从 ReAct 到 Multi-Agent:AI Agent 的工程架构演进
一个反直觉的事实
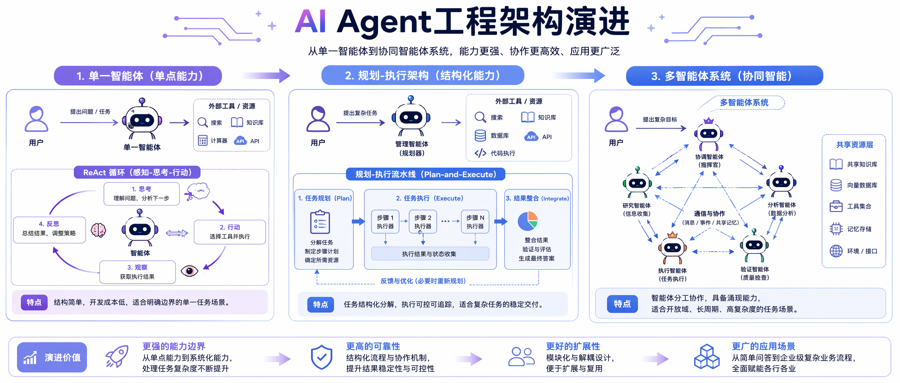
2024年初,大部分人对 AI Agent 的想象还停留在"让 GPT-4 调用几个 API"。到了2026年,生产环境里跑的单 Agent 系统可能涉及 20 多个工具调用、数百轮推理循环,而 Multi-Agent 系统则像一个小型技术团队——有架构师、有程序员、有测试员,彼此用协议通信、用投票做决策。
Agent 架构的复杂度,正在从"写一个 prompt"跃迁到"设计一个分布式系统"。这不是炒作,而是有明确工程驱动力的演化:当单 Agent 的推理链长度超过某个阈值后,错误会指数级累积;而把一个复杂任务拆给多个专业化 Agent,可以用"分而治之"换取整体可靠性。
类比一下:一个人独立完成一栋房子的设计、施工、装修,出错概率极高;而一个施工队里,设计师画图纸、泥瓦工砌墙、电工布线,每人只干自己擅长的,整体效率和质量反而更高。Multi-Agent 系统本质上就是在模拟这种"施工队协作"。
ReAct:推理+行动的最小闭环
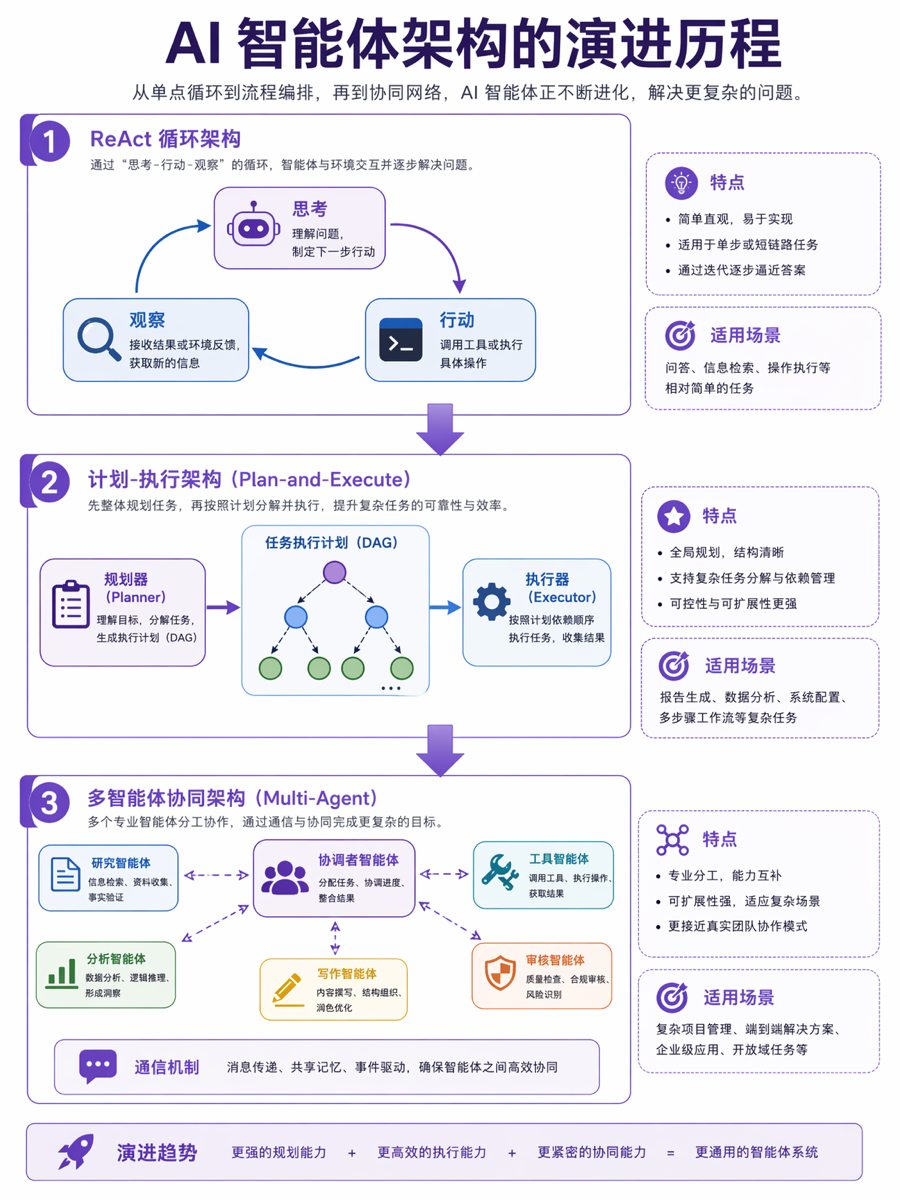
Agent 架构的起点是 2022年10月 Princeton 和 Google 联合提出的 ReAct(Reasoning + Acting) 范式 [^arxiv-react]。在此之前,LLM 的推理(Chain-of-Thought)和行动(Tool Use)是两条独立的研究线:CoT 只会在脑子里"想",不会动手查资料;Act-only 只会调用工具,但缺乏对任务的全局推理。
ReAct 把两者缝合成一个交替循环:
思考(Thought) -> 行动(Action) -> 观察(Observation) -> 思考(Thought) -> …
每一步,模型先输出一段自然语言推理(“我需要查一下巴黎的人口”),然后基于这个推理决定调用什么工具(Search[Paris population]),拿到结果后再继续推理。这个循环一直持续到任务完成或达到最大步数。
论文作者用 PaLM-540B 做了三组实验,数据很能说明问题:
