如何打造真正好用的Agent(非常详细),LLM应用落地全攻略,收藏这一篇就够了!
现在人人都在做 LLM Agent,Claude Code、Codex、AutoResearch、OpenClaw,产品已经真实落地了。但到底怎么构建一个好用的 Agent?
Kangwook Lee 这篇讲稿挺值得认真读的,核心思路来自三个真实系统的生产经验:Terminus-KIRA(终端编程 Agent)、PUBG Ally(实时对战游戏 Agent)和 Smart Zoi(inZOI 游戏里的生活模拟 Agent)。上下文工程、Skills、Compaction、多 Agent、递归语言模型、Ralph 循环、测试时扩展、记忆驱动的自我进化……这些都不是拍脑袋想出来的,每个都是真实问题倒逼出来的解法。
LLM Agent 到底是什么
说白了就三步循环:观察 → 思考 → 行动,不断重复直到任务完成。Agent 读取环境信息,推理该做什么,调工具执行,然后把结果喂回来继续下一轮。
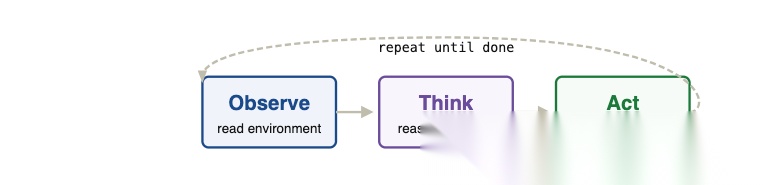
这个核心循环很简单,后面所有的优化、所有踩过的坑,本质上都是在这个循环上做文章。
从最简单的形态说起
最基础的就是单次工具调用,没有循环,一锤子买卖:给个任务,LLM 想一想,调一个工具,结束。适合"帮我搜一下 X"、"帮我算一下 Y"这类简单需求。
context = task_instructiongenerated_tokens = LLM(context)thoughts, action = parse(generated_tokens)exec(action)
加上 while 循环就变成真正的 Agent 了——任务没完成就一直跑,每轮把输出追加到历史里,作为下一轮输入。这里有个细节值得注意:输出(output)不是简单的"下一个状态",而是执行过程中观察到的一切——日志、信号、副作用,甚至奖励信号。比如执行编译命令,输出就是完整的编译日志加上成功/失败标记。
token_history = task_instructionwhile task not completed: generated_tokens = LLM(token_history) thoughts, action = parse(generated_tokens) output = exec(action) token_history += [thoughts, action, output]
上下文工程:真正的核心竞争力
随着循环推进,历史记录越积越长,最终把上下文窗口塞满。计算开销和 KV 缓存内存都线性增长,而大部分历史内容其实已经没用了。这就引出了上下文工程:把历史存储和实际喂给 LLM 的内容分开,每一轮都精心准备"刚好够用"的上下文,而不是把所有历史一股脑塞进去。
token_history = task_instructionwhile task not completed: context = context_build(token_history, external_info) generated_tokens = LLM(context) ...
动态切换工具
工具列表定义在系统提示里,上下文工程允许每一轮动态调整可用工具集。比如一个编程 Agent,开始用文件浏览工具,中间切换到编辑工具,最后换成测试工具——按阶段按需加载,不用一次全开着。
Skills:按需加载的技能包
Skills 是结构化的(提示词 + 工具集 + 指令)组合包,需要的时候才加载进上下文。为什么不直接写成一个超长系统提示?因为上下文窗口有限,Skills 的逻辑是:需要什么,用什么,不需要的不占空间。
下面是 Claude Code 里一个真实的 Skill:
# /commit —— 创建 git 提交的技能# 当用户要求提交更改时:# 1. 运行 git status 和 git diff 查看所有变更# 2. 分析差异,概括变更性质(新功能、修 bug、重构、文档等)# 3. 起一个简洁的提交信息(1-2 句),重点写"为什么"而不是"做了什么"# 4. 暂存相关文件(避免包含密钥、.env 等)# 5. 创建提交# 可用工具: Bash(git status), Bash(git diff), Bash(git add), Bash(git commit)
一个 Skill 就是一个文本文件,Agent 在调试代码时根本不会看到 /commit 这个 Skill。更妙的是,Skills 本身可以被 Agent 写入、更新,甚至在多个 Agent 之间共享——更新 Skill 就等于更新提示词,这是一种去中心化的持续学习方式。
不过要注意,Skills 也是最容易"过拟合"测试集的手段。针对特定任务定制的 Skill 可以刷高评分,但不代表通用能力真的提升了。
Compaction:上下文满了就压缩
不同场景有不同的压缩策略。编程 Agent 可以扔掉冗长的编译日志只保留成功/失败结果;ML 研究 Agent 只保留验证损失而不保存完整训练曲线;实在没办法了就用另一个 LLM 来做摘要压缩。核心思路都一样:把没用的扔掉,只留关键信息。
KV 缓存的约束
上下文工程改变了每一轮的输入,但如果前缀变了,KV 缓存就会失效,需要重新计算,代价不小。
Manus 2025 年提出的解法是掩码法:从一开始就把所有信息放进系统提示,通过 logit masking 来"屏蔽"暂时不需要的部分,而不是动态添加删除。前缀始终不变,KV 缓存一直有效。初始提示词虽然长了,但多轮循环下来收益相当可观。
临时上下文(Ephemeral Context)
另一个技巧是把当前轮特有的信息追加在稳定前缀之后,这部分"临时上下文"用完即丢,不会存入历史。
while task not completed: context = token_history + log # log 是临时的,不会存入历史 generated_tokens = LLM(context) thoughts, action = parse(generated_tokens) output = exec(action) token_history += [thoughts, action, result] # 只保留结果!
