GPT 每次说话都在“掷骰子“——生成策略图解
一、先理解:GPT 输出的是什么?
每次生成一个词之前,模型会输出一个概率分布——对词表里每一个词打一个分,经过 Softmax 后变成概率。
比如输入"今天天气",模型可能输出:
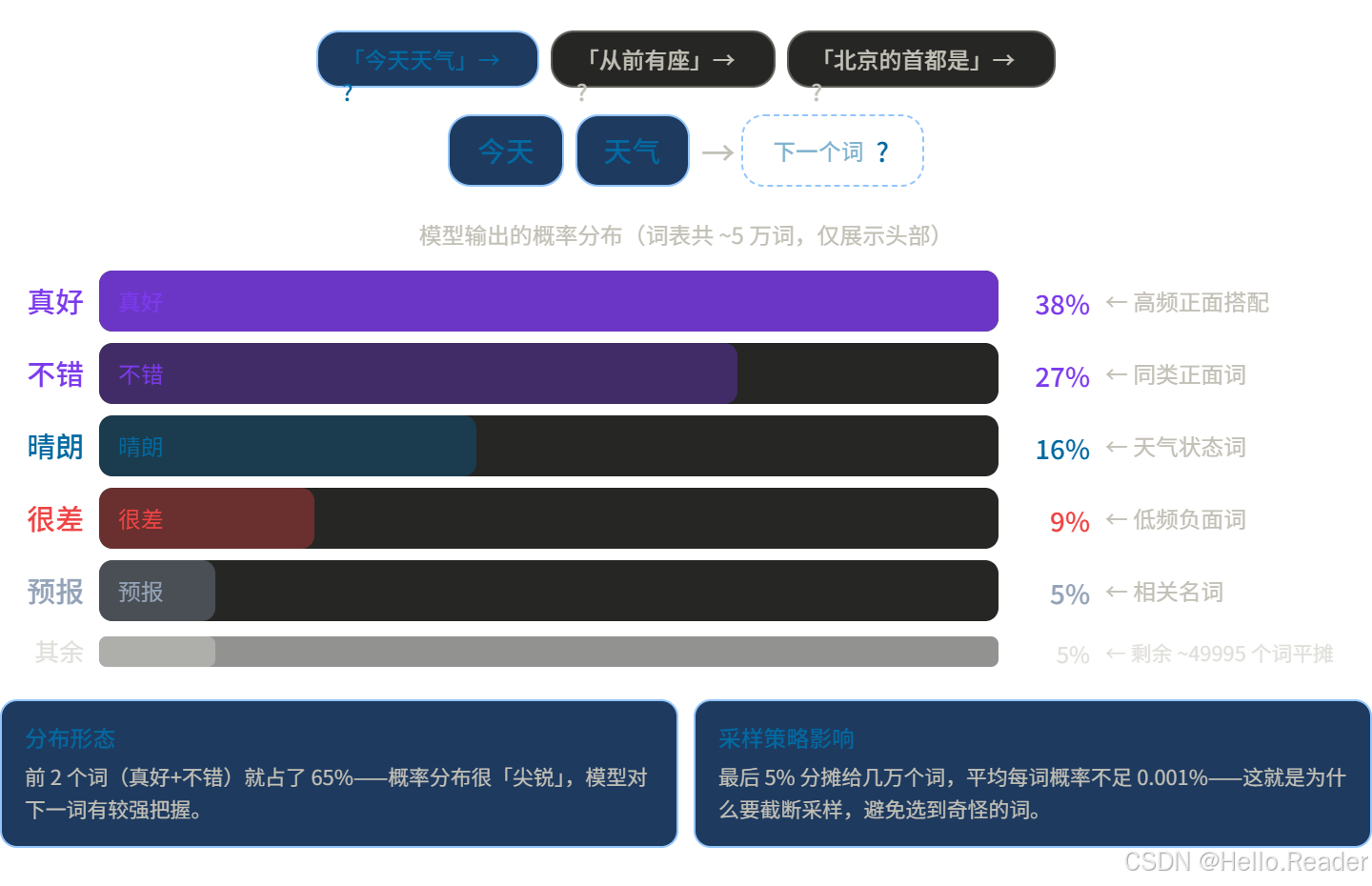
问题来了:拿到这个概率分布,下一步怎么办?
这就是"生成策略"要回答的问题。
二、方法一:贪心搜索(Greedy Search)
思路
每次直接选概率最高的词,不管后面会怎样。
类比
