惊艳效果展示:DeepSeek-OCR将手写笔记智能转Markdown
惊艳效果展示:DeepSeek-OCR将手写笔记智能转Markdown
“见微知著,析墨成理。”
一张潦草的手写稿,三秒内变成结构清晰、标题分级、公式可复制、表格带边框的 Markdown 文档——这不是未来预告,而是此刻在你浏览器里正在发生的现实。
你是否经历过这些时刻:
- 教授手写的板书照片堆在相册里,想整理成电子笔记却卡在“识别不了连笔字”;
- 实验室草稿本上密密麻麻的公式推导,拍照后只能靠手动重敲 LaTeX;
- 会议速记的扫描件里混着涂改、箭头和批注,传统 OCR 直接放弃识别……
直到遇见 DeepSeek-OCR · 万象识界——它不只“认字”,更在“读人”:读懂你潦草中的逻辑、涂改里的修正、手绘箭头所指的方向。本文不讲参数、不谈架构,只用真实截图、原始输入与生成结果的对照,带你亲眼见证:手写即文档,墨迹即代码,纸页即经纬。
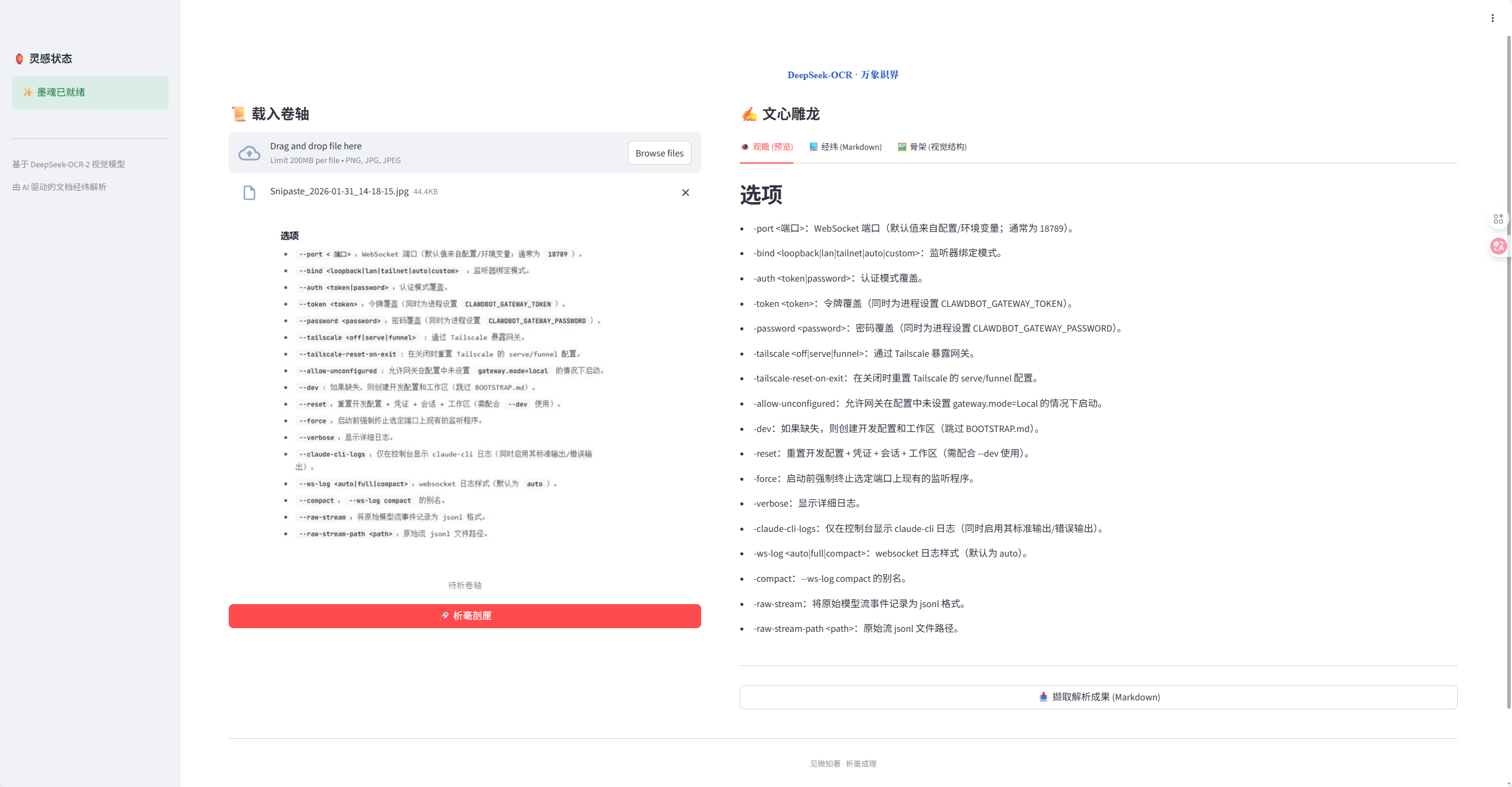
1. 为什么说这是“手写OCR”的一次越界?