• HotpotQA(多跳问答,EM 指标):纯 CoT 29.4%,纯 Act 25.7%,ReAct 最佳配置达到 35.1%。ReAct 不是每一项都碾压,但它在需要"推理指导行动"的环节优势明显。
• FEVER(事实验证,准确率):纯 Act 58.9%,ReAct 达到 64.6%。这里的关键是 ReAct 的推理轨迹会暴露模型自己的"幻觉"——当推理链里出现"我假设 X 成立"时,模型往往会接着用行动去验证这个假设。
• AlfWorld(文本环境决策,成功率):纯 Act 45%,ReAct 71%。在这个需要长期规划的居家任务模拟器里,没有推理的行动会像无头苍蝇一样乱点家具。
ReAct 的局限性也很明显:它是贪婪的。每一步只做局部最优决策,没有全局规划。如果一个任务需要 10 步完成,第 3 步的最优选择可能导致第 8 步陷入死胡同。就像开车只看下一个路口的红绿灯,从不看导航路线。
Plan-and-Execute:先规划再执行的扩展
为了解决 ReAct 的短视问题,业界在 2023 年发展出了 Plan-and-Execute 架构。核心思想很简单:不要把推理和行动混在一起,而是先让一个"规划器"(Planner)把任务拆成子任务列表,再逐个执行。
这个概念有两个重要的学术来源。一是 ACL 2023 的 Plan-and-Solve(PS)提示 [^arxiv-ps],作者在 GSM8K 数学推理任务上做了验证:Zero-Shot-CoT 准确率 56.4%,PS 提升到 58.2%,加强版 PS+ 达到 59.3%。虽然绝对提升只有 3 个百分点,但 PS+ 把计算错误率从 7% 降到了 5%——说明"先规划再计算"确实能减少执行阶段的低级错误。
二是 2023年底提出的 LLMCompiler [^arxiv-llmc],它把 Plan-and-Execute 推向了工程化:Planner 生成有向无环图(DAG),任务抓取单元(Task Fetching Unit)按依赖关系调度执行,Executor 并行调用工具。与顺序执行的 ReAct 相比,LLMCompiler 实现了 最高 3.7 倍的延迟加速,同时准确率提升约 9%。
类比一下:ReAct 像边做饭边想下一步加什么调料;Plan-and-Execute 像先看完一整本菜谱,列出备料清单,然后开火。前者适合简单菜,后者适合年夜饭。
