OpenClaw + Ollama 本地实战(非常详细),模型选型与部署从入门到精通,收藏这一篇就够了!
想在本地跑大模型,但不知道自己的电脑能跑啥?显存不够会不会爆?工具调用又是怎么回事?这篇文章帮你彻底搞清楚。
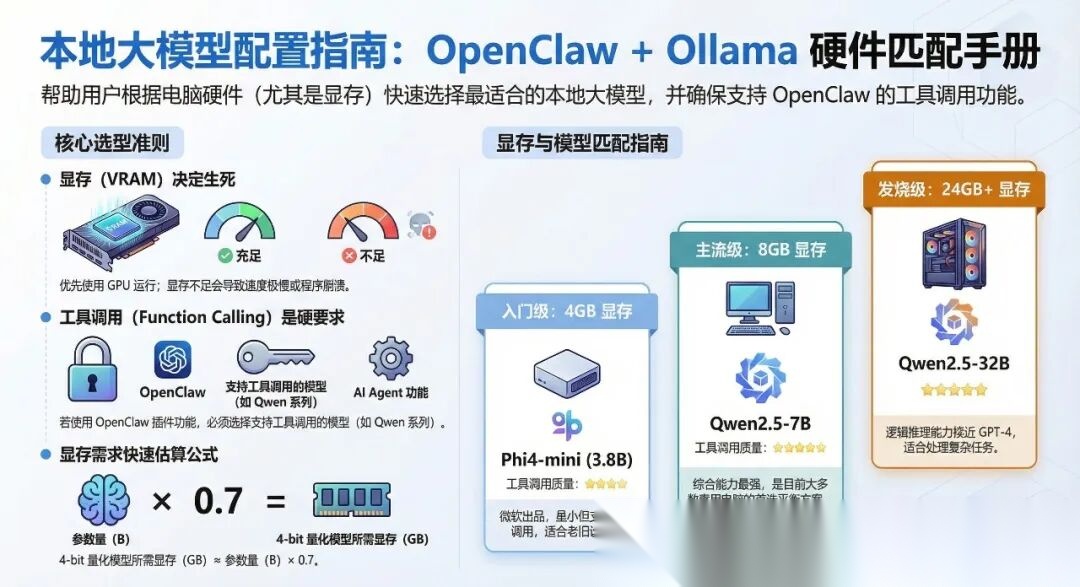
一、核心概念:两件事决定你能跑什么
1.1 显存(VRAM)vs 内存(RAM)
很多人分不清这两个,简单说:
- • 显存(VRAM) 是显卡自带的内存,模型优先加载到这里,速度快、推理流畅
- • 内存(RAM) 是主板上的系统内存,显存不够用时才会用到,速度慢很多
结论很简单:有独立显卡,优先用 GPU 跑。
CPU 不是不能跑,7B 模型可能只有 2~5 tokens/s,聊个天都得等半天,体验很差。
1.2 工具调用能力(Function Calling)
