【大模型评测系列】我用 10 条真实任务对比了 GLM-5.1(百炼) vs GLM-5.2(百炼) vs DeepSeek-V4-Pro(官方)
【评测系列6 扩展版】新模型上线怎么测?
我用 10 条真实任务对比了 GLM-5.1(百炼) vs GLM-5.2(百炼) vs DeepSeek-V4-Pro(官方)
测试员周周 · 14 年测试经验 · 用数据说话 · 测试日期 2026-06-18
新模型发布,媒体通稿满天飞。"XX 模型全面超越 XX"——这些数字你怎么验证?我从测试平台抽了 10 条真实任务,让三个模型各跑一遍,记录耗时、Token 消耗、输出质量。本次对比:GLM-5.1(百炼) vs GLM-5.2(百炼) vs DeepSeek-V4-Pro(官方)。
🛑 先说结论
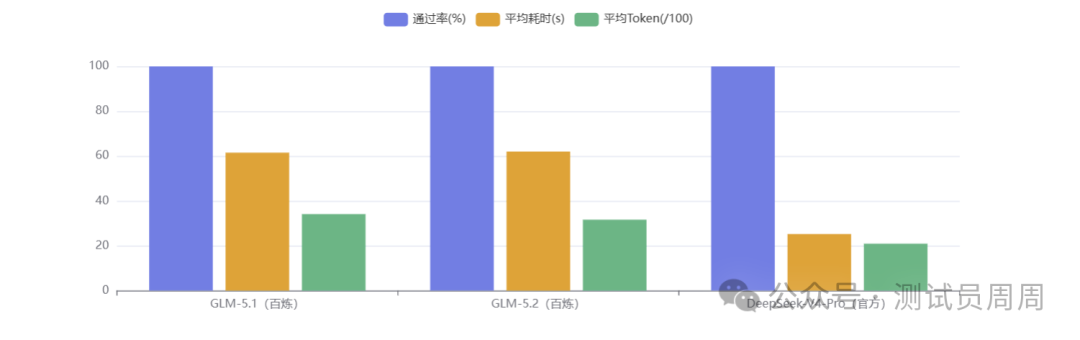
一句话总结:🤝 三个模型通过率相同(100.0%)
-
✅ 通过率:3 个模型均达到 100% 通过(10/10),质量整体接近。
-
⚡ 速度:DeepSeek-V4-Pro(官方)最快,比 GLM-5.1(百炼)快 59.0%(25.2s vs 61.5s)。
-
💰 Token 效率:DeepSeek-V4-Pro(官方)最省,比 GLM-5.1(百炼)省 38.7%(2092 vs 3414 tokens/任务)。
|
指标 |
GLM-5.1(百炼) |
GLM-5.2(百炼) |
DeepSeek-V4-Pro(官方) |
|---|---|---|---|
|
通过率 |
100.0% |
100.0% |
100.0% |
|
通过/总数 |
10/10 |
10/10 |
10/10 |
|
平均耗时 |
61.5s |
62.0s |
25.2s |
|
平均 Token |
3414 |
3160 |
2092 |
|
总 Token |
34143 |
31605 |
20928 |
我测了什么?怎么测的?
