1
1- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)