用自然语言查数据库 — Langflow 低代码实战详解
标签: 智能体技术 · 低代码 AI
日期: 2026年6月 · 深度研究场景 · 阅读时间约 10 分钟
引言
想象一下:你的业务同事直接用中文问系统"上季度哪个区域的退货率最高?",系统自动查数据库,几秒后把漂亮的表格结果送到他面前。这不是科幻,这就是 Langflow 的自然语言 SQL 模板能做到的事。
一、Langflow 是什么?
Langflow 是一个开源的低代码 AI 工作流构建平台,GitHub 上已有超过 13.8 万颗星。它的核心思路很简单:把 AI 应用拆解成一个个功能节点,用可视化的方式把它们连起来,就像搭积木一样。
💡 低代码 ≠ 没有代码。 Langflow 让你用拖拽搭建 80% 的流程,剩下 20% 需要配置参数或写少量 Prompt。它面向的是既想快速落地、又不想深陷工程细节的开发者和产品人。
Langflow 主要服务两类场景:RAG(检索增强生成) 和 Agentic 应用(智能体应用)。今天要讲的这个"自然语言查数据库"模板,属于典型的 Agentic 场景——AI Agent 主动理解意图、调用工具、完成任务。
二、要解决什么问题?
数据库查询对非技术同学来说有一道很高的门槛:SQL。你需要知道表名、字段名、JOIN 的写法……即使是简单的统计,一个不熟悉 SQL 的人往往需要依赖数据团队排队等结果。
🎯 这个模板的目标:
让任何人都能用自然语言(中文或英文)直接查数据库,无需了解 SQL,无需技术背景,结果直接以表格形式返回。
解决思路其实不复杂,一共分三步:
步骤 1:让 AI 理解数据库结构(Schema)
把数据库的表结构作为"背景知识"注入给 AI Agent,让它知道有哪些表、哪些字段可以用。
步骤 2:把自然语言翻译成 SQL
AI Agent 根据用户问题和 Schema 知识,生成对应的 SQL 查询语句。
步骤 3:执行 SQL 并返回结果
把生成的 SQL 发给数据库执行,把查询结果格式化后展示给用户。
三、工作流全景图
整个 Flow 在 Langflow 画布里的逻辑,一共经过 5 个关键阶段,每个阶段对应画布上的一组节点,数据像流水一样从左流向右,最后把结果返还给用户。