PUBG Ally 就用了这个方案——敌人位置、血量、安全区这些信息当下关键,但下一轮就没意义了,没必要永远保留。顺便说一下,PUBG Ally 是一个完全跑在玩家本地 GPU 上的实时游戏 Agent,集成了语音(STT + SLM + TTS)、战术建议、实战辅助,全部本地推理。
多 Agent 和子 Agent:本质是上下文隔离
可以把多 Agent 理解成面向对象编程里的对象隔离。如果让同一个 Agent 既写代码又做 Code Review,Review 的判断会被写代码时的思路所干扰(确认偏误)。分成两个 Agent、各自拥有干净的上下文,问题就解决了:
code = LLM_Agent("code it")review = LLM_Agent("review it", code)# 或者迭代式:while True: code = LLM_Agent("code it", review) review = LLM_Agent("review it", code)
子 Agent 的逻辑也一样:主 Agent 不直接读取一个巨大的文件,而是派一个子 Agent 去读,子 Agent 把摘要返回给主 Agent,自己的上下文直接丢弃。主 Agent 只看到简洁的结论,上下文保持整洁。
递归语言模型:用程序来调度 Agent
假设 LLM 计划处理 file000.txt 到 file099.txt,在实际执行中它可能中途漏掉 file078.txt——记忆不可靠。解决方案是让 LLM 直接写一段程序来调度子 Agent,程序保证每个文件都被处理,LLM 不再需要靠"记忆"来跟踪进度:
summary = run_program(""" for file in files: result += LLM_Agent("summarize " + file) return result""")
这对规模较小的模型效果尤为显著——程序结构弥补了模型在长程追踪上的短板。
最大的生产问题:虚假完成
讲到这里,前面覆盖了上下文工程、Skills、Compaction、多 Agent、递归语言模型——现在到了最关键的问题:Agent 怎么知道自己该停了?
有三种情况:有外部校验器的可验证任务(好处理)、固定时间/预算限制(也好处理)、以及最常见的——LLM 自己决定是否完成。这最后一种,问题最大。
在 Terminal-Bench-2 这个需要深度专业知识的基准测试上,配合 Claude Opus 4.6 的基线 Agent 在时间限制内提交了 5 次结果,5 次全错,且每次都"充满信心"地认为自己完成了。大约 80% 的失败都源于虚假完成(False Completion)。
Ralph 循环
一个直接的解法:加一个外层循环,让一个全新的 Agent 来验证工作是否真的完成了。每次内层循环都从干净的上下文开始,但面对的是同一个世界状态。只有当新 Agent 什么都没改动,才真正退出:
while True: # 外层循环 token_history = [] while True: # 内层循环,上下文干净 ... if action == done: break output, answer_not_changed = exec(action) token_history += [thoughts, action, output] if answer_not_changed: break # 新 Agent 也认为没什么可改了
Terminus-KIRA 的方案
Ralph 循环有效,但需要完整重启内层循环,开销不小。Terminus-KIRA 的变体更轻量:正常跑的同时,单独维护一份只包含动作和输出、不含思考过程的历史。当 Agent 觉得完成了,让一个只看"做了什么"、看不到"怎么想的"的独立验证者再确认一遍:
token_history = task_instructiontoken_history_wo_thoughts = []while True: ... if action == done: # 只用动作+输出的历史再验证一次,去掉思考过程的干扰 generated_tokens = LLM(token_history_wo_thoughts) thoughts, action = parse(generated_tokens) if action == done: break # 两个都同意,才算真完成 output = exec(action) token_history += [thoughts, action, output] token_history_wo_thoughts += [action, output] # 只记录做了什么
去掉思考过程的干扰,验证者的判断更客观,而且不需要完整重启一轮循环。
AutoResearch:虚假完成不是问题的情况
Andrej Karpathy 的 AutoResearch 火了之后,很多人问它为什么不需要 Ralph 循环。答案很简单:这是一个进度可度量的任务。
