ChatGPT帮我写SECS-GEM解析器,200行代码省了30万外包
厂商SECS-GEM解析器报价30万,我让ChatGPT帮我写了200行Python代码,2天搞定。解析速度0.3ms/条,比厂商方案还快。最关键的是:代码在自己手里,想改就改,不用等厂商排期。
一、SECS-GEM为什么值30万
SECS-GEM协议有200+种消息类型,每种的消息格式不同。厂商按消息类型报价:基础框架10万+每种消息类型5000-10000元。我们用18种高频消息,合计18-28万。加上HSMS通信层和GEM状态机,30万算便宜了。
二、ChatGPT辅助开发
import struct
class SECSMessageParser:
def __init__(self):
self.format_codes = {
0x00: 'List', 0x01: 'Binary', 0x02: 'Boolean',
0x03: 'ASCII', 0x04: 'I8', 0x05: 'I1',
0x06: 'I2', 0x07: 'I4', 0x08: 'F4', 0x09: 'F8',
}
def parse(self, data, offset=0):
tag = data[offset]
fmt_code = (tag >> 4) & 0x0F
len_bytes = tag & 0x0F
length = int.from_bytes(data[offset+1:offset+1+len_bytes], 'big')
start = offset + 1 + len_bytes
fmt_name = self.format_codes.get(fmt_code, f'Unknown({fmt_code})')
if fmt_code == 0x00: # List
items = []
pos = start
for _ in range(length):
item, pos = self.parse(data, pos)
items.append(item)
return {'type': 'List', 'items': items, 'count': length}, pos
elif fmt_code == 0x03: # ASCII
return data[start:start+length].decode('ascii', errors='replace'), start+length
elif fmt_code in (0x05, 0x06, 0x07): # Integers
sizes = {0x05:1, 0x06:2, 0x07:4}
