RAG知识库搭建大揭秘:原来这么简单,还能这么有趣!
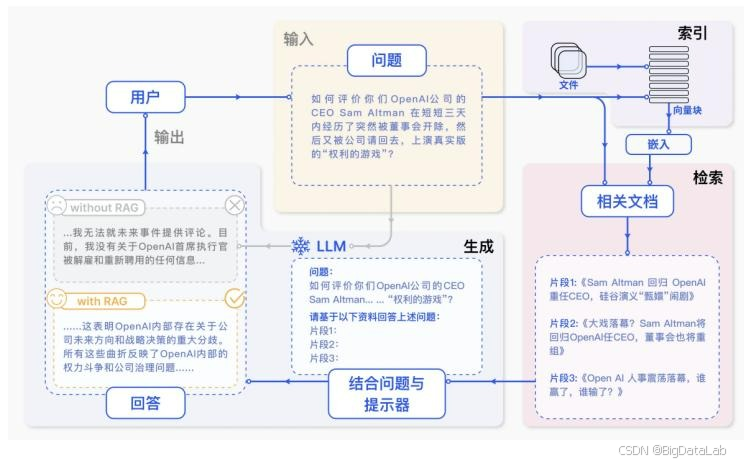
RAG :检索增强生成,检索 + 召回 + 提示词 + LLM 回答,就是给 AI 配了一本可查的书,不让它凭记忆胡说八道。
今天我们就通过一个案例来体验一下RAG是怎么工作的。
1、前置条件:本地dify+ollama LLM模型已搭建完成
前置依赖:本地dify+ollama LLM模型已搭建完成,具体参考Dify+Ollama模型搭建攻略:本地环境实战指南
2、本地部署embedding模型
# 拉取 nomic-embed-text 轻量模型(首次运行自动下载)
ollama run nomic-embed-text