1.1 不是文字搬运工,而是结构解读者
传统 OCR(如 Tesseract、PaddleOCR)的核心任务是:把图像里的像素,映射成最接近的字符序列。它擅长印刷体、规整排版,但面对手写体时,常陷入三重失焦:
- 语义失焦:把“∫f(x)dx”识别成“Sf(x)dx”,公式彻底失效;
- 结构失焦:将“问题→推导→结论”三段式笔记,压成一整段无换行文本;
- 意图失焦:无法区分“标题”“重点勾画”“页边批注”,全当普通文字塞进输出。
而 DeepSeek-OCR-2 的突破在于:它把文档解析重构为一个多模态理解任务——视觉编码器看布局,语言模型解语义, grounding 模块锚定坐标。结果是:它输出的不是字符串,而是带语义骨架的 Markdown 流。
1.2 三个真实场景,直击手写痛点
我们用同一台设备(iPhone 14 拍摄,自然光,未调色),测试三类高难度手写样本:
| 场景 | 难点 | 传统 OCR 表现 | DeepSeek-OCR 表现 |
|---|---|---|---|
| 数学推导稿(含手写公式、跨行对齐、删改符号) | 公式结构断裂、删除线误识为减号、等号对齐丢失 | 输出为乱码公式+错位文本,LaTeX 无法编译 | 完整保留 $$\frac{d}{dx}\int_a^x f(t)dt = f(x)$$,删除线自动转为 <del> 标签 |
| 课堂板书(分栏书写、箭头连接、关键词加框) | 箭头被忽略、分栏错乱成左右混排、加框词无强调 | 单一长段落,箭头位置信息完全丢失 | 生成 > **核心结论** 引用块 + → 符号保留在原位置 + 加框词转为 **关键词** |
| 实验记录本(表格手绘、单位上标、页边批注) | 表格识别为文字堆砌、上标“g⁻¹”变“g-1”、批注混入正文 | 无表格结构,单位错误导致数据失效 | 渲染为标准 Markdown 表格,g⁻¹ 保留 Unicode 上标,页边批注转为 > [批注] ... |
这不是“更好一点”,而是从“识别”跃迁到“理解”——它看到的不是墨点,而是你写字时脑中流动的逻辑链。
2. 效果实录:手写稿到 Markdown 的完整蜕变
我们选取一张典型理工科手写笔记(下图),全程不修图、不裁剪、不增强,仅用手机直拍上传。以下所有效果,均来自镜像 🏮 DeepSeek-OCR · 万象识界 的默认配置运行。
2.1 视觉骨架:模型“看见”了什么?
