教会 AI “顺着线索查案“:一套能让 AI 自己定位 Bug 根因的提问方法
教会 AI “顺着线索查案”:一套能让 AI 自己定位 Bug 根因的提问方法
阅读时间约 8 分钟。不需要会写代码,只要你用过 AI 帮你做过任何"需要排查问题"的事情(写代码、改文档、配环境……),这篇文章对你都有用。
写在前面:这篇文章在讲什么
现在很多人已经习惯让 AI(比如 Claude、ChatGPT)帮自己写代码、改 bug。但你可能也遇到过这种情况:
你说:“页面打不开/数据不显示,帮我看看怎么回事。”
AI 很快回复:“可能是数据库没有数据,你检查一下数据库。”
你查了,数据库明明有数据。AI 猜错了,你们都浪费了一轮。
这不是 AI “笨”,而是它在没有线索的情况下被迫瞎猜。它就像一个刚到案发现场、还没看任何证据就被要求"说说凶手是谁"的侦探——它当然只能猜一个最常见的可能性。
这篇文章分享一套提问方法:通过给 AI 一个"排查框架",逼它像真正的侦探一样,一步步看证据、下钐论、再验证,而不是凭直觉乱猜。文章后半部分附了一个真实的排查案例(来自一个个人项目的真实 bug),给想深入看技术细节的读者参考;前半部分的方法论部分,不需要懂代码也能看懂。
一、先理解一个核心问题:AI 为什么会"乱猜"
AI 回答问题时,本质上是在用最可能的答案填空。如果你的问题信息量太少,AI 只能依赖"统计上最常见的原因"来回答——这往往是真正原因的概率并不高。
打个比方:
- 你问医生:“我头疼,怎么回事?”——医生大概率会说"可能是没睡好,或者感冒了",因为这是头疼最常见的两个原因。
- 但如果你说:“我头疼,集中在左侧太阳穴,过去三天每天下午发作,伴随畏光,没有发烧”——医生能给出的判断会精确得多,因为你提供了可以缩小范围的具体线索。
AI 也是一样。“哪里不对"说得越含糊,AI 给的答案就越像是"统计意义上最常见的猜测”,而不是"针对你这个具体情况的判断"。
二、解决方法:给 AI 一条"下钻路径",而不是只给一个现象
2.1 什么是"下钻"
“下钻”(drill down)是排查问题时的一种思路:从最外层、最容易看到的现象开始,一层层往里,直到找到最根本、最不容易直接看见的原因。
比如手机突然没网了,下钻的过程大概是:
现象:手机显示"无网络连接"