# 检查模型是否存在
ollama list
embedding是什么呢?他其实就是把一段文字,变成一个多维向量,也就是一串数字。向量检索就是通过把两句话分别进行向量量后去比较他们的相似度,我们现在部署的 nomic-embed-test 就是把文字转换成向量的工具,在查询时,把问题也转换为向量,去向量库中找相似的内容。
3、dify配置模型
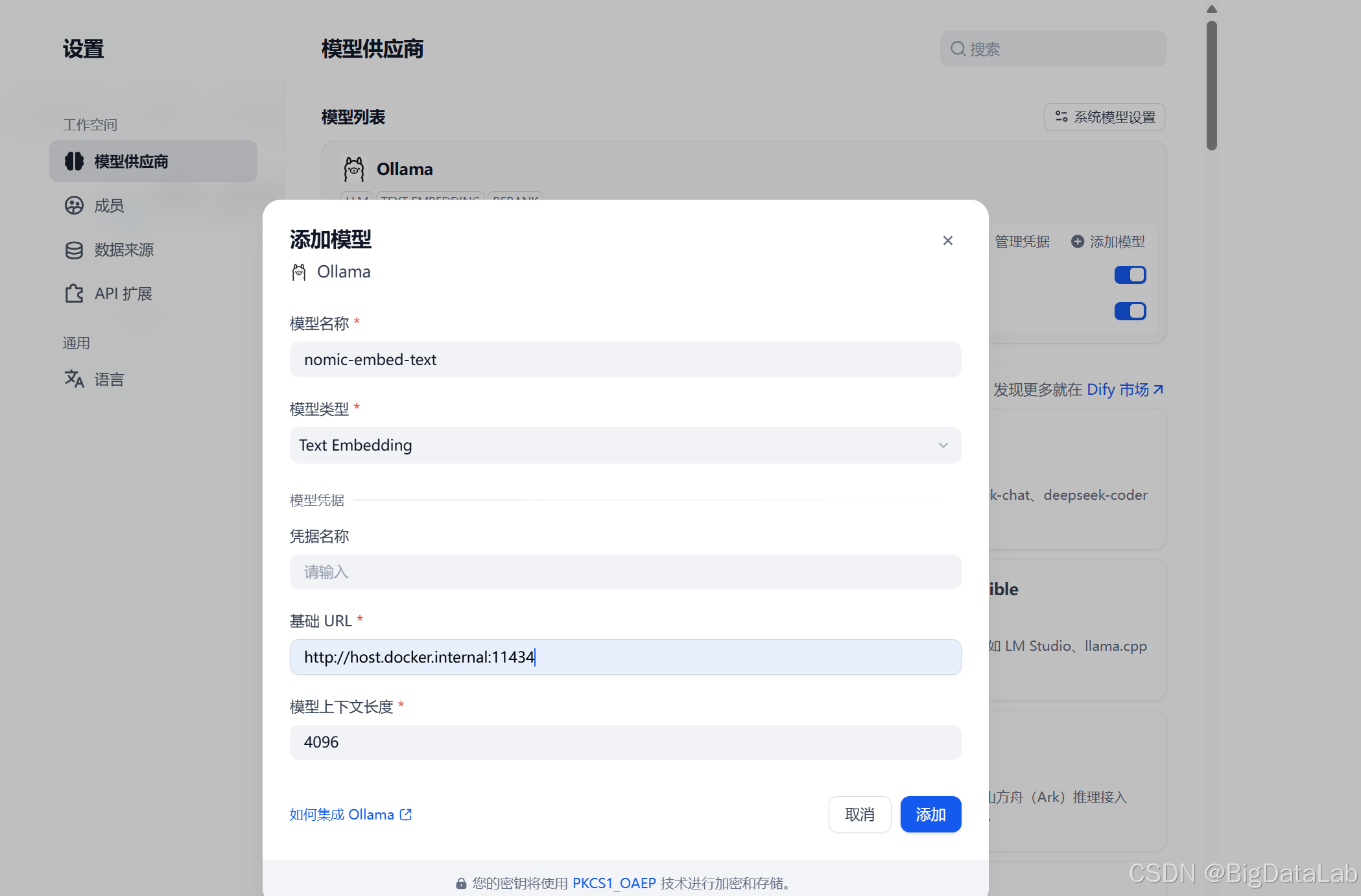
我的dify版本是1.13,模型配置位于右上角:点击头像 -> 设置 -> 模型供应商 -> ollama(如未安装需要先点击安装) -> 添加模型,关键配置如下:
-
模型名称:即ollama list查出的你新下载的模型
-
模型类型:“Text Embedding”
-
基础URL:固定配置“http://host.docker.internal:11434”(基于上一篇docker部署dify+本地ollama模型场景)
4、知识库配置
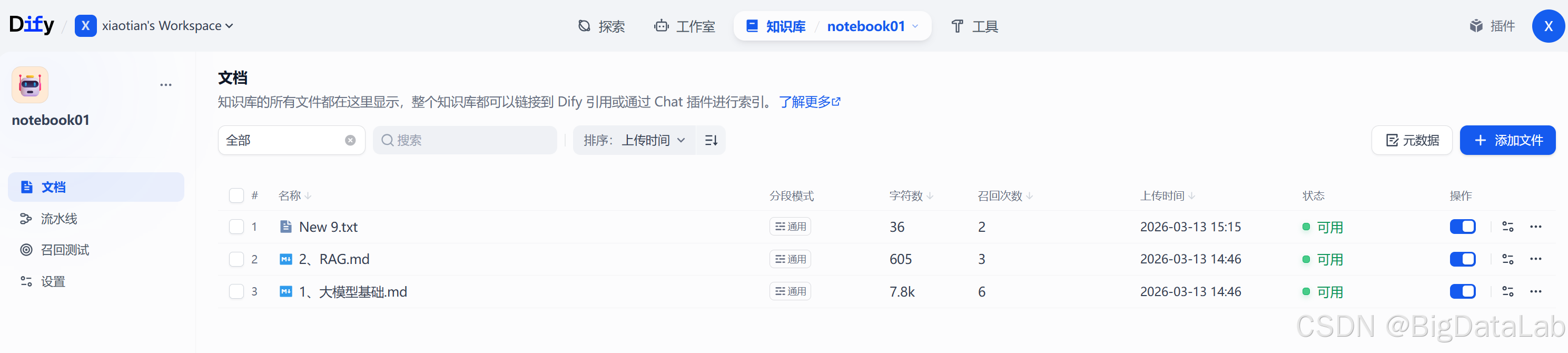
知识库中点击创建知识库,进入后添加文件,他会有个解析的过程,你可以手动编辑一段AI不知道的文本,用于后续测试。

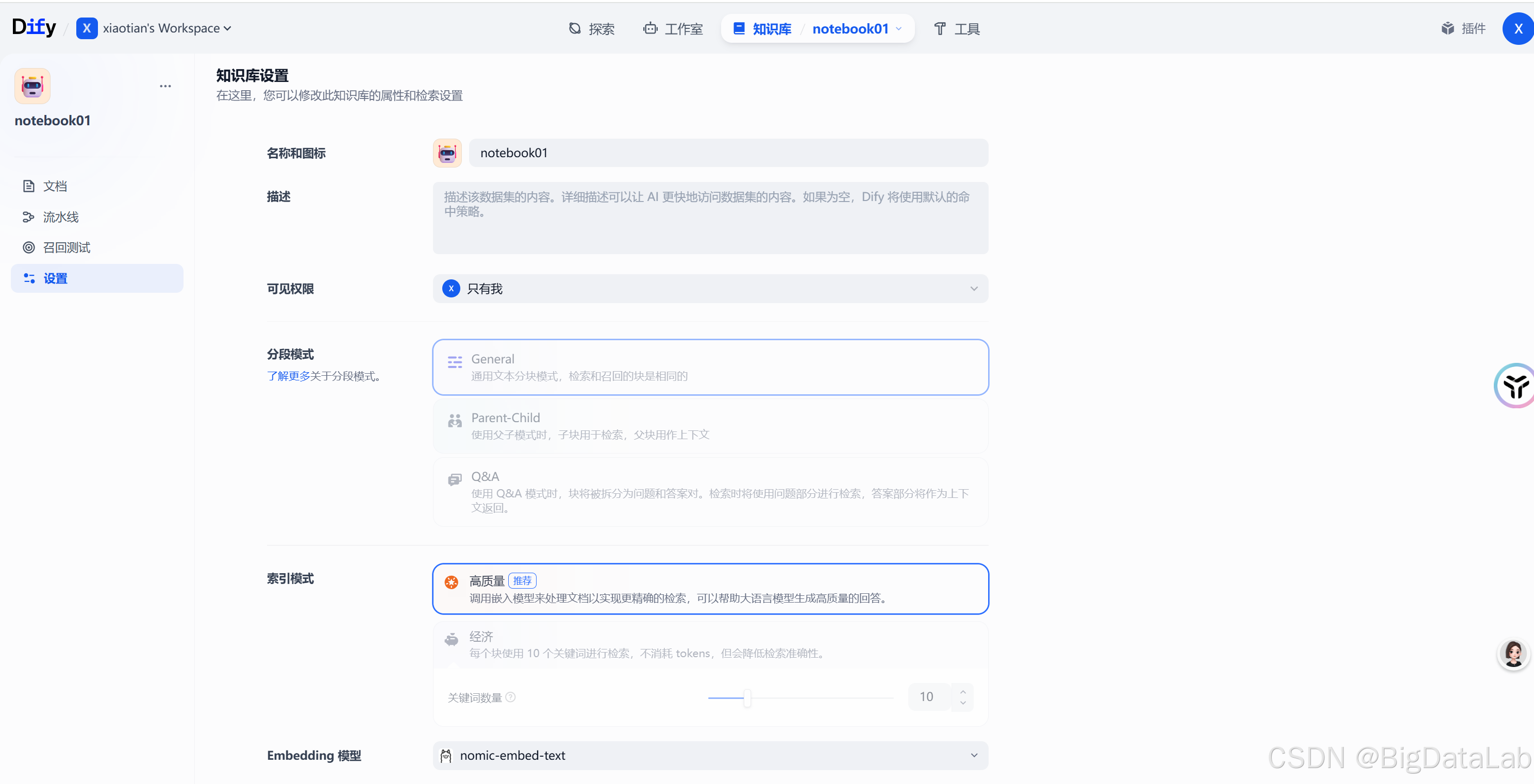