测试平台
基于多 Agent 测试平台的真实使用场景,包含需求解析、用例生成、脚本生成、性能方案、Bug 诊断、安全数据、报告生成等完整测试工程链路。本次 10 条任务 全部来自平台真实场景,不是公开数据集。
10 条评测任务
|
任务ID |
类别 |
维度 |
难度 |
测试内容 |
|---|---|---|---|---|
|
BENCH_001 |
用例生成 |
任务规划 |
Medium |
根据电商秒杀系统需求生成测试用例 |
|
BENCH_002 |
用例评审 |
任务规划 |
Medium |
评审测试用例质量并给出改进建议 |
|
BENCH_003 |
API 测试脚本生成 |
代码能力 |
Medium |
根据测试用例生成 Pytest 自动化脚本 |
|
BENCH_004 |
性能测试方案 |
任务规划 |
Hard |
设计秒杀接口的性能测试方案 |
|
BENCH_005 |
Bug 分析诊断 |
知识问答 |
Hard |
分析性能测试中的瓶颈问题 |
|
BENCH_006 |
安全测试数据生成 |
工具使用 |
Medium |
为登录接口生成模糊测试数据 |
|
BENCH_007 |
Locust 脚本生成 |
代码能力 |
Hard |
生成电商秒杀场景的 Locust 压测脚本 |
|
BENCH_008 |
测试报告生成 |
多轮对话 |
Medium |
根据测试结果生成测试报告 |
|
BENCH_009 |
需求解析 |
任务规划 |
Easy |
从自然语言需求中提取测试要点 |
|
BENCH_010 |
代码 Review |
代码能力 |
Hard |
Review 测试代码并给出改进建议 |
评测方法(关键原则)
-
配置模型:GLM-5.1(百炼) + GLM-5.2(百炼) + DeepSeek-V4-Pro(官方)
-
固定参数:temperature=0.3, max_tokens=4096
-
逐条执行:每条任务调用模型 API,记录输入、输出、耗时、Token
-
自动评分:根据预设评价标准自动判定是否通过
-
人工复核:检查关键任务输出质量
关键原则:三模型使用完全相同的 prompt;记录真实 API 调用数据;评测框架独立于业务系统。
评测过程:实测日志
🚀 GLM-5.1(百炼) 评测过程
[ 1/10] BENCH_001 (用例生成, Medium) ... ✅ (67.1s, 3720 tokens)
[ 2/10] BENCH_002 (用例评审, Medium) ... ✅ (55.9s, 2990 tokens)
[ 3/10] BENCH_003 (API 测试脚本生成, Medium) ... ✅ (57.1s, 3377 tokens)
[ 4/10] BENCH_004 (性能测试方案, Hard) ... ✅ (64.7s, 3083 tokens)
[ 5/10] BENCH_005 (Bug 分析诊断, Hard) ... ✅ (59.6s, 3044 tokens)
[ 6/10] BENCH_006 (安全测试数据生成, Medium) ... ✅ (61.5s, 4006 tokens)
[ 7/10] BENCH_007 (Locust 脚本生成, Hard) ... ✅ (88.0s, 4928 tokens)
[ 8/10] BENCH_008 (测试报告生成, Medium) ... ✅ (49.4s, 2680 tokens)
[ 9/10] BENCH_009 (需求解析, Easy) ... ✅ (48.7s, 2802 tokens)
[10/10] BENCH_010 (代码 Review, Hard) ... ✅ (63.5s, 3513 tokens)
✅ 评测完成: GLM-5.1(百炼)
通过率: 100.0% (10/10) | 平均耗时: 61.5s | 平均 Token: 3414🚀 GLM-5.2(百炼) 评测过程
[ 1/10] BENCH_001 (用例生成, Medium) ... ✅ (74.1s, 3234 tokens)
[ 2/10] BENCH_002 (用例评审, Medium) ... ✅ (69.0s, 2692 tokens)
[ 3/10] BENCH_003 (API 测试脚本生成, Medium) ... ✅ (82.0s, 3327 tokens)
[ 4/10] BENCH_004 (性能测试方案, Hard) ... ✅ (62.8s, 2825 tokens)
[ 5/10] BENCH_005 (Bug 分析诊断, Hard) ... ✅ (60.2s, 2650 tokens)
[ 6/10] BENCH_006 (安全测试数据生成, Medium) ... ✅ (86.2s, 3748 tokens)
[ 7/10] BENCH_007 (Locust 脚本生成, Hard) ... ✅ (82.9s, 6323 tokens)