就像你在餐厅点菜,每道菜都点菜单上排第一的。结果:永远点宫保鸡丁、番茄炒蛋、米饭……保证不踩雷,但也永远吃不到惊喜。
优点和缺点
优点:快,确定性强(同样输入永远同样输出)
缺点:容易陷入循环,生成内容重复、呆板
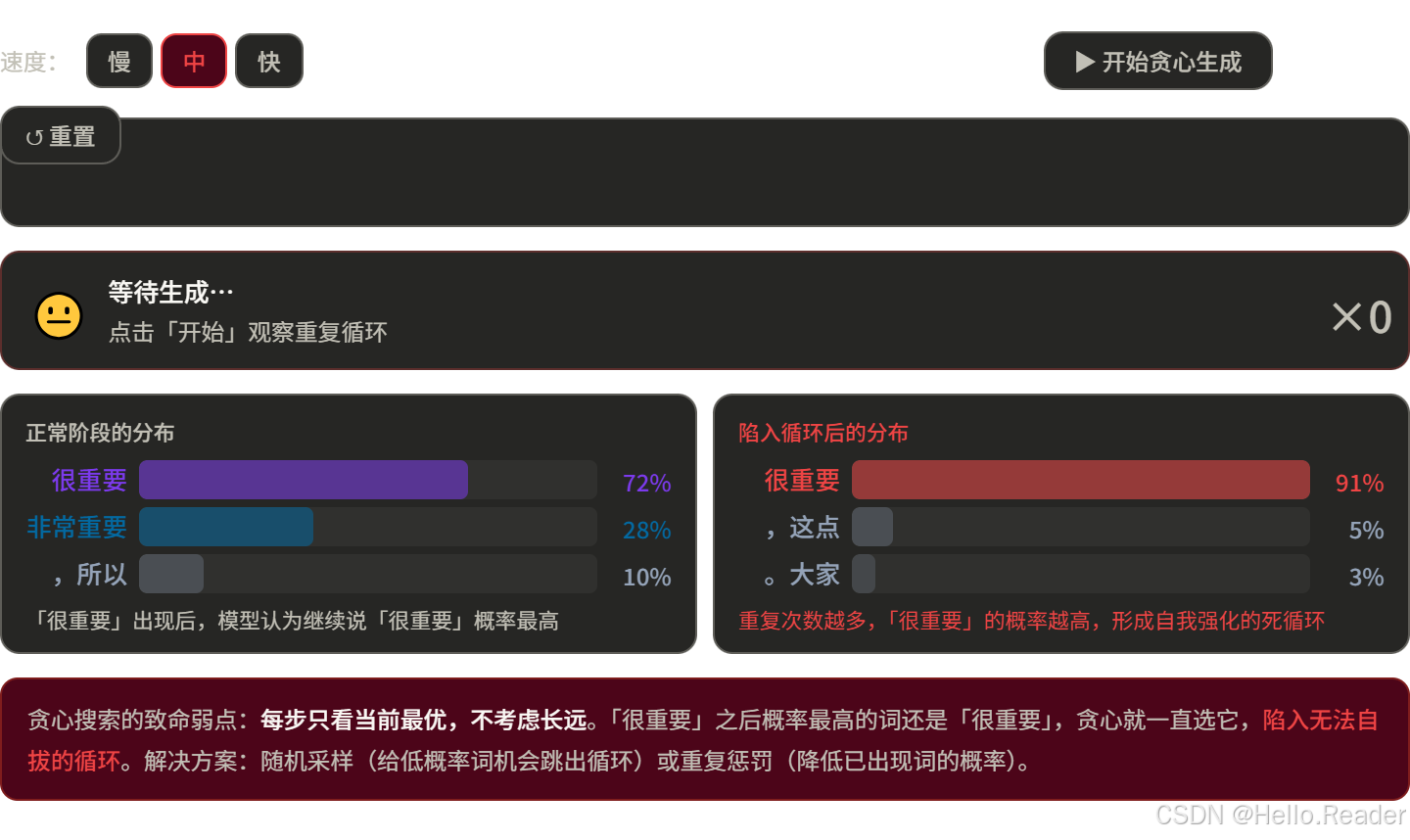
为什么会循环?因为"重要"之后概率最高的词还是"很重要",一直贪心下去就卡死了。
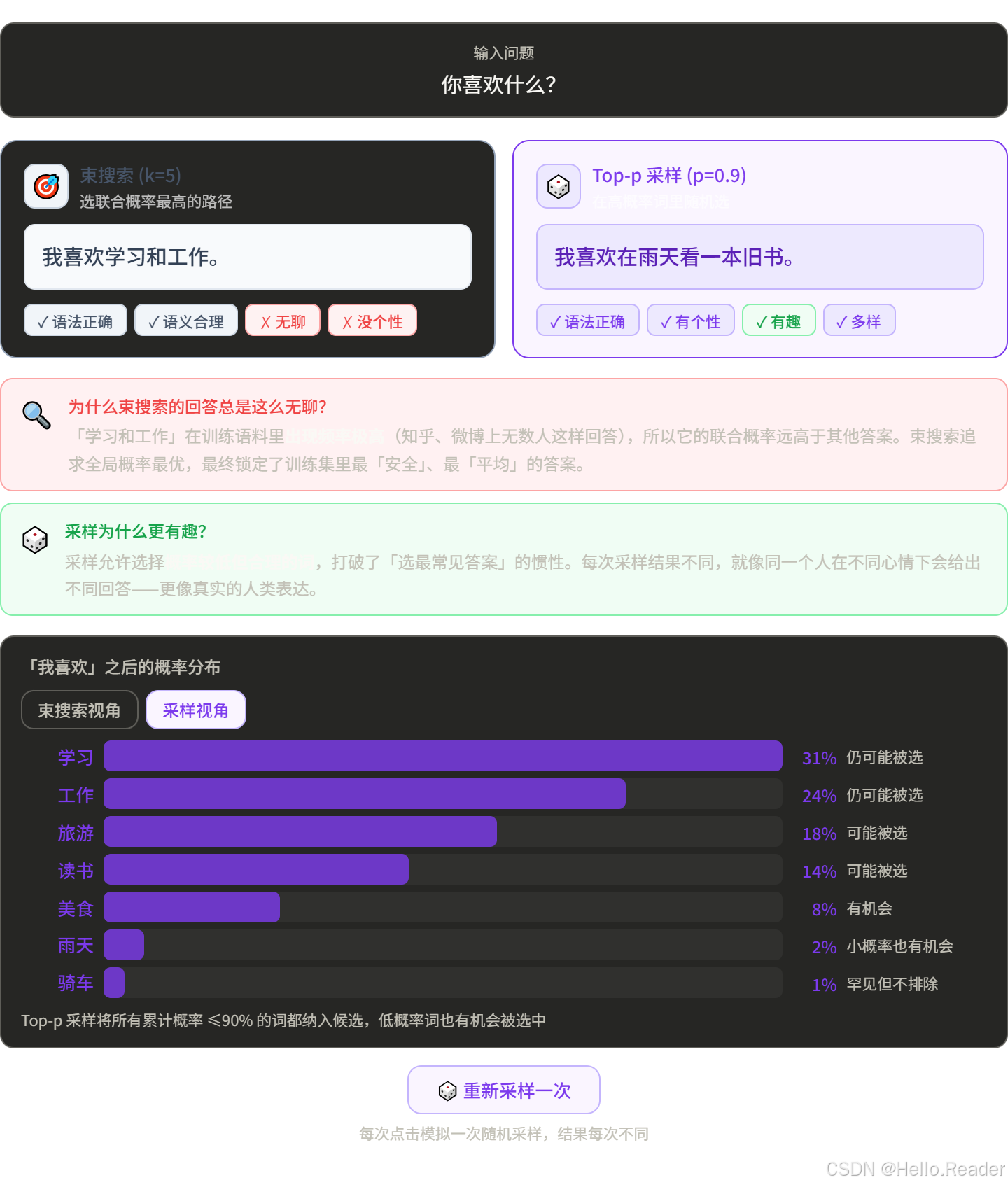
三、方法二:束搜索(Beam Search)
思路
贪心每次只保留 1 条路,束搜索同时保留 k 条最优路径(k 叫"束宽",beam width)。