设置中,索引模式选择【高质量】,Embedding 模型选择刚才添加的模型,最下方保存。
5、配置应用
应用可以复用上次的知识库聊天机器人(或直接通过模板创建【知识库+聊天机器人】)。
- 知识检索节点:知识库位置添加刚刚创建好的知识库
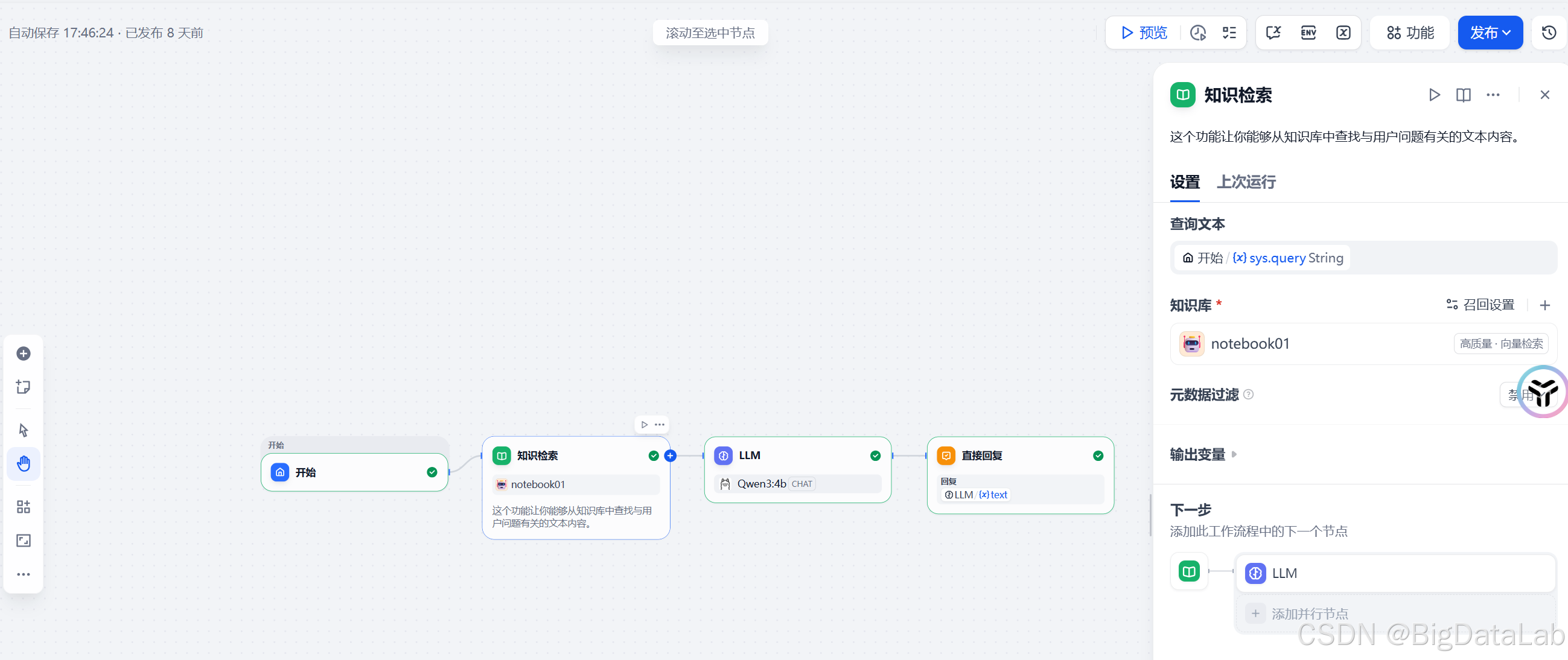
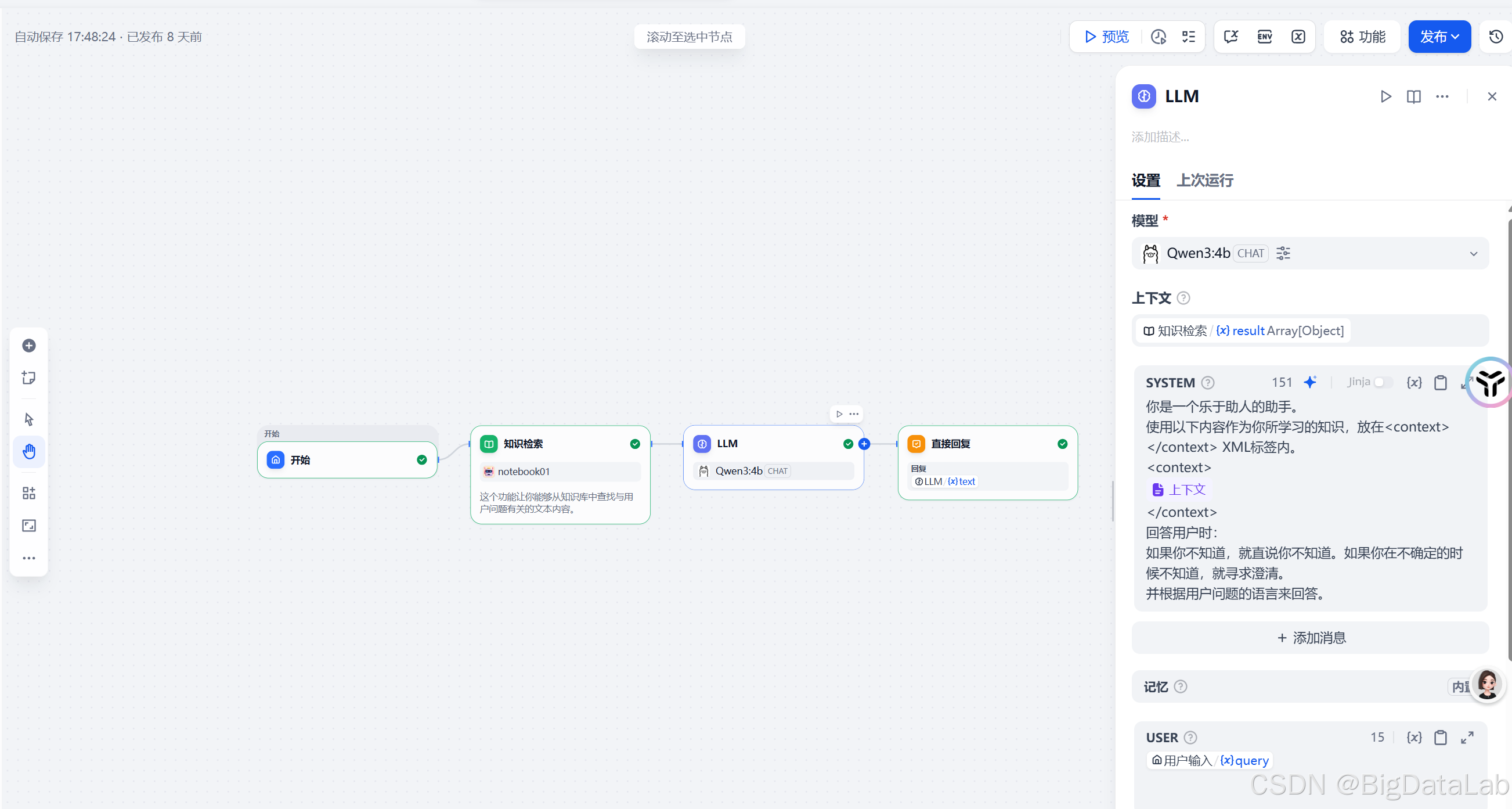
- LLM节点:上下文,选择 【知识检索】的result,如果是通过模板生成的应用,prompt中有一些尽量隐藏他从上下文中获取的信息,将这句话删掉,否则可能由于你的知识库中的知识,大模型自己不了解,而选择按他自己的意思来猜测,导致结果不准确。
6、效果验证
