一个人不够,那就开八场会——Multi-Head Attention 图解
一、先回顾:单头 Attention 的局限
还是这句话:
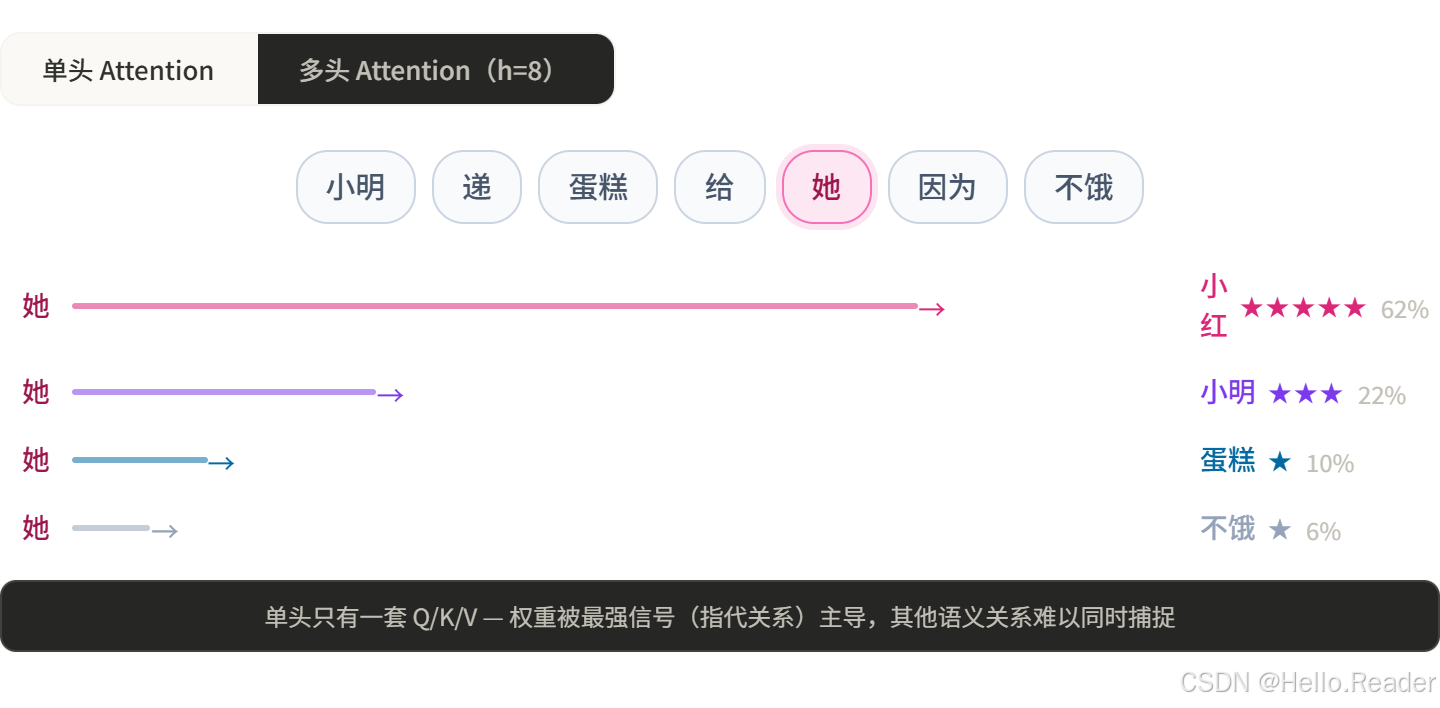
“小明把蛋糕递给小红,因为她不饿了。”
单头 Attention 在处理"她"时,会去找最相关的词——找到"小红",很好。
但这句话其实同时包含好几层关系:
- 指代关系:“她” → “小红”
- 动作关系:“递” → “小明”(谁在递)、“小红”(递给谁)
- 因果关系:“因为” → "不饿了"解释了为什么递给她
- 语义关系:“蛋糕” 和 “吃” 在语义上天然接近