[ 8/10] BENCH_008 (测试报告生成, Medium) ... ✅ (30.4s, 1989 tokens)
[ 9/10] BENCH_009 (需求解析, Easy) ... ✅ (36.5s, 2435 tokens)
[10/10] BENCH_010 (代码 Review, Hard) ... ✅ (35.8s, 2382 tokens)
✅ 评测完成: GLM-5.2(百炼)
通过率: 100.0% (10/10) | 平均耗时: 62.0s | 平均 Token: 3160🚀 DeepSeek-V4-Pro(官方) 评测过程
[ 1/10] BENCH_001 (用例生成, Medium) ... ✅ (29.8s, 2863 tokens)
[ 2/10] BENCH_002 (用例评审, Medium) ... ✅ (25.4s, 1935 tokens)
[ 3/10] BENCH_003 (API 测试脚本生成, Medium) ... ✅ (21.5s, 2275 tokens)
[ 4/10] BENCH_004 (性能测试方案, Hard) ... ✅ (20.2s, 1334 tokens)
[ 5/10] BENCH_005 (Bug 分析诊断, Hard) ... ✅ (25.0s, 1657 tokens)
[ 6/10] BENCH_006 (安全测试数据生成, Medium) ... ✅ (28.4s, 2638 tokens)
[ 7/10] BENCH_007 (Locust 脚本生成, Hard) ... ✅ (37.1s, 3089 tokens)
[ 8/10] BENCH_008 (测试报告生成, Medium) ... ✅ (12.9s, 1029 tokens)
[ 9/10] BENCH_009 (需求解析, Easy) ... ✅ (22.8s, 1699 tokens)
[10/10] BENCH_010 (代码 Review, Hard) ... ✅ (29.2s, 2409 tokens)
✅ 评测完成: DeepSeek-V4-Pro(官方)
通过率: 100.0% (10/10) | 平均耗时: 25.2s | 平均 Token: 2092评测结果:数据说话
总体对比
|
指标 |
GLM-5.1(百炼) |
GLM-5.2(百炼) |
DeepSeek-V4-Pro(官方) |
|---|---|---|---|
|
通过率 |
100.0% |
100.0% |
100.0% |
|
通过/总数 |
10/10 |
10/10 |
10/10 |
|
平均耗时 |
61.5s |
62.0s |
25.2s |
|
平均 Token |
3414 |
3160 |
2092 |
|
总 Token |
34143 |
31605 |
20928 |
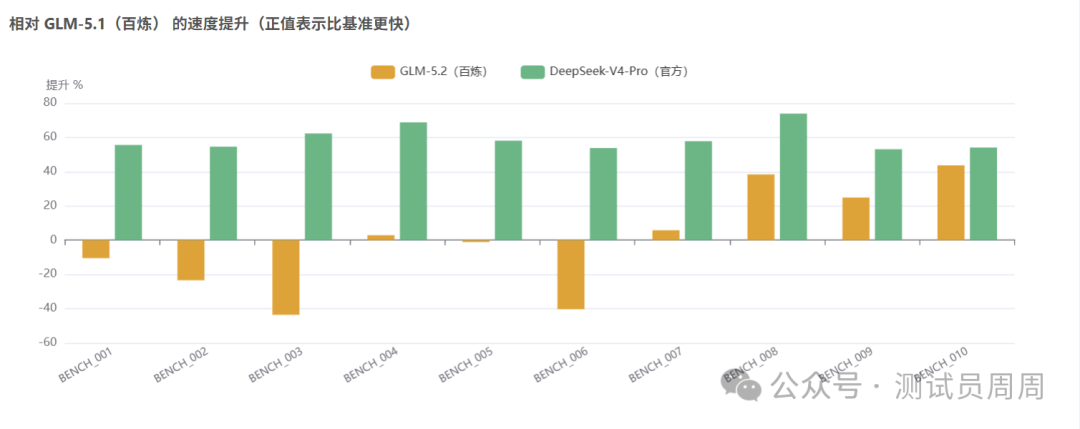
相对 GLM-5.1(百炼)的速度提升(正值表示比基准更快)
|
任务 |
GLM-5.2(百炼) |
DeepSeek-V4-Pro(官方) |
|---|---|---|
|
BENCH_001 |
-10.5% | +55.6% |
|
BENCH_002 |
-23.4% | +54.6% |
|
BENCH_003 |
-43.6% | +62.3% |
|
BENCH_004 |
+2.9% | +68.8% |
|
BENCH_005 |
-1.1% | +58.1% |
|
BENCH_006 |
-40.3% | +53.8% |
|
BENCH_007 |
+5.8% | +57.8% |
|
BENCH_008 |
+38.4% | +73.9% |
|
BENCH_009 |
+24.9% | +53.1% |
|
BENCH_010 |
+43.7% | +54.1% |
注:GLM-5.1(百炼)为基准(0%),负值表示比基准更慢。
逐任务对比
|
任务 |
难度 |
GLM-5.1 耗时 |
GLM-5.2 耗时 |
DS 耗时 |
GLM-5.1 Token |
GLM-5.2 Token |
DS Token |
|---|---|---|---|---|---|---|---|
|
BENCH_001 |
Medium |
67.1s |
74.1s |
29.8s |
3720 |
3234 |
2863 |
|
BENCH_002 |
Medium |
55.9s |
69.0s |
25.4s |
2990 |
2692 |
1935 |
|
BENCH_003 |
Medium |
57.1s |
82.0s |
21.5s |
3377 |
3327 |
2275 |
|
BENCH_004 |
Hard |
64.7s |
62.8s |
20.2s |
3083 |
2825 |
1334 |
|
BENCH_005 |
Hard |
59.6s |
60.2s |