工作流示意图
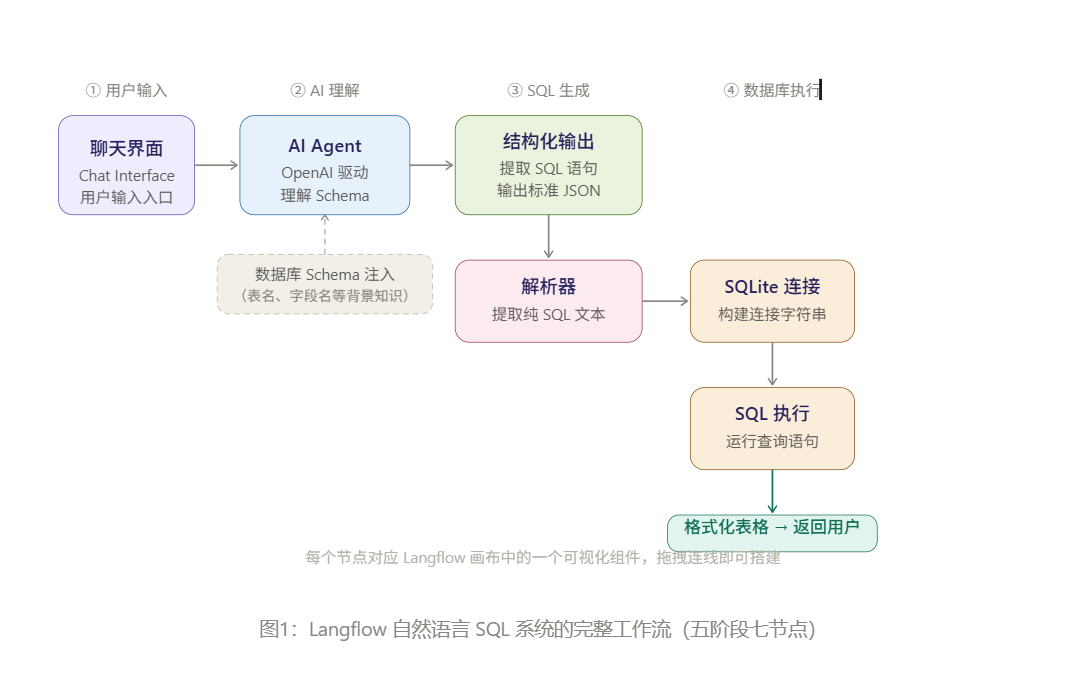
📌 流程图说明: 每个节点对应 Langflow 画布中的一个可视化组件,拖拽连线即可搭建。完整的交互式流程图请参考原文 HTML 版本。
各阶段说明:
| 阶段 | 节点 | 作用 |
|---|---|---|
| ① 输入 | Chat Interface | 用户输入自然语言问题的入口 |
| ② 理解 | AI Agent(OpenAI 驱动) | 读取问题 + Schema,推理出 SQL |
| ③ 生成 SQL | Structured Output | 从 Agent 输出中精准提取 SQL,输出标准 JSON |
| ③ 解析 | Parser | 从 JSON 里取出纯文本 SQL |
| ④ 执行 | SQLite Connection + SQL Component | 构建连接、运行查询 |
| ⑤ 输出 | Chat Output | 格式化表格展示给用户 |
实际langflow流程设计如下,这里直接连接pg数据库。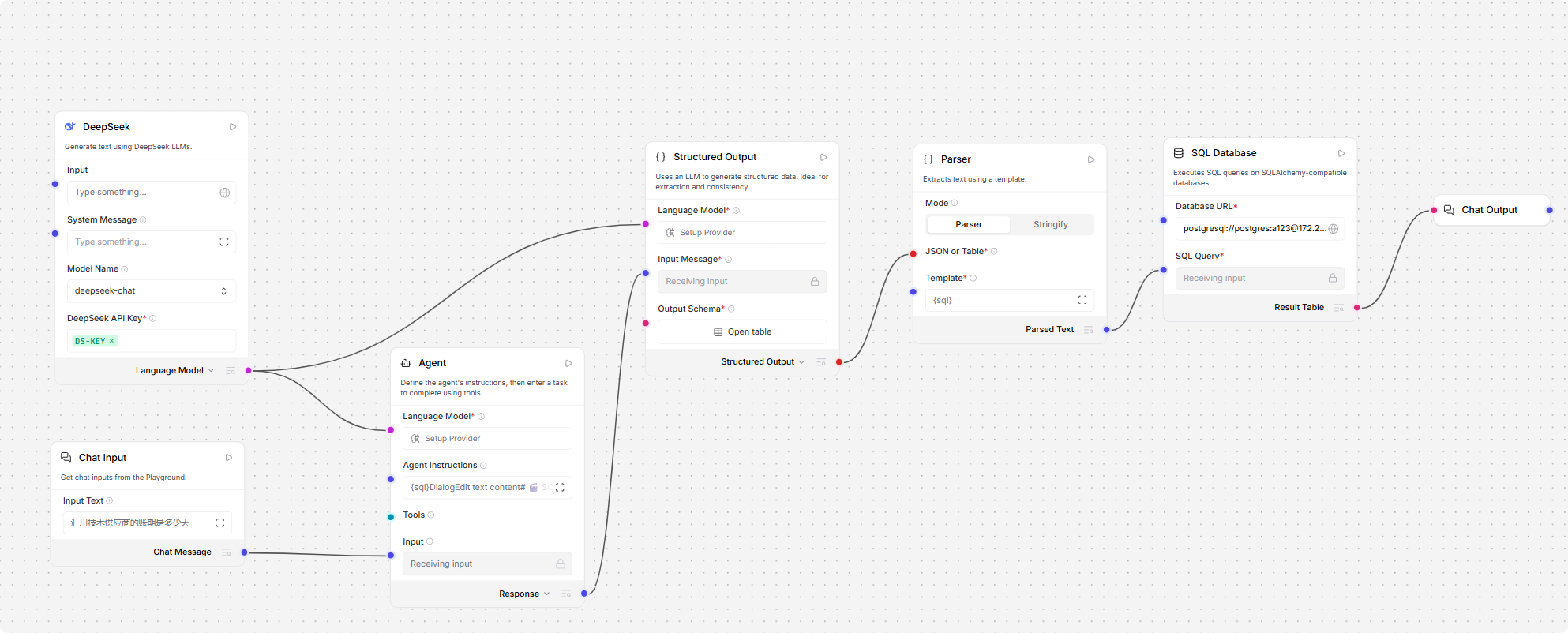
四、六大核心组件详解
下面逐一拆解每个组件的作用,用大白话说清楚它们在干什么:
1. 💬 聊天界面(Chat Interface)
用户输入问题的入口,就像一个普通聊天窗口。接收自然语言,把问题传给下游组件。
2. 🤖 AI Agent
整个流程的"大脑"。由 OpenAI 大模型驱动,读取用户问题,结合数据库 Schema,推理出合适的 SQL 语句。
3. 📐 结构化输出(Structured Output)
Agent 的输出往往是一大段文字,这个组件负责从中精准提取 SQL 语句,以标准 JSON 格式输出,避免格式混乱。
4. 🔧 解析器(Parser)
用模板模式从 JSON 里取出纯文本的 SQL 字符串,交给数据库去执行。
5. 🗄 SQLite 连接组件
根据你提供的数据库文件路径,自动构建连接字符串,让 SQL 执行组件知道去哪个数据库操作。
