Gemini 真的最懂你?先看这套评测:中科大×NUS 的真实场景准则
点击蓝字

关注我们
AI TIME欢迎每一位AI爱好者的加入!
AlpsBench:大模型个性化终身服务的评测新基准
随着大型语言模型的长上下文理解和自我进化能力不断提升,大模型正逐渐从即时性的通用工具,演变为能够提供终身服务的个性化 AI 助手。然而,如何有效评估大模型的个性化记忆与偏好对齐能力,成为了当前学术界的一大瓶颈。
现有的个性化评测基准普遍存在显著局限:
“无记忆过程”的评测(如 LaMP):直接将历史记录作为上下文,忽略了个性化信息的提取与治理过程。
“感知记忆”的评测(如 LoCoMo):高度依赖大模型合成的对话数据。由于真实人类对话充满隐式表达和多样性,合成数据往往过于简单直接,导致评测结果与真实世界存在严重分布差异。
为了弥补这一鸿沟,中国科学技术大学,新加坡国立大学研究团队发表了最新研究成果:AlpsBench: An LLM Personalization Benchmark for Real-Dialogue Memorization and Preference Alignment。该工作提出了一个覆盖记忆管理全生命周期的系统性评测框架,为个性化大模型的研究提供了重要的方法论支撑。
📄 论文信息
-
论文标题:AlpsBench: An LLM Personalization Benchmark for Real-Dialogue Memorization and Preference Alignment
-
论文链接:
https://github.com/ThisIsCosine/AlpsBench/blob/main/paper/PersonalizationBench__Arxiv.pdf
-
项目主页:
https://misshsiaoo.github.io/Alps_Bench/Github
-
仓库:
https://github.com/ThisIsCosine/AlpsBench
数据集构建:立足真实长程对话
AlpsBench 的数据集构建遵循严谨的四阶段流程:
-
数据采集:基于WildChat真实对话集,筛选出对话轮次在6 至 249 轮之间的长程交互数据,以确保上下文信息的丰富性。
-
记忆提取:利用DeepSeek-v3.2推理模型自动提取结构化记忆条目,并重点针对用户偏好等隐性个性化信号进行分类过滤,以增强基准的挑战性。
-
人工校验:邀请具备一年以上相关领域经验的资深从业者对提取出的记忆进行逐一修正,最终形成了包含2,500 组样本的高质量基准数据。
-
任务构建:基于验证后的记忆,利用GPT-5.2自动构建并经人工质检,形成了涵盖信息提取、更新、检索及利用四个维度的评测任务,完整覆盖了个性化信息的全生命周期管理。

