一次讲清 MCP:OpenAI 和 Anthropic 的格式差异,以及 Agent 的统一接入层
一次讲清 MCP:OpenAI 和 Anthropic 的格式差异,以及 Agent 的统一接入层

问题不在“能不能接”,而在“以后还接不接得动”
你做了一个 Agent 项目,第一版跑在 OpenAI 上。
你翻到 OpenAI 文档,发现有 type: "mcp",感觉这事很简单:远程 MCP Server 直接挂进去就行。后来团队又说要支持 Claude,于是你去看 Anthropic 文档,发现它也有 MCP connector。
这时问题就来了。
如果你把 MCP 直接绑在某一家模型厂商的原生字段上,系统很快会长成这样:
OpenAI Adapter 里写一套 MCP 接法
Anthropic Adapter 里再写一套
表面上看,两家都“支持 MCP”。实际上,你会得到两套边界不同、回填方式不同、执行位置也不同的工具接入代码。后面再叠加兼容 OpenAI / Anthropic 的模型,复杂度只会继续长。
真正的问题不是“哪家文档写得更详细”,而是:
在多模型 Agent 项目里,MCP 这层到底应该放在模型 API 上,还是放在你自己的 Agent 运行时里?
这篇文章就讲清楚这件事。
一句话定义
MCP 统一接入的关键,不是挑哪家厂商“原生支持 MCP”,而是让你的 Agent 自己做 Host,自己管理 MCP Client,再把 MCP 工具统一包装成模型无关的 Tool。
先纠正三个常见误区
误区一:OpenAI 和 Anthropic 都在讲 MCP,所以接入方式应该差不多
不对。它们讲的经常不是同一层。
MCP 规范讲的是协议层:Host、Client、Server 怎么通过 JSON-RPC 和 transport 交互。模型厂商文档讲的更多是产品接入层:在我的 API、SDK、编码工具或平台里,开发者怎么把 MCP 能力接进去。
误区二:只要 API 支持 MCP,我就没必要自己管 MCP Client
不对。API 原生支持的通常是远程 HTTP MCP,或者平台托管的 Connector。只要你要接本地 stdio server、私有网络系统、内网数据库,MCP Client 还是得在你自己的 Agent 进程里。
误区三:只要后续模型兼容 OpenAI / Anthropic 格式,就不需要统一接入层
也不对。兼容格式只能降低 adapter 层的重复工作,不能替你解决工具命名、schema normalize、审批、审计、tool search 和本地 stdio 这类 Host 侧问题。
MCP 本身到底解决什么
MCP 要解决的问题其实很朴素:让 LLM 应用和外部工具之间有一套标准协议,而不是每个 Agent 都为每个系统单独写一层私有集成。
MCP 规范里最核心的三个运行时角色是:
Host:真正的 AI 应用本体,比如 Claude Code、Codex、IDE 助手,或者你自己写的 Agent。Client:Host 内部负责和某个 MCP Server 建立连接的组件。Server:暴露 Tools、Resources、Prompts 的程序。
Transport 层历史上经历过变化。旧版规范里常见的是 stdio 和 HTTP+SSE;2025-03-26 之后,标准化方向变成了 stdio 和 Streamable HTTP,后者用来替代旧的 HTTP+SSE 表述。
这意味着一件很重要的事:
MCP 只规定 Host、Client、Server 怎么说话,但它并不替你决定 MCP Client 到底是放在你的应用里,还是放在模型厂商的平台里。
OpenAI 和 Anthropic 的真实差异,就从这里开始。
OpenAI:一条是平台托管 MCP,一条是 SDK 自管 MCP
OpenAI 现在给了两条不同的路。
第一条路是 Responses API 里的 hosted MCP / Connectors。请求里可以直接把远程 MCP Server 写进 tools:
{
"model": "gpt-5.5",
"tools": [
{
"type": "mcp",
"server_label": "stripe",
"server_url": "https://mcp.stripe.com",
"authorization": "$STRIPE_OAUTH_ACCESS_TOKEN",
"require_approval": "never"
}
],
"input": "Create a payment link for $20"
}
如果不是自己维护的 MCP Server,也可以直接用 OpenAI 维护的 Connector,写法会变成 connector_id:
{
"model": "gpt-5.5",
"tools": [
{
"type": "mcp",
"server_label": "Dropbox",
"connector_id": "connector_dropbox",
"authorization": "<oauth access token>",
"require_approval": "never"
}
],
"input": "Summarize the Q2 earnings report."
