AI Loop:别再写 Prompt 了,去设计循环吧
一、🔍 什么是 Loop?
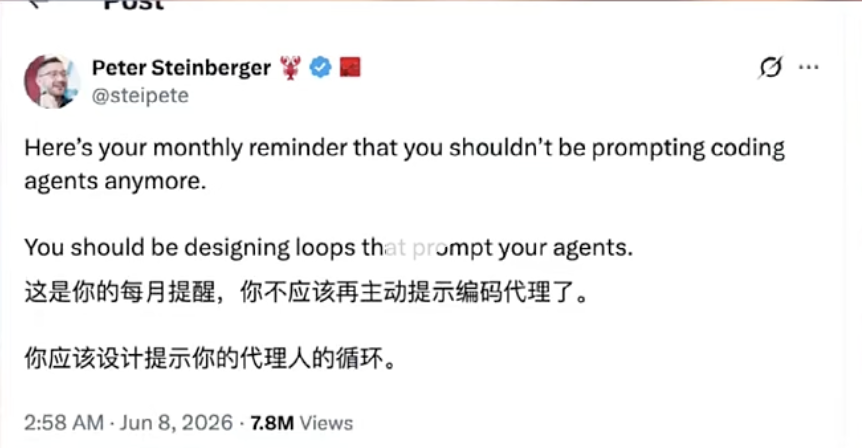
Loop(循环)是计算机最底层的能力之一。它只包含三件事:
- 🏁 从哪开始
- 🔄 重复做什么
- 🛑 什么时候停
面对一万行数据,要逐行检查、改格式——人工做很慢,但写一个循环程序,几秒钟就跑完了。
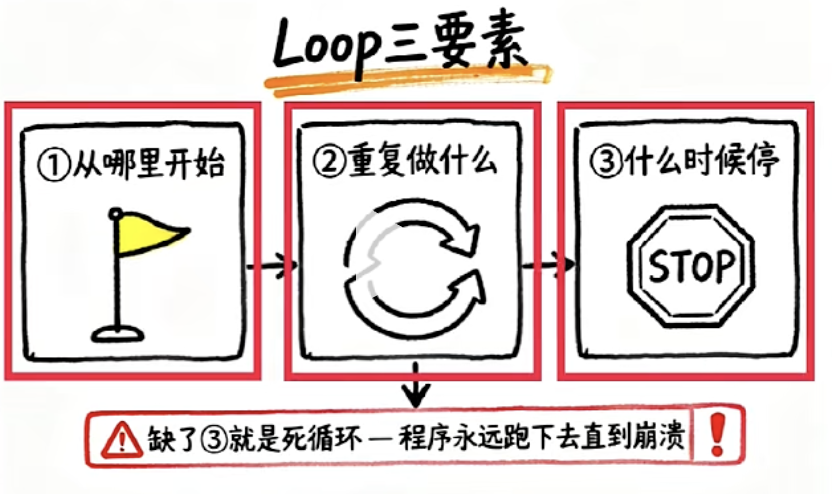
这个看似简单的逻辑,其实也是所有大语言模型(LLM)的底层训练方式。无论是 DeepSeek、Claude 还是 Qwen,训练过程都遵循同一个模式:
📦 拿一批数据给模型看 → 📏 算它错了多少 → 🔧 调整参数 → 🔁 再来一轮。
万亿次循环之后,AI 就学会了对话和协作。✨
二、😮💨 日常协作的困境
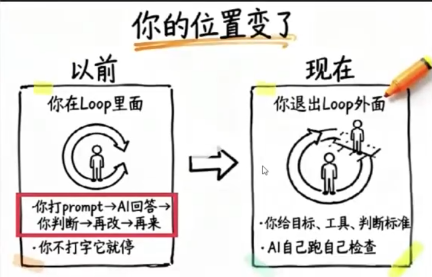
我们每天跟 AI 一问一答的过程,本质上也是一个人工驱动的 Loop:
✍️ 写 Prompt → 👀 看结果 → 😞 不满意 → 📝 改 Prompt → 🔁 再来一遍
这种方式的问题是:虽然工作交给了 AI,但人必须盯着 AI 干活。 👀 每轮都要手动判断结果好不好、手动修改输入,人始终被绑在流程里。😩
Loop 的核心价值,就是把人从循环中抽离出来。 🚀 让 AI 自己生成、自己检查、自己迭代,直到满足条件。
三、🏗️ AI Loop 的架构
AI Loop 包含两个核心环节:
- 🧠 生成(Generation):调用 LLM 生成内容
- 🔎 校验(Check):调用 LLM 检查生成结果是否符合规则
两者交替执行,形成一个自治环路:
┌──────────┐ ┌──────────┐
│ 🧠 gen() │ ──→ │ 🔎 check()│
│ 生成内容 │ │ 校验结果 │
└──────────┘ └────┬─────┘
↑ │
│ ┌───────────┘
│ │ ✅ pass? → 结束
│ │ ❌ fail? → 再来一轮
└────┘
四、💻 代码实现
4.1 🔌 初始化与配置
首先加载环境变量,创建 OpenAI 兼容的客户端(这里使用 DeepSeek):
import { OpenAI } from 'openai'
import dotenv from 'dotenv'
dotenv.config();
const client = new OpenAI({
apiKey: process.env.DEEPSEEK_API_KEY,
baseURL: process.env.DEEPSEEK_API_BASE_URL
});
4.2 🛑 刹车机制——防止死循环
Loop 最大的风险是停不下来。我们需要三种刹车策略:
const limit = {
maxRound: 5, // 最大尝试次数,防止死循环
maxTokens: 2000, // 超预算限制,控制成本
sameStop: 2 // 连续相同几次停下来,避免原地踏步
}
每种刹车各有分工:
| 刹车方式 | 作用 | 防止什么 |
|---|---|---|
🔢 maxRound |
限制循环轮次 | 🔁 无限循环 |
💰 maxTokens |
限制 token 消耗 | 💸 费用失控 |
⏸️ sameStop |
连续相同即停 | 🌀 生成内容不再变化时无意义消耗 |
对应的刹车判断函数:
let round = 0, totalTokens = 0, lastText = "", sameCount = 0;
function needStop() {
return round >= limit.maxRound
|| totalTokens >= limit.maxTokens
|| sameCount >= limit.sameStop;
}
4.3 📋 定义任务与规则
任务描述和校验规则是关键——规则越清晰,Loop 越高效:
const task = {
desc: "小红书美妆文案",
rules: [
"标题带数字",
"正文<300字",
"正文包含图片",
"大爆款",
"结尾有行动号召"
]
}
4.4 🧠 生成函数 —— gen()
调用 LLM 生成内容,返回文本和消耗的 token 数:
async function gen() {
const res = await client.chat.completions.create({
model: 'deepseek-v4-flash',
messages: [
{
role: 'user',
content: `假如你是一位资深小红书美妆博主,
写一篇${task.desc},
严格遵守:${task.rules.join("、")},只输出文案`
}
]
})
return {