用 k=3 举例,生成"今天天气"的后续:
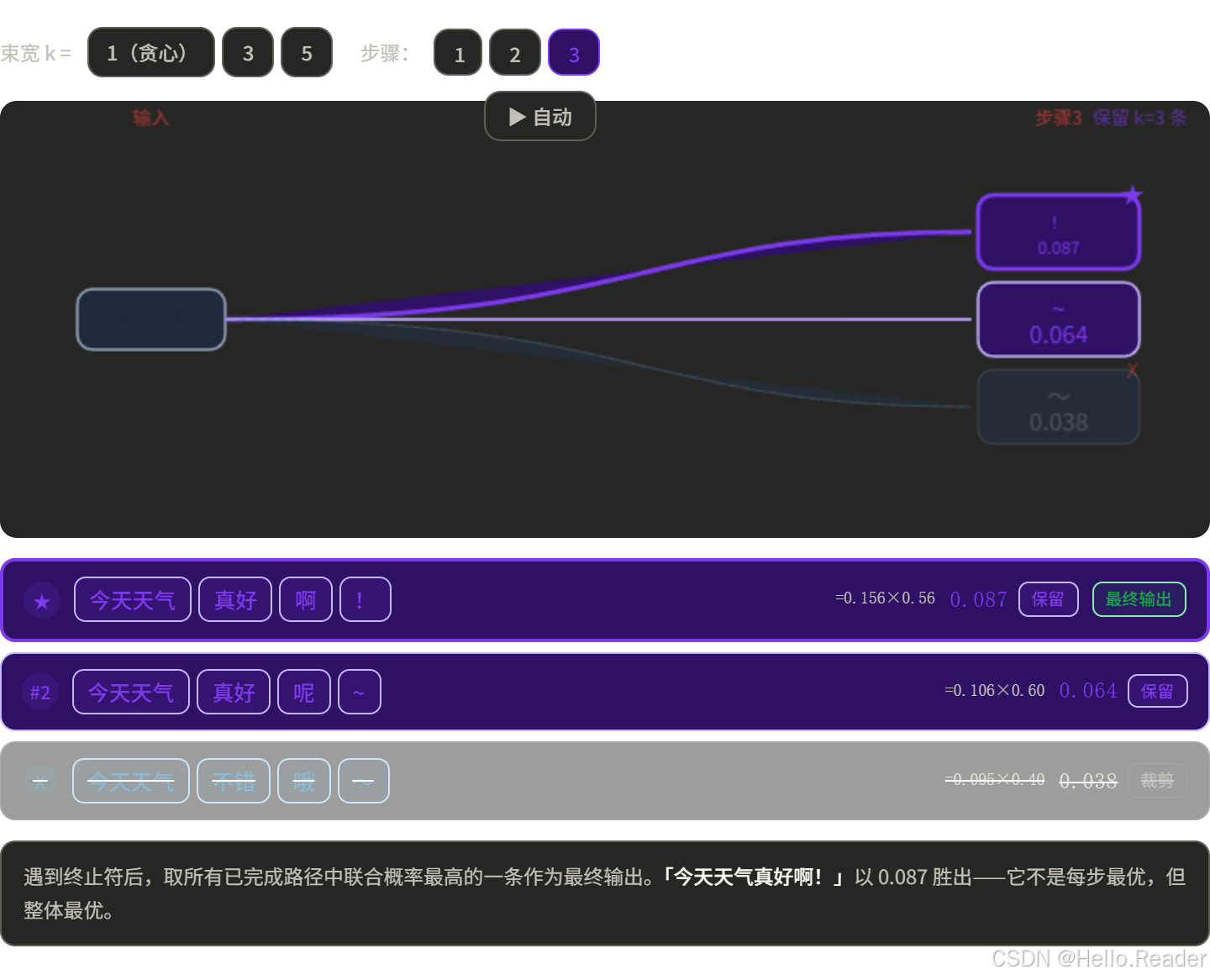
保留最高的 3 条继续
最终选整体概率最高的路径
类比
就像下棋时你不只看当前最好的一步,而是同时推演 3 条支线剧情,最后选整体走法最好的一条。
优点和缺点
优点:比贪心找到更好的完整序列,翻译、摘要任务中效果明显
缺点:
- k 越大计算越慢(每步要维护 k 条路)
- 对话和创作场景中,束搜索生成的文本太正式、太无聊
- 倾向于选"安全"的高概率词,缺乏多样性