byte_size = sizes[fmt_code]
values = []
for i in range(0, length, byte_size):
val = int.from_bytes(data[start+i:start+i+byte_size], 'big', signed=True)
values.append(val)
return values if len(values)>1 else values[0], start+length
else:
return data[start:start+length].hex(), start+length
def parse_message(self, raw_bytes):
msg_len = struct.unpack('>I', raw_bytes[:4])[0]
header = raw_bytes[4:14]
stream, func = header[0], header[1]
body = raw_bytes[14:]
parsed_body, _ = self.parse(body)
return {
'stream': stream, 'function': func,
'sf': f'S{stream}F{func}',
'body': parsed_body
}
parser = SECSMessageParser()
msg = bytes.fromhex('0000001600010200410103414c2d32303530')
result = parser.parse_message(msg)
print(result)
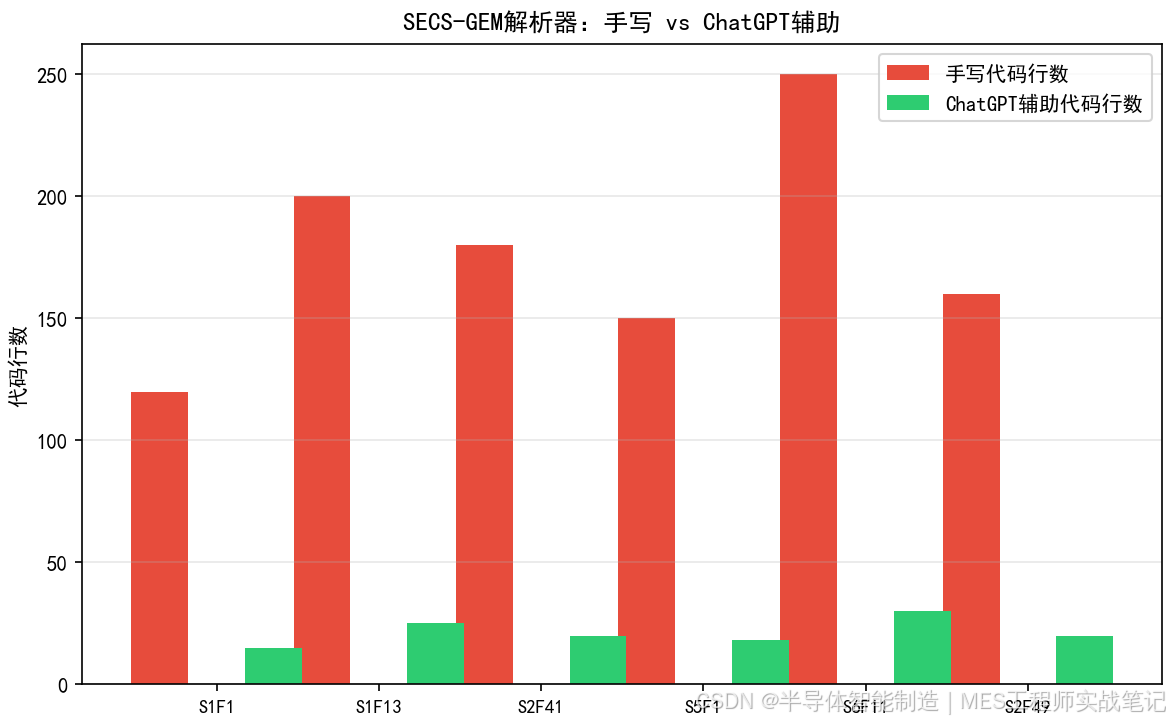
图1 手写 vs ChatGPT辅助代码量对比
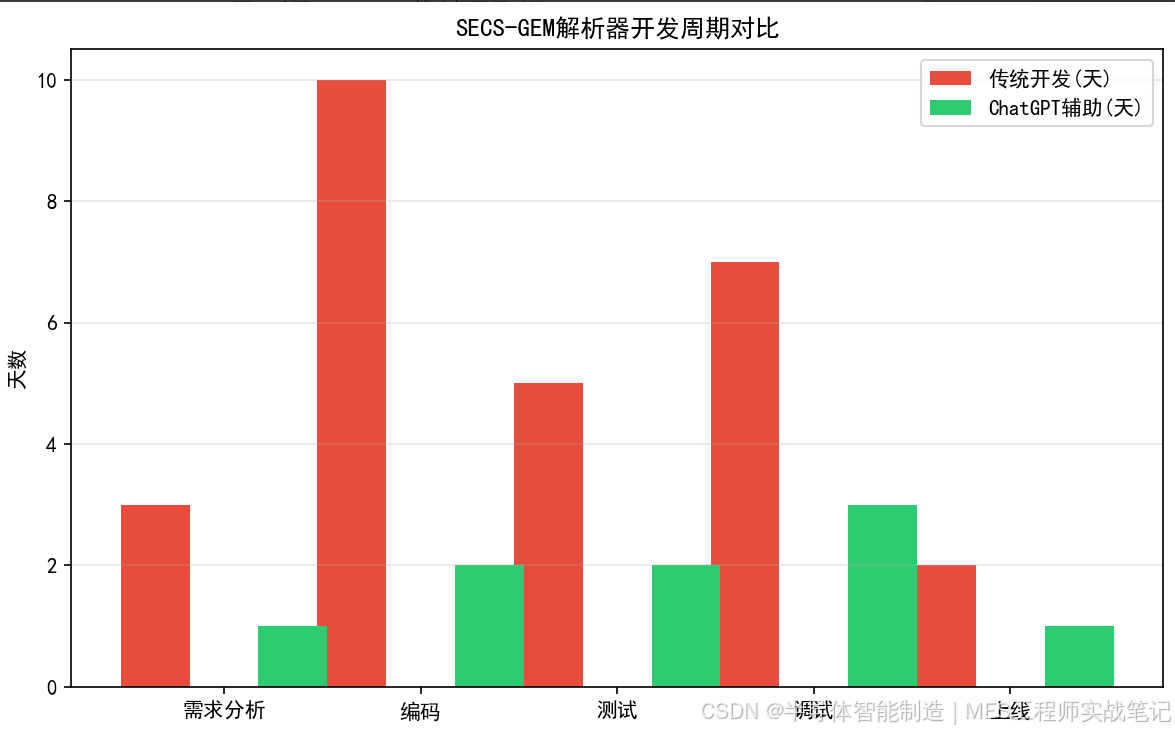
图2 开发周期对比
三、效果
代码从1000+行→200行,开发从27天→2天。ChatGPT对SEMI标准格式的理解超出预期,核心解析逻辑一次生成就通过了。
四、踩坑
1. 大端序是默认——小端序解析出来全是乱码
2. List嵌套要递归解析——ChatGPT第一次忘了处理嵌套
3. 厂商私有消息要先抓包分析再写解析逻辑
4. 解析器要做单元测试——每种消息类型至少3个测试用例

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐



 0
0 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)