vllm单机双卡部署Qwen3 30B FP8模型踩坑记录
参考:https://adg.csdn.net/694cfd845b9f5f31781abf2b.html?spm=1001.2101.3001.6650.2&utm_medium=distribute.pc_relevant.none-task-blog-2~default~BlogOpenSearchComplete~activity-2-154947197-blog-158834889.235%5Ev43%5Epc_blog_bottom_relevance_base1&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2~default~BlogOpenSearchComplete~activity-2-154947197-blog-158834889.235%5Ev43%5Epc_blog_bottom_relevance_base1&utm_relevant_index=2
作者在部署Qwen3-30B模型到双4090工作站时遇到显存不足和推理标签异常两大问题。通过不断尝试试错,最终摸索出采用强制使用vllm V0引擎、修改模型配置文件的解决办法,完美解决了上述问题。
编辑 『养乐多多』 · 2025-11-17 22:01:32 发布
一、背景
单位搞建设,配了台双4090的工作站,想着终于能部署个大点的模型了,根据显存大小,打算部署Qwen3的30B模型,结果反复遇到问题……
二、部署环境
1.硬件
CPU:双路至强
内存:256G
GPU:4090 24G*2
2.软件
后端:GPUStack 0.7.1 集成vllm 0.10.1.1
前端:Open-WebUI 0.6.36
模型:Qwen3-30B-A3B-Thinking-2507-FP8
三、艰难的部署历程
问题1:模型启动阶段爆显存
尝试1:
模型可以进入启动阶段,预估显存也是充足的,尝试过如下参数调整:
--max-model-len最低调到2048,无法启动成功
--swap-space=32,无用
--cpu-offload-gb=16,无用
尝试2:
最开始想用fp8进行计算,设置—dtype,但是支持的参数列表里并没有fp8,强制设置后启动直接报错,显示不支持fp8,无法启动成功。
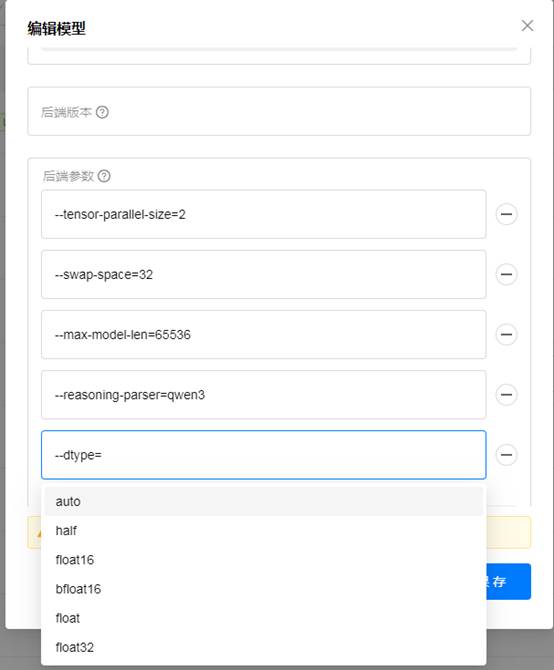
尝试3:
dtype不行,继续研究,有个—kv-cache-dtype支持fp8。
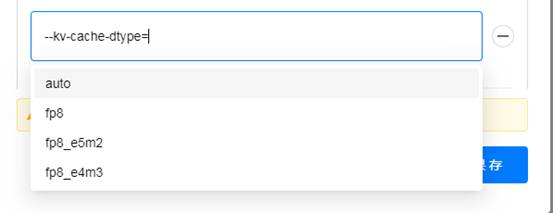
想着KV cache也不小,能把这个减小了也行,尝试了一下,观察了vllm启动的日志,突然发现不一样了,如果kv-cache-dtype设置为fp8的话,vllm自动退回V0引擎启动模型(默认在Ampere、Hopper等较新的架构上使用V1引擎),然后就启动成功了!目前看来有可能是V1引擎的一些缓存优化机制占用了太多显存。
最终解决方案:
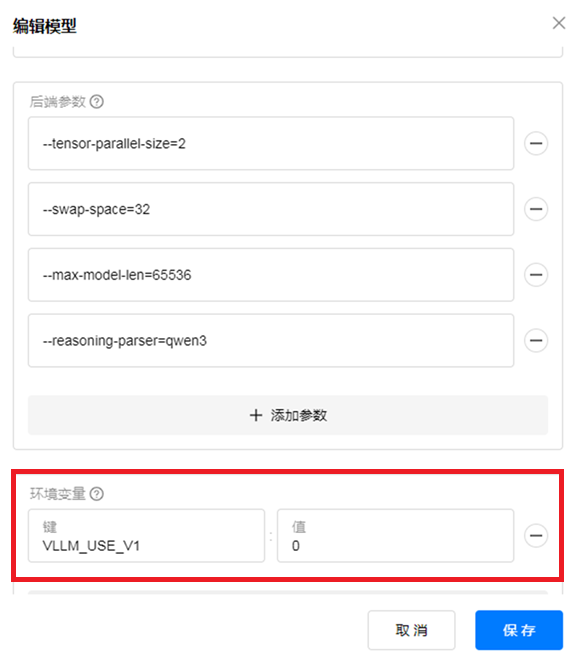
修改vllm的环境变量,强制启用v0引擎,再把max-model-len调大,我这里最大可以开到100K左右,先设置64K用着。
我这里用的是gpustack,在模型的编辑界面加上环境变量【VLLM_USE_V1】即可,值为0。直接使用VLLM的话同理修改环境变量即可。
问题2:推理过程作为结果输出
模型虽然能跑了,但是模型一开始不输出<think>标签,推理过程被前端当作结果输出,没有【正在思考】的提示,而且推理结束后还会输出一个</think>标签,很不方便阅读。
尝试1:
修改提示词,让模型在推理过程中先输出<think>标签,无效,甚至因为模型在思考这个问题,多次输出了<think>标签,导致了前端解析的异常。
尝试2:
修改vllm参数,配置--reasoning-parser=qwen3,无效,这个只能解决引擎无法正确识别模型输出的<think>标签的问题,我这里是模型完全没有输出<think>标签,不是同样的问题。
尝试3:
修改前端open-webui关于推理标签的参数,不填写起始标签,将结束标签设置为【</think>】。
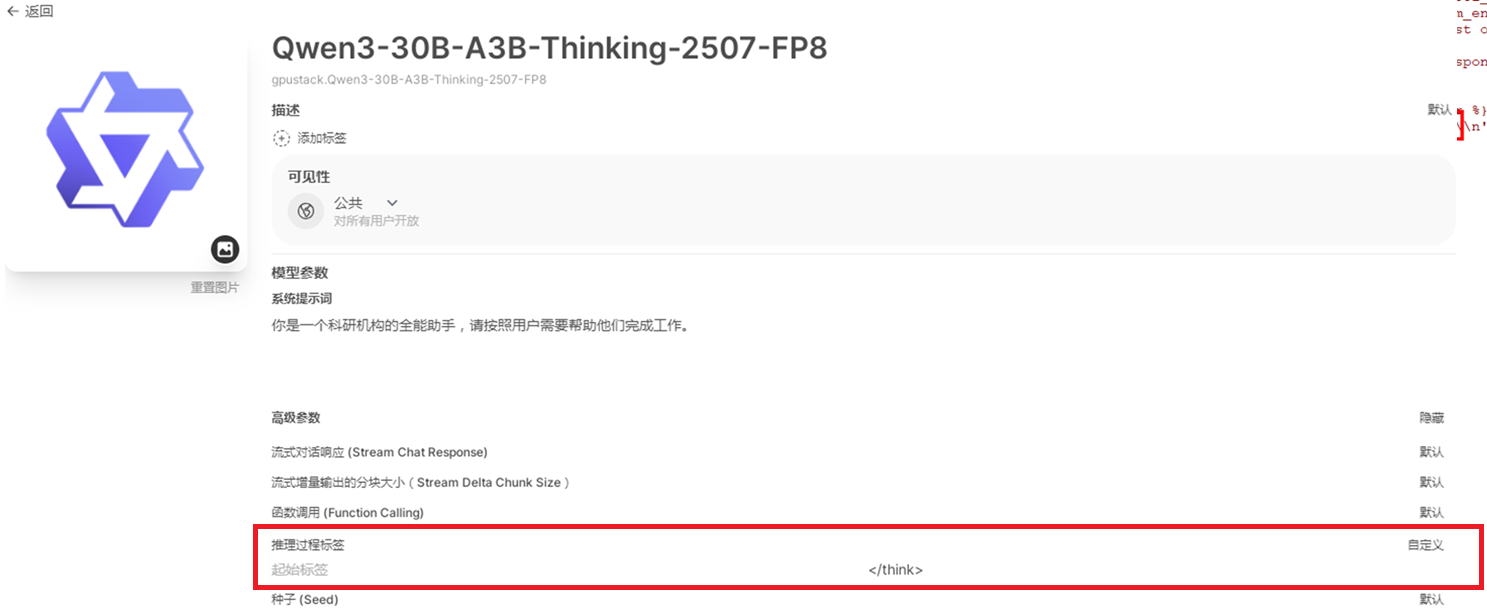
然而这个设置会导致模型最后输出的结果也被认为是推理过程,不完美。