单头 Attention 只有一套 Q/K/V,一次只能主要关注一种关系。就像你开会只带了一个问题,其他维度就顾不上了。
二、Multi-Head:同时开 8 场会
Multi-Head Attention 的思路极其简单:
与其用一套 Q/K/V 做一次 Attention,不如用 h 套不同的 Q/K/V 同时做 h 次,每次关注不同的语义维度,最后把结果合并。
用开会类比:
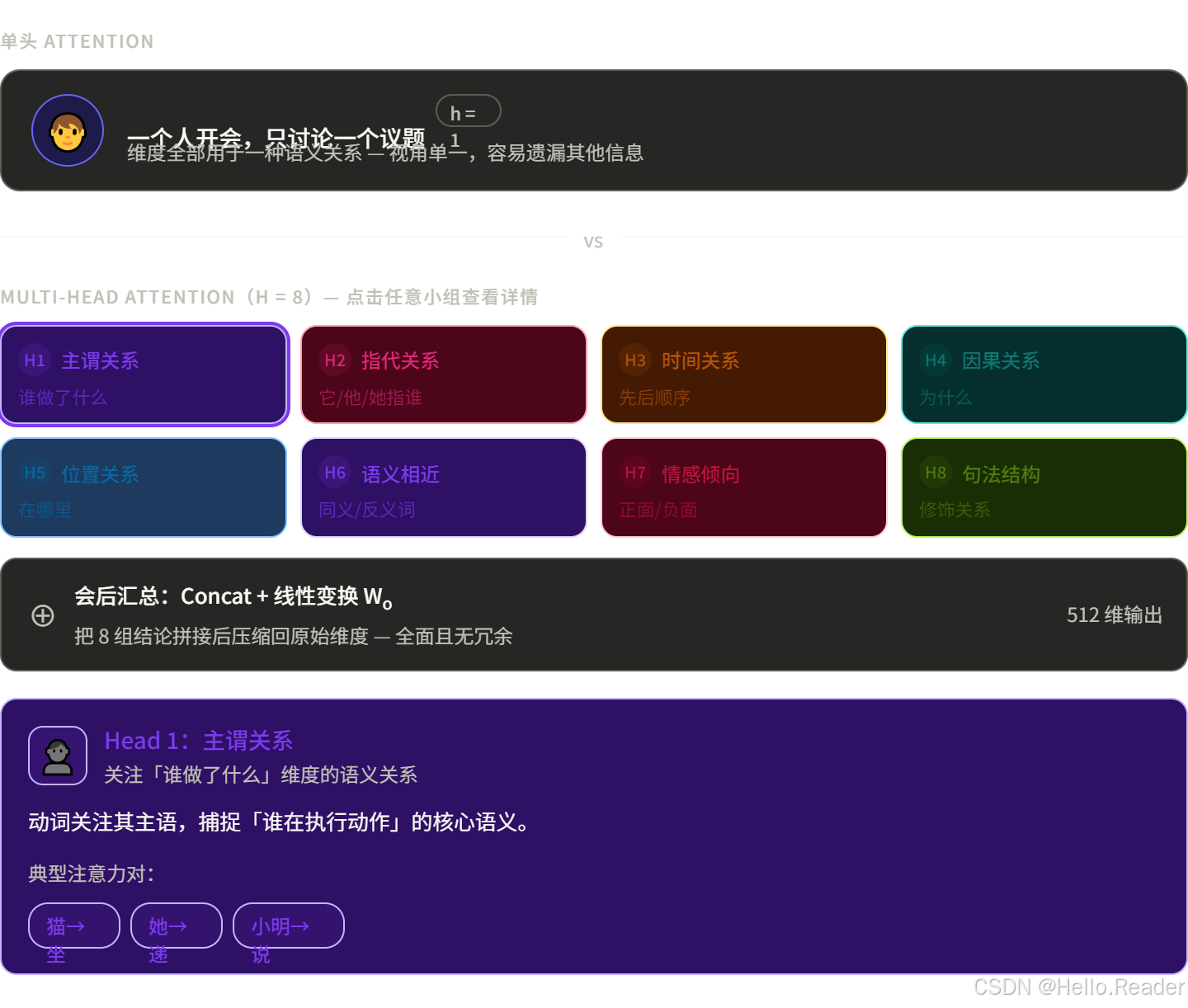
注意:每个小组用的是不同的权重矩阵,所以它们学到的关系是不同的。模型不会提前规定每组负责什么——这些分工是训练时自动学会的。
三、数学上是怎么做的?