}
这条路的特点是:MCP Client 由 OpenAI 平台代管。OpenAI 会先去远程 MCP Server 拉工具列表,响应里会出现 mcp_list_tools;模型真的调用工具时,输出里会出现 mcp_call;如果需要审批,还会出现 mcp_approval_request,你的应用再回一个 mcp_approval_response。
如果后端 MCP Server 在内网或防火墙后面,OpenAI 还给了 Secure MCP Tunnel,意思是你不用把私有 MCP Server 直接暴露到公网。
第二条路是 OpenAI Agents SDK。这个 SDK 既支持 HostedMCPTool,也支持本地自管的 MCPServerStdio 和 MCPServerStreamableHttp,还支持 tool filtering。
这条路的工程含义很明确:
- 只接远程公开 MCP 或官方 Connector,可以直接吃平台托管能力。
- 要接本地
stdio、私有工具链、企业内网系统,还是应该把 MCP Client 放在你自己的 Agent Host 里。
OpenAI 这套设计,本质上是“双轨制”:既支持平台代管,也允许你自己掌控运行时。
Anthropic:MCP connector 和 Tool Use 是两层东西,不要混看
Anthropic 的文档更容易让人看混,因为它同时有“普通工具调用”与“MCP connector”两种形态。
1. 普通 Tool Use
Anthropic 自定义工具的格式是:
{
"name": "search_docs",
"description": "Search documentation for a keyword and return matching snippets.",
"input_schema": {
"type": "object",
"properties": {
"query": { "type": "string" }
},
"required": ["query"]
}
}
这和 OpenAI 常见的函数工具格式已经不一样了。Anthropic 的重点字段是:
namedescriptioninput_schema
Claude 决定使用这种客户端工具时,响应会给你:
stop_reason: "tool_use"- 一个或多个
tool_useblock
然后由你的应用执行真实工具,再把 tool_result 发回去。
也就是说,在普通 Tool Use 这条路里,Anthropic 的边界非常清楚:
模型负责提出工具调用意图,执行发生在你的应用侧。
2. MCP connector
Anthropic 还提供了 MCP connector,让 Messages API 直接连远程 MCP Server。这个接口不是把 MCP 塞进 tools 数组,而是单独用一个顶层字段 mcp_servers:
{
"mcp_servers": [
{
"type": "url",
"url": "https://example-server.modelcontextprotocol.io/sse",
"name": "example-mcp",
"authorization_token": "YOUR_TOKEN",
"tool_configuration": {
"enabled": true,
"allowed_tools": ["example_tool_1", "example_tool_2"]
}
}
]
}
这就是 Anthropic 和 OpenAI 在“托管远程 MCP”这件事上的第一个显著格式差异:
- OpenAI:把远程 MCP 当成
tools数组里的一个type: "mcp"工具。 - Anthropic:把远程 MCP 当成独立的
mcp_servers配置块。
第二个更重要的差异在响应格式上。Anthropic 的 MCP connector 会返回两种新 block:
{
"type": "mcp_tool_use",
"id": "mcptoolu_014Q35RayjACSWkSj4X2yov1",
"name": "echo",
"server_name": "example-mcp",
"input": { "param1": "value1", "param2": "value2" }
}
和:
{
"type": "mcp_tool_result",
"tool_use_id": "mcptoolu_014Q35RayjACSWkSj4X2yov1",
"is_error": false,
"content": [
{
"type": "text",
"text": "Hello"
}
]
}
Anthropic 这条路同样是平台级托管远程 MCP Client,但它的请求和响应 shape 与普通 Tool Use 并不一样。当前版本还要求 beta header:anthropic-beta: "mcp-client-2025-11-20"。
所以你看 Anthropic 文档时,一定要把这两件事拆开:
tools + tool_use + tool_result:普通客户端工具机制。mcp_servers + mcp_tool_use + mcp_tool_result:远程 MCP connector 机制。
两者相关,但不是同一个抽象层。

OpenAI 和 Anthropic 到底差在哪
如果只抓工程上最关键的差异,我会把它们压缩成下面这张表。
