阿里国际agent开发岗,我跪了!!!
刚面完阿里国际的agent开发岗,趁热把面试题记下来。说实话,面完那一刻我有点懵——不是题难,是那种“你会但差一点点”的遗憾感,最难受。
下面是我还记得的问题,有些答得好,有些答得不好,都写出来给大家参考。
一、LangChain和LangGraph到底有啥区别?
面试官问的第一个技术问题就是这个。
我说,LangChain像是一个工具箱,里面有各种链、各种工具、各种模板,帮你快速搭一个单Agent应用。你写代码的时候,思路是线性的:用户输入 → 调一个工具 → 调LLM → 输出。
LangGraph不一样。它是在LangChain基础上做的图结构编排框架。你的任务可以分叉、可以循环、可以有条件跳转。比如一个场景:先让AgentA规划,然后AgentB执行,执行完让AgentC检查,检查不通过就回到AgentA重新规划。这种逻辑在LangChain里写起来特别别扭,但在LangGraph里就是加一条边的事。
面试官追问了一句:“那你觉得哪个更好?”
我说没有更好,看场景。简单任务用LangChain够用,复杂协作必须上LangGraph。面试官点了点头,没继续追问。
二、LangGraph踩过什么坑?
这个问题我回答得不太好,因为项目里踩的坑太多,一时不知道说哪个。
我选了最疼的一个:状态管理。
LangGraph里每个节点都能读写一个共享的state对象,但不同节点是并发执行的。有一次我发现,两个节点同时修改state里同一个字段,后执行的直接把先执行的覆盖了,完全没有警告。
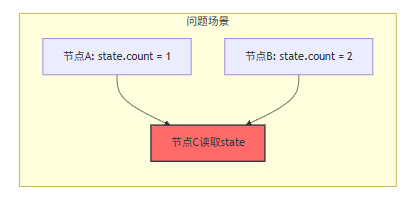
解决方式是在节点里做“合并写”,不要直接覆盖,而是判断一下这个字段是不是已经被别的节点改过了。
面试官听完说:“这是LangGraph的已知问题,你能自己发现并解决说明真的用过。”
三、RAG原理和Embedding模型怎么选的?
先说原理。
RAG就是先搜后读。用户问一个问题,先去知识库里找相关的段落,然后把问题和这些段落一起丢给大模型,让它照着搜到的信息回答。

Embedding模型。
我项目里用的是text-embedding-3-small,主要原因是便宜且够用。但我也对比过两个方案:
| 方案 | 优点 | 缺点 |
|---|---|---|
| text-embedding-3-small | 成本低、速度快 | 中文语义理解一般 |
| BAAI/bge-large-zh | 中文效果好 | 需要自己部署,延迟高 |
| 混合检索(Embedding+BM25) | 召回最稳 | 实现复杂,两套系统 |
最后选了small,因为项目对成本敏感,而且业务场景对召回率要求没那么极端。
面试官追问:“你说embedding模型对比过,具体怎么对比的?”
我说做了一个小测试集,人工标注了50个问题和对应的正确答案段落,然后算每种方案的Hit Rate(召回率)。small是82%,bge是89%,差7个百分点,但small的API调用成本是bge自部署的1/10,所以选了small。
四、上下文压缩怎么做?各有什么优劣?
这是RAG里的经典问题。检索回来的段落可能很长,直接塞进prompt会超过token限制,所以需要压缩。
我试过三种方式:
方式一:截断
直接取每段的前500个字。简单粗暴,但可能丢掉后面的关键信息。
方式二:重排序+截断
先让一个轻量模型给每个段落打分,把分数高的放前面,然后截断。这样至少保证重要的内容在前面,不会被切掉。
方式三:LLM摘要压缩
把每个段落单独丢给小模型生成一句话摘要,然后把这些摘要拼起来。优点是信息密度高,缺点是会丢失细节,而且多一次LLM调用增加延迟。
面试官问:“你觉得哪种最好?”
我说看业务。客服场景用户问“怎么退货”,细节很重要,截断可能把“需要订单号”这条信息切掉,所以我用重排序+截断。如果是做新闻摘要,用LLM压缩效果更好。
五、Fallback怎么做的?