不用怕,就三步:
Step 1:把维度切小,分给每个头
原来的词向量维度是 ‘ d m o d e l ‘ `d_model` ‘dmodel‘(比如 512 维)。
有 h h h 个头,就把维度平均分:每个头负责 ‘ d k = d m o d e l / h ‘ `d_k = d_model / h` ‘dk=dmodel/h‘ 维(比如 512/8 = 64 维)。
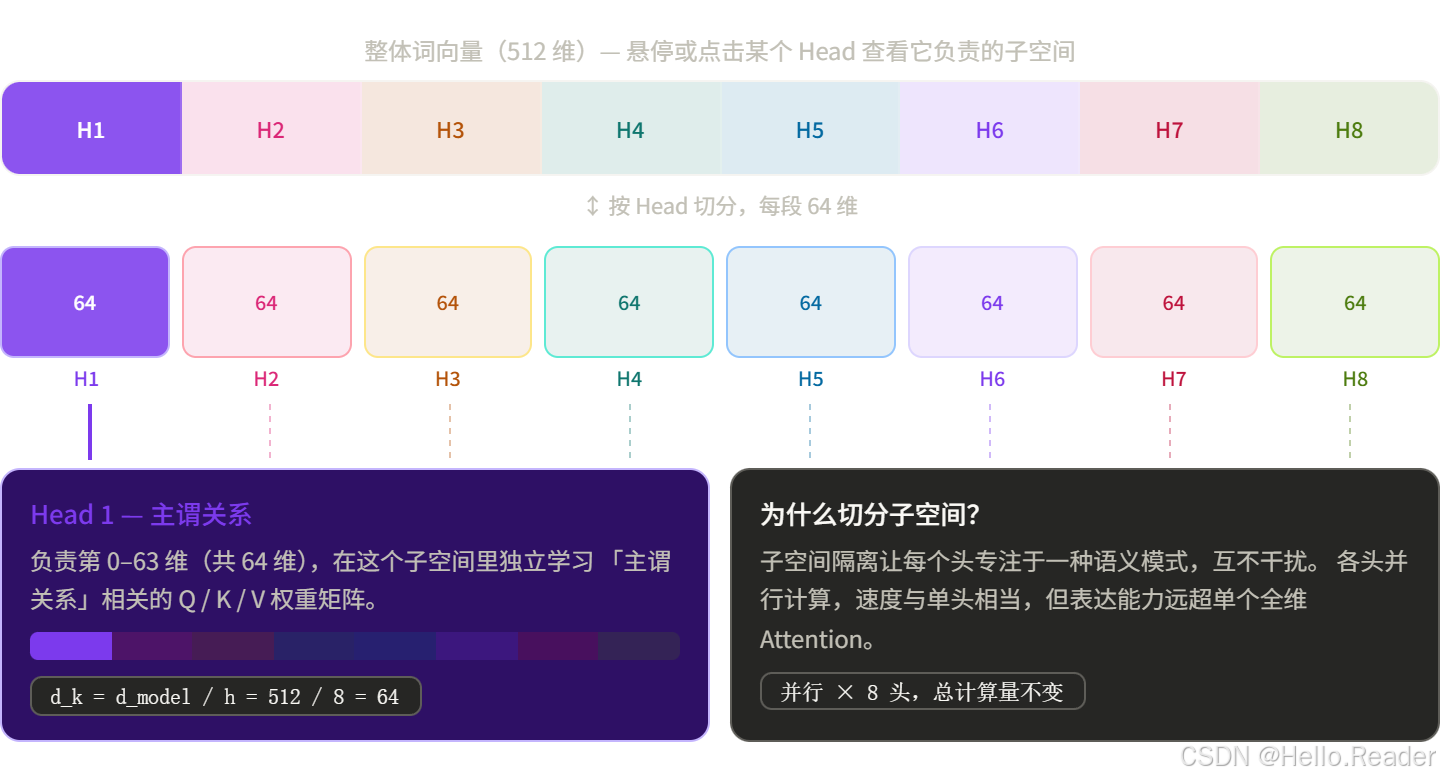
每个头都有自己专属的权重矩阵 W q i 、 W k i 、 W v i Wq_i、Wk_i、Wv_i Wqi、Wki、Wvi,学到的是不同的"视角"。
Step 2:每个头独立做 Attention
每个头各自完整地走一遍 Self-Attention 流程:
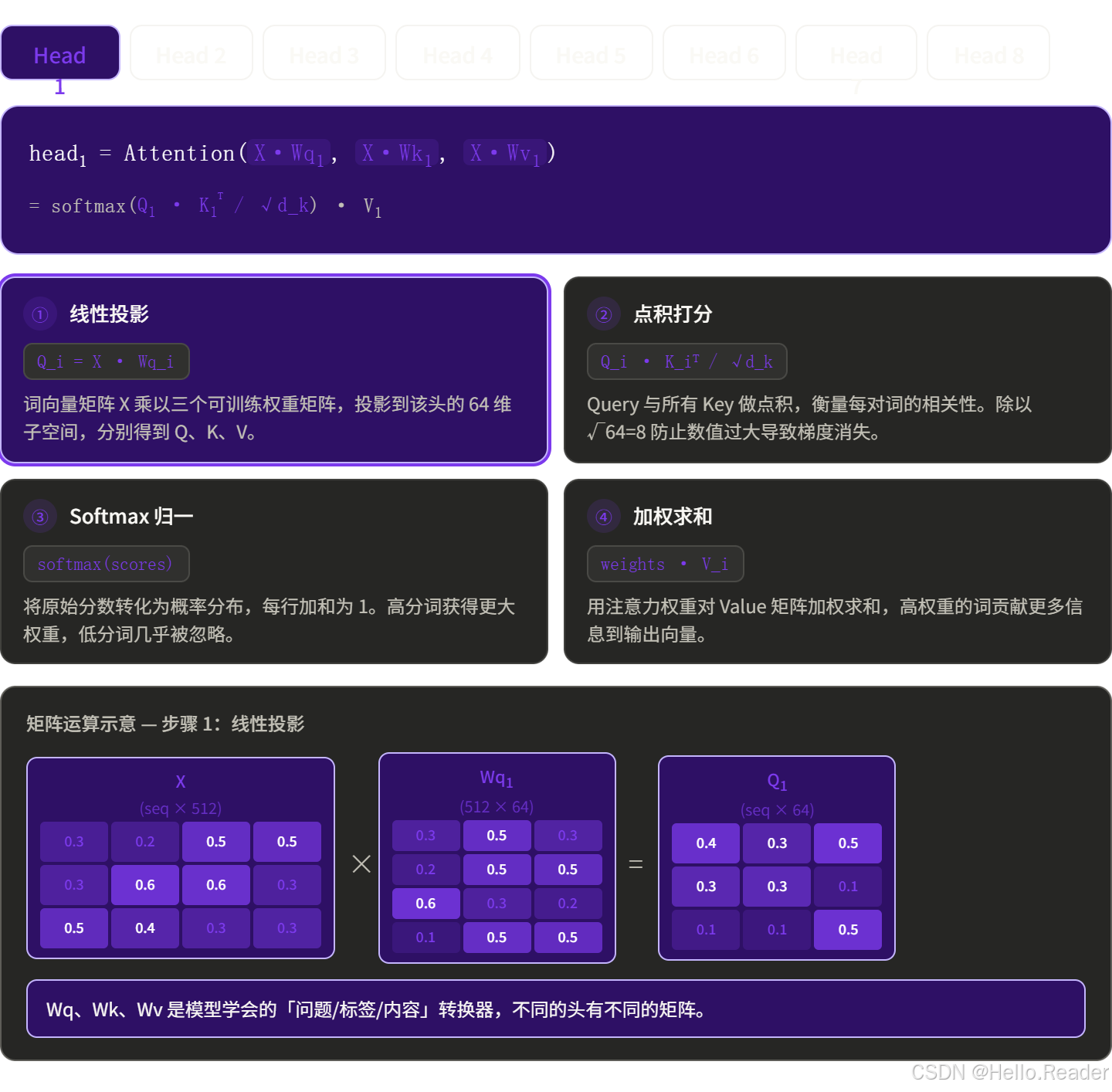
8 个头并行计算,互不干扰,速度和单头一样快。
Step 3:拼接 + 线性变换
把 8 个头的输出横向拼起来,再乘一个输出权重矩阵 Wo,压缩回原始维度: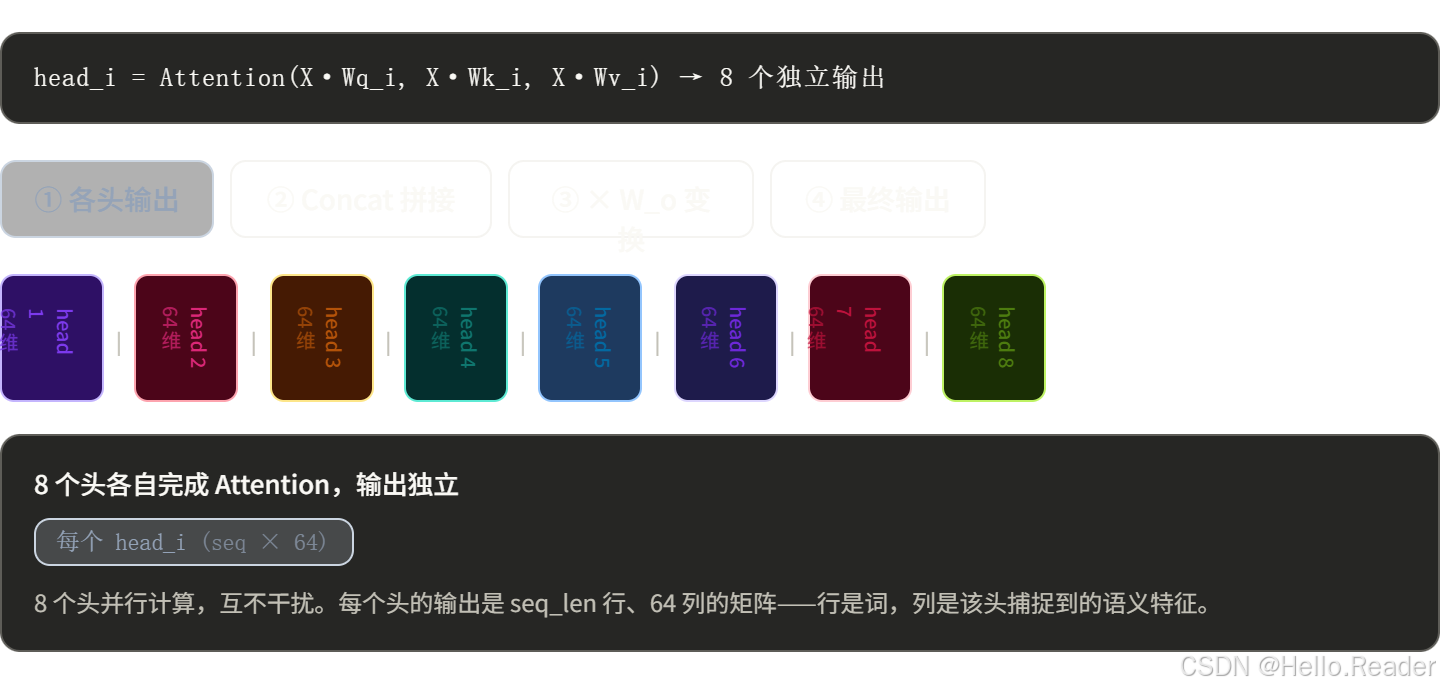
