RAG系统如何支持多模态检索?图文检索如何实现?
🚀 本文收录于Github:AI-From-Zero 项目 —— 一个从零开始系统学习 AI 的知识库。如果觉得有帮助,欢迎 ⭐ Star 支持!
RAG系统如何支持多模态检索?图文检索如何实现?
by @Laizhuocheng
一、简介
想象这样一个场景:你打开电商App,看到一件很眼熟的衣服,但不知道叫什么名字。你拍了张照片上传,系统不仅找出了相似的商品图片,还告诉你这件衣服叫"oversized针织开衫",材质是"羊绒混纺",适合"秋冬季节穿搭"。
这就是多模态检索的魅力——让图像和文本能够真正"对话"。
传统文本RAG有一个致命局限:只能处理文字。如果你的知识库里有成千上万张产品图片、医学影像、设计图纸,传统的RAG系统对它们束手无策。最直观的想法可能是给每张图片配文字描述,然后检索这些描述。但这样做有两个问题:
- 丢失了图像本身的视觉信息:一张商品图包含的颜色、款式、质感等视觉特征,很难用文字完全描述清楚
- 无法支持图查文:用户上传一张图片,系统无法理解图片内容去做检索
多模态RAG的诞生就是为了解决这个核心问题:让不同模态的数据能够在同一个语义空间里对话。
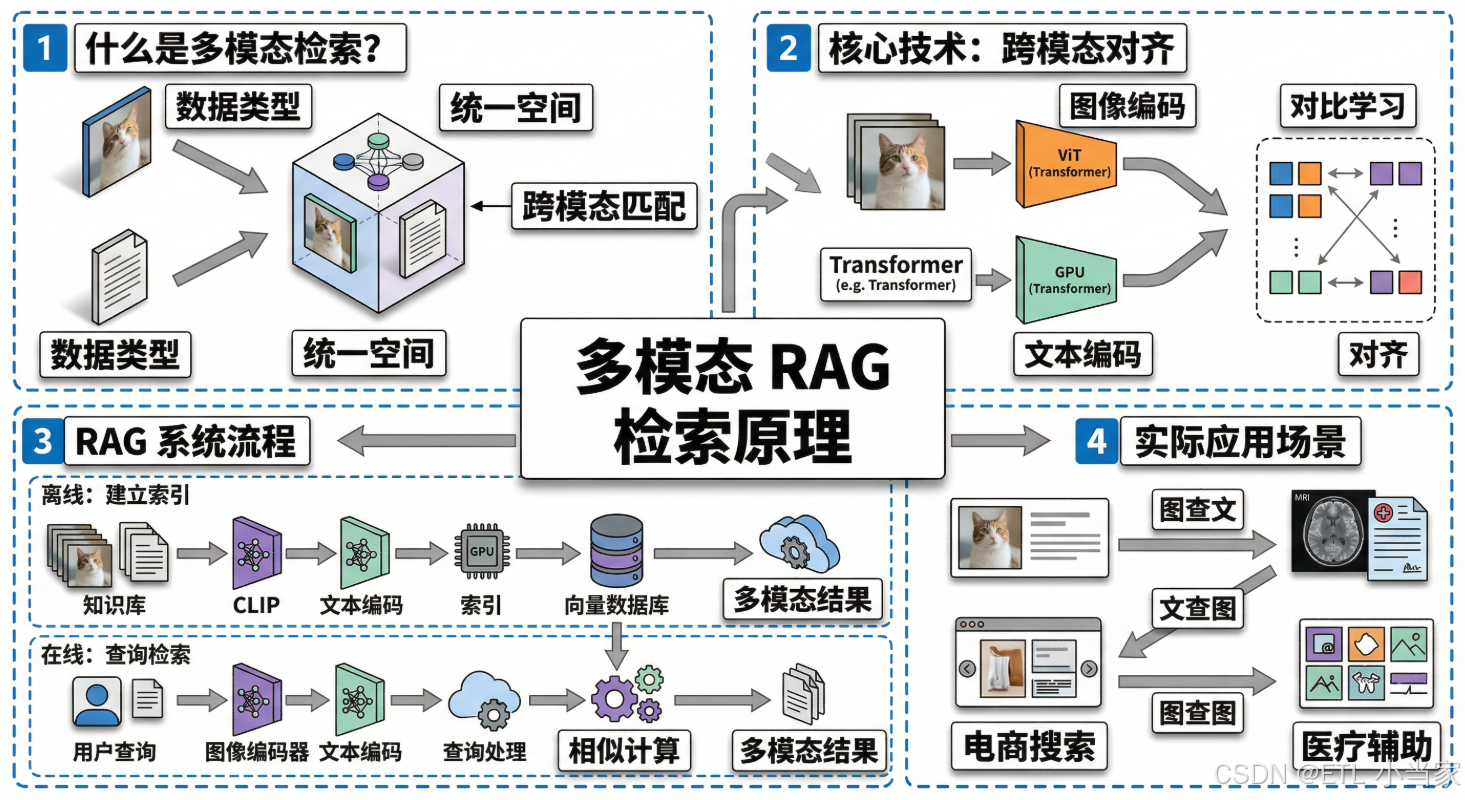
二、什么是多模态检索?