大模型调用不可能100%成功,所以必须有降级方案。
我设计的fallback分三层:
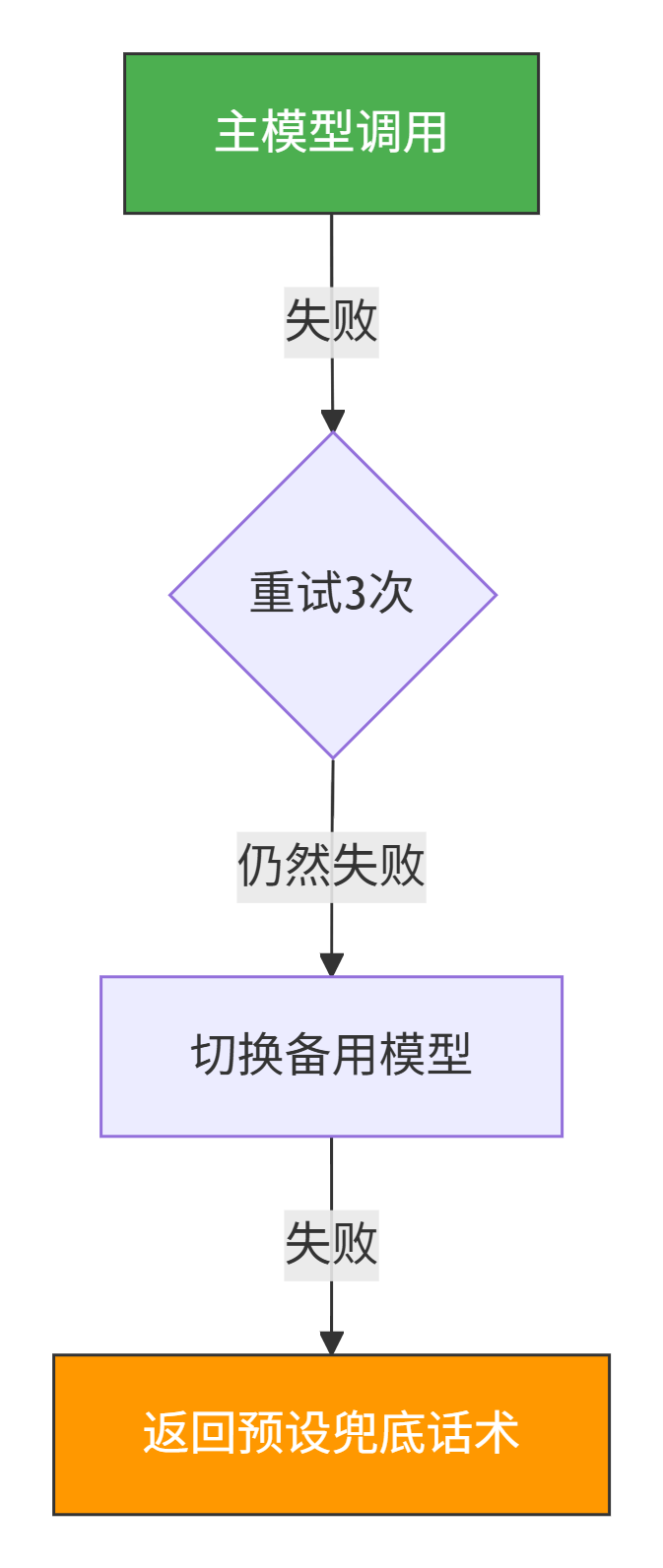
第一层,重试。网络抖动导致的失败,重试一次就能好。
第二层,换模型。主模型用的是GPT-4,如果一直超时,就切到Claude或者本地部署的Qwen。虽然效果差一点,但至少能返回结果。
第三层,兜底话术。如果所有模型都挂了,返回“系统繁忙,请稍后再试”。这个话术虽然没用,但比报错好。
面试官追问:“你怎么判断‘失败’?超时还是返回空?”
我说两个都算。超时阈值设的30秒,超过就算失败。返回空或者返回“我不确定”这种无效回答也算失败,会触发fallback。
六、AgentState的作用是什么?为什么不用全局变量?
这个问题我在LangGraph踩坑那部分已经提过,面试官专门拎出来细问了。
AgentState是一个贯穿整个graph的共享对象,每个节点都能读和写。
# 伪代码示例class AgentState(TypedDict): messages: List[BaseMessage] current_step: str intermediate_results: dict
为什么不用全局变量?
三个原因:
第一,全局变量在多线程环境下不安全。LangGraph的节点可能是并发执行的,两个节点同时修改同一个全局变量,结果不可预测。
第二,全局变量没法回溯。你改完就改完了,没有历史记录。但AgentState每次更新都可以保存快照,方便调试和重放。
第三,全局变量不支持图结构特有的“条件恢复”。比如你的图执行到一半挂了,从上一个checkpoint恢复时,全局变量的状态已经丢了,但AgentState可以从序列化的快照里原样恢复。
面试官听完说了句“不错”,没有继续追问。
七、整体的失败重试机制怎么设计的?