text: res.choices[0].message.content.trim(),
token: res.usage.total_tokens
};
}
4.5 🔎 校验函数 —— check()
再调用一次 LLM,让它以结构化的方式判断生成结果是否满足所有规则:
async function check(text) {
const res = await client.chat.completions.create({
model: 'deepseek-v4-flash',
messages: [
{
role: 'user',
content: `校验${text}
规则:${task.rules.join("、")},
仅输出JSON{pass:布尔,fail:数组}`
}
]
})
return JSON.parse(res.choices[0].message.content.trim());
}
💡 注意这里要求 LLM 输出 JSON 结构 {pass: boolean, fail: string[]},这样程序可以直接解析,不需要人工介入判断。
4.6 🔁 核心循环 —— runLoop()
把生成和校验串起来,构成自治循环:
async function runLoop() {
console.log('AI Loop 开始');
while (!needStop()) {
round++;
console.log(`\n第${round}轮`);
const { text, token } = await gen();
totalTokens += token;
// 检测是否与前一次内容相同
sameCount = text === lastText ? sameCount + 1 : 0;
lastText = text;
const { pass, fail } = await check(text);
if (pass) {
console.log(`全部规则通过,循环结束`);
console.log(`最终文案:${text}`);
return; // 通过,退出
} else {
console.log(`不满足${fail}`);
// 继续下一轮
}
}
console.log(`触发刹车强制停止,最后一次内容:${lastText}`);
}
runLoop();
五、🎬 完整执行流程
整个 Loop 的运行过程如下:
🔄 第1轮: gen() 生成文案 → check() 校验 → ❌ fail: ["标题带数字", "大爆款"]
🔄 第2轮: gen() 生成文案 → check() 校验 → ❌ fail: ["正文包含图片"]
🔄 第3轮: gen() 生成文案 → check() 校验 → ❌ fail: ["结尾有行动号召"]
🔄 第4轮: gen() 生成文案 → check() 校验 → ✅ pass → 🎉 结束
或者触发刹车:
🔄 第1~5轮: 始终有个规则不满足 → 🛑 maxRound 触发 → 强制停止
六、⚖️ 优势与成本
✅ 优势
- 🚀 解放人力:不需要人工盯着每一轮结果、手动改 Prompt 再试
- 📏 可量化:规则明确、结果可编程解析,不像"差不多""还行"这种主观判断
- 🔧 可复用:换一个
task.desc和task.rules,就能用于其他场景(文案、代码、翻译……)
⚠️ 缺点
- 💸 Token 消耗量大:每轮都需要一次生成 + 一次校验,堆叠起来 token 成本不容忽视
- 🎲 LLM 判断的可靠性:check 环节本身也依赖 LLM,校验结果的准确性并非 100%,复杂规则可能出现误判
这也是 readme 中提到的核心权衡:Loop 解放了人,但 token 量会爆炸。 💣
七、🚀 思考延伸
这个 Demo 虽然简单,但揭示了一个方向性的转变:
💬 从"我一问,AI 一答" → 🤖 “我设规则,AI 自己跑”
Claude Code 的作者也说过类似的话——他不是在写 prompt,而是在设计 loop。当你把"写提示词"的思维,切换到"设计循环和校验规则"的思维,AI 的使用方式就完全不同了。
你可以在这个框架上继续扩展:
- 🧠 多模型协作:用不同的模型负责生成和校验,发挥各自优势
- 🪜 渐进式规则:第一轮先过基础规则,后续轮次逐步收紧
- 📝 历史反馈:把上一轮失败的原因喂给下一轮的生成,让 AI 有针对性地改进
- 🏆 多路径竞争:同一轮生成多个版本,只留校验得分最高的那个继续迭代
Loop 这个概念,简单却强大——它把 AI 从"🔧 工具"变成了"👷 工人"。

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐
 27
27 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)