Wo 的作用是让各个头的信息融合,而不只是简单堆叠。
四、用图来看:单头 vs 多头
最终拼接 → 比单头理解更立体、更全面
五、一个更直觉的比喻:摄影师 vs 摄影团队
想象你要拍摄一场婚礼:
单头 Attention = 只有一个摄影师,他只能站在一个位置,拍一个角度。
Multi-Head Attention = 8 个摄影师同时拍:
- 摄影师1 在台上,拍新人表情
- 摄影师2 在观众席,拍宾客反应
- 摄影师3 在门口,拍全景
- 摄影师4 在角落,拍细节装饰
- ……
最后把所有照片剪辑在一起,你对这场婚礼的理解比任何单一角度都完整。
Wo(输出矩阵)就是那个剪辑师——负责把所有素材整合成一个连贯的故事。
六、为什么不直接用一个超大的单头?
合理的问题!既然多头是把维度切小再分配,为什么不直接用一个 512 维的单头做一次超级 Attention?
答案有两点:
1. 子空间隔离,学习更专注
每个头在自己的 64 维子空间里学习,不会被其他类型的关系"干扰"。就像每个小组开独立的会,比所有人挤在一个会议室更高效。
2. 表达能力更强
数学上可以证明,h 个 d_k 维的 Attention 头,能学到的函数族严格包含单个 d_model 维 Attention 能学到的。多头不是冗余,是真的能捕捉到更复杂的模式。
七、真实模型里用了几个头?
| 模型 | 层数 | 注意力头数 | d_model |
|---|---|---|---|
| 原版 Transformer | 6 | 8 | 512 |
| BERT-base | 12 | 12 | 768 |
| BERT-large | 24 | 16 | 1024 |
| GPT-3 | 96 | 96 | 12288 |
| GPT-4(推测) | 120+ | 128+ | 超大 |
头越多,模型能同时关注的语义维度越多——但计算量也同步上升。这是个工程上的权衡。
八、研究者发现了什么有趣的事?
Multi-Head Attention 的各个头真的会"自发分工",研究者通过可视化发现了一些规律:
- 某些头专门负责指代消解:遇到"它""她"时,这些头的注意力几乎全打在先行词上
- 某些头负责句法依存:比如动词和它的主语之间权重特别高
- 某些头关注局部:主要看相邻的 1-2 个词
- 某些头关注全局:权重相对均匀地分布在整个句子
这不是人工设计的,是模型在大量文本上训练后自动涌现的能力,相当神奇。
九、完整流程总结

十、三句话总结
-
Multi-Head = 多视角理解:h 个头同时做 Attention,每个头学到不同类型的语义关系。
-
并行不增加时间:各头独立计算,速度和单头几乎一样,但表达能力强得多。
-
分工是自动学会的:模型训练时自发形成"指代头""句法头"等专业分工,不需要人工指定。
延伸阅读
- 📄 原论文:Attention Is All You Need — Section 3.2.2 专门讲 Multi-Head
- 🔬 可视化工具:BertViz — 可以看到 BERT 每个头在关注什么
- 📝 深入研究:Are Sixteen Heads Really Better than One?(2019)— 探讨哪些头真正重要

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐

 14
14 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)