Plan-and-Execute 的伪代码骨架如下:
def plan_and_execute(task, tools, llm):
# Step 1: Planning
plan = llm.generate(f"把以下任务拆成子任务列表: {task}")
steps = parse_steps(plan) # e.g., [“查天气”, “查路线”, “推荐餐厅”]
# Step 2: Execution with state
state = {"task": task, "results": {}}
for step in steps:
action = llm.generate(f"基于当前状态执行: {step}\n状态: {state}")
observation = tools.execute(action)
state["results"][step] = observation
# Step 3: Synthesis
answer = llm.generate(f"综合所有结果回答问题: {state}")
return answer
这里的关键设计是 state——一个显式的状态字典,把每步的执行结果累积起来。ReAct 的状态隐含在对话历史里,模型需要自己从长上下文中"回忆"之前的结果;Plan-and-Execute 把状态外化,降低了记忆负担,也方便人类介入调试。
但 Plan-and-Execute 有一个致命弱点:计划赶不上变化。如果执行到第 3 步时发现第 1 步的结果是错的,整个计划就需要重排。2024 年 LangChain 提出的 “Plan-and-Execute with Re-planning” 方案就是在执行循环里加一个重规划触发器:当某步执行结果与预期偏差超过阈值时,调用 Planner 重新生成剩余步骤。
Multi-Agent:多个 Agent 怎么协作
Plan-and-Execute 解决的是"一个 Agent 怎么更有条理地做事"。但当任务本身需要多种专业能力时——比如写一个全栈项目需要产品、前端、后端、测试——单 Agent 换再多 prompt 也模拟不出真正的专业分工。这是 Multi-Agent 系统的出发点。
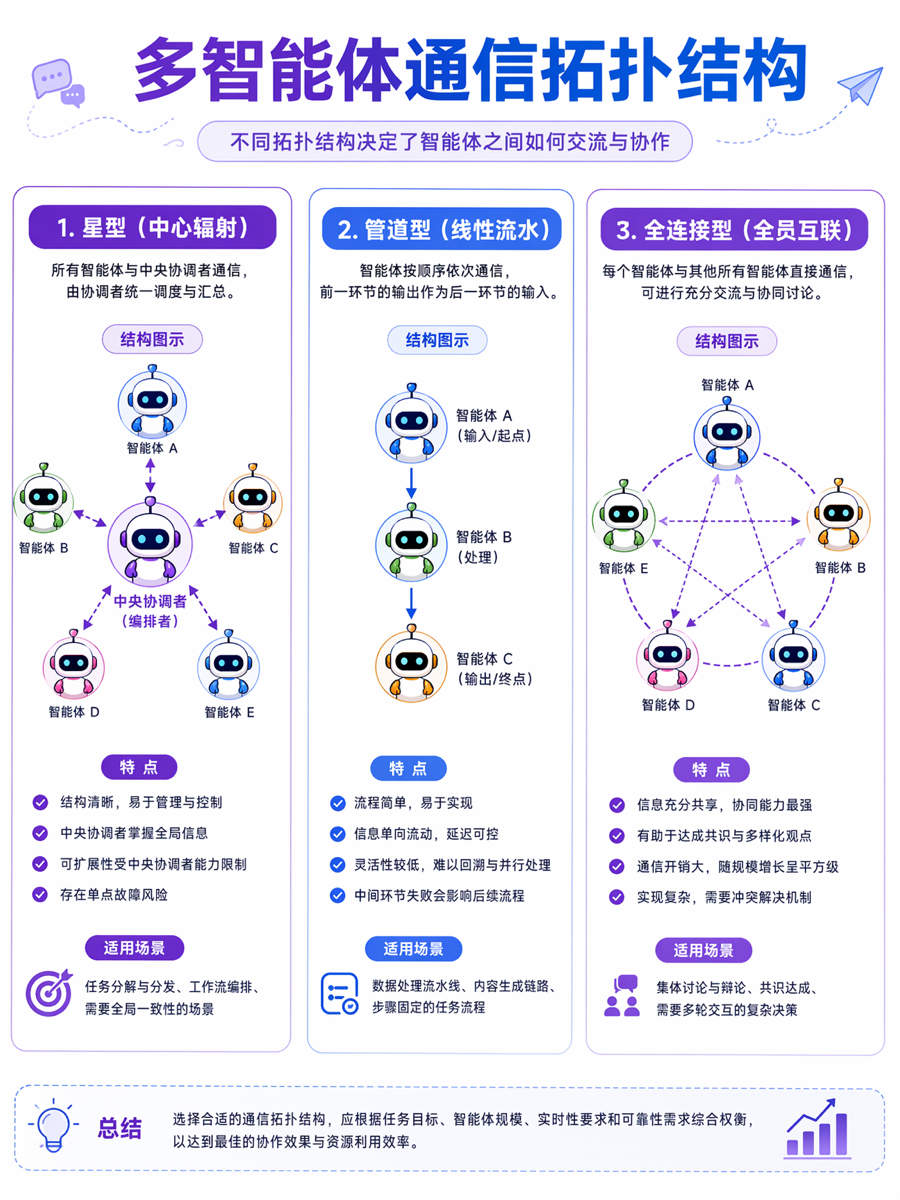