↓ 下钻一层:是 Wi-Fi 断了,还是流量没了?
↓ 下钻一层(假设是 Wi-Fi):是手机的问题,还是路由器的问题?
↓ 下钻一层(假设是路由器):是路由器没电,还是宽带欠费?
↓ 根因:宽带欠费,运营商停了网
每一层都是一个"二选一"或"几选一"的判断,并且每一层的判断都需要证据,而不是直接靠经验"我觉得是 xxx"。
2.2 排查任何"系统性问题",本质都可以分成三层
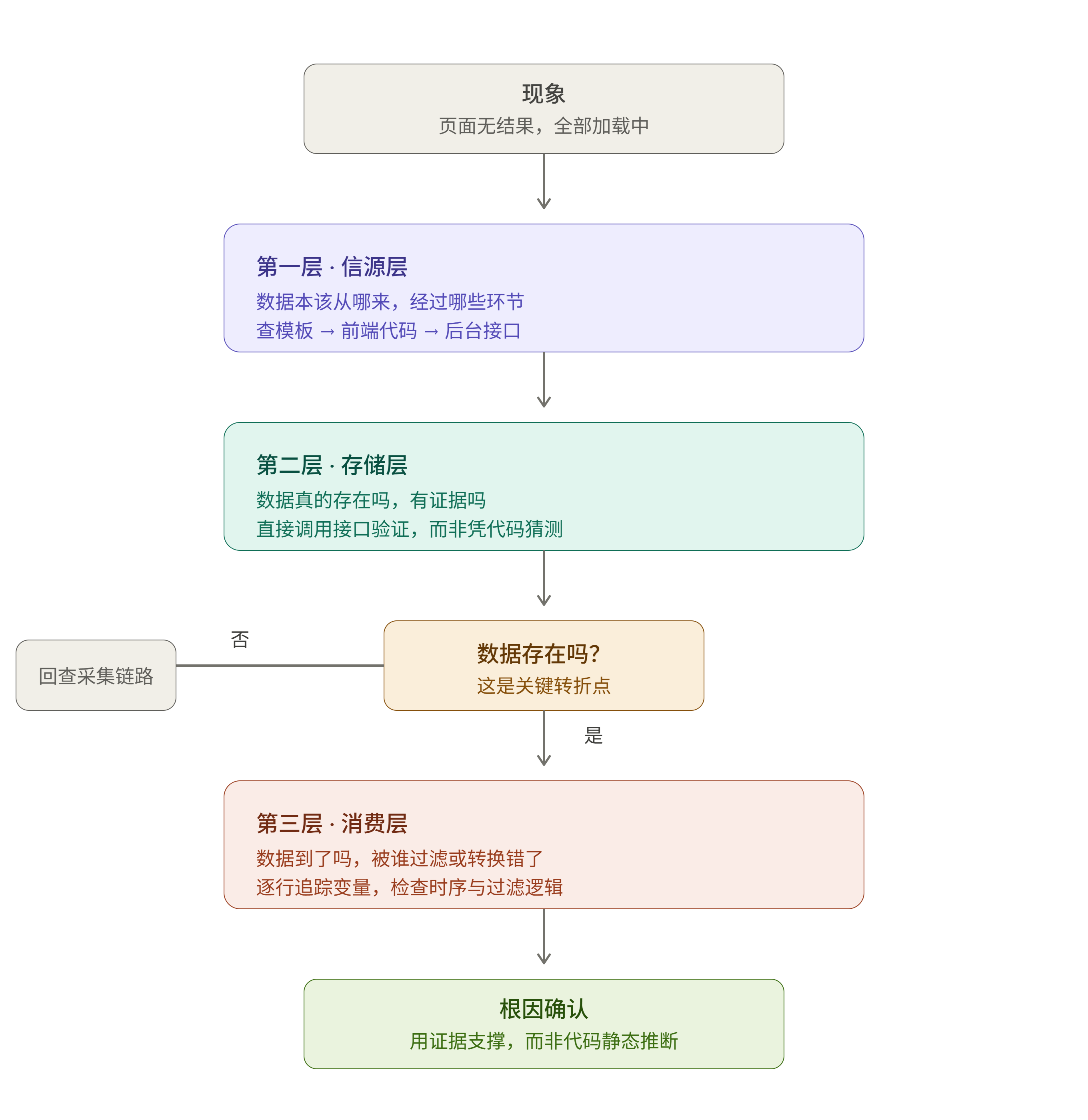
不管是网页、APP、还是某个工作流程出了问题,几乎都可以套用这三层框架来问:
| 层级 | 这一层在问什么 | 类比 |
|---|---|---|
| 第一层:信源层 | 这个东西本来应该从哪里来?经过了哪些环节? | 快递到底是从哪个仓库发出来的,经过了几个中转站? |
| 第二层:存储层 | 东西真的存在吗?是不是已经"产生"了,只是没显示出来? | 快递真的已经到了你家小区的驿站吗?还是压根没发货? |
| 第三层:消费层 | 东西已经产生了,为什么我这边看不到/用不了? | 快递到驿站了,但通知短信没发给你,或者你把它当成垃圾短信屏蔽了? |
这三层的顺序很重要:大多数人(包括 AI)习惯从"存储层"开始猜(“是不是数据库没数据”),因为这是最容易想到、最容易表述的猜测。但实际经验里,问题出在"消费层"(已经有了,但传递/显示环节出错)的情况,比"压根没产生"的情况更常见,也更隐蔽——因为消费层出问题时,往往没有任何报错,系统看起来一切正常,只是结果不对。
2.3 一句话总结这套方法的核心
不要问"是不是 A 出了问题",要问"东西从产生到我看见,一共经过哪几步?每一步都给我证据,证明它在那一步是正常的。"
这句话背后的逻辑是:把一个模糊的"哪里错了"问题,拆成一串可以逐个验证的"是/否"问题,AI(或者任何排查者)就不需要"猜",只需要顺着链路一步步"查"。
三、可以直接套用的提问模板
下面这个模板,你可以直接复制,把方括号里的内容换成你自己的情况:
你看一下 [项目名/系统名],当前 [某个功能/页面] 出现了 [具体现象]。
请按照完整链路排查,不要直接猜原因:
1. 先搞清楚这个内容/数据本来应该从哪里产生、经过哪些步骤,最后显示给我;
2. 然后逐步验证每一步是否正常:数据真的产生了吗?有证据吗?