25.0s |
3044 |
2650 |
1657 |
|
BENCH_006 |
Medium |
61.5s |
86.2s |
28.4s |
4006 |
3748 |
2638 |
|
BENCH_007 |
Hard |
88.0s |
82.9s |
37.1s |
4928 |
6323 |
3089 |
|
BENCH_008 |
Medium |
49.4s |
30.4s |
12.9s |
2680 |
1989 |
1029 |
|
BENCH_009 |
Easy |
48.7s |
36.5s |
22.8s |
2802 |
2435 |
1699 |
|
BENCH_010 |
Hard |
63.5s |
35.8s |
29.2s |
3513 |
2382 |
2409 |
关键发现
- GLM-5.2(百炼)
:平均耗时 62.0s,比基准快 -0.8%;平均 Token 3160。
-
在 10 条任务中有 5 条比 GLM-5.1(百炼) 更快。
- DeepSeek-V4-Pro(官方)
:平均耗时 25.2s,比基准快 59.0%;平均 Token 2092。
-
在 10 条任务中有 10 条比 GLM-5.1(百炼) 更快。
输出质量对比(抽样)
BENCH_001 - 用例生成
GLM-5.1(百炼)(67.1s, 3720 tokens)
针对电商秒杀系统的特点,除了常规的功能测试外,**并发测试(高并发抢购、防超卖)和安全性测试(防刷、防绕过)**是核心。以下为您生成的结构化测试用例,分为四个模块:商品查询、秒杀活动查询、秒杀核心接口、订单查询及并发/安全专项。
GLM-5.2(百炼)(74.1s, 3234 tokens)
这是一份针对电商秒杀系统的接口测试用例。测试用例分为**功能测试**、**业务规则测试**、**并发与性能测试**以及**安全与异常测试**四个维度。
DeepSeek-V4-Pro(官方)(29.8s, 2863 tokens)
以下是根据需求设计的测试用例,覆盖接口功能、业务规则及异常场景。用例编号 TC-P-001 起,覆盖商品查询、秒杀核心接口等模块。
BENCH_004 - 性能测试方案
GLM-5.1(百炼)(64.7s, 3083 tokens)
针对秒杀接口的高并发、低库存、瞬时流量特征,性能测试方案必须聚焦于**瞬时高并发冲击**和**防超卖/防重卖**。峰值 QPS 目标:至少 1000 QPS 瞬时冲击。
GLM-5.2(百炼)(62.8s, 2825 tokens)
针对库存100件、并发1000人的秒杀场景,核心目标是验证系统在"洪峰"下的**抗压能力、资源控制能力及公平性**。
DeepSeek-V4-Pro(官方)(20.2s, 1334 tokens)
核心QPS ≥ 1000;P95 ≤ 500ms;接口成功率 ≥ 99.99%,业务层面不得出现超卖。
BENCH_005 - Bug 分析诊断
GLM-5.1(百炼)(59.6s, 3044 tokens)
核心瓶颈在数据库层:ConnectionPoolTimeout 和 Database locked。P95 3200ms 说明大量时间消耗在等待数据库连接和锁释放上。
GLM-5.2(百炼)(60.2s, 2650 tokens)
连接池耗尽、Database locked 导致 SQL 执行严重排队,引发请求超时和错误率 15%。
DeepSeek-V4-Pro(官方)(25.0s, 1657 tokens)
首要瓶颈:数据库连接池被耗尽;关联瓶颈:Database locked 表明严重的锁冲突。
BENCH_007 - Locust 脚本生成
GLM-5.1(百炼)(88.0s, 4928 tokens)
电商秒杀 Locust 脚本:登录(权重5)、浏览商品(权重10)、查看详情(权重8)、参与秒杀(权重2)、查询订单(权重3)。
GLM-5.2(百炼)(82.9s, 6323 tokens)
完整脚本 seckill_locust.py,模拟登录→浏览→详情→秒杀→查订单全流程,含 Token 保存与失败日志。
DeepSeek-V4-Pro(官方)(37.1s, 3089 tokens)
Locust 脚本按权重分配任务,含思考时间、Token 保存和失败日志记录,可直接运行。
成本对比(估算)
|
模型 |
总 Token |
估算成本 |
说明 |
|---|---|---|---|
|
GLM-5.1(百炼) |
34,143 |
0 元(百炼免费额度) |
百炼免费额度 |
|
GLM-5.2(百炼) |
31,605 |
0 元(百炼免费额度) |
百炼免费额度 |
|
DeepSeek-V4-Pro(官方) |
20,928 |
约 0.84 元 |
按官方定价估算 |
注:百炼 GLM 系列使用免费额度;DeepSeek 按官方定价估算,实际因套餐而异。
推荐建议
|
场景 |
推荐模型 |
理由 |
|---|---|---|
