国产时序数据库实战盘点:告别盲目堆性能
前言
2026年工业物联网、工控监控、电网调度、智慧港口、船舶管理国产化替换进入落地深水区。很多架构师在选型时序数据库时,存在典型误区:只盯着写入吞吐峰值做判断,忽略时序采集数据与现有业务库打通、运维、数据一致性带来的隐性成本。
当前国产时序数据库分化为两条完全不同的技术路线:
- 专用时序引擎:TDengine、Apache IoTDB、DolphinDB、openGemini等,专门针对海量测点写入做底层优化,单表写入性能拉满,但天然割裂关系业务数据,跨库查询必须引入同步中间件;
- 关系内核多模时序插件:以中电科金仓KingbaseES(KES)时序扩展为代表,在成熟关系型数据库内核中内嵌时序存储逻辑,同一套数据库实例同时承载业务关系数据、时序采集数据、GIS空间数据,原生支持标准SQL、完整ACID事务,复用原有整套运维体系。
本文不堆砌空洞概念,先盘点2026主流国产时序库落地优缺点,再提供全套可直接上线运行的实操SQL,覆盖建表、批量写入、混合关联查询、降采样、GIS时序联动、事务验证,附带TSBS性能压测脚本、真实行业落地案例,最后给出可直接落地的选型判断标准。
一、2026主流国产时序数据库落地实战对比
抛开厂商宣传,从开发、运维、复杂业务场景三个维度整理线上项目真实使用表现:
| 数据库产品 | 核心优势 | 生产环境短板 | 适配场景 |
|---|---|---|---|
| TDengine | 单机写入吞吐高、存储压缩率优秀、集群运维轻量化、开源生态完善 | 多表JOIN性能差,不支持完整ACID事务,时序与业务数据联动依赖数据同步服务 | 机房服务器监控、纯设备测点采集、无复杂业务关联场景 |
| Apache IoTDB | 端-边-云原生架构,树形设备模型适配工业分层设备采集,边缘侧轻量化部署 | 自定义SQL语法,传统DBA学习成本高,无法直接关联存量业务表 | 工业现场边缘网关采集、分层工控设备数据上报 |
| DolphinDB | 时序+流计算一体化,内置向量化引擎,海量历史时序批量分析速度突出 | 通用关系数据库能力薄弱,无法承载企业核心业务,生态封闭 | 金融高频量化、纯时序离线回溯分析 |
| openGemini/CnosDB | 云原生弹性扩缩容,兼容InfluxQL,容器监控、云主机监控开箱即用 | 事务支持残缺,电力、政务等强一致性关键业务无法落地 | 云平台容器、微服务监控告警 |
| 金仓KES时序引擎 | PostgreSQL兼容内核,标准SQL语法,时序/关系/GIS三模统一存储,完整ACID,复用KES高可用、权限、备份工具链 | 纯无关联海量测点场景下,单机裸写入峰值略低于专用时序库 | 智能电网调度、智慧船舶、智能制造、国产化全栈替代、时序业务混合分析场景 |
其余细分产品如紫金桥RealHistorian、YMatrix、GreptimeDB等,仅在垂直工控、云监控小范围场景有优势,通用性不足。
两条路线核心矛盾:专用时序库牺牲关系能力换写入性能;金仓时序引擎牺牲部分裸写峰值,换取数据一体化、低运维成本、强事务保障,更适配政企、能源、制造等复杂国产化项目。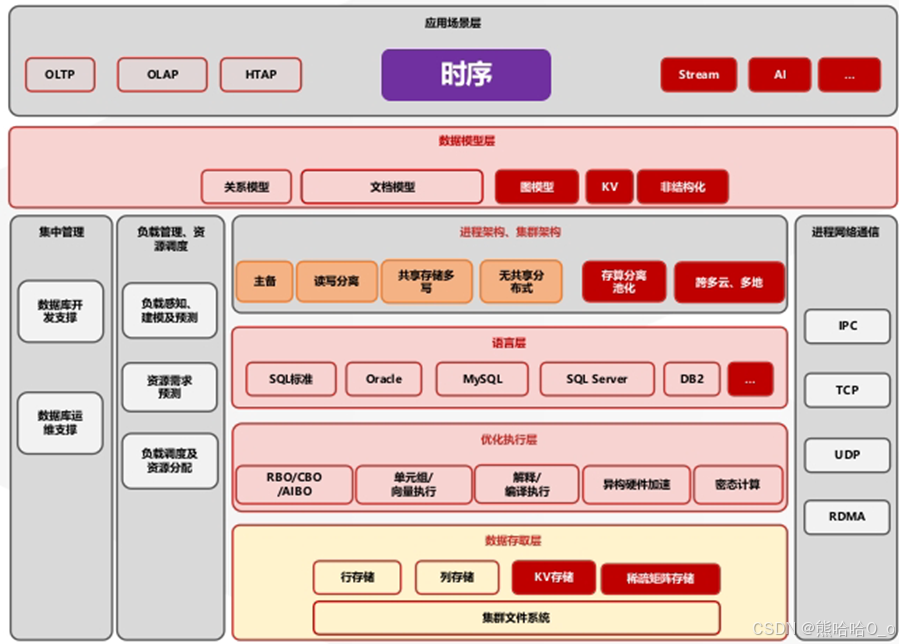
二、金仓KES时序引擎全流程实操代码
金仓时序能力为内置扩展插件kingbase_timeseries,已安装KingbaseES V8/V9环境无需额外部署独立时序服务,所有SQL可直接在ksql、DBeaver客户端执行。
2.1 启用时序扩展插件
-- 查询当前已加载插件
SELECT extname,extversion FROM pg_extension;
-- 加载官方时序扩展
CREATE EXTENSION IF NOT EXISTS kingbase_timeseries;
-- 校验时序引擎版本,验证插件生效
SELECT ts_version();
2.2 业务模型模拟:智能制造设备监控
模拟真实业务双表结构:
- 普通关系表:device_info,存储设备静态台账、班组、维保人员等业务数据;
- 时序分区表:device_metric,存储秒级采集温度、振动、电流时序数据;
两张表同实例、同库,无需同步组件,直接JOIN分析。
1)创建业务关系表(设备台账)
CREATE TABLE device_info (
device_id VARCHAR(32) PRIMARY KEY,
device_name VARCHAR(64) NOT NULL,
workshop VARCHAR(32),
maintainer VARCHAR(32),
install_date TIMESTAMP
);
-- 插入基础业务数据
INSERT INTO device_info VALUES
