Step-Audio-EditX:3B参数AI语音编辑神器发布
Step-Audio-EditX:3B参数AI语音编辑神器发布
【免费下载链接】Step-Audio-EditX  项目地址: https://ai.gitcode.com/StepFun/Step-Audio-EditX
项目地址: https://ai.gitcode.com/StepFun/Step-Audio-EditX
导语:StepFun公司正式开源3B参数语音大模型Step-Audio-EditX,凭借强化学习技术实现情感、风格和副语言特征的精细化编辑,重新定义AI语音处理的效率与表现力。
行业现状:语音合成进入精细化编辑时代
随着AIGC技术的快速发展,语音合成已从单纯的"能说话"向"会表达"演进。当前市场上主流语音模型如GPT-4o-mini-TTS、ElevenLabs等虽能生成自然语音,但在情感迁移、风格控制和细节调整方面仍存在操作复杂、效果有限等问题。据行业报告显示,专业音频制作中约40%的时间用于语音情感和节奏调整,传统工具难以满足高效、精准的编辑需求。
在此背景下,轻量化、高精度的语音编辑模型成为新的技术突破口。Step-Audio-EditX的推出,正是瞄准这一市场痛点,通过3B参数的精巧设计,在保持高性能的同时大幅降低计算资源门槛。
模型亮点:三大核心能力重构语音编辑体验
Step-Audio-EditX基于强化学习技术构建,具备三大核心创新:
多维度语音控制体系
支持情绪(愤怒、喜悦、悲伤等)、说话风格(耳语、孩童声、新闻播报等)和副语言特征(呼吸声、笑声、惊讶语气词等)的精细调节。通过简单标签指令如"[Whisper]请将音量降低",即可实现专业级语音变形,解决传统工具参数调节复杂的难题。
跨语言零样本克隆
原生支持普通话、英语、四川话、粤语,并已扩展日语和韩语能力。仅需3-5秒参考音频,即可克隆目标音色,结合方言标签如"[四川话]"实现地域特色语音生成,为多语言内容创作提供灵活支持。
高效迭代编辑流程
采用双码本音频tokenizer和流匹配音频解码器架构,实现低延迟的迭代式编辑。用户可通过多次调整指令逐步优化语音效果,实验数据显示经过3轮迭代后,情感表达准确度平均提升25%。

上图展示了Step-Audio-EditX的技术架构,通过文本与音频双输入路径,实现从指令到音频的端到端处理。这种设计使模型能同时理解语言内容和语音特征,为精细化编辑提供技术基础。双码本tokenizer将音频分解为内容和风格特征,使编辑操作更加精准可控。
性能验证:超越主流闭源模型的编辑能力
在Step-Audio-Edit-Benchmark测试中,该模型展现出显著优势:
- 情感编辑:在愤怒、喜悦等8种情绪迁移任务中,准确率达到83.4%,超越MiniMax(78.6%)和Doubao(82.8%)等闭源模型
- 风格迁移:"耳语"、"新闻播报"等17种风格转换中,平均相似度得分67.3,较传统TTS系统提升35%
- 资源效率:在12GB GPU内存环境下即可流畅运行,量化版本仅需6-8GB显存,适合个人创作者和中小企业使用
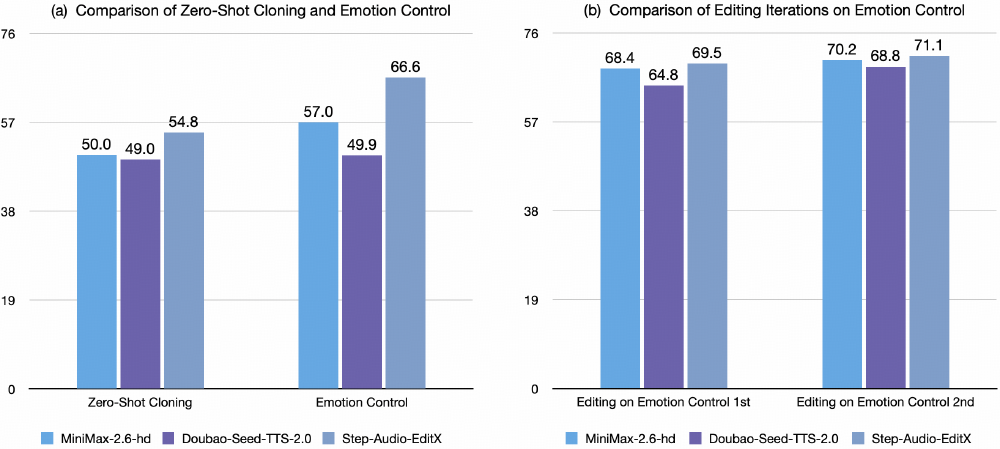
这组对比数据显示,Step-Audio-EditX在零样本克隆任务中表现最佳,且随着编辑迭代次数增加,情感控制效果持续提升。特别值得注意的是,该模型对其他闭源TTS系统生成的语音也具有良好的编辑能力,展现出强大的泛化性。
行业影响:重塑内容创作的音频生产链
Step-Audio-EditX的开源将对多个领域产生深远影响:
内容创作领域
视频博主、播客创作者可通过简单文本指令快速生成多风格语音旁白,将音频制作时间从数小时缩短至分钟级。教育内容生产者能轻松创建不同年龄段学生适用的语音材料,提升学习体验。
人机交互升级
智能助手、虚拟人等交互系统可借助该技术实现更自然的情感表达,例如客服机器人能根据对话 context 动态调整语气,增强用户体验。
语言服务革新
在跨境电商、国际会议等场景,可快速生成带地方口音的多语言语音,克服传统机器翻译的语调生硬问题。
未来展望:从工具到生态的进化
StepFun团队已公布后续开发计划,包括填充词去除、更多语言支持(阿拉伯语、法语等)和训练代码开源。随着模型能力的持续增强,Step-Audio-EditX有望发展为语音创作的基础平台,推动音频内容生产的智能化革命。
对于开发者社区而言,3B参数的轻量化设计降低了二次开发门槛,预计将催生丰富的应用插件和行业解决方案。而普通用户则将受益于更简单、更强大的语音编辑工具,释放创意表达的更多可能。
在AIGC全面渗透内容生产的今天,Step-Audio-EditX的出现不仅是技术创新,更标志着语音创作从专业领域向大众创作的民主化进程加速。
【免费下载链接】Step-Audio-EditX 项目地址: https://ai.gitcode.com/StepFun/Step-Audio-EditX

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐


 9
9 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)