| 维度 | OpenAI | Anthropic |
|---|---|---|
| 普通自定义工具定义 | 常见是 tools: [{ type: "function", function: { name, description, parameters, strict } }];Responses API 回填 function_call_output |
tools: [{ name, description, input_schema, strict }];回填 tool_result |
| 托管远程 MCP 的声明位置 | 放在 tools 里,type: "mcp" |
顶层 mcp_servers |
| 托管远程 MCP 的服务标识 | server_label + server_url 或 connector_id |
name + url + authorization_token |
| 工具白名单 | allowed_tools |
tool_configuration.allowed_tools |
| 审批机制 | require_approval,响应里可能出现 mcp_approval_request |
由 MCP connector 流程和结果 block 承接 |
| 平台托管 MCP 的响应痕迹 | mcp_list_tools、mcp_call、mcp_approval_request |
mcp_tool_use、mcp_tool_result |
本地 stdio MCP |
Responses API 不直接管;但 Agents SDK 支持 MCPServerStdio |
MCP connector 走远程 server;普通 Tool Use 则由你的应用自己执行 |
如果只用一句话总结:
OpenAI 更像“把 MCP 做成了一种内置工具类型”,Anthropic 更像“把 MCP 做成了一个并列的远程 server 配置机制”。
为什么把 OpenAI 和 Anthropic 讲清楚就够了
如果你后面还要接 GLM、DeepSeek 这类模型,反而更应该先把 OpenAI 和 Anthropic 两套主格式理顺。
原因很简单:
- 一类兼容 OpenAI 风格函数工具。
- 一类兼容 Anthropic 风格工具块。
- 你真正需要稳定的,还是 Host 自己的统一抽象。
换句话说,后续模型是落到 OpenAI-compatible adapter,还是落到 Anthropic-compatible adapter,不会改变 MCP 统一层应该由 Host 持有这件事。
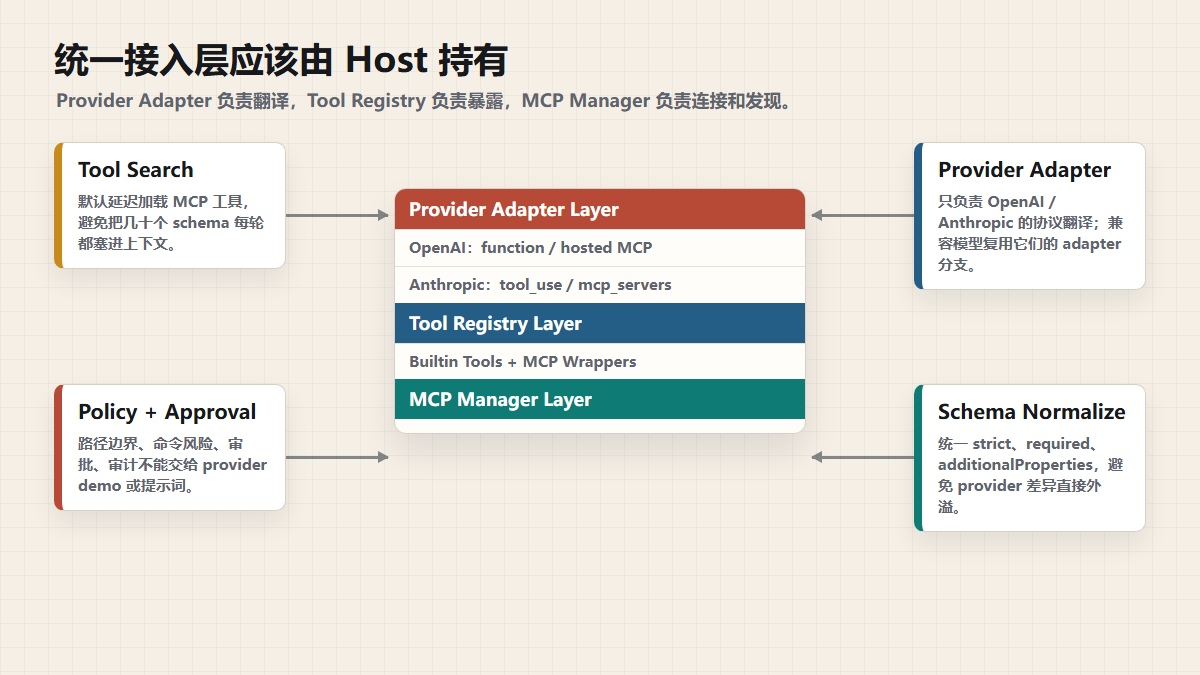
一套更稳的统一接入层,应该长什么样
到这里基本就能得出结论了:
如果你真要做多模型 Agent,最不应该做的事,就是把 MCP 直接写死在某一个 provider 的原生字段上。
User
│
▼
Agent Loop
│
├── Provider Adapter
│ ├── OpenAI formatter / parser
│ ├── Anthropic formatter / parser
│ └── Compatible formatter branches
│
├── Tool Registry
│ ├── Builtin Tools
│ └── MCP Tool Wrappers
│
├── Tool Search / Defer Loading
│
└── MCP Manager
├── stdio clients
├── Streamable HTTP clients
└── Remote server auth / approvals / retries
这套设计里,真正需要稳定的不是“某个 provider 的 MCP 格式”,而是你自己的内部抽象。
1. 先定义一层统一内部工具协议
无论工具来自内置工具、MCP server,还是别的 registry,先统一成一个内部结构:
type UnifiedTool = {
name: string;
description: string;
inputSchema: JsonSchema;
source: {
kind: "builtin" | "mcp";
serverName?: string;
originalToolName?: string;
};
risk: {
readOnly: boolean;
destructive: boolean;
requiresApproval: boolean;
};
visibility: {
deferred: boolean;
};
};
这层抽象一旦立住,后面的所有 provider 适配,都只是在做“格式转换”,而不是改业务逻辑。
2. MCP Manager 统一管理 transport、连接和工具发现
MCPManager 只干一件事:接管所有 MCP server 的生命周期。
它负责:
- 读取配置;
- 判断
stdio还是Streamable HTTP; - 执行
initialize; - 拉取
tools/list; - 缓存工具定义;
- 处理重连、超时、认证和错误隔离。
伪代码大概是这样:
async function registerMcpTools(configs, registry) {
for (const serverConfig of configs) {
const client = await createMcpClient(serverConfig);