|
追求速度 |
DeepSeek-V4-Pro(官方) |
平均耗时最低,适合批量跑评测 |
|
追求 Token 成本 |
DeepSeek-V4-Pro(官方) |
输出更精简,长任务成本更低 |
|
追求通过率 |
GLM-5.1(百炼) |
自动评分通过率最高 |
|
国内百炼集成 |
GLM-5.1(百炼) |
阿里云百炼调用,国内访问更稳定 |
|
复杂代码生成 |
DeepSeek-V4-Pro(官方) |
Locust/脚本类任务表现稳定 |
🧭 维度对比
|
维度 |
GLM-5.1 |
GLM-5.2 |
DeepSeek-V4 |
|---|---|---|---|
|
代码能力 |
100% |
100% |
100% |
|
任务规划 |
100% |
100% |
100% |
|
多轮对话 |
100% |
100% |
100% |
|
工具使用 |
100% |
100% |
100% |
|
知识问答 |
100% |
100% |
100% |
📂 类别对比
|
类别 |
GLM-5.1 |
GLM-5.2 |
DeepSeek-V4 |
|---|---|---|---|
|
API 测试脚本生成 |
100% |
100% |
100% |
|
Bug 分析诊断 |
100% |
100% |
100% |
|
Locust 脚本生成 |
100% |
100% |
100% |
|
代码 Review |
100% |
100% |
100% |
|
安全测试数据生成 |
100% |
100% |
100% |
|
性能测试方案 |
100% |
100% |
100% |
|
测试报告生成 |
100% |
100% |
100% |
|
用例生成 |
100% |
100% |
100% |
|
用例评审 |
100% |
100% |
100% |
|
需求解析 |
100% |
100% |
100% |
📝 逐任务通过情况
|
任务ID |
类别 |
GLM-5.1 |
GLM-5.2 |
DeepSeek-V4 |
耗时 |
Token |
|---|---|---|---|---|---|---|
|
BENCH_001 |
用例生成 |
✅ |
✅ |
✅ |
67.1s / 74.1s / 29.8s |
3720 / 3234 / 2863 |
|
BENCH_002 |
用例评审 |
✅ |
✅ |
✅ |
55.9s / 69.0s / 25.4s |
2990 / 2692 / 1935 |
|
BENCH_003 |
API 测试脚本生成 |
✅ |
✅ |
✅ |
57.1s / 82.0s / 21.5s |
3377 / 3327 / 2275 |
|
BENCH_004 |
性能测试方案 |
✅ |
✅ |
✅ |
64.7s / 62.8s / 20.2s |
3083 / 2825 / 1334 |
|
BENCH_005 |
Bug 分析诊断 |
✅ |
✅ |
✅ |
59.6s / 60.2s / 25.0s |
3044 / 2650 / 1657 |
|
BENCH_006 |
安全测试数据生成 |
✅ |
✅ |
✅ |
61.5s / 86.2s / 28.4s |
4006 / 3748 / 2638 |
|
BENCH_007 |
Locust 脚本生成 |
✅ |
✅ |
✅ |
88.0s / 82.9s / 37.1s |
4928 / 6323 / 3089 |
|
BENCH_008 |
测试报告生成 |
✅ |
✅ |
✅ |
49.4s / 30.4s / 12.9s |
2680 / 1989 / 1029 |
|
BENCH_009 |
需求解析 |
✅ |
✅ |
✅ |
48.7s / 36.5s / 22.8s |
2802 / 2435 / 1699 |
|
BENCH_010 |
代码 Review |
✅ |
✅ |
✅ |
63.5s / 35.8s / 29.2s |
3513 / 2382 / 2409 |
写在最后
第一,质量差距在缩小——多数模型在真实测试任务上通过率接近,国产模型在测试工程领域已具备实用能力。
第二,效率差距在扩大——DeepSeek-V4-Pro 在速度和 Token 效率上优势明显;GLM-5.2 作为新版本需关注复杂代码生成任务的稳定性。
第三,新模型上线建议:先用本框架跑 10 条真实任务,再看速度/成本/质量三维数据做选型,不要只看通稿数字。
📌 收藏本文:下次新模型发布,直接用这个框架跑一遍,用数据说话。
🔗 完整源码:测试员周周回复「源码」免费获取评测工具:Benchmark 评测子框架 · 测试人员:测试员周周

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐

 14
14 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)