多模态检索(Multimodal Retrieval)是指系统能够处理多种数据类型(如文本、图像、音频、视频等),并将它们映射到统一的向量空间,实现跨模态的相似度匹配。
核心思想:把不同模态的数据转换成"同一种语言",让它们能够相互理解。
举个生动的例子:
- 一张猫的照片(图像模态)
- “一只橘色的猫趴在沙发上”(文本模态)
虽然它们的原始数据完全不同——一个是像素矩阵,一个是token序列,但在经过特殊设计的编码器处理后,它们的向量表示在高维空间中应该距离很近。
这就是所谓的跨模态对齐(Cross-modal Alignment),它是整个多模态RAG系统的理论基础。
多模态检索的三种模式:
| 检索模式 | 查询类型 | 返回类型 | 应用场景 |
|---|---|---|---|
| 文查图 | 文本 | 图像 | “找一件红色连衣裙” |
| 图查文 | 图像 | 文本 | 上传图片找商品描述 |
| 图查图 | 图像 | 图像 | 找相似款式 |
三、多模态检索如何工作
跨模态对齐:从对比学习到统一空间
实现跨模态对齐的关键技术是对比学习(Contrastive Learning),CLIP是这个领域的典型代表。
CLIP的训练原理:
想象一下,你有4亿对图文配对数据,每对包含一张图片和对应的描述文字。训练时:
-
双塔结构:用两个编码器分别处理图片和文字
- 图像编码器:通常是ViT(Vision Transformer)或ResNet
- 文本编码器:通常是Transformer
-
对比目标:让配对的图文向量相似度高,不配对的相似度低
-
具体过程:
- 一个batch里有1000对图文
- 每张图片的向量要和它对应的文字向量距离最近
- 和其他999个文字向量距离尽可能远
为什么双塔结构很重要?