await client.initialize();
const tools = await client.listTools();
for (const tool of tools) {
registry.register({
name: `mcp__${serverConfig.name}__${tool.name}`,
description: tool.description,
inputSchema: normalizeSchema(tool.inputSchema),
source: {
kind: "mcp",
serverName: serverConfig.name,
originalToolName: tool.name
},
risk: inferRisk(tool),
visibility: {
deferred: true
}
});
}
}
}
这里最重要的是三点:
- 工具名必须带 server 前缀,不然
search、query、create这种名字迟早撞。 - schema 要先归一化,别把 provider 不支持的 JSON Schema 特性原样往外传。
- 某个 MCP server 连接失败,只应该让这个 server 的工具不可用,不应该拖垮整个 Agent。
3. Tool Registry 只暴露模型当前该看到的工具
很多工具系统一开始就错在这里:每轮都把所有工具定义完整塞给模型。
这在 MCP 场景里会非常快地失控。一个 GitHub server、一个 Slack server、一个 Grafana server、一个内网平台 server,加起来就是几十上百个工具。
所以 Tool Registry 必须和 Tool Search / defer loading 配合:
- 高频内置工具常驻;
- MCP 工具默认延迟加载;
- 模型先看到 ToolSearch,再按名字或语义搜索需要的工具;
- 只有被选中的工具才展开完整 schema。
Anthropic 现在已经把 Tool Search 做成官方能力,OpenAI 也在 function calling 文档里明确建议函数很多时搭配 tool search。即使你最后自己在客户端实现 BM25 或 regex 版 ToolSearch,也比每轮全量暴露稳定得多。
4. Provider Adapter 只做“翻译”,不要做业务
不同模型的差异,应该被压缩在 provider adapter 里。
这一层只负责三件事:
interface ProviderAdapter {
formatTools(tools: UnifiedTool[]): unknown[];
parseToolCalls(response: unknown): UnifiedToolCall[];
appendToolResults(history: unknown[], results: UnifiedToolResult[]): unknown[];
}
比如:
- OpenAI Adapter:把内部工具转成
tools数组;普通函数工具回填function_call_output,托管远程 MCP 则按需构造成type: "mcp"。 - Anthropic Adapter:普通工具走
tools + tool_use + tool_result;如果你明确选择 Anthropic MCP connector 模式,再额外填充mcp_servers。 - 兼容模型:只要它落在 OpenAI-compatible 或 Anthropic-compatible 其中一类,就复用这两条 adapter 分支,不再单独发明一套工具协议。
最关键的一点是:
Adapter 只负责“翻译协议”,不要让它掺进工具执行、权限判断和业务逻辑。
5. Policy、Approval、Audit 放在 Host,不放在模型 prompt
一旦你开始接 MCP,权限边界就不能继续靠“提示词自觉”了。
至少要有这几层控制:
Policy Engine:路径越权、命令白名单、写操作风险分级。Approval Gate:高风险工具、外部敏感系统调用、数据出域审批。Result Adapter:大结果截断、敏感信息脱敏、错误结构化。Trace / Audit:记录哪个模型在什么时候调用了哪个工具,参数摘要是什么,结果如何。
OpenAI 托管 MCP 里有 require_approval 和 mcp_approval_request;Anthropic connector 也有自己的 server 配置和结果 block。但如果你要跨模型统一行为,这些控制最终还是应该落回 Host 自己的规则系统里。
什么时候该用厂商原生 MCP,什么时候一定要自己接
这件事其实可以用一个很实用的判断框架来决定。
可以直接用厂商原生 MCP 的情况
- 你只支持一家模型。
- 你接的是远程公开 MCP Server 或官方 Connector。
- 你希望尽量少写基础设施代码。
- 你接受执行链路的一部分运行在模型平台侧。
更应该自己接 MCP 的情况
- 你要同时支持 OpenAI、Anthropic,以及后续兼容其中某一套格式的模型。
- 你要接本地
stdioserver。 - 你要接企业内网数据库、GitLab、日志平台、私有服务。
- 你要自己统一审批、审计、缓存、工具搜索和降级策略。
- 你不想让工具系统随着 provider API 变化不断返工。
一句话说就是:
