Step 3.5 Flash:11B参数驱动196B级智能推理
Step 3.5 Flash:11B参数驱动196B级智能推理
【免费下载链接】Step-3.5-Flash  项目地址: https://ai.gitcode.com/StepFun/Step-3.5-Flash
项目地址: https://ai.gitcode.com/StepFun/Step-3.5-Flash
导语:StepFun推出的开源大模型Step 3.5 Flash凭借创新的稀疏混合专家(MoE)架构,仅激活11B参数即可实现196B级别的推理能力,在保持高性能的同时大幅提升运行效率,重新定义了大模型的"智能密度"标准。
行业现状:当前大语言模型领域正面临性能与效率的双重挑战。一方面,模型参数量持续攀升至千亿甚至万亿级别以追求更强能力,如Kimi K2的1T参数模型;另一方面,高昂的计算成本和部署门槛限制了技术普惠。据行业报告显示,2025年主流大模型单次推理成本较2023年下降60%,但复杂任务的累计使用成本仍对企业和开发者构成压力。在此背景下,"高效智能"成为突破方向,稀疏激活、混合专家架构等技术逐渐成为行业新焦点。
产品/模型亮点:Step 3.5 Flash通过四大核心创新实现了效率与性能的平衡:
首先是稀疏混合专家架构,模型总参数量达196B,但每生成一个token仅激活约11B参数。这种设计使模型兼具大参数量的"记忆容量"和小模型的"运行速度",在Mac Studio M4 Max等高端消费级硬件上即可实现本地部署。
其次是多token预测技术(MTP-3),通过一次前向传播同时预测4个token,将生成速度提升至100-300 tok/s,峰值编码任务可达350 tok/s,解决了传统大模型"思考快、表达慢"的痛点。
第三是混合注意力机制,采用3:1的滑动窗口注意力(SWA)与全注意力比例,在支持256K超长上下文的同时,计算开销仅为标准长上下文模型的三分之一,特别适合处理代码库、学术论文等长文档。
最后是强化学习自迭代框架,使模型在复杂任务中表现突出:SWE-bench Verified编码任务达74.4%,Terminal-Bench 2.0终端操作任务达51.0%,展现出强大的智能体(Agent)能力。
如图所示,Step 3.5 Flash在推理、编码和智能体三大核心能力上已接近GPT-4等顶级闭源模型,尤其在xbench-DeepSearch等综合评估中得分83.7,显著领先于同量级开源模型。
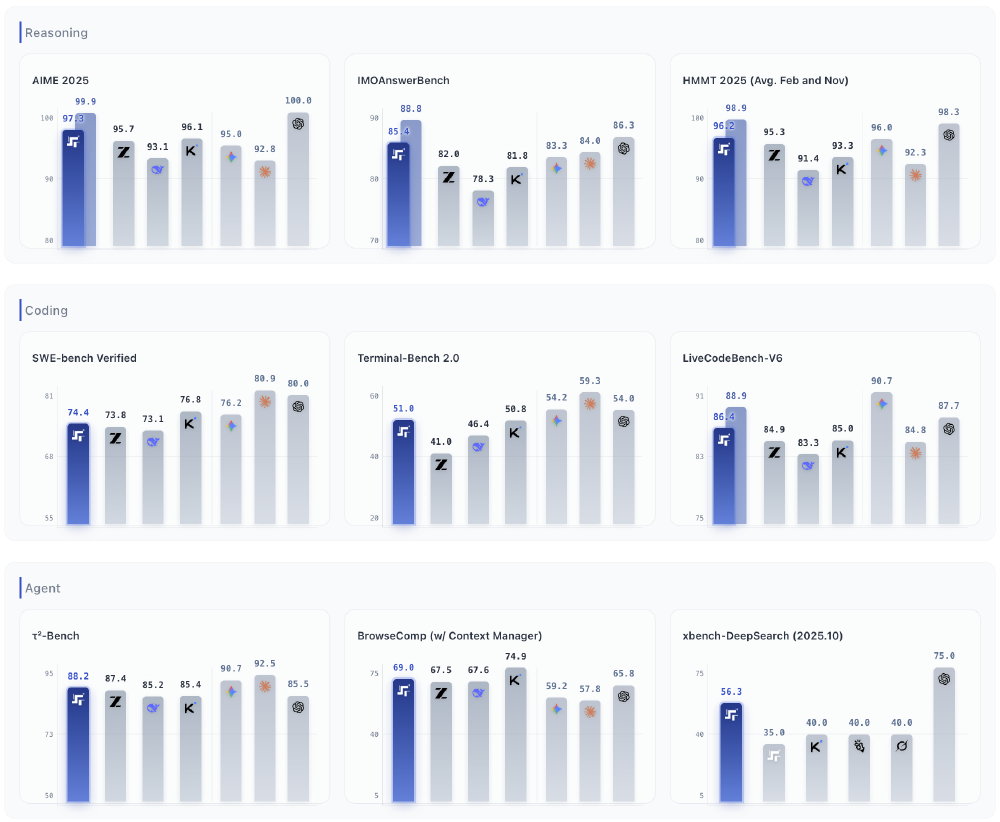
该图表清晰展示了Step 3.5 Flash(蓝色柱子)与其他开源及闭源模型的性能对比。左侧按参数规模排列的开源模型中,Step 3.5 Flash以11B激活参数实现了接近右侧顶级闭源模型的能力,尤其在推理任务上表现突出。阴影部分显示启用Parallel Thinking技术后性能进一步提升,为开发者提供了性能优化的参考方向。
行业影响:Step 3.5 Flash的推出将加速大模型技术的实用化进程。对于企业用户,其高效推理特性可降低智能客服、代码辅助等场景的运营成本;开发者将获得一个兼具高性能和可访问性的研究平台;而终端用户则能在本地设备上享受安全的AI服务,无需担心数据隐私问题。
该模型的技术路线也为行业提供了重要启示:通过架构创新而非单纯增加参数量来提升性能,可能是未来大模型发展的主流方向。据测算,相比同等能力的传统模型,Step 3.5 Flash的推理成本降低约6-18倍,这将极大推动AI技术在资源受限场景的应用。
结论/前瞻:Step 3.5 Flash以"11B参数实现196B级智能"的突破,证明了高效架构设计的巨大潜力。随着模型在vLLM、SGLang等推理框架的支持完善,以及社区对其RL框架的持续优化,我们有理由期待其在智能体开发、复杂任务处理等领域的更多创新应用。未来,"智能密度"——即单位参数产生的智能水平,可能会取代参数量成为衡量大模型价值的核心指标,推动AI技术向更高效、更普惠的方向发展。
【免费下载链接】Step-3.5-Flash 项目地址: https://ai.gitcode.com/StepFun/Step-3.5-Flash

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐

 5
5 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)