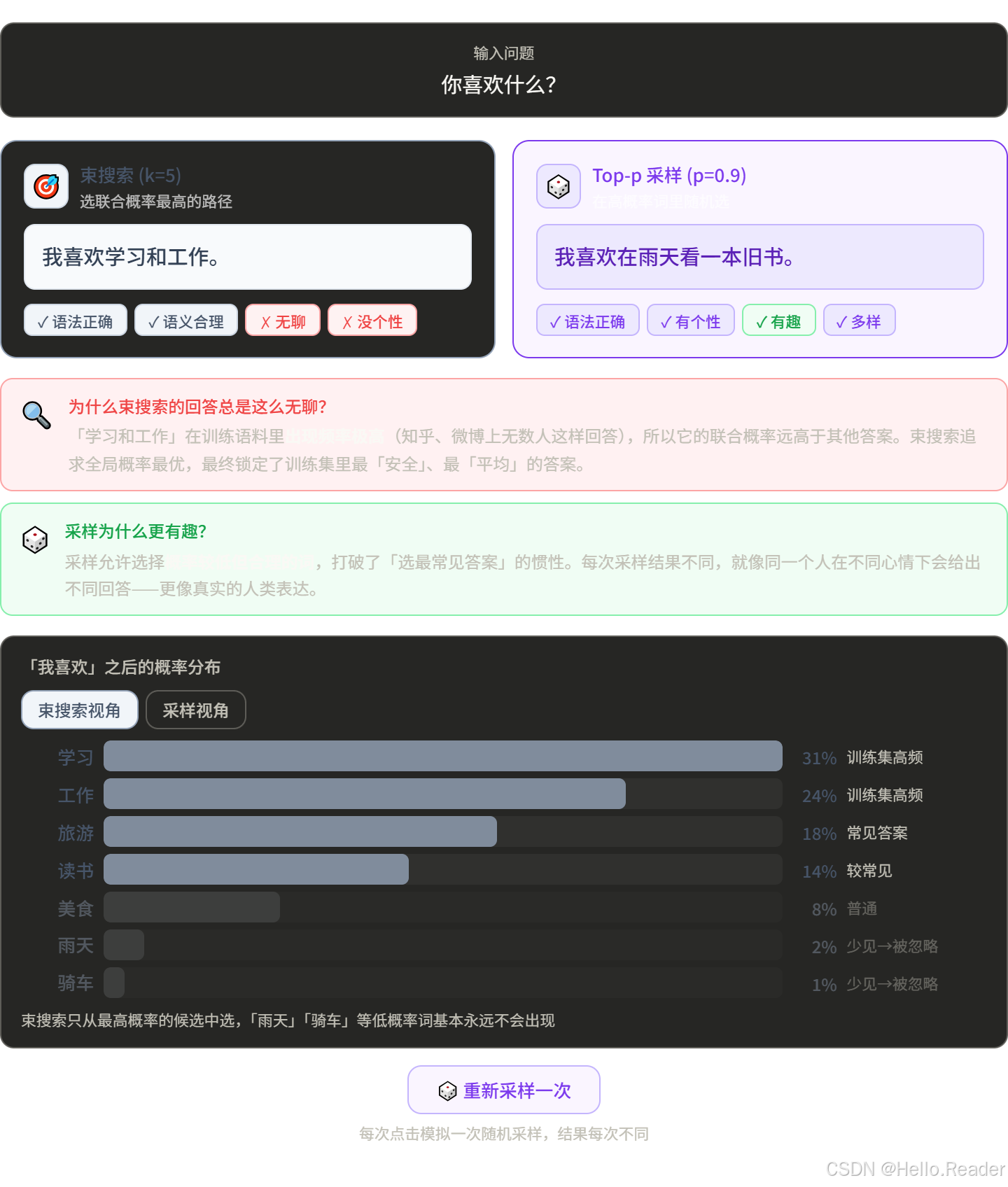
四、方法三:随机采样(Random Sampling)
思路
按概率随机抽取,不总选最高的那个。
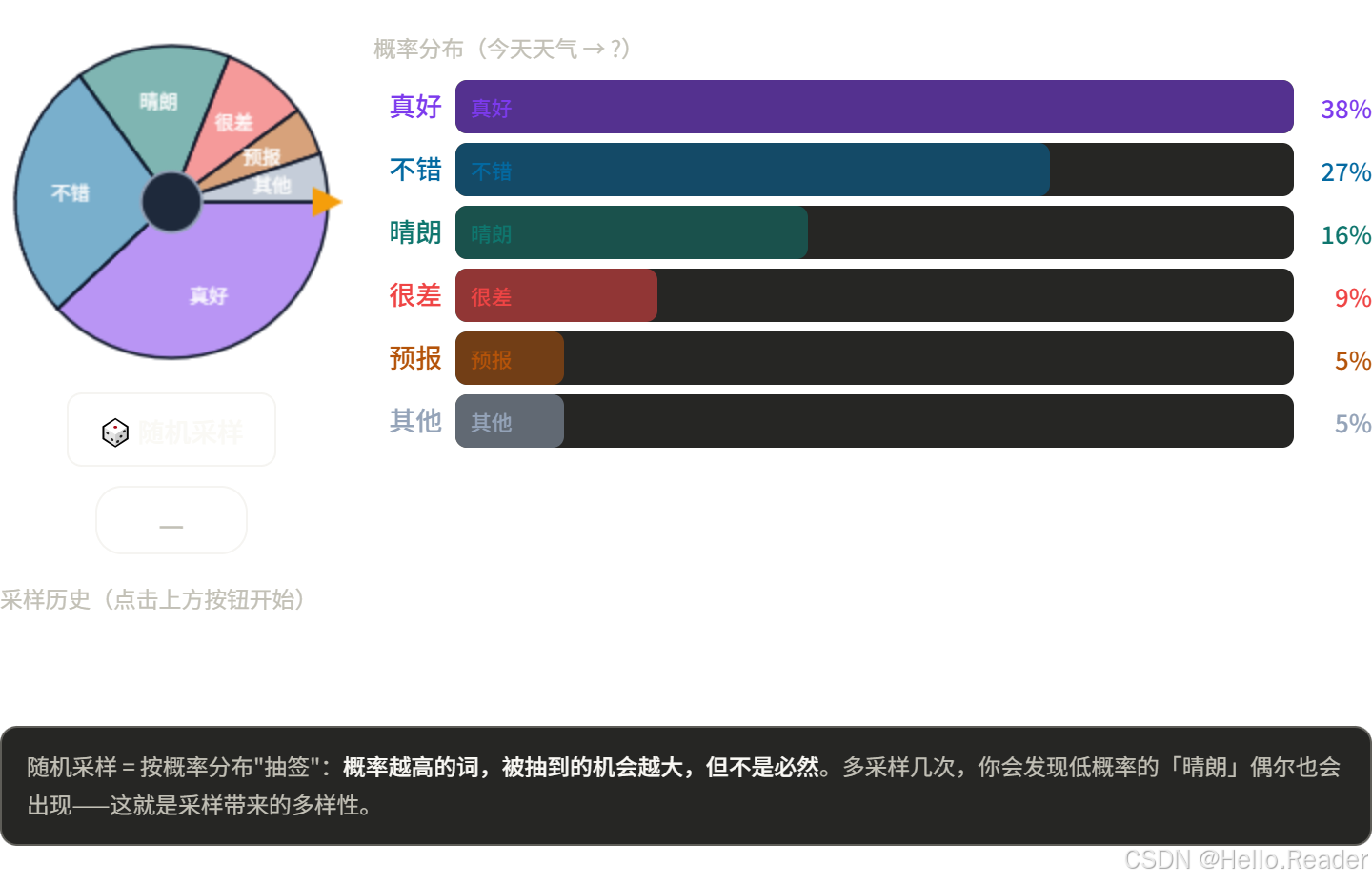
随机采样:可能选"真好",也可能选"晴朗",
甚至小概率选到"很差"
类比
就像转轮盘赌,区域大的(高概率词)更容易被选中,但区域小的也有机会。每次结果不同,充满变数。
优点和缺点
优点:输出多样,有创意,不重复
缺点:有时会选到不合理的低概率词,生成乱七八糟的内容
