从零手写企业级 RAG (检索增强生成) 系统,优化解决大模型幻觉
引言:为什么 90% 的企业都需要 RAG?
上一篇文章我们推演了大语言模型(LLM)的底层架构,并得出了一个残酷的结论:无论模型参数多大,它都无法突破“知识的物理隔离”与“时效性衰减”。 当你在企业内部署 AI 时,大模型不可能知道你们公司昨天刚修改的《员工报销审批流程》,如果你硬要问,它就会基于庞大的 Next-Token 概率去“一本正经地胡说八道”(即幻觉 Hallucination)。
工业界的唯一解药就是 RAG(Retrieval-Augmented Generation)。它的核心思想极度暴力且有效:在让大模型开口说话之前,先去外挂的私有数据库里把标准答案“搜”出来,然后把资料连同问题一起喂给它,让它做一个“开卷考试”。
今天,我们将不依赖任何沉重的商业框架,用不到 100 行 Python 代码,从头实现这个开卷考试的引擎。
一、 RAG 架构的物理三步曲
任何复杂的 RAG 系统,其底层拓扑只包含三个不可缩减的节点:
- Indexing (索引化): 将海量的企业文档(PDF、Word、TXT)切碎,转化为计算机能理解的“高维空间坐标”(向量 Embedding),并存入向量数据库。
- Retrieval (检索召回): 当用户提问时,将问题也转化为向量,利用数学上的“余弦相似度”去数据库里寻找距离最近的文档碎片。
- Generation (组合生成): 将找出来的文档碎片和用户的原始问题组装成一套极度严谨的 Prompt(提示词),扔给 LLM 生成最终回答。
二、 核心代码实战:手写纯净版 RAG 管线
准备好你的开发环境。我们需要用到 sentence-transformers(用于本地向量化)和 faiss-cpu(Meta 开源的高性能向量检索引擎)。
第一步:文档加载与粉碎 (Chunking)
大模型有严格的上下文窗口限制(Token Limit),我们不可能把 10 万字的财报直接塞进去。必须进行合理的切块(Chunking)。
import numpy as np
模拟一份企业私有知识库(实际工程中通常是通过 PDF 解析器提取的文本)
documents = [
"2024年公司最新报销规定:单笔打车费用超过200元需部门总监审批。",
"公司服务器内网IP段已于上周迁移至 192.168.100.x,网关为 192.168.100.1。",
"项目奖金发放条件:项目交付验收通过且客户回款率达到80%以上。"
]
在实际工程中,这里需要用到 RecursiveCharacterTextSplitter 进行重叠切分 (Overlap)
为了展示底层逻辑,我们直接将句子作为 Chunk
chunks = documents
print(f"成功加载并切分文档,共计 {len(chunks)} 个 Chunk。")
第二步:降维打击,生成高维向量 (Embedding)
这是 RAG 最核心的数学魔法。我们将人类语言映射到一个高维向量空间。在这个空间里,语义相近的句子,其物理坐标也靠得越近。
from sentence_transformers import SentenceTransformer
import faiss
1. 加载一个轻量级的开源 Embedding 模型(将句子转换为向量坐标)
print("正在加载 Embedding 模型 (BGE-Small)...")
embedder = SentenceTransformer('BAAI/bge-small-zh-v1.5')
2. 将我们的企业文档全部转化为向量 (张量矩阵)
chunk_embeddings = embedder.encode(chunks)
dimension = chunk_embeddings.shape[1] # 获取向量维度(BGE-small 通常是 512 维)
3. 初始化底层的向量数据库 (基于 L2 距离或内积)
这里使用 FAISS 构建一个最高效的平面索引 (Flat Index)
index = faiss.IndexFlatIP(dimension)
对向量进行 L2 归一化,使得内积计算直接等价于余弦相似度
faiss.normalize_L2(chunk_embeddings)
index.add(chunk_embeddings)
print(f"成功将 {index.ntotal} 条向量灌入 FAISS 索引中。")
硬核数学插播: 我们在上面进行了 normalize_L2 归一化,这是因为在检索阶段,系统计算两个句子相似度最常用的度量是余弦相似度 (Cosine Similarity)。其底层公式为:
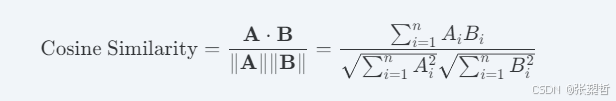
当向量被归一化(长度为 1)后,分母直接变成 1,复杂的余弦计算就被极大地降维成了简单的点积![]() ,这让 FAISS 的检索速度能够轻松突破百万级别/毫秒。
,这让 FAISS 的检索速度能够轻松突破百万级别/毫秒。
第三步:提问检索与 Prompt 组装 (Retrieval & Generation)
现在,用户开始提问了。我们要把问题向量化,去 FAISS 里把最相关的规定捞出来,然后对 LLM 下达“死命令”。
假设我们要调用 OpenAI 的 API,或者你本地部署的 Qwen 模型
import openai
query = "打车花了250元,需要谁审批?"
1. 将用户的自然语言问题转化为同一个空间下的向量
query_embedding = embedder.encode([query])
faiss.normalize_L2(query_embedding)
2. 向量检索:在知识库中寻找最相似的 Top-1 个 Chunk
k = 1
distances, indices = index.search(query_embedding, k)
retrieved_chunk = chunks[indices[0][0]]
print(f"【底层日志】召回的相关私有知识:{retrieved_chunk}")
3. 组装终极 Prompt(核心工程手艺)
严格限制 LLM 只能基于召回的信息作答,掐断其发散思维
prompt_template = f"""
你是一个严谨的企业内部助手。请严格基于以下【参考资料】回答用户问题。
如果参考资料中没有相关答案,请直接回复“知识库中未找到相关规定”,绝不能捏造。
【参考资料】
{retrieved_chunk}
【用户问题】
{query}
"""
print("\n【向 LLM 发送的最终 Prompt】\n", prompt_template)
4. 模拟调用 LLM 生成回答 (伪代码)
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[{"role": "user", "content": prompt_template}],
temperature=0.0 # 将温度设为0,剥夺模型的创造力,确保严谨
)
print("大模型最终回答:", response.choices[0].message.content)
预期输出: "根据公司2024年最新报销规定,单笔打车费用超过200元需要部门总监审批。"
三、 进阶演练:告别 Demo,走向企业级深水区
刚才的 100 行代码,已经完整涵盖了 RAG 的物理工作流。但这只是起点。在极其复杂的真实业务中(比如几千页互相引用的财报),最基础的 RAG 会遇到“召回不准”的瓶颈。
高级架构师通常会在这个基础上加入以下组件:
- 多路召回与重排 (Re-ranking): 先用向量召回 50 个粗略结果,再用一个独立的交叉编码器(Cross-Encoder)结合关键词 BM25 算法,进行极其细致的打分和二次重排。
- 查询词重写 (Query Transformation / HyDE): 用户的提问往往很短且模糊。让 LLM 先把用户的问题“扩写”或“翻译”一遍,再去向量库里搜,能让命中率提升 30% 以上。
结语
从“把数据切碎扔进向量空间”,到“利用余弦相似度暴力检索”,再到“组装 Prompt 进行降维打击”。真正的 AI 开发从来不是调包,而是掌握这些数据流动背后的物理法则。 只有手写过一次底层管线,你才能在未来使用 LangChain 或者 LlamaIndex 等重型框架时,迅速定位那些隐藏在黑盒里的 Bug。

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐
 10
10 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)