('DEV001','冲压机A','一号车间','张工','2026-01-10'),
('DEV002','数控切割机B','一号车间','李工','2026-02-05'),
('DEV003','冷却机组C','二号车间','王工','2026-03-12');
2)创建自动分区时序指标表
支持按天自动分区,内置时序存储优化,创建时序复合索引加速时间范围查询:
CREATE TABLE device_metric (
ts TIMESTAMP NOT NULL,
device_id VARCHAR(32) NOT NULL,
temp FLOAT,
vibration FLOAT,
electric_current FLOAT
) USING timeseries
PARTITION BY RANGE (ts) (
START '2026-06-01' END '2026-07-01' EVERY INTERVAL '1 day'
);
-- 时序专用联合索引
CREATE INDEX idx_ts_dev ON device_metric (ts, device_id);
2.3 时序数据批量写入
-- 批量插入秒级采集时序数据
INSERT INTO device_metric VALUES
('2026-06-18 10:00:01','DEV001',52.3,2.1,16.8),
('2026-06-18 10:00:02','DEV001',52.5,2.2,16.9),
('2026-06-18 10:00:03','DEV001',53.1,2.5,17.2),
('2026-06-18 10:00:01','DEV002',48.2,1.8,15.3),
('2026-06-18 10:00:02','DEV002',48.5,1.9,15.4),
('2026-06-18 10:00:03','DEV002',48.8,2.0,15.6);
2.4 核心能力:时序表与业务表关联聚合查询
该场景是专用时序库的短板,TDengine、IoTDB需要同步设备台账数据才能实现关联,金仓原生标准SQL直接JOIN:
需求:查询一号车间近3分钟所有设备平均温度、最大振动值,同时带出设备名称、维保负责人
SELECT
d.device_id,
d.device_name,
d.maintainer,
ROUND(AVG(m.temp),2) AS avg_temperature,
MAX(m.vibration) AS max_vib
FROM device_metric m
LEFT JOIN device_info d ON m.device_id = d.device_id
WHERE m.ts >= NOW() - INTERVAL '3 minutes'
AND d.workshop = '一号车间'
GROUP BY d.device_id, d.device_name, d.maintainer;
2.5 时序降采样窗口分析
针对海量秒级原始数据,使用time_bucket按固定时间窗口聚合,减少查询返回数据量,优化大屏、报表性能:
-- 按10秒窗口聚合,统计单台设备温度均值、电流峰值
SELECT
time_bucket(INTERVAL '10 second', ts) AS window_time,
device_id,
ROUND(AVG(temp),2) AS avg_temp,
MAX(electric_current) AS max_current
FROM device_metric
GROUP BY window_time, device_id
ORDER BY window_time ASC;
2.6 特色能力:时序+GIS空间混合查询(船舶轨迹场景)
国产时序库中仅金仓原生集成GIS与时序存储,无需对接第三方空间引擎,适用于船舶GPS、车辆轨迹监控:
-- 创建船舶GPS轨迹时序表,内置Point空间字段
CREATE TABLE ship_gps_track (
ts TIMESTAMP NOT NULL,
ship_code VARCHAR(32),
location GEOMETRY(Point),
speed FLOAT
) USING timeseries
PARTITION BY RANGE (ts) (START '2026-06-01' END '2026-07-01' EVERY INTERVAL '1 day');
-- 插入船舶时序定位数据
INSERT INTO ship_gps_track VALUES
('2026-06-18 10:00:01','SHIP001',ST_GeomFromText('POINT(119.3 26.1)'),12.5),