传递到下一步了吗?有证据吗?最后显示这一步,过滤/转换逻辑对吗?
3. 每往下查一层,都把你看到的证据(命令输出、日志、截图等)给我看,
不要凭代码直接下结论。
4. 找到根因后,把你的完整推理过程(也就是你是怎么一步步排除掉
其他可能性,最后定位到这个原因的)写给我看。
5. 如果你说问题解决了,要给我能验证的证据(比如实际运行结果),
没有证据我不会认为问题已经解决。
3.1 这个模板里每一句话在起什么作用
| 模板里的句子 | 作用 | 如果去掉会怎样 |
|---|---|---|
| 点名项目/系统范围 | 防止 AI 在不相关的地方瞎找 | AI 可能去翻一些无关的文件,浪费时间 |
| 具体描述现象 | 给 AI 一个明确的"反推起点" | 现象太模糊,AI 没法往回查,只能瞎猜 |
| “不要直接猜原因” + “按链路排查” | 强制 AI 走流程,而不是抄近路给结论 | AI 大概率第一句话就给一个猜测性结论 |
| “每一步都要证据” | 逼 AI 真的去执行验证(比如真的运行一下命令),而不是纯靠"读代码、凭感觉" | AI 可能只读代码就下结论,而代码"看起来对"不代表"实际跑起来对" |
| “把推理过程写给我看” | 让你能够监督和理解 AI 的判断逻辑,而不是被一个"黑箱结论"说服 | 你没法判断 AI 这次是真的查出来了,还是又在编 |
| “没有证据不算解决” | 防止 AI 为了让你满意,过早宣布"问题已解决" | AI 有时会在没有真正验证的情况下说"已经修好了" |
3.2 一个简单的对比,看看这套方法的效果差异
❌ 普通提问方式:
你:“为什么页面是空白的?”
AI:“可能是数据库里没有数据,建议检查一下数据库。”
你:(查了数据库,发现数据其实在缓存里,根本不在数据库表里——AI 第一句就猜错了方向)
✅ 结构化提问方式:
你:“按完整链路排查,不要直接猜。页面上的内容应该是从哪一步产生、经过哪些环节,最后显示出来的?每一步给我证据。”
AI:先去看页面代码 → 找到数据是从一个接口拿的 → 实际调用接口,发现接口真的返回了数据(证据1) → 既然数据没问题,那问题必然在"接口返回数据"之后的某一步 → 继续往下查,发现是页面里有一个先后顺序搞反了的小逻辑,导致数据被提前过滤掉了(证据2)→ 找到真正原因。
两种方式的关键差异:第二种方式逼着 AI 把"系统中真实存在的状态"一步步摸出来,而不是直接说出一个听起来合理但没验证过的猜测。
四、把这次排查经验"存下来",让 AI 下次直接复用
如果你比较常用某个 AI 工具(比如有"长期记忆"功能的 AI 助手),可以考虑把这次排查的方法和结论都记录下来,分成两份:
1. 通用方法(以后遇到任何类似问题都能用)
排查"系统里有问题但说不清哪里错"类问题时,按以下顺序检查:
第一步:东西本来该从哪产生?经过哪些环节?
第二步:东西真的产生了吗?有什么证据?
第三步:东西产生了,为什么没传到我看到的地方?是不是中间被过滤/转换错了?