如果你用的是 OpenClaw 这类 AI Agent 框架,工具调用能力是硬性要求。模型不支持,Skills 就完全跑不起来。
注意:不是所有模型都支持工具调用! 选模型前一定要确认这一点。
二、硬件支持情况
2.1 Ollama 支持哪些硬件?

2.2 NVIDIA 显卡兼容列表
运行 nvidia-smi 查看当前显卡信息。
| 系列 | 代表型号 | 支持状态 |
|---|---|---|
| RTX 40xx | 4090, 4080, 4070, 4060 | ✅ 完全支持 |
| RTX 30xx | 3090, 3080, 3070, 3060 | ✅ 完全支持 |
| RTX 20xx | 2080, 2070, 2060 | ✅ 完全支持 |
| GTX 10xx | 1080, 1070, 1060 | ✅ 支持 |
| GTX 9xx | 970, 960 | ✅ 支持 |
三、配置-模型对照表
3.1 显存需求估算
快速估算公式(4-bit 量化):

常见模型实际占用参考:
| 模型 | 参数量 | 显存占用(Q4量化) |
|---|---|---|
| gemma3:1b | 1B | ~0.8 GB |
| phi4-mini | 3.8B | ~2.5 GB |
| llama3.2:3b | 3B | ~2 GB |
| qwen2.5:7b | 7B | ~5 GB |
| llama3.1:8b | 8B | ~5.5 GB |
| mistral:7b | 7B | ~4.5 GB |
| qwen2.5:14b | 14B | ~9 GB |
| mistral-nemo:12b | 12B | ~8 GB |
| qwen2.5:32b | 32B | ~20 GB |
| qwq:32b | 32B | ~20 GB |
| llama3.3:70b | 70B | ~40 GB |
3.2 根据显存选模型
4GB 显存(入门级)
入门推荐,选小而精的模型:
- phi4-mini(3.8B,~2.5GB)⭐ 首选,微软出品,支持工具调用,4GB 显存跑得动
- qwen2.5:1.5b(1.5B,~1.2GB)性价比高,阿里出品
- llama3.2:1b(1B,~0.8GB)Meta 小模型,快但能力有限
8GB 显存(主流级)
这个档位性价比最高,主力机器推荐配置:
- qwen2.5:7b(7B,~5GB)⭐ 首选,综合能力强,工具调用质量高
- llama3.1:8b(8B,~5.5GB)Meta 出品,综合最佳之一
- mistral:7b(7B,~4.5GB)经典 7B,工具调用稳定
16GB 显存(进阶级)
可以跑 14B 级别的模型,体验明显提升:
- qwen2.5:14b(14B,~9GB)⭐ 强烈推荐,工具调用质量高,16GB 显存的最优解
- mistral-nemo:12b(12B,~8GB)Mistral 出品,表现稳定
⚠️ 注意:phi4(14B 版本)本体不支持工具调用,如需工具调用请用 phi4-mini 或 phi4-tools 社区版。
24GB+ 显存(高端级)
顶配体验,企业或发烧友级别:
- qwen2.5:32b(32B,~20GB)⭐ 顶级开源模型,效果接近 GPT-4
- qwq:32b(32B,~20GB)推理特化,擅长复杂逻辑任务
- llama3.3:70b(70B,~40GB)需要 48GB 显存,建议双卡
48GB+ 显存(专业级)
- • qwen2.5:72b(72B,~45GB)旗舰模型,极强综合能力
3.3 纯 CPU 方案(无显卡)
没有独立显卡也能跑,但要有心理准备:
- • 速度慢:7B 模型通常只有 2~5 tokens/s
- • 内存需求大:至少需要 16GB 系统内存
- • 推荐选择 1.5B~3B 小模型:
qwen2.5:1.5b或llama3.2:1b
四、支持工具调用的模型清单
如果你用 OpenClaw 的 Skills 功能,必须选这部分的模型。
4.1 强烈推荐
⭐⭐⭐⭐⭐ qwen2.5 系列(0.5B~72B)
- • 阿里通义千问,工具调用质量最强
- • 推荐:
qwen2.5:7b/qwen2.5:14b/qwen2.5:32b
⭐⭐⭐⭐⭐ qwen3 系列(0.6B~235B)
- • 2025 年发布的最新一代,比 qwen2.5 更强
- • 含稠密模型(0.6B/1.7B/4B/8B/14B/32B)和 MoE 模型(30B-A3B/235B-A22B)
- • MoE 架构:参数量大,但实际推理时只激活一小部分,显存占用比参数量少很多
- • 推荐:
qwen3:8b/qwen3:14b/qwen3:30b-a3b
⭐⭐⭐⭐⭐ llama3.1 系列(8B/70B)
- • Meta 官方,工具调用支持完善,综合能力强
- • 推荐:
llama3.1:8b(8GB 显存的最佳选择之一)
⭐⭐⭐⭐ llama3.2 系列(1B/3B)
- • Meta 轻量小模型,适合入门或资源受限场景
⭐⭐⭐⭐ mistral:7b
- • 经典 7B 模型,工具调用稳定可靠
⭐⭐⭐⭐ gemma3 系列(1B/4B/12B/27B)
- • Google 于 2025 年 3 月发布,已原生支持工具调用,同时支持多模态(视觉理解)
- • 推荐:
gemma3:4b/gemma3:12b
⭐⭐⭐⭐ phi4-mini(3.8B)
- • 微软 2025 年 2 月发布,官方支持工具调用
- • 4GB 显存下效果最佳的工具调用模型
4.2 可用但效果一般
| 模型 | 说明 |
|---|---|
| deepseek-r1 | 推理模型,工具调用支持有限,慎用 |
| mistral-nemo:12b | 效果尚可,但不算优秀 |
| command-r:35b | 专为 RAG 检索场景设计 |
| phi4(14B 原版) | 强推理能力,但不支持工具调用;可用社区版 phi4-tools |
4.3 不支持工具调用(重要!)