四大核心任务
AlpsBench 将大模型的个性化能力拆解为四个核心任务:提取(Extraction)、更新(Update)、检索(Retrieval)与利用(Utilization)。
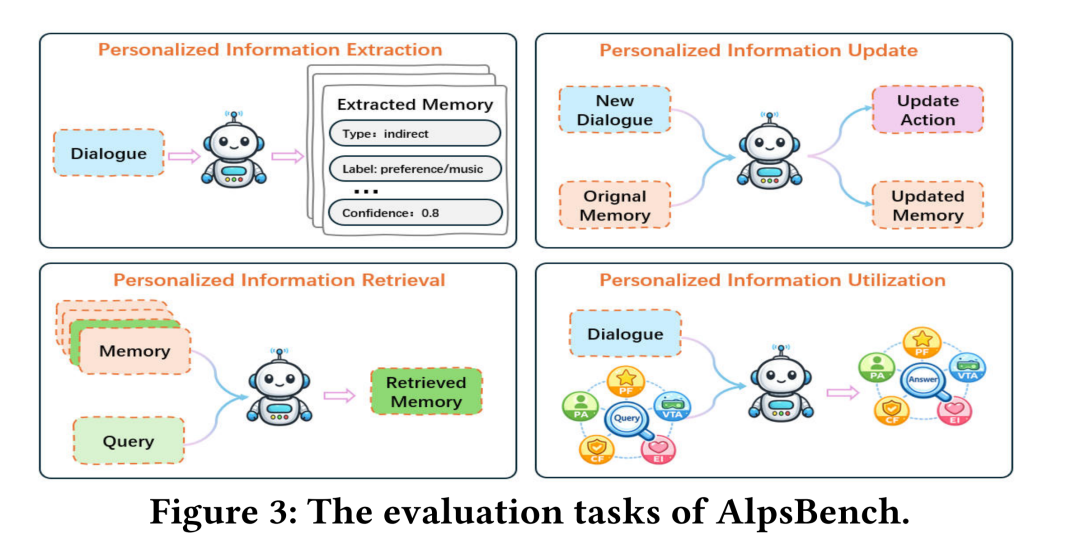
4 Evaluted Tasks in AlpsBench :
Personalized Memory
Extraction, Updating,
Retrieval and Usage
实证发现
研究团队对当前的前沿通用大模型(如 GPT-5.2, DeepSeek-v3.2, Gemini-3-Flash)以及记忆导向系统(如 Mem0, EverMemOS 等)进行了全面评测。实验结果如下表所示:
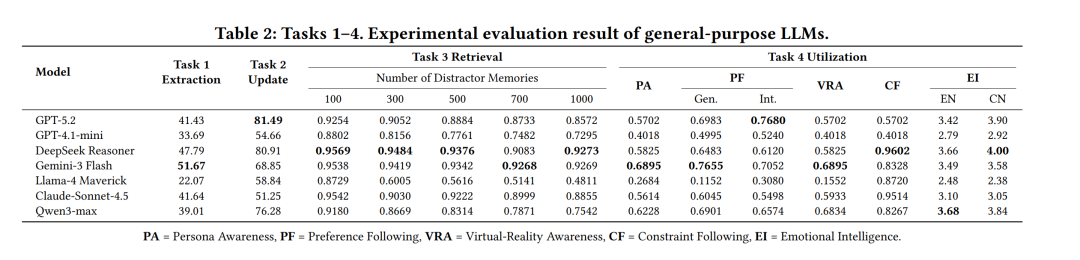
实验结果揭示了当前 LLM 在个性化任务中的多个关键缺陷:
任务一:个性化信息提取(Personalized Information Extraction)
-
任务定义:要求模型从原始且未经处理的长对话历史中,提炼出结构化的用户关键信息与偏好 。
-
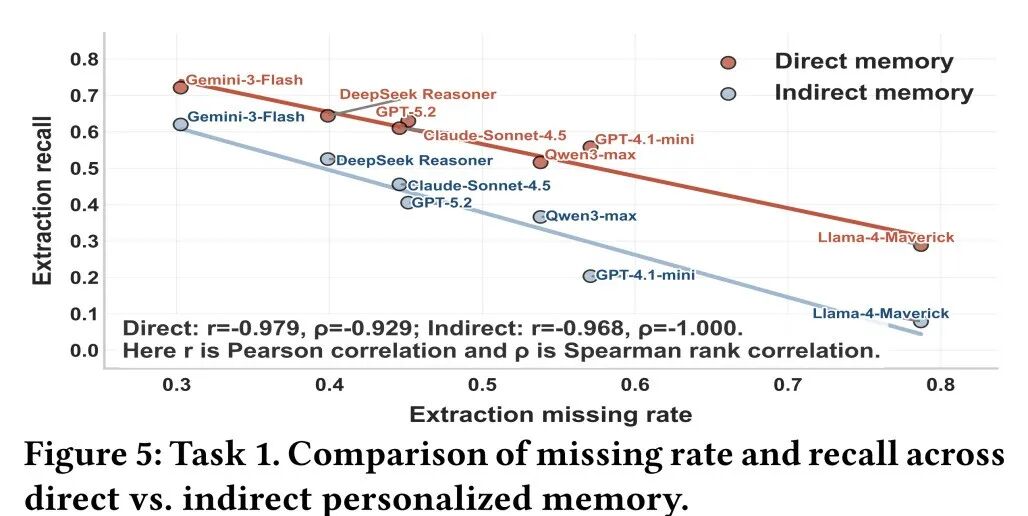
核心发现(通用大模型):大模型在提取 隐式用户特征(Latent user traits)时存在严重不足 。实验表明,即便是表现最优的 Gemini-3 Flash,提取准确率也仅为 51.67%,而 Llama-4 更是低至 22.07% 。研究发现,面对间接表达时,模型的“提取漏报率”显著上升,这是导致模型无法建立有效长期记忆的根本原因 。
-
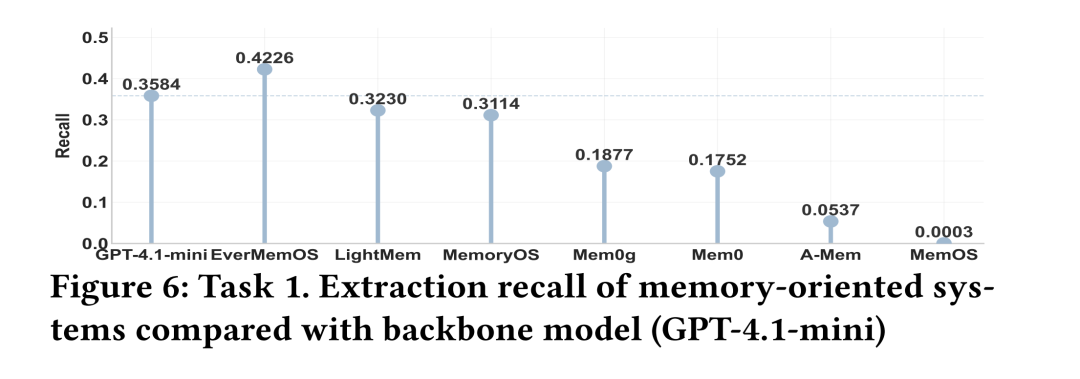
核心发现(记忆导向系统):针对专门的记忆系统(如 Mem0等)进行测试,实验发现部分记忆系统对于个性化记忆的提取召回率甚至 低于其背座模型(如 GPT-4.1-mini)。这反映了当前系统普遍存在“存储策略偏差”:它们往往倾向于无差别地记录所有对话内容(即“全量存储”),而缺乏对个性化相关信息的精准过滤与优先级筛选,导致提取效率与准确性受限 。