目标是训练出验证损失更低的模型。损失到底有没有降,数据说了算,Agent 根本没办法"虚报完成"。整个提示词的核心逻辑就是:永远不停——看 git 状态,改 train.py,提交,跑实验,读结果,好就保留,不好就 reset,记录,继续循环。
“
一旦实验循环开始,不要停下来询问用户是否继续。用户可能已经睡着了,或者离开了电脑,期望 Agent 一直工作直到被手动停止。按每个实验约 5 分钟算,一晚上能跑 100 个实验,用户醒来就看到结果。
进度(验证损失)是可以直接衡量的,虚假完成几乎不可能发生。AlphaEvolve 和 AdaEvolve 也是同样的模式。
自动强化学习 Agent
和 AutoResearch 类似,但更进一步,用于 RL 工程。不只是调超参数,Agent 还要自主设计奖励函数来避免 reward hacking。KRAFTON 团队用一个 b-boying 蜘蛛做了演示:Agent 自主设计奖励函数、训练 RL 策略、不断迭代,最终达到超人表现。
测试时扩展:多跑几次选最好的
测试时扩展(Test-Time Scaling)的思路是跑多个候选再挑最好的。但用在 Agent 上有几个难题:整个 Agent 循环跑多次成本极高;Agent 输出不是固定选项,没法直接投票;而且当成功率低于 50% 时,多数人投票反而选出了错的那个。
直接让 LLM 从所有候选里挑"最有希望的",本质上是隐式多数投票,成功率低的时候会适得其反。
BTL 成对比较的思路是每次只让 LLM 比较两个候选,不让它同时看到所有人,从而避免多数偏误:
for i in range(N): history[i] = LLM_agent(task_instruction)for (i, j) in [N] x [N]: y[i,j] = LLM("哪个更有希望?" + history[i] + history[j])s = BTL_solver(y) # Bradley-Terry-Luce 模型return argmax(s)
初步测试结果:
| Agent | 单次基线 | BTL 最优 | 提升 |
|---|---|---|---|
| Terminus-KIRA | 76.2 | 81.3 | +5.1 |
| Terminus-2 | 62.9 | 67.0 | +4.1 |
| OpenSage GPT-5.3 | 78.4 | 81.1 | +2.7 |
BTL 方法确实比简单计分略胜一筹,而且每对可以比较多次,比较本身也是一种测试时算力投入。
OpenClaw:靠记忆自我进化
OpenClaw 的核心是在基础 Agent 循环和 Ralph 循环之上,加了记忆更新。每次任务结束后,Agent 更新自己的记忆,而这个记忆在下一次任务开始时就已经加载进来了:
token_history = system_prompt + memory + task_instructionwhile True: ... if action == done: memory = memory_update(thought_history) # 自我进化! break ...
记忆更新可以很有创意——总结本次会话、更新 Agent 的"身份认知"、积累跨任务的性格和经验。这是一种真正意义上的持续学习,任务与任务之间有了连续性。
记忆在真实产品里的样子
inZOI 是全球第一款搭载本地 LLM Agent 的游戏,销量超过 100 万份。开发团队尝试过让 AI 角色自主进化性格,但发现角色性格很容易极端化,最终选择了让用户自定义人格的方案来保证稳定性。
PUBG Ally 的记忆则集中在友谊和过去的游戏经历上。“还记得我们那次赢的比赛吗?”——有了这样的记忆,队友才有了真实感,而不只是一个指令执行器。
还有哪些没解决的问题
- 主动性:Agent 什么时候该主动找用户说话?什么时候该自己去做?
- 快速反应:System 1 / System 2 架构怎么落地
- 蒸馏:把 LLM Agent 压缩成 SLM Agent,不是简单的知识蒸馏,有离策略、模型共享等难题
- 多模态:语音转文字再转语音,信息在每个环节都有损耗,多模态应该是模型的核心能力而不是外挂
- 评测:Agent 输出复杂、不确定性高,怎么可靠地评估是个大问题
- 规划:LLM 的探索/利用权衡做得很差,外部搜索机制是目前的补丁
最后说几句
LLM Agent 的核心循环本身很简单,但让它在生产环境里真正跑起来,每个环节都有讲究。上下文工程是最核心的设计空间;虚假完成是最常见的生产问题;记忆机制让 Agent 真正拥有了跨任务的连续性。
整个领域还非常早期——作者用的比喻是"通信技术的 1950 年代"。从真实问题出发去做工程,而不是从 benchmark 出发去刷分——这句话值得反复想想。
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐
 10
10 0
0- 0



 已为社区贡献76条内容
已为社区贡献76条内容

所有评论(0)