双塔结构的最大优势是编码过程独立,不需要交叉attention。这意味着:
- 预计算:可以提前把知识库的所有图文都编码好存起来
- 快速检索:查询时只需要编码query,然后做向量检索
- 可扩展性:支持百万级甚至千万级的知识库
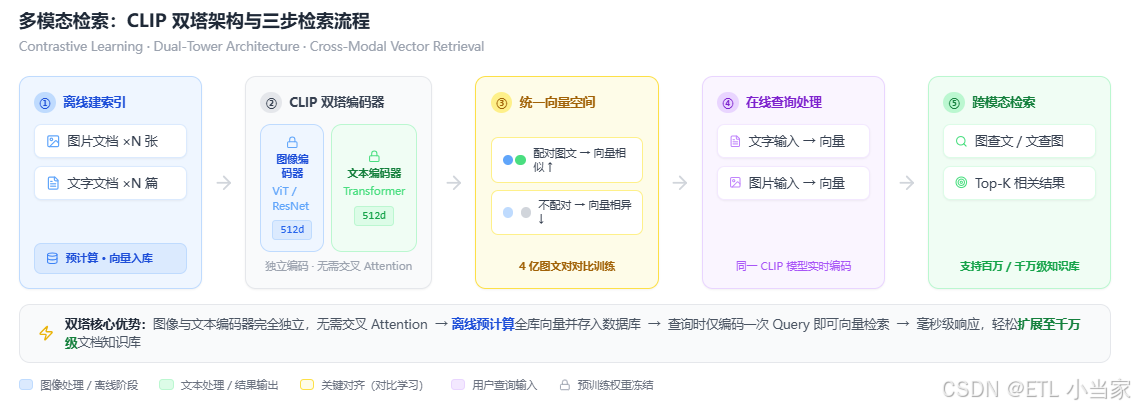
三步实现流程
多模态检索的实现可以分为三个清晰的步骤:
第一步:建立索引(离线阶段)
使用同一个CLIP模型的两个编码器分别处理文本和图像,向量维度统一(通常是512维),元数据中标记模态类型。
关键点:
- 图像和文本使用相同的向量空间
- 可以预计算所有文档的向量,加速检索
- 元数据记录模态类型,便于后续过滤
第二步:查询处理(在线阶段)
查询可以是文本或图像:
- 文本查询:用户输入文字,编码成向量
- 图像查询:用户上传图片,编码成向量
系统都能用同一个模型编码成向量,实现真正的跨模态检索。
第三步:跨模态检索(相似度匹配)
底层都是向量相似度计算,只是元数据过滤不同:
- 图查文:上传图片 → 编码成向量 → 检索文本向量 → 返回相关文字
- 文查图:输入文字 → 编码成向量 → 检索图像向量 → 返回相关图片
模态融合策略
检索回来的结果可能包含多种模态,如何融合这些结果是关键。
特征层面融合(Early Fusion)
在向量层面直接融合不同模态的特征,融合更精细,但计算复杂,无法预计算。
结果层面融合(Late Fusion)
分别检索不同模态的结果,然后在结果层面做重排序,灵活可控,支持模态过滤。
四、多模态检索的优缺点
| 优势 | 劣势 |
|---|---|
| 支持跨模态查询:图查文、文查图、图查图 | 模型训练成本高:需要大量图文配对数据 |
| 保留视觉信息:不丢失图像的原始特征 | 向量维度高:存储和检索成本增加 |
| 检索更精准:语义相似度匹配比关键词匹配更准 | 模态不平衡问题:容易偏向数据量大的模态 |
| 用户体验好:支持更自然的交互方式 | 工程复杂度高:需要处理多模态元数据 |
| 知识利用率高:能够挖掘不同模态间的关联 | 标注成本高:需要大量高质量的图文配对数据 |
| 创新应用场景多:支持前所未有的交互模式 | 计算资源消耗大:图像编码比文本编码消耗更多资源 |
五、多模态检索的实际应用与发展趋势
实际应用场景
1. 电商商品搜索
场景:用户上传一张衣服图片,找相似商品
工作流程:
- 用户上传图片
- CLIP图像编码器生成512维向量
- 在向量库中检索相似商品图片(图查图)
- 同时检索商品描述文本(图查文)
- 融合结果返回给用户
效果:
- 相似度提升:从关键词匹配的60%提升到语义匹配的85%
- 转化率提升:用户找到心仪商品的概率提高30%
- 长尾商品曝光:通过视觉特征匹配到冷门但相似的商品
2. 医学影像分析
场景:医生输入"肺部结节",检索相似病例
工作流程:
- 医生输入文本查询"肺部结节"
- 或上传一张CT影像
- 检索相似的医学影像(文查图/图查图)
- 同时检索相关的病历文本、诊断报告(文查文/图查文)
- 返回完整的病例信息
价值:
- 辅助诊断:快速找到相似病例作为参考
- 知识沉淀:把影像和文本关联,形成可检索的知识库
- 教学培训:医学生可以通过检索学习典型病例
效果:
- 诊断效率:从平均10分钟缩短到3分钟
- 准确率:相似病例检索准确率达到90%+
- 知识利用率:历史病例利用率提升5倍
3. 工业质检
场景:制造业缺陷检测
工作流程:
- 拍摄当前产品的质检照片
- 检索历史数据库中的相似缺陷案例
- 关联到当时的维修工单、工艺调整记录
- 提供处理建议
价值:
- 快速定位问题:找到历史上类似的缺陷案例