任务二:个性化信息更新(Personalized Information Update)
● 任务定义:用户的偏好是动态演变的。该任务要求模型面对新对话时,能够准确判断对旧记忆执行何种操作(保留、追加或修改/解决冲突)。
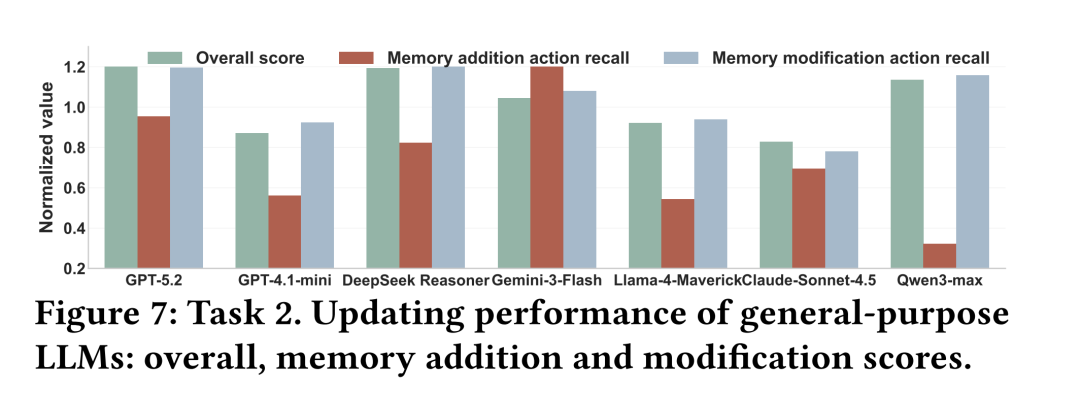
● 核心发现:记忆更新能力存在明显的性能天花板。即使是最强大的 GPT-5.2,在该任务上的准确率也仅达到 81.49% 。更重要的是,模型在“追加新记忆”和“修改冲突记忆”上的表现呈现出明显的不一致性,这表明当前大模型尚未形成处理动态记忆演变和冲突解决的统一内在逻辑。
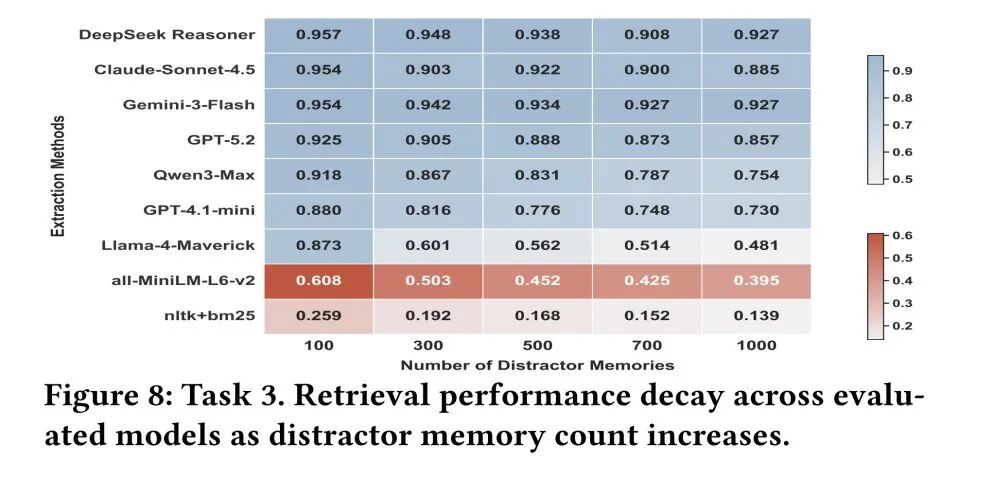
任务三:个性化信息检索(Personalized Information Retrieval)
● 任务定义:在包含大量干扰记忆的候选池中,根据用户查询精准召回相关的个性化记忆。
● 核心发现:随着干扰记忆数量的增加(从 100 增加到 1000),通用大模型和传统检索方法的性能差异急剧扩大。特别值得注意的是,常用于外部记忆挂载的经典语义级检索方法(如 nltk+BM25 和 all-MiniLM-L6-v2)在面临高密度噪音时遭遇了断崖式崩溃(准确率分别骤降至 0.14 和 0.40) 。这证明了简单的“即插即用”检索模块根本无法胜任复杂的长期个性化任务,学术界亟需开发具备逻辑感知能力的轻量级检索架构。
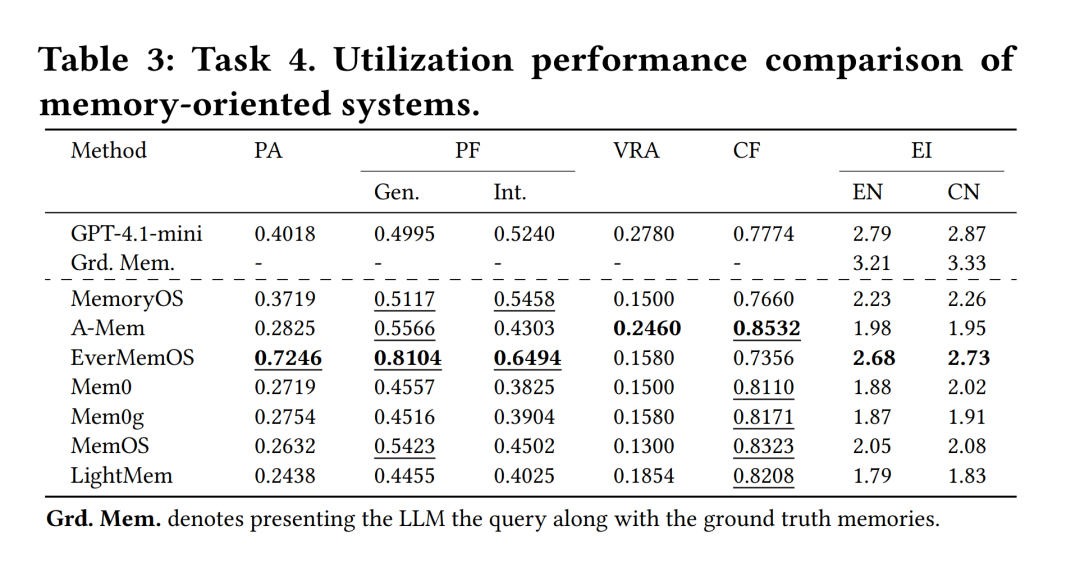
任务四:个性化信息利用(Personalized Information Utilization)
● 任务定义:将检索到的记忆应用于生成最终回复。AlpsBench 设计了 5 个细粒度的评估维度:角色感知 (PA)、偏好遵循 (PF)、虚拟现实感知 (VRA)、约束遵循 (CF) 和情商 (EI) 。