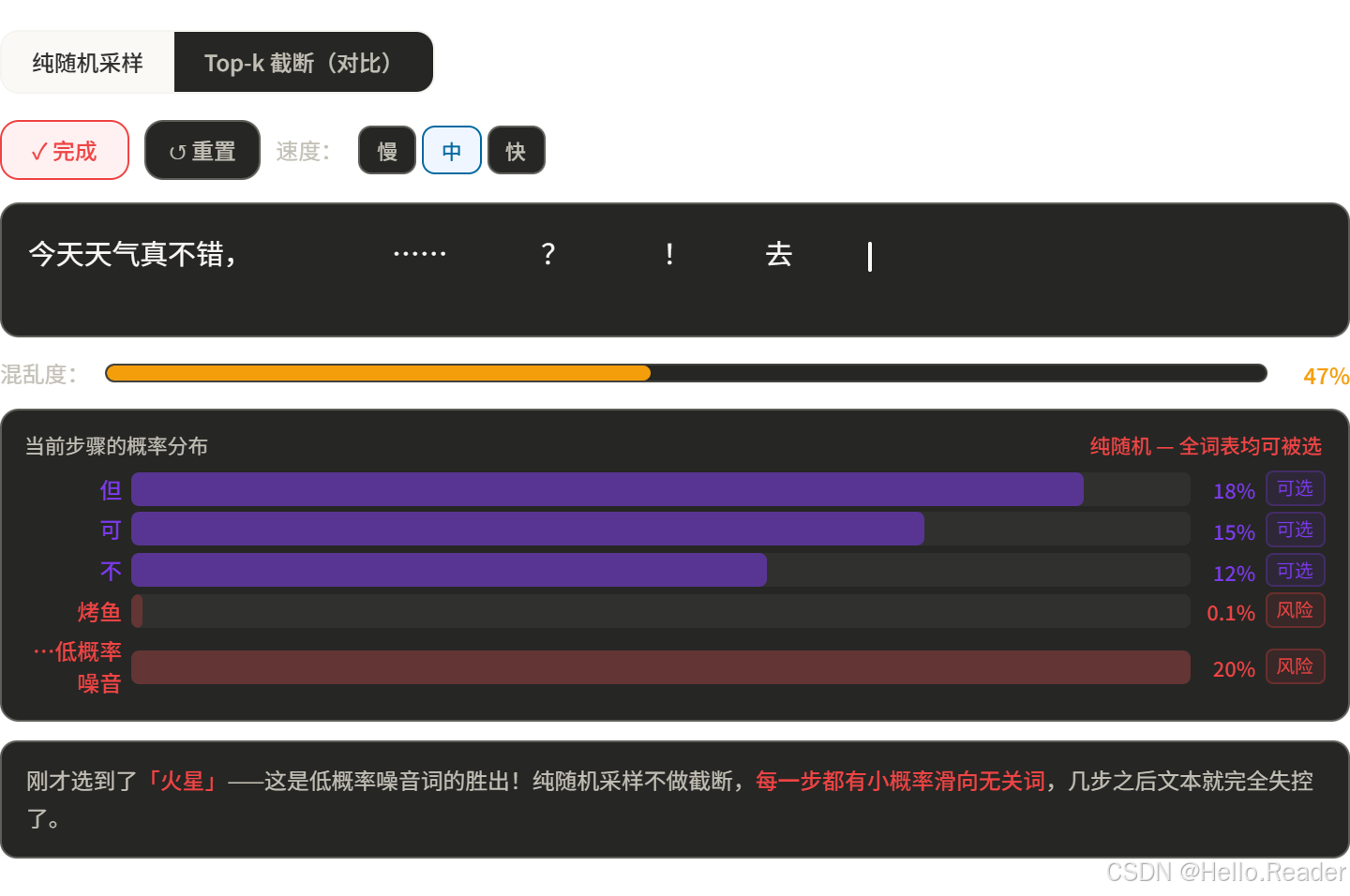
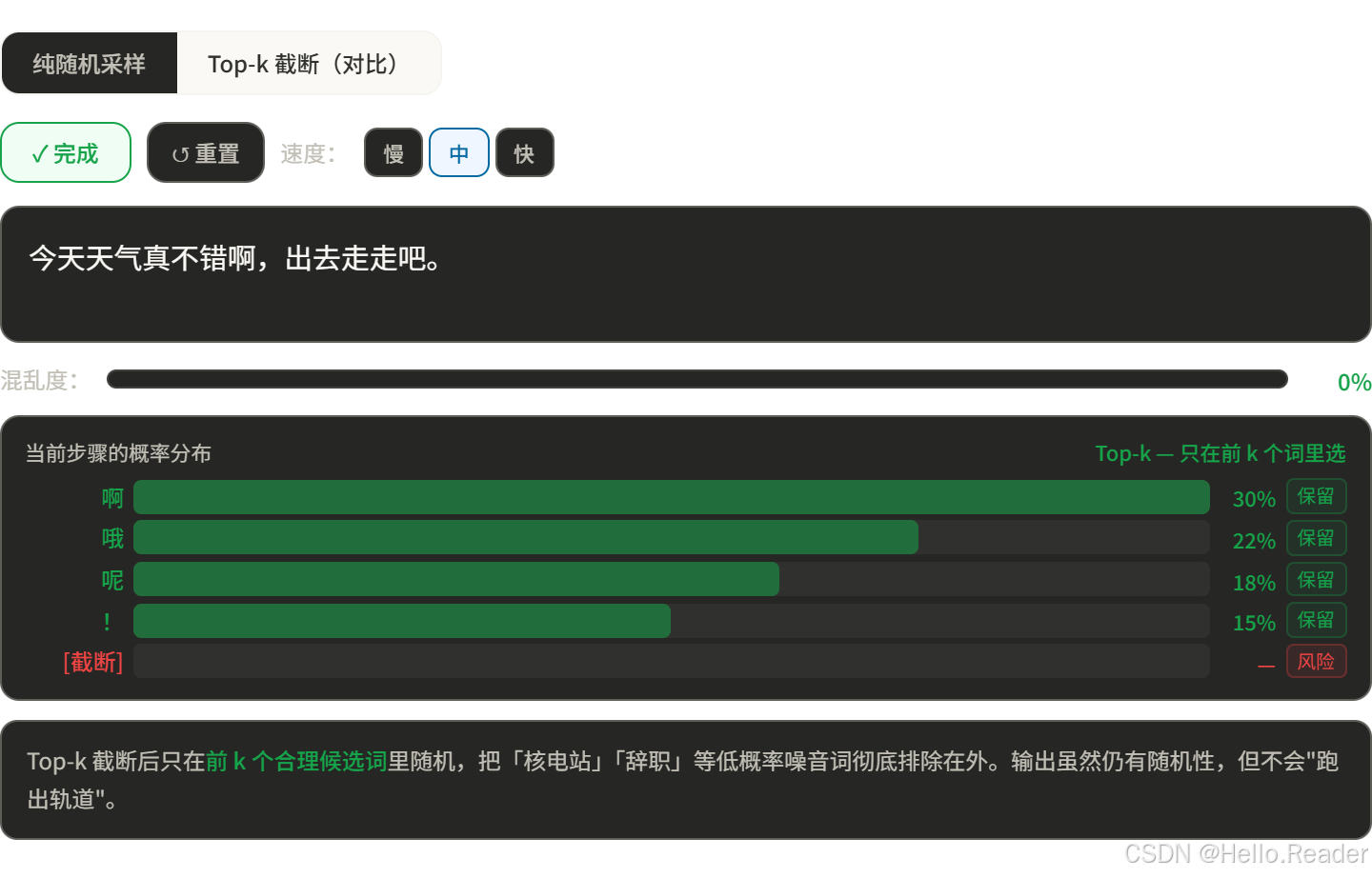
所以直接用随机采样太危险,需要"截断"——只在合理的候选词里随机。
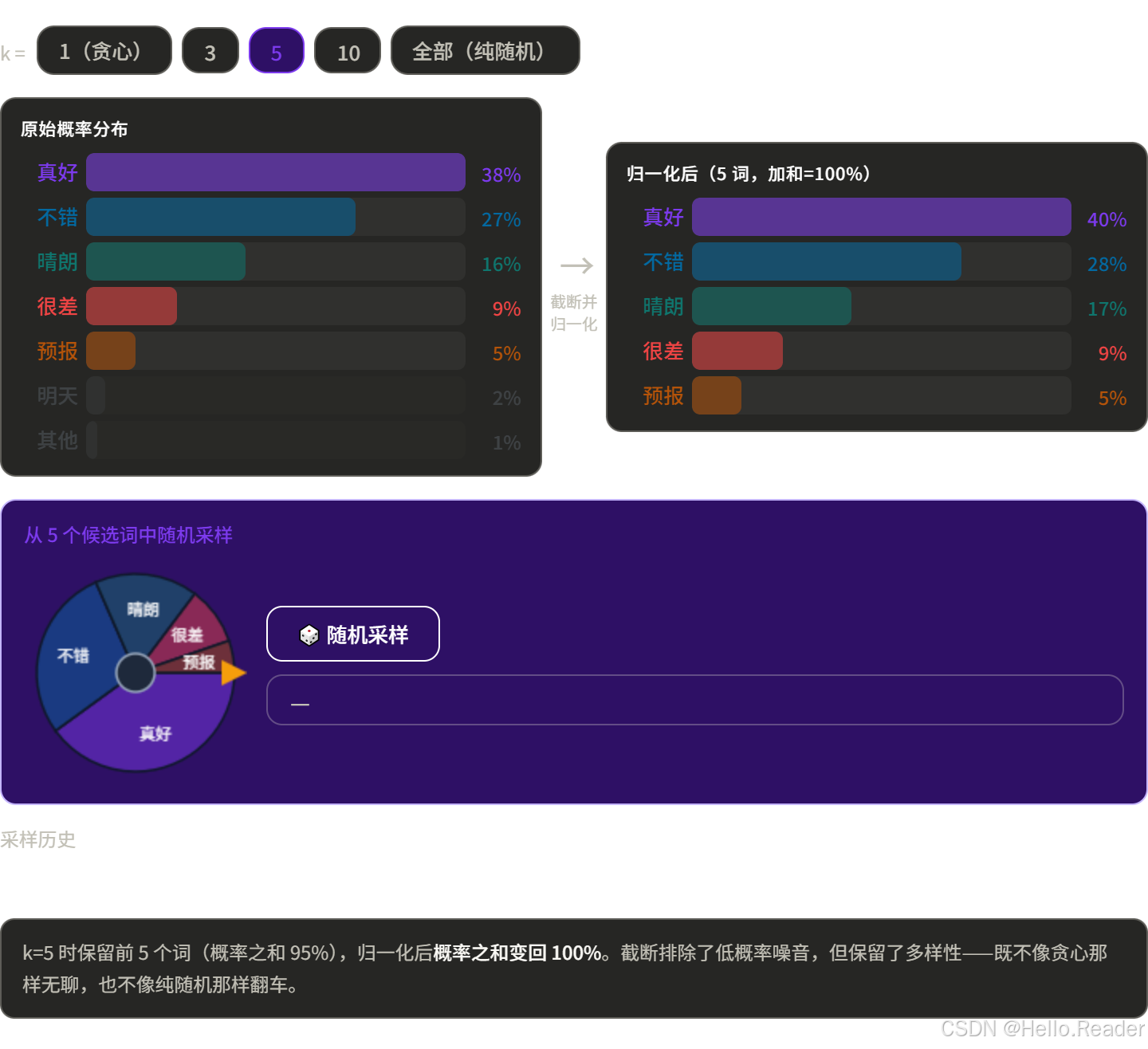
五、方法四:Top-k 采样
思路
只在概率最高的 k 个词里随机,其余词直接忽略。
类比
餐厅的菜单太长了,你先圈出评分最高的 5 道菜,然后在这 5 道里随机点一道。不会点到难吃的,但也保留了惊喜感。
k 怎么选?