通信拓扑:谁跟谁说
Multi-Agent 系统的第一层设计是通信拓扑。2026年1月的一篇综述 [^arxiv-orchestration] 把常见的拓扑归纳为三类:
-
星型(Hub-and-Spoke):一个中央 orchestrator 接收任务,分发给各 worker Agent,再汇总结果。这是 AutoGen [^arxiv-autogen] 和 CrewAI 的默认模式。优点是控制集中、调试简单;缺点是 orchestrator 是单点瓶颈,且所有上下文都汇聚到中心节点,容易爆上下文窗口。
-
流水线(Pipeline):Agent A 的输出作为 Agent B 的输入,依次传递。LangGraph 的图结构天然适合这种模式。适合有明确先后顺序的任务(如:需求分析 -> 架构设计 -> 编码 -> 测试)。
-
全连接/辩论(Fully-connected / Debate):多个 Agent 同时处理同一问题,然后互相辩论、投票达成共识。NeurIPS 2025 的一篇论文 [^neurips-debate] 发现,多 Agent 辩论中的性能提升主要来自多数投票(Majority Voting),而非辩论本身。这是一个重要的反直觉结论:你把三个 Agent 叫来开会辩论,效果可能不如让它们各自独立作答然后取多数票。
调度机制:任务怎么分
通信拓扑决定了"谁能跟谁说话",调度机制决定"话什么时候说"。
最简单的调度是静态分派:任务开始前就划定每个 Agent 的职责(CrewAI 的 Role-Based 设计)。一个 Agent 永远当研究员,另一个永远当写手。这好理解,但不够灵活——如果研究员发现某个问题需要代码验证,它没有执行权限,只能把需求写进共享文档等别人来读。
更高级的是动态调度。2025 年的 ProtocolRouter 研究 [^openreview-protocol] 提出:根据任务特征自动选择通信协议,能把完成时间缩短最多 36%,协议切换开销控制在 3.5 秒以内,整体性能提升 18%。核心思路是:简单任务用星型(低延迟),复杂任务用分层拓扑(高容错)。
冲突解决:意见不一致怎么办
Multi-Agent 系统里,冲突是常态。两个 Agent 对同一问题的回答矛盾,怎么办?