只要你不是“单模型 + 纯远程公有工具”的简单场景,Host 自己掌控 MCP Client 通常都更稳。
最容易做错的四件事
1. 把 MCP 直接绑死在 provider request shape 上
今天写 type: "mcp",明天写 mcp_servers,后天再补一套 OpenAI-compatible tools,最后整个工具层就碎了。
2. 不做 schema 归一化
不同 provider 对 strict mode、required、additionalProperties、JSON Schema 子集的要求并不完全一样。OpenAI 明确强调 strict mode 的 schema 约束,Anthropic 也单独提供 strict tool use。你不先做 schema normalize,后面一定会在边界 case 上爆炸。
3. 不做 Tool Search,默认全量暴露
少量工具时看不出来,一上 MCP server 数量就立刻出问题。token 成本、选择准确率和上下文污染都会一起上升。
4. 以为接入层只要“能调用”就算完成
真正费时间的从来不是“第一次调通”,而是后面的:
- 权限
- 超时
- 重试
- 审批
- 日志
- 结果裁剪
- 故障降级
这些都不在 provider 的 demo 代码里,但它们才是生产系统的一半。

最小落地方案
如果你现在就在做一个多模型 Agent,我建议直接按下面这个顺序上:
- 先把 MCP server 配置抽出来,只描述
transport、command/url、env/headers、allowed_tools。 - 建立
MCPManager,统一完成连接、发现、缓存、重连和错误隔离。 - 把 MCP 工具包装成内部统一命名,例如
mcp__github__search_issues。 - 建立
ToolRegistry,控制哪些工具常驻,哪些工具延迟加载。 - 为 OpenAI 和 Anthropic 各写一个薄的
ProviderAdapter;兼容模型直接挂到对应分支。 - 在 Host 侧落 Policy、Approval、Trace,不把这些规则寄托在模型 prompt 上。
- 先跑通 3 类工具:只读工具、写工具、高风险执行工具。
- 最后再决定哪些 provider 场景可以走原生托管 MCP,哪些必须走 Host 自己的 MCP Client。

总结
这篇文章如果只留一句结论,那就是:
OpenAI 和 Anthropic 的差别,不在于“谁有 MCP”,而在于谁把 MCP 做成了什么形态;而对一个真正要长期演进的 Agent 项目来说,最稳的办法永远是自己掌握这层 Host 能力。
所以,多模型 Agent 里最推荐的 MCP 架构不是“哪个厂商原生支持 MCP 就用哪个字段”,而是:
Agent 自己做 Host,自己管理 MCP Client,把 MCP 工具统一包装成内部 Tool,再由不同 ProviderAdapter 翻译给各家模型。
这才是最不容易被厂商 API 变化绑架的接入方式。
参考资料
- OpenAI API Docs:MCP and Connectors
https://developers.openai.com/api/docs/guides/tools-connectors-mcp - OpenAI Agents SDK:Model context protocol
https://openai.github.io/openai-agents-python/mcp/ - OpenAI API Docs:Function calling
https://developers.openai.com/api/docs/guides/function-calling - Anthropic Claude Docs:MCP connector
https://platform.claude.com/docs/en/agents-and-tools/mcp-connector - Anthropic Claude Docs:Tool use with Claude
https://platform.claude.com/docs/en/agents-and-tools/tool-use/overview - Anthropic Claude Docs:Define tools
https://platform.claude.com/docs/en/agents-and-tools/tool-use/define-tools - Anthropic Claude Docs:Tool search tool
https://platform.claude.com/docs/en/agents-and-tools/tool-use/tool-search-tool - Model Context Protocol:Specification
https://modelcontextprotocol.io/specification/2025-11-25 - Model Context Protocol:Transports
https://modelcontextprotocol.io/specification/2025-03-26/basic/transports

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐
 9
9 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)