- 可追溯的知识闭环:把视觉异常和对应的处理记录关联起来
- 经验传承:老师傅的经验通过图文检索传承给新人
4. 设计素材检索
场景:设计师找灵感素材
工作流程:
- 设计师上传一张参考图片(如海报设计)
- 检索相似的设计作品
- 同时检索相关的设计理念、配色方案文本
- 提供完整的灵感素材包
价值:
- 创意启发:通过视觉相似度找到灵感
- 风格保持:确保设计风格一致性
- 效率提升:减少素材搜索时间
当前局限性
冷启动问题:
新上架的商品或新增的图片可能没有足够的图文配对数据,CLIP编码出来的向量质量不稳定。解决方案是人工标注一些种子数据做微调。
模态不平衡:
如果商品库里图片占90%,文本只占10%,检索时容易偏向图片结果。需要在重排序时做模态均衡,比如调整文本和图像的权重。
向量更新策略:
商品信息会变化(如价格调整、库存更新),向量也要更新。全量重建成本太高,需要设计增量更新机制,比如每天凌晨只更新变更的数据。
性能挑战:
生产环境最大的挑战是QPS和延迟。假设系统要支持1000 QPS,单次CLIP推理大概50ms,向量检索10ms,单机根本扛不住。
发展与演进
优化策略:
模型推理加速:
使用ONNX Runtime加载量化模型,推理速度提升2-3倍,精度损失<1%。在NVIDIA GPU上进一步优化,多个query合并编码,提升GPU利用率。
缓存优化:
使用Redis缓存热门query的向量,减少90%的重复编码,响应时间从50ms降低到5ms,GPU利用率降低40%。
混合检索:
先用商品类目过滤,再用BM25做一次粗筛,最后向量精排。候选集从百万级降到几万级,检索速度提升5-10倍。
未来展望:
多模态大模型与RAG深度结合:
现在的CLIP主要做语义对齐,但推理能力有限。像GPT-4V这种视觉语言模型出现后,我们可以把检索和生成更紧密地结合,从单纯的检索走向理解+生成的完整链路。
实时多模态学习:
未来可能会出现能够实时学习新模态的RAG系统。用户上传一张新类型的图片,系统能够在线学习这种新模态的特征,下次遇到类似图片时能够准确检索。
多模态知识图谱:
把多模态检索和知识图谱结合起来:图片→实体识别→知识图谱→关联推理。不仅能找到相似图片,还能推理出"这张图片里的建筑是什么风格?"“这个产品的设计师是谁?”
跨语言多模态检索:
支持不同语言的文本和图像进行跨语言、跨模态的检索。比如用中文描述检索英文商品图片,或者用日文描述检索中文设计素材。
六、总结与思考
多模态检索的本质是跨模态对齐,通过对比学习让不同模态的数据在统一的向量空间中对话。实现上分为三步:建立索引、查询处理、跨模态检索。关键技术是双塔结构的多模态编码器(如CLIP),工程上需要考虑性能优化、模态平衡、增量更新等问题。
多模态检索的价值不仅在于技术实现,更在于它打破了不同模态之间的壁垒,创造了前所未有的交互方式。它让机器能够像人类一样,通过多种感官(视觉、听觉、文字)来理解和检索信息,这是人工智能向更自然、更智能方向发展的重要一步。
总结:多模态检索通过跨模态对齐技术,实现了不同数据类型在同一语义空间的对话。它不仅提升了检索的准确性和效率,更重要的是创造了全新的应用场景和用户体验。
思考:人类的感知和认知本来就是多模态的——我们看图、读字、听声音,所有这些信息在大脑中融合成统一的理解。多模态AI的发展,正是在模拟这种自然的智能方式。真正的智能不在于单一模态的极致,而在于多模态信息的融合与理解。这不仅是一个技术挑战,更是对智能本质的探索。

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐



 8
8 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)