6. 📊 SQL 执行 + 输出
真正执行查询,把原始数据库结果整理成格式化表格,最终展示在聊天界面里。
⚠️ 关于结构化输出这一步为什么必要:
LLM 的输出本质上是自由文本,哪怕你要求它"只返回 SQL",它也可能在 SQL 前后加一段解释。Structured Output Component用另一个 LLM 专门做提取,相当于"二次校准",确保输出始终是格式一致的 JSON。
五、最关键的一步:把数据库结构告诉 AI
Agent 能生成正确 SQL 的前提,是它"知道"你的数据库长什么样。这通过在 Agent 的 System Prompt(系统提示词) 中注入 Schema 描述来实现。
举个例子,假设你有一张销售表,Prompt 里会这样描述:
你是一个 SQL 查询助手。以下是数据库的表结构,请根据用户问题生成准确的 SQLite 查询语句。
数据库 Schema:
表名: orders(订单表)
字段:
- order_id INTEGER 订单ID(主键)
- product_name TEXT 产品名称
- category TEXT 产品类别
- region TEXT 销售区域
- amount REAL 销售金额
- sale_date DATE 销售日期
- status TEXT 订单状态(completed / returned)
规则:
1. 只生成 SELECT 语句,不允许 INSERT/UPDATE/DELETE
2. 日期字段使用 strftime 函数处理
3. 如果问题模糊,选择最合理的解读
4. 只返回 SQL,不需要解释
有了这段 Schema 描述,当用户问"上个月各区域的退货率是多少",AI 就知道该用 orders 表、region 字段、status 字段来构建查询了。
💡 进阶做法: 对于表特别多的大型数据库,可以引入向量检索——把 Schema 存进向量数据库,每次查询时只取出相关的表描述,避免 Prompt 超长。这正是 Langflow 后续可扩展节点中"Vector Stores"的用武之地。
六、输出的 JSON 格式是什么样的?
