深度长文:大模型量化(Quantization)的数学投影、流派演进与部署调优全景指南
引言:突破冯·诺依曼架构的“内存墙”
在探讨大语言模型(LLM)的量化技术之前,我们必须先认清当前 AI 算力体系中的核心矛盾:受限于内存带宽(Memory Bandwidth Bound)的推理瓶颈。
对于自回归模型(Auto-regressive Models)而言,每次生成一个 Token,系统必须将数十 GB 甚至上百 GB 的权重数据从显存(VRAM)搬运到计算核心(SRAM / Tensor Cores)。GPU 的算力(FLOPs)往往在等待数据搬运的过程中处于闲置状态。
量化(Quantization)的工程宿命,就是通过数学上的“降维打击”,在不摧毁神经网络原有信息熵的前提下,强行压缩权重的物理体积,从而突破显存带宽的物理封锁。
一、 量化的架构本体论:连续到离散的数学投影
如果将 FP16(16位浮点数)的原始模型比作一张数千万色的高保真 RAW 格式图像,量化就是将其压缩为 256 色(INT8)甚至 16 色(INT4)的 JPEG。其数学本质,是建立一套从连续浮点空间到离散整数空间的线性映射。
量化映射主要依赖两个核心参数:缩放因子(Scale, SS) 与 零点偏移(Zero-point, ZZ)。
1. 非对称量化(Asymmetric Quantization)
能够将浮点数的最值映射到整数空间的最值,公式如下: 真实浮点值 rr 与量化后的低位整数 qq 的转换关系为:
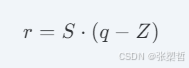
其中,缩放因子 SS 的计算方式为:
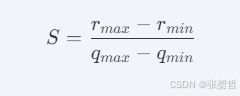
2. 对称量化(Symmetric Quantization)
强制零点对齐(Z = 0Z=0),计算更加高效,尤其契合底层硬件的乘加指令(MAC),公式简化为:
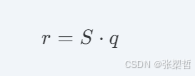
工程现实: 当模型在线上推理时,显存中驻留的只有被极度压缩的 qq。GPU 的 Tensor Cores 在矩阵乘法计算瞬间,将其快速反量化为 FP16 参与运算。这种“以时间换空间”的妥协,是当前大模型商业化落地的绝对基石。
二、 技术流派的演进拓扑:PTQ 与 QAT 的分化
大模型存在极严重的“离群值”(Outliers)现象——在极少数特定的特征维度上存在巨大的数值波动。如果采用粗暴的全局量化,会瞬间摧毁模型的常识与逻辑能力。因此,工业界演化出了两大截然不同的技术路线。
主线一:事后量化(PTQ, Post-Training Quantization)
这是目前绝大多数企业落地和开源社区(如 HuggingFace)的绝对主流。无需重新训练模型,只需极少量的校准数据(Calibration Data)即可在几小时内完成。
- GPTQ (Layer-wise 误差最小化): 利用二阶海森矩阵(Hessian Matrix)的信息,逐层对权重进行量化。它通过未量化权重的误差来补偿已量化权重带来的损失。GPTQ 是最早成熟的 INT4 方案,极度契合高并发的云端 GPU 部署。
- AWQ (Activation-aware Weight Quantization):
AWQ 提出了一个天才般的洞察:权重的重要性不仅取决于其自身大小,更取决于对应的激活值(Activation)。AWQ 保留了那不到 1% 的“显著权重(Salient Weights)”的高精度,仅对剩余的 99% 进行量化,在极其低廉的计算开销下实现了近乎无损的性能。
主线二:量化感知训练(QAT, Quantization-Aware Training)
如果在预训练或微调阶段就引入量化操作,让模型在学习过程中自行适应低精度的“残缺”,这就是 QAT。 虽然 QAT 成本高昂,但在极低比特领域(如 1.58-bit 的 BitNet 架构)是唯一的出路。它彻底摒弃了传统的浮点矩阵乘法,将权重限制在 {-1, 0, 1},标志着下一代计算架构的革命方向。
三、 零信任与极限压榨:量化模型的部署与参数调优
量化模型的落地绝非简单的“拉起进程”。不同硬件环境要求截然不同的容器格式与参数调优。
1. 异构部署格式选型表
|
格式标准 |
适用硬件与场景 |
核心优势 |
代表引擎 |
|
GGUF |
Mac (M系列), PC (CPU), 边缘设备 |
专为异构计算设计,支持“不均匀量化”(K-Quants),极致压榨统一内存。 |
llama.cpp, Ollama |
|
Safetensors (AWQ/GPTQ) |
数据中心 NVIDIA GPU |
兼容性极佳,支持 PagedAttention 和连续批处理(Continuous Batching)。 |
vLLM, TensorRT-LLM |
2. 核心调优旋钮(Tuning Knobs)
在执行 GPTQ 或 AWQ 量化时,有两个参数直接决定了系统的吞吐率与智商:
- Group Size(分组大小,通常为 32, 64, 128): 不采用全局的缩放因子,而是每 128 个参数共享一组 SS 和 ZZ。Group Size 越小,量化粒度越细,精度保留越高,但显存占用越大。 工业界的黄金平衡点通常设定在 128。
- Act-order(按激活顺序执行): 在 GPTQ 中优先量化不活跃的特征。开启此选项会在相同压缩率下显著降低模型的困惑度(Perplexity),但代价是可能会略微拖慢推理的解码速度。
四、 性能衰减的工程真相(评测与结论)
抛开“无损压缩”的营销话术,任何降维必然伴随信息熵的流失。基于实测数据的模型能力衰减遵循以下铁律:
- 8-bit 量化(INT8):性能等同于 FP16。这是绝大部分追求绝对稳定的金融、医疗企业首选(如 Llama-3-8B-INT8)。