这个问题范围比较大,我把三个层面的重试都说了一遍。
Node层
每个节点执行失败,会重试3次,间隔2秒、4秒、8秒递增。3次都失败就标记这个节点为“失败”,整个graph暂停,发告警。
RAG链层
检索失败(比如向量数据库超时),会降级到关键词检索(BM25)。BM25也失败的话,返回空召回集,让模型用自身知识回答。
Tool层
工具调用失败,比如调天气API返回500,会重试2次。还失败就返回“工具暂时不可用”,并且把这个信息写回给LLM,让LLM告诉用户“查不了天气”。

面试官问:“你有没有考虑过部分失败的情况?比如RAG召回了3段,其中1段对应的文档源挂了?”
我说这个场景没考虑到,真要处理的话可以给每段召回加一个“可用性”标记,不可用的段落直接丢掉,不参与后续生成。面试官说这是个好方向,可以想想。
八、Transformer原理和多头注意力
这部分问得比较基础,但也细。
Transformer,简单说就是“Attention is all you need”那篇论文提出的架构。它不依赖RNN的循环结构,全靠注意力机制捕捉序列中不同位置的关系。
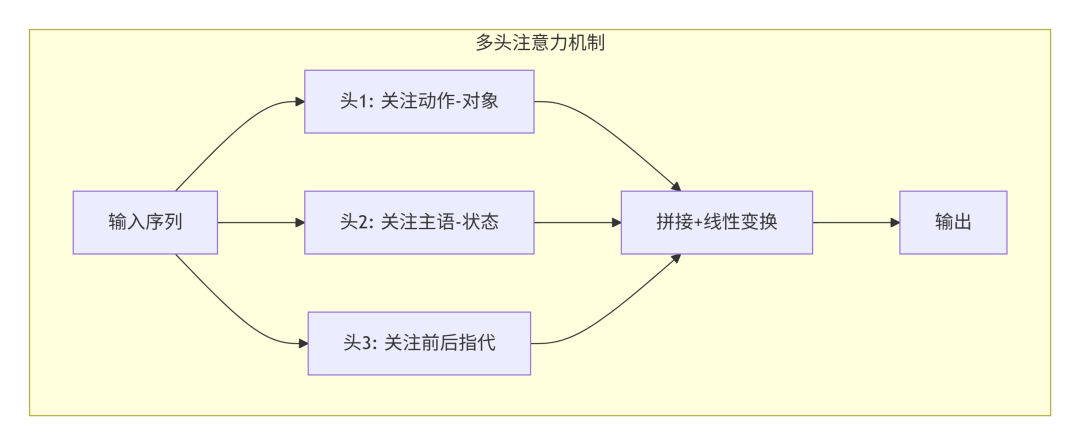
多头注意力,可以理解为让模型从多个角度观察同一段文本。
举个例子。“他打篮球打得好,但他受伤了”这句话里的两个“他”,指向同一个人。一个注意力头可能关注“篮球”和“打”的关系,另一个头关注“受伤”和“他”的关系。多个头并行计算,最后把结果拼在一起。
面试官没再追问,应该是觉得基础过关了。
九、实习IM项目的实现
一个即时通讯系统的后端,支持单聊、群聊、已读回执、离线消息。
我负责的是消息可靠性保证,核心是两件事:消息不丢、消息不重。
消息不丢靠“先存后发”。用户发消息,服务器先写进数据库,状态标记为“发送中”,然后再推给接收方。接收方收到后回一个ack,服务器再把状态改成“已送达”。
消息不重靠客户端生成的唯一消息ID,服务端用这个ID去重。同一个ID的消息如果收到两次,第二次直接忽略。
面试官问:“群聊的已读回执怎么做的?1000人的群,每人读一下你都要存吗?”