经过"结构化输出组件"处理后,中间数据以固定 JSON 格式传递,这让系统更健壮,不会因为 AI 回答格式变化而出错:
{
"question": "上个月各区域的退货率是多少?",
"sql": "SELECT region, ROUND(SUM(CASE WHEN status='returned' THEN 1.0 ELSE 0 END) / COUNT(*) * 100, 2) AS return_rate FROM orders WHERE strftime('%Y-%m', sale_date) = strftime('%Y-%m', 'now', '-1 month') GROUP BY region ORDER BY return_rate DESC;"
}
解析器组件拿到这个 JSON 后,只取出 sql 字段的值,把它发给 SQLite 执行——干净、可靠、可预测。
七、这个方案适合哪些场景?
| 场景 | 分类 | 典型问法 |
|---|---|---|
| 业务自助分析 | 数据分析 | “上季度哪个产品线利润最高?” |
| 客服与运营 | 运营支持 | “张三负责的工单里,未解决的有多少?” |
| 财务与销售 | 财务分析 | “本月应收账款超过 30 天的客户有哪些?” |
| 教学与学习 | 教育场景 | “帮我查一下每个学生的平均分”(用于学 SQL) |
| 数据工程调试 | 工程工具 | “users 表里有多少条记录是过去 7 天新增的?” |
八、动手试试:快速上手步骤
步骤 1:访问 Langflow,选择模板
打开 langflow.org,在模板库中找到"Natural Language SQL Query"模板,点击 Use 导入到你的工作区。
步骤 2:配置 OpenAI API Key
在 AI Agent 节点和 Structured Output 节点中,填入你的 OpenAI API Key(或替换为其他支持的模型)。
步骤 3:修改 Schema Prompt
打开 AI Agent 节点的 System Prompt,把示例 Schema 替换成你自己数据库的表结构描述。这一步最关键,描述越清楚,生成的 SQL 越准确。
步骤 4:配置数据库路径
在 SQLite Connection 节点中,填写你的 .db 文件路径。如果用的是 PostgreSQL 或 MySQL,可以替换对应的连接组件。
步骤 5:测试与迭代
在聊天界面输入一个问题,观察每个节点的输出,验证 SQL 是否正确。如有偏差,调整 Schema 描述或 Prompt 规则。
步骤 6:部署上线
通过 Langflow 内置的 API Endpoint 功能一键发布,业务系统可以通过 REST API 或 Webhook 调用这个 Flow。
九、要注意的局限性
⚠️ SQL 注入风险:
AI 生成的 SQL 语句需要做安全校验。建议在 SQL 执行节点前加一个过滤层,只允许SELECT语句通过,禁止任何写入或删除操作。
ℹ️ Schema 复杂度有限制:
当数据库有几十张表时,一次性把所有 Schema 塞进 Prompt 会超出模型的上下文窗口。此时需要配合向量检索,动态选取相关表的 Schema。
ℹ️ 复杂逻辑准确率有波动:
对于简单查询(过滤、排序、聚合),准确率很高。对于多表 JOIN、复杂窗口函数等,建议多测试,必要时在 Prompt 里给出示例 SQL(Few-Shot)。
十、还能怎么扩展?
这个 Flow 只是一个起点,Langflow 的节点库可以让它做更多事情:
- 接入向量数据库:存储 Schema 文档,支持超大数据库的语义检索
- 执行前检查结果:利用count(*)嵌套,预查询结果集大小,避免结果太多造成内存
- 加入 DataFrame 后处理:对查询结果做二次计算、可视化
- 推送到外部系统:通过 API Request 节点,把查询结果自动发送到钉钉、邮件或 BI 系统
- 替换更强的模型:换用 Claude 或本地部署的 Qwen,提升复杂查询的准确率
- 增加对话历史:让用户可以追问"那上上月呢",保持上下文连贯
总结
Langflow 的"自然语言转 SQL"模板,本质上是一个精心设计的 AI Agent 管道:用自然语言作为输入,用 Schema Prompt 作为知识底座,用结构化输出保证数据流的可靠性,最终把 AI 的语言理解能力和数据库的查询能力打通。
它的意义不只是"让不懂 SQL 的人也能查数据库",更在于它展示了一种通用的 AI 落地模式:
把领域知识注入 Prompt → AI 推理 → 结构化输出 → 调用外部系统 → 结果返回用户
这个模式可以复用到几乎所有"自然语言操控结构化系统"的场景里。
🚀 动手是最好的学习方式。 Langflow 完全开源,把模板导入进去,改一改 Schema Prompt,对着自己的数据库问一个问题,整个机制就会瞬间变得清晰。
深耕 AI Agent、低代码工作流与大模型应用落地,致力于让复杂技术浅显易懂。

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐

 10
10 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)