尝试4:
查看模型的配置文件,网上找到类似的问题首先要查看模型的tokenizer_config.json文件中有没有关于<think>标签的定义,我看了下,文件里确实有。
然后我对比了Qwen3-30B-A3B-Thinking-2507-AWQ模型的配置,终于发现了问题所在,FP8这个模型的对话模板配置里多了个<think>……所以我想问问阿里的团队,是因为2507版以后推理和非推理模型分离,推理模型开启强制思考吗?
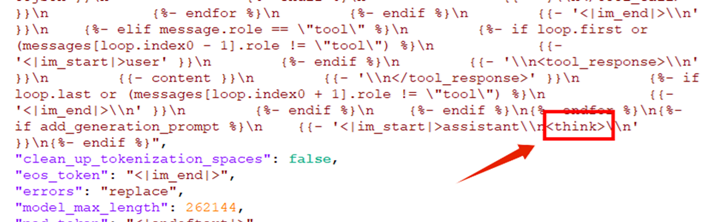
Qwen3-30B-A3B-Thinking-2507-FP8的tokenizer_config.json
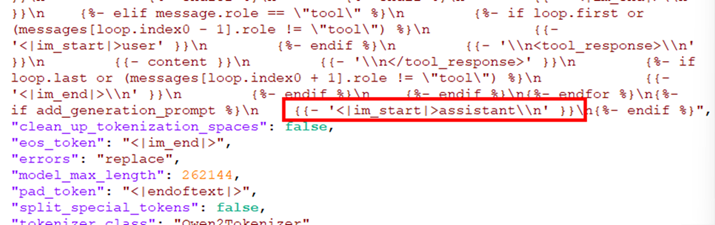
Qwen3-30B-A3B-Thinking-2507-AWQ的tokenizer_config.json
最终解决方案:
直接用AWQ模型的tokenizer_config.json文件覆盖FP8模型的配置文件,然后重启模型,终于正常了!

至此,问题全部解决,完结撒花!

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐
 8
8 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)