('2026-06-18 10:00:05','SHIP001',ST_GeomFromText('POINT(119.31 26.11)'),12.8),
('2026-06-18 10:00:01','SHIP002',ST_GeomFromText('POINT(119.35 26.15)'),10.2);
-- 联合查询:近1小时指定海域范围内所有船舶轨迹
SELECT
ship_code,
ts,
ST_AsText(location) AS gps_coordinate,
speed
FROM ship_gps_track
WHERE ts >= NOW() - INTERVAL '1 hour'
AND ST_DWithin(
location,
ST_GeomFromText('POINT(119.3 26.1)'),
0.1
);
2.7 时序表ACID事务验证(电力调度刚需)
绝大多数专用时序数据库不支持事务,电力、工控等数据不可丢失场景存在数据错乱风险;金仓时序表完全支持事务提交、回滚:
BEGIN;
-- 写入一条异常工况时序数据
INSERT INTO device_metric VALUES('2026-06-18 10:10:00','DEV001',62.5,3.8,22.1);
-- 手动回滚,数据不落地存储
ROLLBACK;
-- 查询校验,无本条数据
SELECT * FROM device_metric WHERE ts = '2026-06-18 10:10:00' AND device_id = 'DEV001';
三、TSBS基准压测脚本与性能数据
行业通用时序基准测试工具TSBS,统一硬件环境8核16G SSD,实测客观性能:
- 金仓KES时序引擎:单机稳定写入102万数据点/秒
- InfluxDB:单机稳定写入115万数据点/秒
裸写入性能差距较小;但在时序+关系多表联合查询场景,金仓查询性能领先InfluxDB约37%,省去跨库同步带来的额外开销。
TSBS金仓写入压测shell脚本:
tsbs-load kingbase \
--host=127.0.0.1 \
--port=54321 \
--user=system \
--password=Kingbase123 \
--db=ts_test_db \
--scale=100 \
--workers=8 \
--use-timeseries-table
四、线上生产落地场景
4.1 国家电网智能调度国产化平台
存量业务数据库统一使用金仓KES,无需新增独立时序集群;电力高频采集测点直接写入时序分区表,事务机制保障调度数据零丢失,省去MySQL/专用时序库双向同步中间件,整体中间件架构缩减30%,运维人员仅需掌握一套数据库技能。
4.2 福建省船舶安全综合管理平台
每日亿级船舶GPS时序轨迹写入,一库同时承载船舶档案业务数据、时序轨迹、GIS空间点位;前端轨迹回放、船舶信息关联查询均毫秒响应,无需拆分多套存储组件。
4.3 智能制造产线监控平台
设备工况时序数据可直接关联生产工单、维保记录、班组台账,BI报表无需多库数据拼接,报表开发周期缩短一半,运维仅需一套KES备份、监控工具。
五、2026时序数据库选型判断标准
- 纯服务器/容器监控、无业务关联、仅做测点存储:优先TDengine、Apache IoTDB,极致写入性能成本最优;
- 金融量化、海量历史时序离线批量计算:选择DolphinDB;
- 国产化信创项目、时序数据需和业务台账频繁关联、要求数据事务一致性、存量环境为金仓KES:优先金仓多模时序引擎,降低长期运维TCO;
- 车辆、船舶轨迹,需要时序+GIS一体化分析场景:国产时序库中金仓为最优方案。
总结
2026年时序数据库选型早已脱离“唯写入TPS”的单一评判标准。绝大多数企业数字化项目的核心痛点,从来不是数据写入速度不足,而是多套数据库拆分带来的架构臃肿、数据同步故障、运维学习成本高、关键业务数据无事务保障。
金仓时序引擎没有跟随行业主流打造独立专用时序产品,而是基于成熟关系内核做时序能力扩展,以融合多模架构实现时序、关系、GIS数据统一底座。对于能源、制造、政务等国产化复杂业务场景,一体化存储架构带来的运维简化、业务开发提效、数据强一致能力,远高于单纯追求单机写入峰值的收益,也是国产基础软件务实落地的差异化创新路线。
未来随着实时AI分析、流批一体化普及,时序引擎与多模数据、AI算子、流计算框架的无缝融合,将是所有国产时序厂商共同迭代的核心方向。

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐

 4
4 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)