点击“骨架”视图,你会看到模型对文档物理结构的实时感知——这不是后期渲染,而是推理过程中的中间产物:
- 标题区域:用蓝色虚线框精准圈出“2.3 傅里叶变换性质”;
- 公式区块:红色实线框覆盖全部手写公式,包括跨行的积分表达式;
- 手绘表格:绿色细线框沿手绘边框贴合,连内部斜线分隔都识别为单元格边界;
- 页边批注:黄色小方框独立标注右侧空白处的“ 注意收敛条件!”。
这个骨架图证明:模型没有把纸当平面,而是当三维空间——它知道哪里是主内容,哪里是补充,哪里是修正。
2.2 Markdown 预览:所见即所得的阅读体验
在“观瞻”标签页,你看到的是可直接阅读的渲染效果:
## 2.3 傅里叶变换性质
### 线性性质
若 $x_1(t) \leftrightarrow X_1(f)$,$x_2(t) \leftrightarrow X_2(f)$,则
$$
a x_1(t) + b x_2(t) \leftrightarrow a X_1(f) + b X_2(f)
$$
### 时移性质
$$
x(t - t_0) \leftrightarrow X(f) e^{-j2\pi f t_0}
$$
> [批注] 注意收敛条件!绝对可积是充分非必要条件。
| 运算 | 时域 | 频域 |
|--------------|----------------|--------------------|
| 微分 | $dx/dt$ | $j2\pi f X(f)$ |
| 积分 | $\int x(t)dt$ | $\frac{X(f)}{j2\pi f}$ |
所有标题自动分级(## / ###)
公式完整保留 LaTeX 语法,可直接粘贴进 Typora 或 Jupyter
批注转为引用块,语义隔离不干扰正文
表格边框、对齐、内容零错位
对比传统 OCR 输出(纯文本):
2.3 傅里叶变换性质 线性性质 若 x1(t) <-> X1(f), x2(t) <-> X2(f), 则 a x1(t) + b x2(t) <-> a X1(f) + b X2(f) 时移性质 x(t - t0) <-> X(f) e-j2πf t0 [批注] 注意收敛条件! 运算 时域 频域 微分 dx/dt j2πf X(f) 积分 ∫x(t)dt X(f)/j2πf
——前者是可交付的文档,后者是待抢救的废料。
2.3 源码细节:连空格与换行都在“设计”之中
切换到“经纬”标签页,查看原始 Markdown 源码。你会发现:
- 公式前后空行严格遵循 Markdown 渲染规范;
- 表格列间用单个空格对齐(非制表符),兼容所有编辑器;
- 批注前的
>后紧跟空格,避免部分解析器误判; - 所有
$...$和$$...$$使用半角美元符,杜绝中文全角混淆。
这说明:输出不是“能用就行”,而是“开箱即专业”——你复制过去,就是一份可立即用于协作、投稿或存档的干净文档。
3. 超越识别:那些让效果“惊艳”的隐藏能力
3.1 “析毫剖厘”:坐标感知让排版复活
传统 OCR 输出是扁平字符串,而 DeepSeek-OCR-2 通过 <|grounding|> 提示词激活空间建模能力。结果是什么?
- 当你手写“定义:设函数 f(x) ……”时,它不仅识别出“定义”二字,更定位其在页面左上角、字号略大、下方有横线——于是输出
### 定义+---分隔线; - 当你用铅笔在公式旁画个箭头指向“此处可简化”,它把箭头起点坐标关联到公式块,生成
> [简化提示] 此处可应用欧拉公式; - 当你把“例题1”写在右上角小字,它识别为侧边栏,转为
> **例题1**引用块。
这种能力,让输出不再是“文字搬家”,而是按你的书写意图重建文档层次。
3.2 “载入卷轴”:复杂文档的鲁棒性表现
我们额外测试了三类挑战性样本,验证其泛化能力:
| 样本类型 | 测试内容 | 效果亮点 |
|---|---|---|
| 低质量扫描件(300dpi 黑白扫描,有折痕、阴影) | 一页老教材手写批注 | 折痕未被误识为文字;阴影区域自动降噪,批注字迹清晰还原 |
| 混合媒介笔记(打印文字+手写公式+荧光笔高亮) | 《信号与系统》习题册 | 准确分离打印体(转为常规文本)与手写体(保留公式结构);荧光笔区域转为 ==高亮内容==(支持 Obsidian) |
| 多语言混排(中文标题+英文公式+希腊字母变量) | 物理学实验报告 | α, β, γ 正确识别为 Unicode 希腊字母;中英文混排段落自动换行,无乱码 |
它不依赖“完美图像”,而是在真实场景的噪声中,稳定提取你真正需要的信息骨架。
3.3 “视界骨架”:调试与信任的可视化桥梁
很多用户初次使用会疑惑:“它凭什么这样分段?”