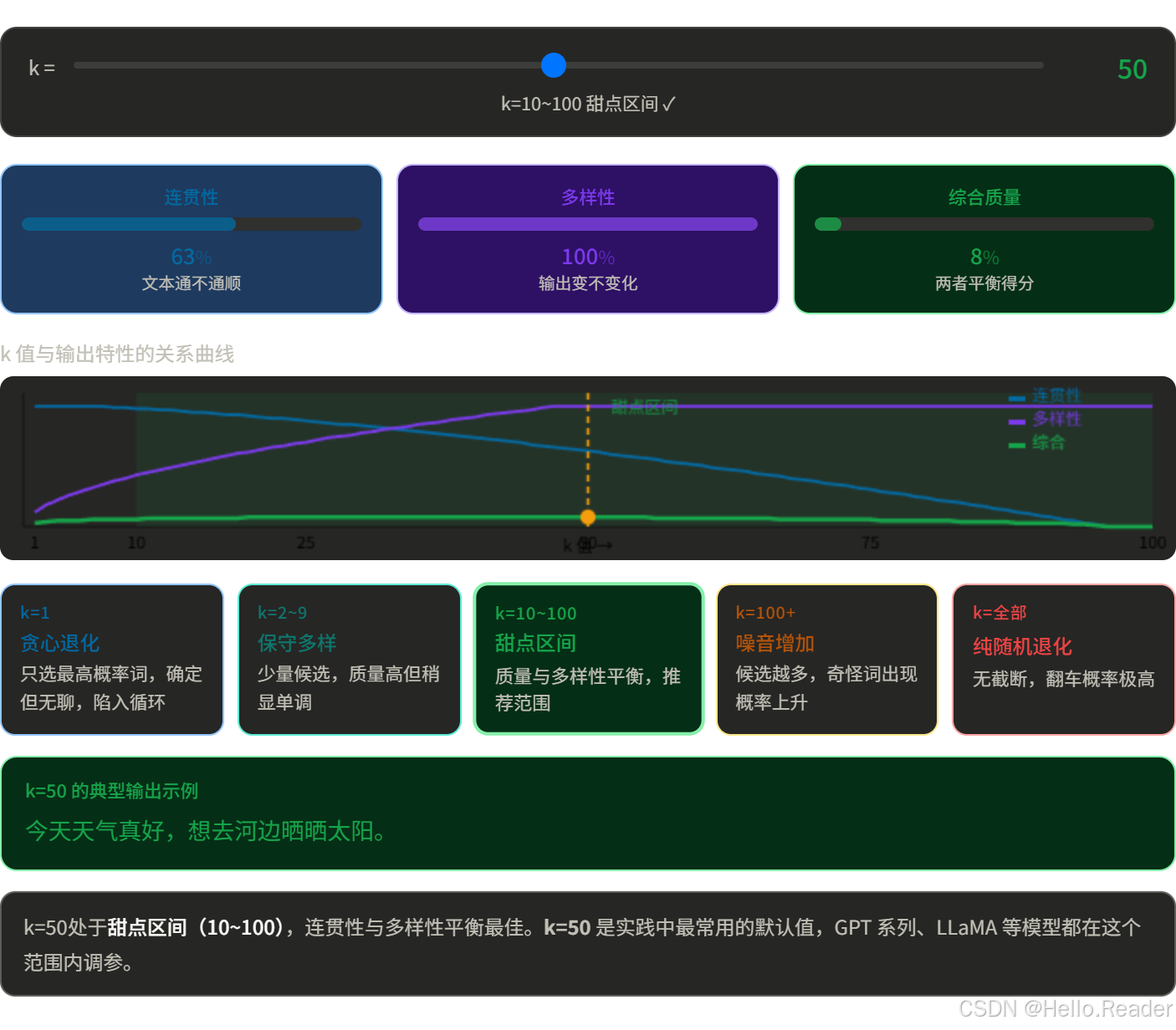
问题:k 是固定数量,不够灵活。有时候"合理候选词"只有 3 个(比如填空题),有时候有 500 个(比如开放式创作)。固定 k 顾此失彼。
六、方法五:Top-p 采样(核采样,Nucleus Sampling)
思路
不固定 k 的数量,而是累积概率达到 p 就截止。
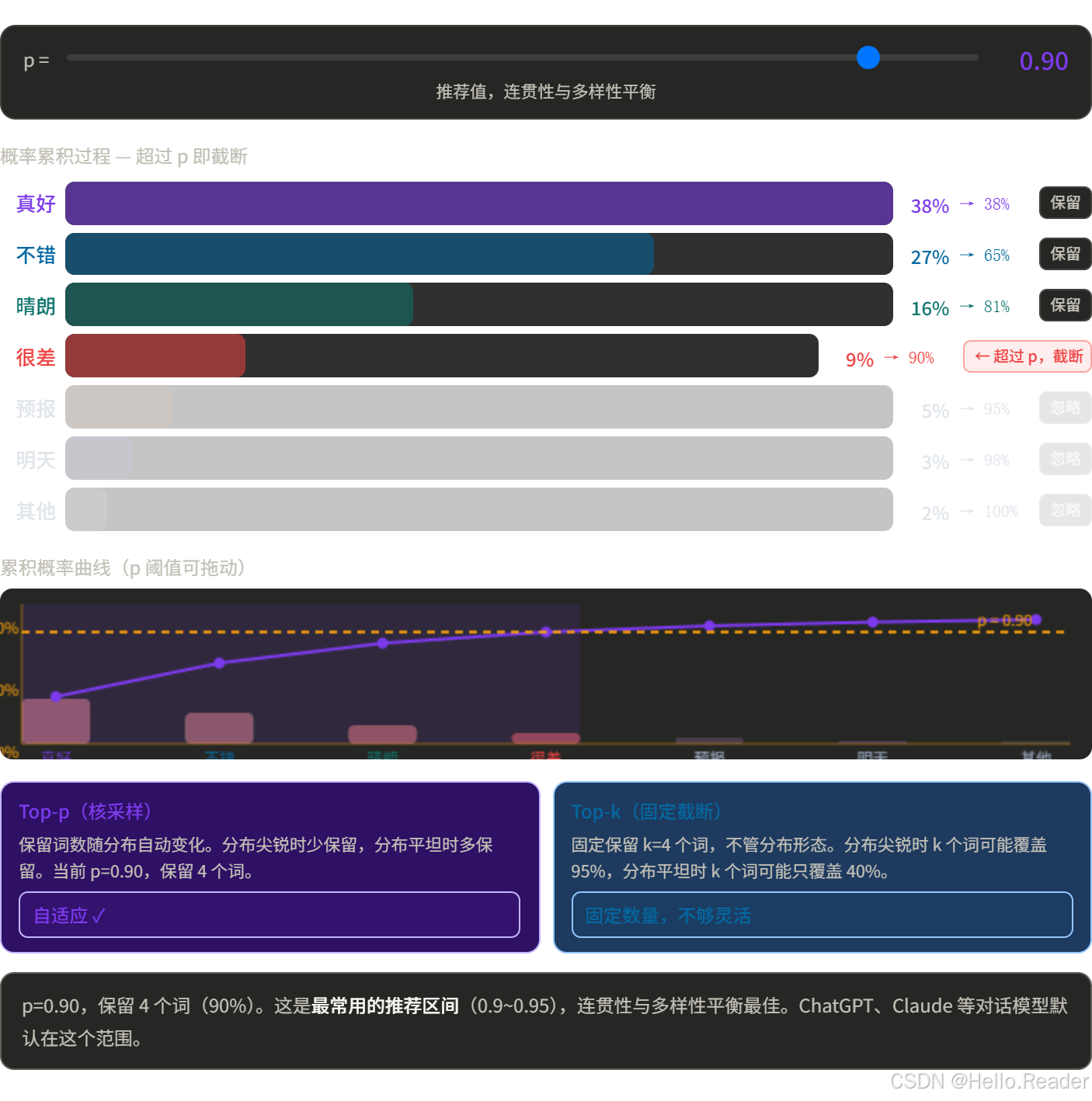
概率分布"尖锐"时(少数词占大多数),自动缩小候选集;
概率分布"平坦"时(很多词概率差不多),自动扩大候选集。
类比
不是圈固定几道菜,而是圈"性价比最好的那批菜",直到价值覆盖到 90% 才停。菜单变化时,圈的数量自然调整。
为什么叫"核采样"?