以下模型无法用于 OpenClaw 的 Skills 功能,适合纯聊天或文本生成场景:
| 模型 | 说明 |
|---|---|
| ❌ codellama | Meta 专为代码设计,无工具调用 |
| ❌ llama2 | 已过时,无工具调用,不推荐使用 |
📌 注意:gemma3(新版)和 phi4-mini 已经支持工具调用,如果你看过旧文章说它们不支持,那是过时的信息。
五、OpenClaw 配置实战
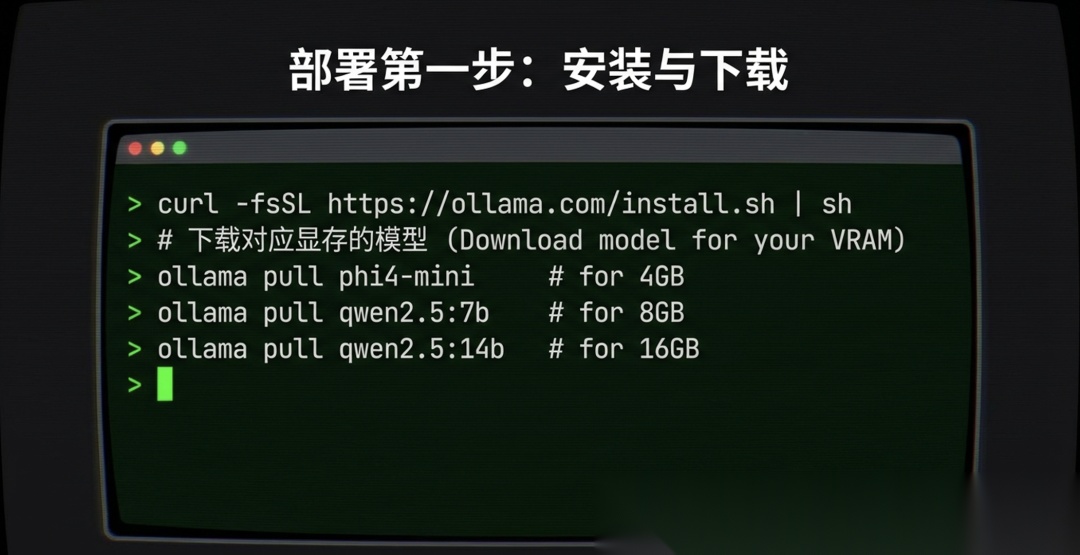
5.1 安装 Ollama
macOS / Linux:
curl -fsSL https://ollama.com/install.sh | sh
Windows:
直接下载安装包:ollama.com/download
5.2 下载推荐模型
根据你的显存情况,拉取对应模型:
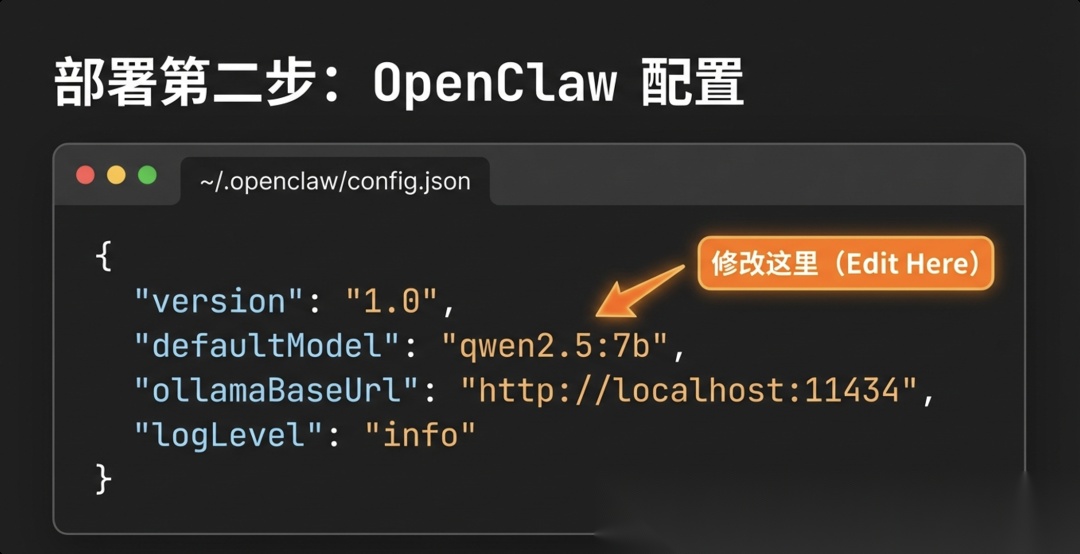
5.3 配置 OpenClaw
编辑 ~/.openclaw/config.json,将 defaultModel 设置为你拉取的模型名称:
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐
 10
10 0
0- 0



 已为社区贡献65条内容
已为社区贡献65条内容

所有评论(0)