通用提示:没有任何报错信息时,往往问题出在"已经产生但传递/展示环节出错",
而不是"压根没产生"。这种情况最容易被误判为"数据没了"。
2. 这一次的具体记录(仅供回顾这一次事件用)
现象:xxx
最终根因:xxx
怎么修的:xxx
下次遇到类似情况,可以直接对照这次的根因模式排查。
这样下次遇到类似问题,你甚至可以直接说"参考上次那次排查方法",AI 就能直接复用思路,不需要你重新教一遍。
五、附录:一次真实的排查案例(技术细节,供深入参考)
这部分涉及具体的项目代码和技术名词,如果你只想了解方法论,到这里就可以停了。如果你想看"理论是怎么在真实场景里被执行出来的",可以继续往下看。
背景说明(技术名词简单解释)
- 这是一个个人博客项目里的"世界观测站"页面(
/world),页面上会展示从各种信息源(科技新闻、GitHub 热门项目等)抓取来的内容。 - Alpine.js:一种轻量级的前端框架,作用是让网页能够"动态"地从后台获取数据并展示,不用整页刷新。
- 缓存(Cache):一种临时存数据的地方,类似"便利店货架",区别于数据库这种"长期仓库"——东西可能放在便利店货架上(缓存),但仓库(数据库)里没有记录,这是完全正常的,不代表"东西不存在"。
- API:前端页面和后台服务器之间"要数据"的接口,类似点餐时服务员和厨房之间传递订单的窗口。
现象
用户访问 /world 页面,所有数据区块都卡在"加载中…",没有任何内容显示。
排查过程(对照第二章的三层框架)
第一层:信源层 —— 数据本该从哪来?
依次查看了页面模板文件、前端 JS 代码、后台 API 路由,确认数据流转路径是:
页面模板 → 前端 JS(Alpine.js) → 后台 API → 缓存
第二层:存储层 —— 数据真的存在吗?
直接用命令行工具模拟调用 API(curl /api/market/news?limit=50),结果返回了 50 条真实数据。同时查了后台的"信源健康记录",确认多数信源采集是成功的。
→ 这一步的结论:数据是存在的,问题不在"有没有数据",而在"数据之后发生了什么"。这是整个排查里最关键的一次转折——如果停在"猜数据库没数据",方向就错了。
第三层:消费层 —— 数据有了,为什么没显示?
逐行查看前端 JS 里页面初始化的代码,发现一个时序问题:
- 页面在拿到新闻数据后,会用一个"信源配置列表"对新闻做过滤(只显示用户关心的信源);
- 但代码里,"过滤新闻"这一步执行得比"加载信源配置"还早;
- 也就是说,过滤发生时,“信源配置列表"还是空的,于是所有新闻都被当成"不属于任何已配置信源”,被过滤掉了。
这种问题最隐蔽的地方在于:接口请求全部成功(状态码 200),代码逻辑本身也没有任何语法错误,系统不会报任何错——但结果就是不对。
根因与修复
- 根因:前端代码里两个异步操作的执行顺序写反了,导致"过滤逻辑"在"过滤所需的配置"加载完成之前就执行了。
- 修复:调整代码执行顺序,确保"信源配置"先加载完,再执行新闻过滤。
- 验证:重新触发一次数据抓取,再次用命令行调用接口确认返回数据正常,并实际打开页面确认内容正常显示。
排查中发现的其他小问题(一并修复)
排查主问题的过程中,顺带发现并修复了几个相关的小问题,比如:某个信源的抓取接口已经更新了新版本但代码还在用旧版本、某个信源的旧抓取方式(RSS)已经停止维护、某个配置项的数据类型不对导致数值处理出错等。这些不是本次"页面空白"的根因,但都是排查链路上顺手清理掉的隐患。
这次排查的复盘:哪里还能做得更快
| 环节 | 当时做法 | 更好的做法 |
|---|---|---|
| 查找相关代码文件 | 一个一个文件去读 | 可以用关键词搜索直接定位,更快 |
| 调试某个信源接口问题 | 反复用命令行试了好几次 | 应该先直接看返回内容的具体细节,而不是只看"成功/失败"状态 |
| 验证修复效果 | 临时加了调试用的接口,用完没留下 | 应该把这类"触发重新抓取"的功能做成永久可用的管理功能,方便以后排查 |
这几点也说明,排查方法论之外,保留一些"方便下次排查"的工具或接口,本身也是值得长期投入的事情。
六、写在最后
这套方法的核心,其实不是什么"高深技巧",而是一个朴素的常识:遇到问题先看证据,再下结论,而不是先有结论再找证据。 这件事对人来说是常识,但 AI 在没有被明确要求的时候,常常会因为"想尽快给你一个答案"而走捷径。
你要做的,只是在提问的时候,明确告诉它"不要走捷径,按顺序查,每一步都要给证据"。这件事不需要你懂技术细节,只需要你愿意多打几个字,把"哪里不对"换成"东西是怎么一步步到我面前的,麻烦你帮我顺着这条路查一遍"。

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐
 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)