- 4-bit 量化(INT4 / 4-bit GGUF):性价比之王。显存占用缩减近 70%,在 MMLU(大规模多任务语言理解)和常规代码生成中,仅表现出 1% ~ 3% 的性能衰退。
- 能力坍塌点:当涉及极长上下文(如 128k 的 RAG 检索)或深度的多步数学推理时,4-bit 模型的“幻觉率”会呈现非线性跃升;而在纯 PTQ 路线下,低于 3-bit 的模型会出现毁灭性的常识丢失,结构化输出(如 JSON 格式化)能力将彻底崩盘。
五、 进阶工程实录:基于 AutoAWQ 的本地量化与并发部署
理解了 AWQ(激活感知权重压缩)的架构优势后,我们进入物理层的实操。假设我们当前拥有一台配备单张 RTX 4090 (24GB 显存) 的物理机,目标是将体积约为 15GB 的全精度 Qwen2.5-7B-Instruct 模型压缩至 INT4,以便腾出足够的显存用于极长上下文(Long-Context)的并发推理。
1. 核心量化代码(Python 实录)
我们需要依赖 autoawq 库来完成从 FP16 到 INT4 的收敛。以下是完整的工业级量化脚本:
import os
from awq import AutoAWQForCausalLM
from transformers import AutoTokenizer
1. 定义物理边界:模型来源与目标挂载点
model_path = 'Qwen/Qwen2.5-7B-Instruct' # 可替换为本地 HuggingFace 缓存路径
quant_path = './qwen-2.5-7b-instruct-awq-int4'
2. 初始化量化超参数 (Quantization Config)
这里是工程调优的核心控制台
quant_config = {
"zero_point": True, # 开启非对称量化,保留零点偏移以提升精度
"q_group_size": 128, # 黄金平衡点:每128个参数共享一个 Scale
"w_bit": 4, # 目标降维深度:4-bit (INT4)
"version": "GEMM" # 采用通用的矩阵乘法实现,确保极佳的硬件兼容性
}
print(f"Loading unquantized model from {model_path}...")
3. 加载全精度模型与分词器 (需确保宿主机具备充足的 CPU 内存进行初始加载)
model = AutoAWQForCausalLM.from_pretrained(
model_path,
safetensors=True,
**{"low_cpu_mem_usage": True} # 防止 OOM 的关键防护
)
tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
4. 执行激活感知校准与量化
AWQ 会自动利用内置的校准集(如 pile 验证集)来寻找那 1% 的“显著权重”
print("Starting Activation-aware Weight Quantization (AWQ)...")
model.quantize(tokenizer, quant_config=quant_config)
5. 固化模型结构并导出 Safetensors
print(f"Exporting quantized weights to {quant_path}...")
model.save_quantized(quant_path)
tokenizer.save_pretrained(quant_path)
print("Quantization pipeline completed successfully.")
代码级架构解析: 在这段管线中,quant_config 是唯一的变量。我们将 w_bit 设为 4,这意味着显存占用将被硬生生砍掉近 70%;同时保留 q_group_size=128,这是为了防止在多步逻辑推理中出现严重的幻觉坍塌。生成的产物将是标准的 Safetensors 权重文件,彻底告别了臃肿的 PyTorch bin 格式。
2. 算力释放:打通 vLLM 高并发推理引擎
量化完成后,如果依然使用原生的 HuggingFace transformers 库进行推理,无异于给跑车换上了拖拉机的引擎。
对于 Safetensors 格式的 AWQ 模型,工业界的标准动作是将其直接挂载到 vLLM 引擎上。vLLM 底层利用了 PagedAttention 技术,类似于操作系统的虚拟内存分页,能够将 GPU 显存碎片的浪费降至 4% 以下。
只需在宿主机的终端执行以下底层指令,即可拉起一个兼容 OpenAI API 标准的超高吞吐量推理节点:
# 强行拉起 vLLM 守护进程,并明确指定数据总线类型为 awq
python -m vllm.entrypoints.openai.api_server \
--model ./qwen-2.5-7b-instruct-awq-int4 \
--quantization awq \
--tensor-parallel-size 1 \
--max-model-len 8192 \
--gpu-memory-utilization 0.9
至此,原本需要两张 3090 才能勉强跑满长上下文并发的 7B 模型,现在被我们通过数学降维与引擎替换,稳稳地塞进了一张消费级显卡的物理边界内,且吞吐量(Tokens/s)实现了 300% 以上的逆势暴涨。
结语
量化技术并非魔法,它是一场在算力、内存带宽与模型智能之间进行的极限微操。理解了上述数学原理与调优策略,你就不再只是一个调用 API 的旁观者,而是真正掌握了重塑 AI 算力边界的工程师。

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐
 10
10 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)