我说存,但是存的是“最后已读位置”。每个用户只记录自己读到了哪条消息,而不是记录每条消息的已读状态。这样已读回执的存储量从O(M×N)降到了O(N)。
十、实习Agent客服项目的RAG与回答生成
这个项目是把RAG用在了电商客服场景。
RAG实现:
知识库是商品FAQ、退货政策、优惠券规则这些文档。用户问“这个手机能7天无理由退货吗”,先检索“7天无理由+退货条件”相关的文档段落,然后把这些段落拼进prompt,让大模型生成回答。
回答生成:
不只是把检索结果直接贴给用户。检索回来的可能是“7天无理由退货适用于未激活的商品”,但用户问的“这个手机”是不是已经激活了?需要从对话历史里找。
所以生成阶段有两步:
- 判断用户问题里是否缺少关键信息(比如是否激活)
- 如果缺少,反问用户,而不是瞎回答
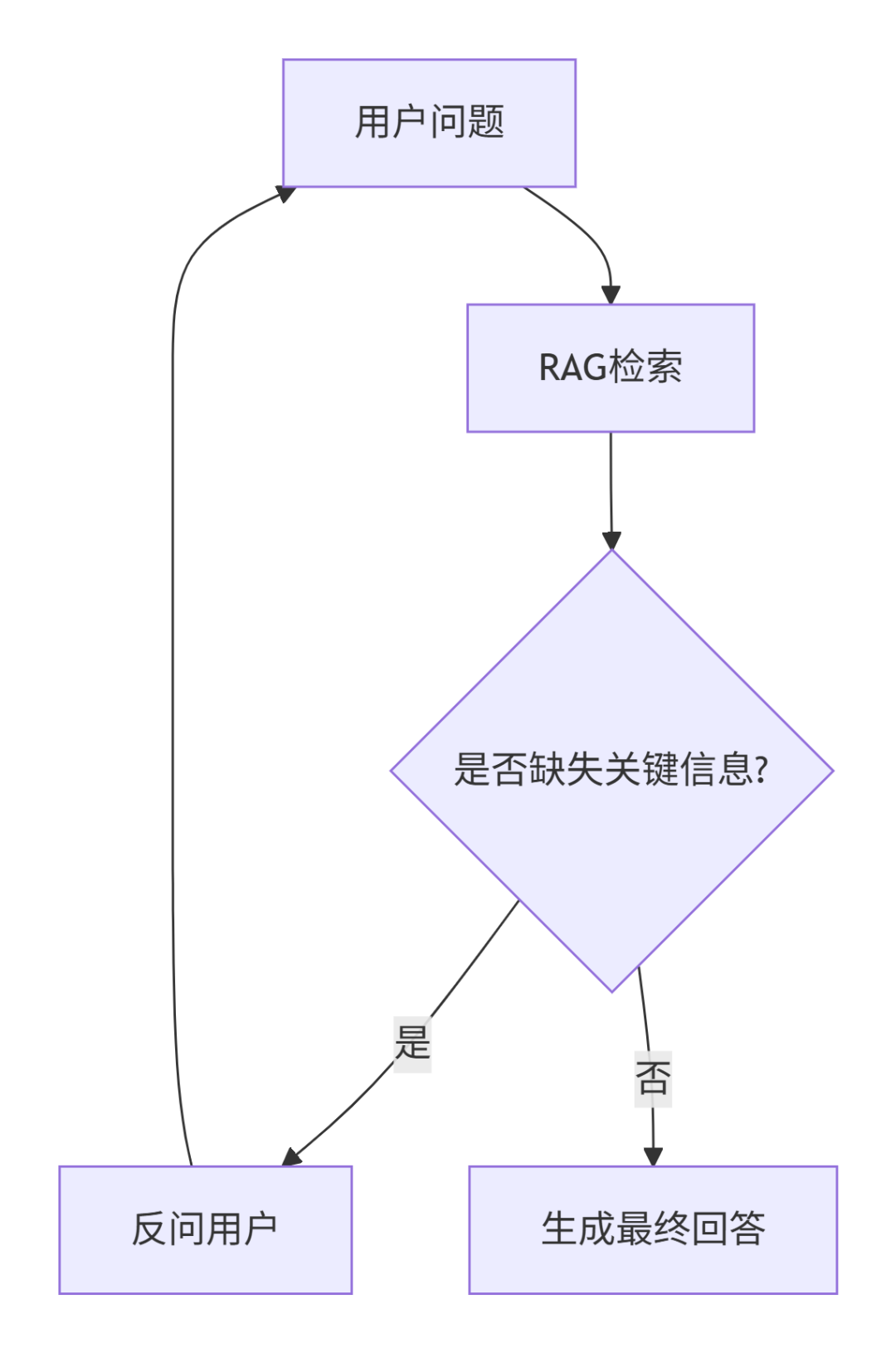
面试官问:“你怎么判断‘是否缺失关键信息’?”
我用了最笨但有效的办法:写规则。把每个业务场景的必需字段列出来,比如退货场景必须有“订单号+商品状态”,缺一个就触发反问。当然这个方案不够智能,但电商场景业务清晰,规则够用。
十一、魔改LangGraph项目的记忆系统设计
这是我个人项目里最花时间的一块。
LangGraph原生支持短期记忆(通过AgentState传messages),但长期记忆需要自己搞。
我设计的记忆系统分三层:
工作记忆:当前会话的所有对话,存在内存里,会话结束就清空。
情景记忆:用户的历史行为,比如“上次问过空调怎么清洗”、“之前点过外卖到某个地址”。存在向量数据库里,按用户ID分桶。
语义记忆:从情景记忆里总结出来的抽象知识,比如“用户偏好便宜的商品”、“用户不喜欢等太久”。这个是定期用LLM从情景记忆里抽取的。
记忆的写入时机不是每轮都写,而是当LLM判断“这条信息未来可能有用”时才写。判断逻辑是用一个轻量模型打分,超过阈值才存储。
面试官追问:“你怎么解决记忆过时的问题?”