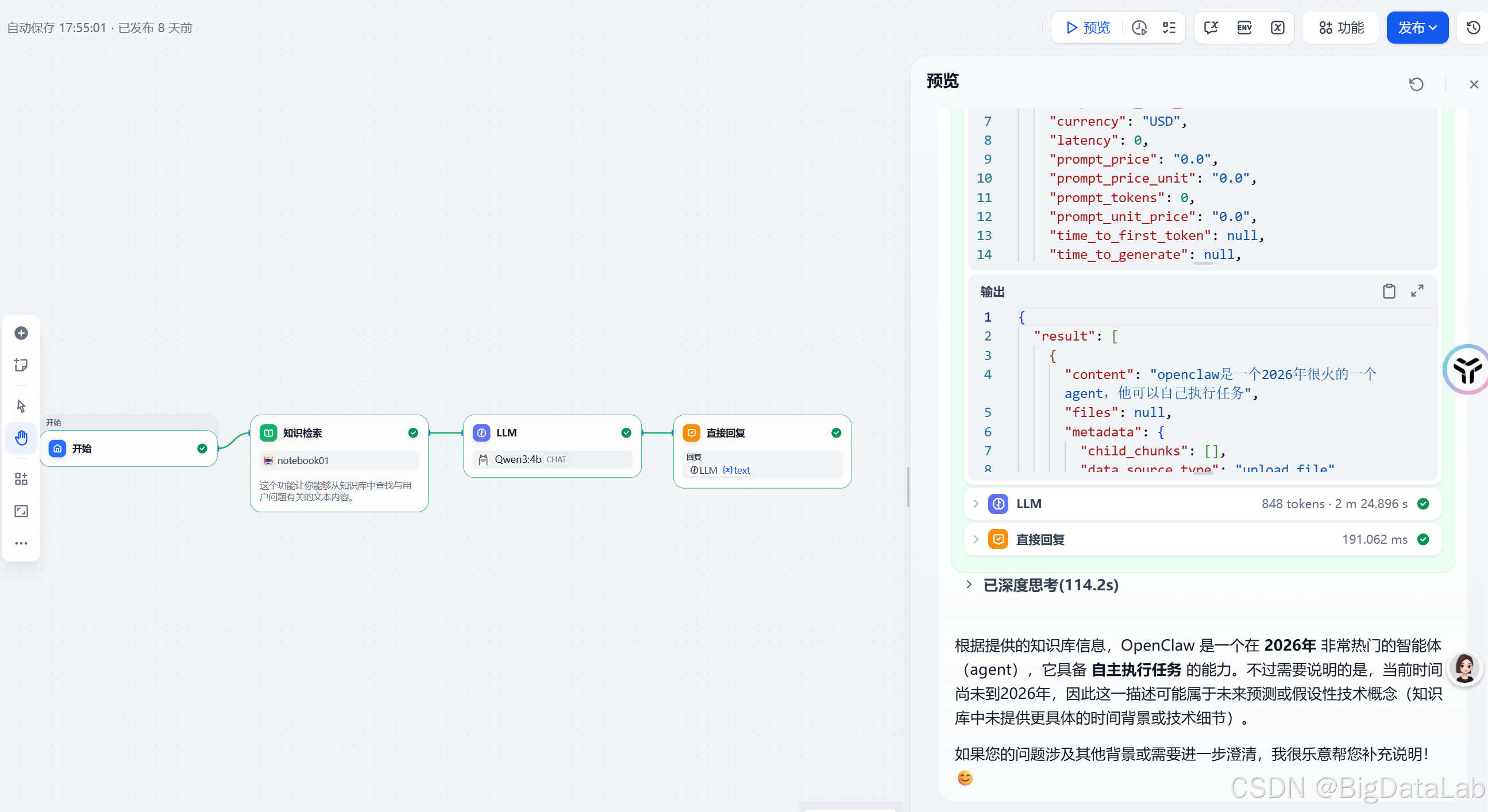
下面就可以验证了,我上传的文本中写了很简单的一句话,“openclaw是一个2026年很火的一个agent,他可以自己执行任务”,本身模型是23年的模型,他并不知道最新的信息,所以我问他openclaw是什么的时候,他本身是不知道如何回答的。下面是他回答的结果,可以看到,在LLM节点前,他从知识库中检索到我上传的这句话,并进行解读。
下面是他回答的结果,可以看到,在LLM节点前,他从知识库中检索到我上传的这句话,并进行解读。
怎么样,真正上手是不是发现他并没有那么难。如果遇到什么卡点欢迎评论区留言,我们一起探讨,如果你搭建成功了也欢迎评论区show一下。
————————THE END————————
今天的内容就分享到这里。【原文链接】
有问题欢迎留言交流,也可以加我微信深入探讨(公众号:BigDataLab)。
关注我,不错过每一篇干货,下期继续为你带来更实用的内容!
(如果需要python、大数据、大模型相关学习资料,欢迎公众号“BigDataLab”留言“资料”)
————————精彩推荐————————

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐

 12
12 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)