因为高概率的那一小撮词,就像分布的"核"(nucleus),p 控制的是核的大小。
p 通常取 0.9 或 0.95,是目前最常用的生成策略之一。
七、方法六:Temperature(温度)
Temperature 不是独立的采样方法,而是一个调节旋钮,可以和上面任意方法组合。
原理
在 Softmax 之前,把 logits(原始得分)除以一个温度 T:
softmax(xi/T)\text{softmax}(x_i / T)softmax(xi/T)
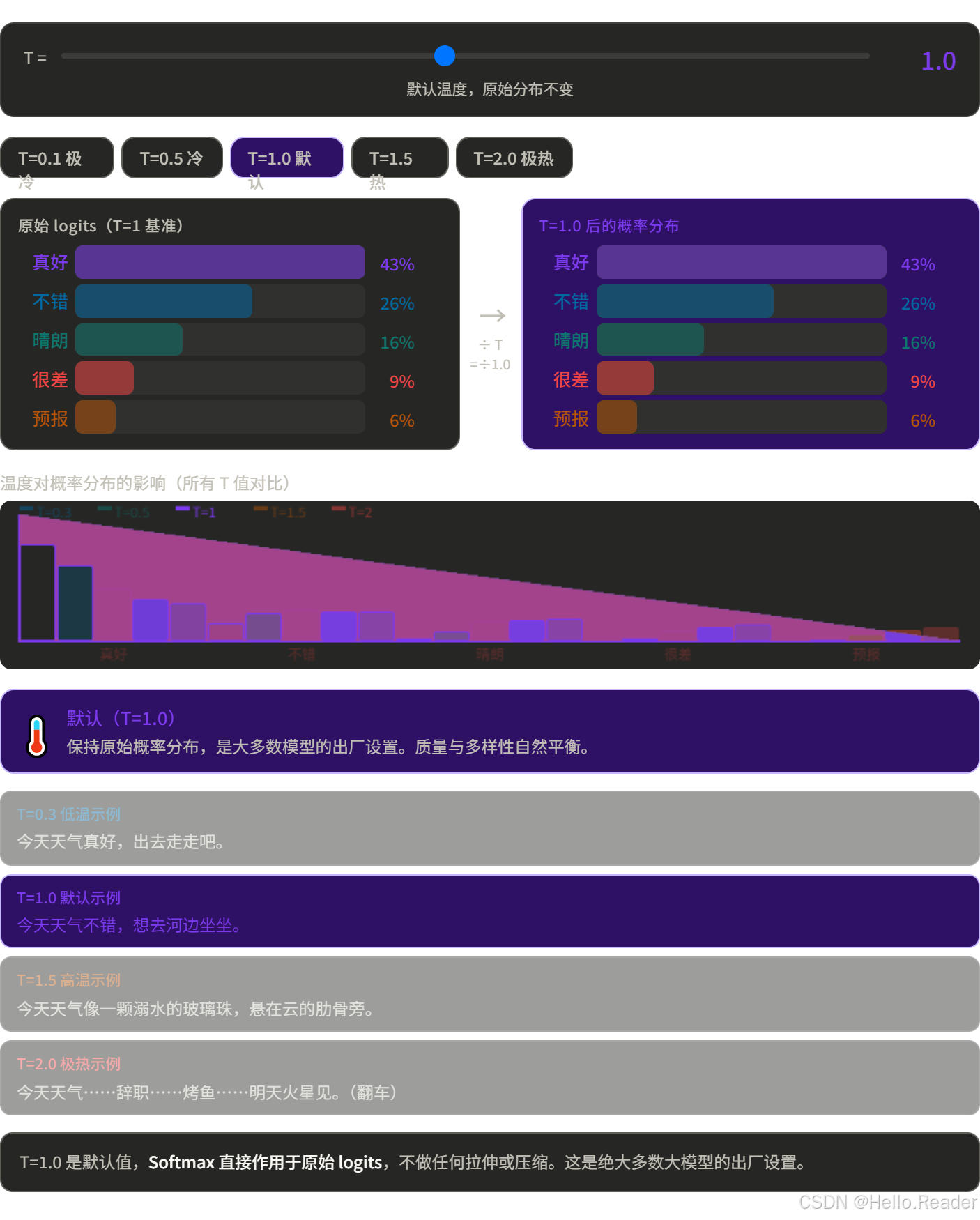
类比
温度就像做饭时的火候:
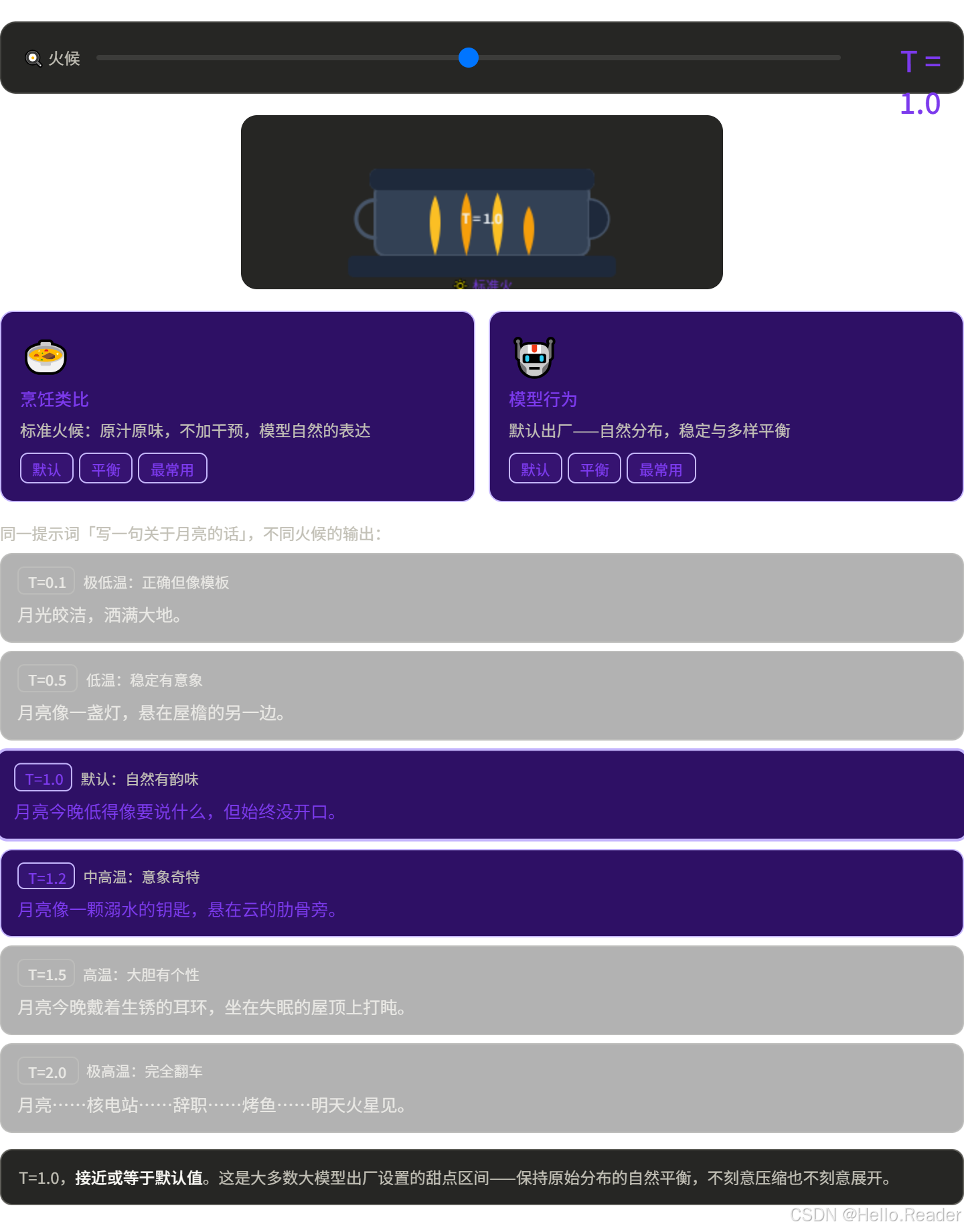
实际效果对比
同一个输入"写一首关于月亮的诗":
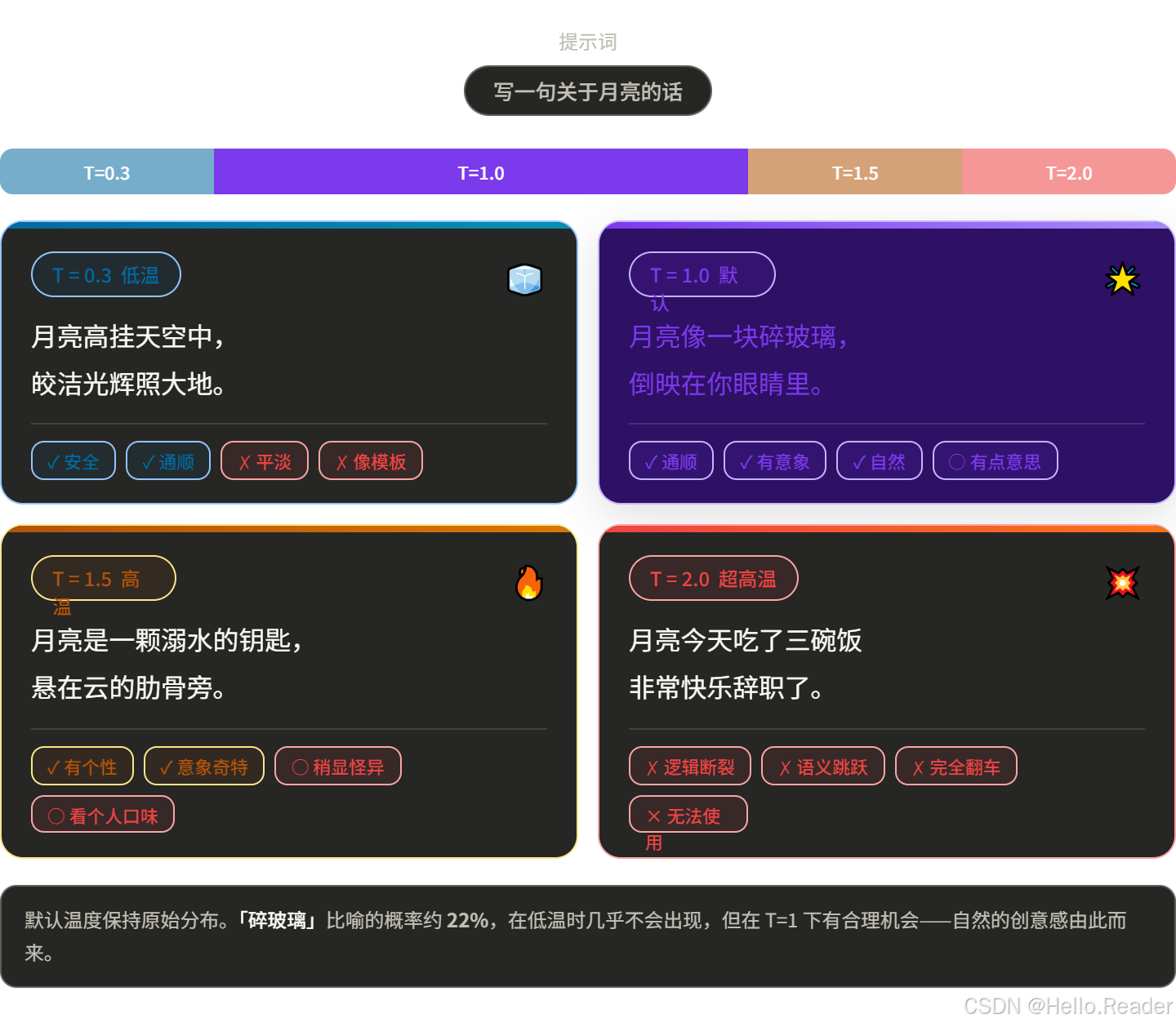
八、实战:ChatGPT/Claude 用的是什么策略?
各大模型的实际配置(大致):
| 模型/场景 | 策略 | 参数 |
|---|---|---|
| GPT-4 默认对话 | Top-p + Temperature | p=1.0, T=1.0 |
| GPT-4 代码生成 | Temperature 低 | T=0.2 |
| Claude 创意写作 | Top-p + 高 Temperature | p=0.95, T≈1.0 |
| 机器翻译 | 束搜索 | beam=4~8 |
| 文本摘要 | 束搜索 + 长度惩罚 | beam=4 |
规律:
- 需要确定答案(代码、翻译、数学)→ 低温或束搜索
- 需要多样创意(故事、对话、头脑风暴)→ Top-p + 中高温
九、一个有趣的问题:为什么 GPT 每次回答不一样?
因为用了随机采样!即使是同一个问题,temperature > 0 就意味着每次采样结果不同。
想要每次结果一样,有两种方法:
- 设置
temperature=0(退化为贪心) - 固定随机种子(
seed)
OpenAI API 里的 temperature 参数就是这个温度旋钮,设为 0 就是贪心,设为 2 就非常随机。
十、三句话总结
-
贪心/束搜索 = 追求最优解,适合有标准答案的任务(翻译、摘要);缺点是无聊。
-
Top-k / Top-p 采样 = 在合理候选里随机,兼顾质量和多样性;Top-p(核采样)比 Top-k 更灵活。
-
Temperature = 控制"随机程度"的旋钮,低温保守、高温创意;几乎所有生成任务都要调它。
延伸阅读
- 📄 核采样原文:The Curious Case of Neural Text Degeneration(Holtzman et al., 2020)
- 📝 Hugging Face 生成策略文档:
generate()函数的所有参数说明 - 💻 自己动手试:OpenAI Playground 可以直接拖动 temperature 和 top_p 滑块看效果

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐

 31
31 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)