我说加了一个衰减机制。每条记忆有个权重,每次会话如果没用到它,权重就衰减一点。权重低于阈值就删掉。比如用户半年前说“喜欢黑色”,但最近三个月都在买白色,那条“喜欢黑色”的记忆就会被淘汰。
最后的手撕代码
二叉树蛇形遍历,leetcode第103题。
两分钟写出来了,核心逻辑就是层序遍历+翻转奇数层。但面试官让我自己构造一棵二叉树来跑测试,我脑子短路了——怎么new节点、怎么挂左右子树,居然卡住了。
# 我能写出来的是这个def zigzagLevelOrder(root): if not root: return [] res = [] queue = [root] left_to_right = True while queue: level_size = len(queue) level = [] for _ in range(level_size): node = queue.pop(0) level.append(node.val) if node.left: queue.append(node.left) if node.right: queue.append(node.right) if not left_to_right: level.reverse() res.append(level) left_to_right = not left_to_right return res# 但构造二叉树我写不出来 😭
面试官说“没事,算法思路是对的”,但我感觉这里扣分了。
出来复盘才发现,构造二叉树不就是递归吗:
def build_tree_from_list(arr, i): if i >= len(arr) or arr[i] is None: return None root = TreeNode(arr[i]) root.left = build_tree_from_list(arr, 2*i+1) root.right = build_tree_from_list(arr, 2*i+2) return root
可惜面试的时候就是没想到。
0 AI行业迎来前所未有的爆发式增长:从DeepSeek百万年薪招聘AI研究员,到百度、阿里、腾讯等大厂疯狂布局AI Agent,再到国家政策大力扶持数字经济和AI人才培养,所有信号都在告诉我们:AI的黄金十年,真的来了!
在行业火爆之下,AI人才争夺战也日趋白热化,其就业前景一片蓝海!
我给大家准备了一份全套的《AI大模型零基础入门+进阶学习资源包》,包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。😝有需要的小伙伴,可以VX扫描下方二维码免费领取🆓

人才缺口巨大
人力资源社会保障部有关报告显示,据测算,当前,****我国人工智能人才缺口超过500万,****供求比例达1∶10。脉脉最新数据也显示:AI新发岗位量较去年初暴增29倍,超1000家AI企业释放7.2万+岗位……
单拿今年的秋招来说,各互联网大厂释放出来的招聘信息中,我们就能感受到AI浪潮,比如百度90%的技术岗都与AI相关!
就业薪资超高
在旺盛的市场需求下,AI岗位不仅招聘量大,薪资待遇更是“一骑绝尘”。企业为抢AI核心人才,薪资给的非常慷慨,过去一年,懂AI的人才普遍涨薪40%+!
脉脉高聘发布的《2025年度人才迁徙报告》显示,在2025年1月-10月的高薪岗位Top20排行中,AI相关岗位占了绝大多数,并且平均薪资月薪都超过6w!
在去年的秋招中,小红书给算法相关岗位的薪资为50k起,字节开出228万元的超高年薪,据《2025年秋季校园招聘白皮书》,AI算法类平均年薪达36.9万,遥遥领先其他行业!

总结来说,当前人工智能岗位需求多,薪资高,前景好。在职场里,选对赛道就能赢在起跑线。抓住AI风口,轻松实现高薪就业!
但现实却是,仍有很多同学不知道如何抓住AI机遇,会遇到很多就业难题,比如:
❌ 技术过时:只会CRUD的开发者,在AI浪潮中沦为“职场裸奔者”;
❌ 薪资停滞:初级岗位内卷到白菜价,传统开发3年经验薪资涨幅不足15%;
❌ 转型无门:想学AI却找不到系统路径,83%自学党中途放弃。
他们的就业难题解决问题的关键在于:不仅要选对赛道,更要跟对老师!
我给大家准备了一份全套的《AI大模型零基础入门+进阶学习资源包》,包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。😝有需要的小伙伴,可以VX扫描下方二维码免费领取🆓


Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐

 3
3 0
0- 0



 已为社区贡献70条内容
已为社区贡献70条内容

所有评论(0)