● 核心发现:评测显示,引入外挂的显式记忆机制虽然能提高模型对偏好和设定的召回率,但并不能必然保证回复具备更高的情商或偏好对齐度。由于不同模型在五个维度上的表现高度碎片化(例如 Gemini-3 在角色感知上最佳,而 DeepSeek 在约束遵循上表现最强),当前的系统在平衡“执行任务约束”与“维持高情商交互”之间仍面临巨大挑战。
研究意义与未来展望
AlpsBench 提供了一个全面、动态的诊断框架,揭示了将大模型直接部署为长期个性化 Agent 所面临的底层认知缺陷:大模型难以可靠地提取隐式偏好、记忆更新存在瓶颈,且在重度噪音干扰下的检索极其脆弱。
该论文指出,未来的 LLM 个性化研究不能仅停留在下游任务的结果对齐,而应深入到记忆治理的全生命周期中,开发更具鲁棒性的抗噪检索模型与兼顾情商的上下文利用策略。
为方便社区进一步验证和扩展本研究,AlpsBench 的完整测评框架与数据集已开源。研究者和开发者可通过以下链接获取相应资源:
-
测评框架(GitHub):https://github.com/ThisIsCosine/AlpsBenc
-
标准化数据集(Hugging Face):https://huggingface.co/datasets/Cosineyx/Alpsbench
往期精彩文章推荐

关于AI TIME
AI TIME源起于2019年,旨在发扬科学思辨精神,邀请各界人士对人工智能理论、算法和场景应用的本质问题进行探索,加强思想碰撞,链接全球AI学者、行业专家和爱好者,希望以辩论的形式,探讨人工智能和人类未来之间的矛盾,探索人工智能领域的未来。
迄今为止,AI TIME已经邀请了2000多位海内外讲者,举办了逾800场活动,超1000万人次观看。

我知道你
在看
提出观点,表达想法,欢迎
留言

点击 阅读原文 进入官网查看更多!

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐



 0
0 0
0- 0



 已为社区贡献19条内容
已为社区贡献19条内容

所有评论(0)