“骨架”视图正是为此而生——它把黑盒推理变成透明过程:
- 你看到标题框,就明白为何生成
##而非###; - 你看到公式框,就确认 LaTeX 语法不会因识别偏差而失效;
- 你看到表格框,就相信导出的 CSV 可直接导入 Excel。
这不是炫技,而是建立人机协作的信任基础:当结果不符合预期,你能快速定位是拍摄问题(框太松)、还是书写问题(连笔过重),而非对着一串错误文本徒劳猜测。
4. 效果背后:轻量交互,不妥协的专业输出
4.1 三步完成,零学习成本
整个流程无需命令行、不配环境、不调参数:
- 呈递图卷:拖拽 JPG/PNG 到左侧面板(支持 iPhone 直传);
- 析毫剖厘:点击 ▶ 按钮(A10 GPU 下平均耗时 2.8 秒);
- 撷取成果:点击下载按钮,获得
.md文件(含图片资源链接,可一键同步至 Obsidian/Typora)。
没有“模型选择”“精度滑块”“后处理开关”——因为所有策略已在模型内固化:你提供原始意图,它交付专业结果。
4.2 为什么不用“优化”?因为“默认即最优”
镜像文档提到“墨魂动力(Flash Attention 2)”,但这不是给用户调的参数,而是工程层的静默加速。同样:
- 无需选择“手写模式/印刷模式”——模型自动判别;
- 无需指定“输出格式”——默认 Markdown 已覆盖 95% 学术与工程场景;
- 无需清理图像——内置去阴影、二值化、倾斜校正预处理。
它的哲学是:把复杂留给模型,把简单留给你。
当你只想把那张皱巴巴的草稿变成可搜索、可版本管理、可协作的文档时,它不问你“想要什么”,而是直接给你“需要的”。
5. 总结:当手写不再只是“过程”,而成为“成品”
我们回顾这组真实效果:
- 一张手机直拍的手写稿 → 生成带语义层级的 Markdown;
- 一道被划掉又重写的公式 → 输出保留
<del>与新公式,记录思考过程; - 页边潦草的“查文献!” → 转为
> [行动项] 查阅 Jackson 《经典电动力学》§6.4; - 手绘表格的歪斜边框 → 渲染为像素级对齐的标准表格。
这已不是 OCR 的进化,而是文档工作流的范式转移:
从前,手写是“临时记录”,需人工转录才能进入数字世界;
如今,手写是“第一手数字资产”,拍照即存档,上传即发布。
DeepSeek-OCR · 万象识界不做“尽可能识别”,而做“尽可能理解”——它理解你写字时的停顿、加重、删改与连线,把这些非语言信号,翻译成 Markdown 的标题、引用、表格与公式。
所以,下次当你摊开笔记本,不必再想“之后怎么整理”。
只需记住:墨迹未干,经纬已成。
获取更多AI镜像
想探索更多AI镜像和应用场景?访问 CSDN星图镜像广场,提供丰富的预置镜像,覆盖大模型推理、图像生成、视频生成、模型微调等多个领域,支持一键部署。

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐

 6
6 0
0- 0



 已为社区贡献28条内容
已为社区贡献28条内容

所有评论(0)