工程上常见的三种策略:
• 投票(Voting):奇数个 Agent 各给一票,少数服从多数。NeurIPS 2025 的实验表明,这是性价比最高的方案。
• 监督者裁决(Supervisor Override):由一个更强模型(如 GPT-4.5 或 Claude 4)担任仲裁员。成本更高,但适合高 stakes 决策。
• 置信度加权(Confidence Weighting):每个 Agent 输出答案时同时输出置信度分数,用加权平均做最终决策。这需要模型对自身不确定性有较好的校准能力,目前 GPT-4 系列在这方面相对可靠。
AutoGen 的原始论文里提到一个有趣的发现:在数学和代码任务上,引入一个"批评者 Agent"(Critic)专门挑其他 Agent 的错误,能把最终答案的准确率提升 10-15%。但批评者不能太毒舌——如果批评意见过于冗长,会把整个系统的 token 消耗翻两三倍。
一个极简的 Multi-Agent 协作伪代码
class Agent:
def __init__(self, role, llm, tools):
self.role = role
self.llm = llm
self.tools = tools
def run(self, task, context):
prompt = f"你是{self.role}。任务:{task}\n上下文:{context}"
return self.llm.generate(prompt)
class MultiAgentSystem:
def __init__(self, agents, orchestrator):
self.agents = agents
self.orchestrator = orchestrator
def execute(self, task):
# 1. 规划
plan = self.orchestrator.plan(task, [a.role for a in self.agents])
# 2. 分派与执行
context = {}
for step in plan.steps:
agent = self.agents[step.agent\_id]
result = agent.run(step.description, context)
context[step.name] = result
# 3. 共识(如果有冲突)
if len(plan.steps) > 1 and plan.require\_consensus:
answers = [context[s.name] for s in plan.steps]
final = majority\_vote(answers)
return final
return context[plan.steps[-1].name]
性能对比与选型建议
到了 2026 年,选 Agent 架构已经不能凭直觉。以下是基于公开 benchmark 和论文数据的硬对比:
| 架构 | 延迟 | 准确率 | 适用场景 | 代表框架 |
| ReAct | 低(顺序执行) | 中等 | 工具调用 < 5 步的简单查询 | LangChain Agents |
| Plan-and-Execute | 中(DAG 可部分并行) | 中高 | 需要多步规划的中等复杂度任务 | LangGraph, LLMCompiler |
| Multi-Agent(静态角色) | 高(多轮通信) | 高(任务匹配度高时) | 需要专业分工的复杂工作流 | CrewAI, AutoGen |
| Multi-Agent(动态调度) | 中-高 | 高 | 任务类型多变、需要自适应分工 | ProtocolRouter + AutoGen |
更关键的发现来自 2025 年的一篇反直觉论文 [^arxiv-single-vs-multi]:在同质任务(比如纯代码生成、纯数学推理)上,一个精心调优的单 Agent(论文里叫 OneFlow)可以达到 92.1% 的 HumanEval 通过率,而同等预算下的 Multi-Agent 系统是 91.1%——单 Agent 不仅更快,还更省 token(节省 53.7%)和延迟(降低 49.5%)。
Multi-Agent 真正的价值出现在异质任务上:当任务需要"查资料+写代码+画图+做测试"这种跨领域组合时,专业分工带来的收益才能覆盖通信开销。
选型建议可以总结成一句话:先单后多。从 ReAct 开始,遇到规划困难时升级到 Plan-and-Execute,只有当任务明确需要多个专业角色协作时,才引入 Multi-Agent。否则你就是在用施工队的配置刷一面墙。
局限与下一步
当前 Agent 架构有三大硬约束。
第一,上下文窗口是隐形天花板。 Multi-Agent 系统里,每个 Agent 都要读共享状态、读对话历史。当项目规模扩大,上下文从 8K 涨到 128K 甚至 1M,token 成本会线性甚至超线性增长。Claude Sonnet 4.5 在 SWE-bench Verified 上用 1M 上下文能推到 78.2%,高算力模式 82.0% [^anthropic-sonnet45]——但这背后是巨额的推理成本。
第二,通信协议还在混战。 2024年底 Anthropic 推出 MCP(Model Context Protocol)[^anthropic-mcp],2025年 Google 推出 A2A(Agent-to-Agent)[^a2a]。两个协议定位不同:MCP 管"Agent 怎么调工具",A2A 管"Agent 怎么跟 Agent 对话"。但生态尚未统一,生产环境里往往要同时维护两套 adapter。
第三,评估基准严重滞后。 TravelPlanner benchmark [^arxiv-travel] 显示,即使是 GPT-4,在真实旅行规划任务上的成功率也只有 0.6%——不是模型不够聪明,而是现有 benchmark 无法刻画"长期规划+多约束满足"的真实难度。Agent 架构的进步速度,已经超过了我们测量它的能力。
下一步值得关注的方向有两个。一是 Agent Workflow Memory [^arxiv-awm],让 Agent 从过去的执行记录里自动提取可复用的工作流模板,而不是每次从零推理。二是 自反思机制 的工程化:Reflexion [^arxiv-reflexion] 在 HumanEval 上把 pass@1 从 GPT-4 的 80% 推到了 91%,核心是给 Agent 配备一个"错题本"——每次失败后不更新模型权重,而是把失败原因写成自然语言记进记忆,下次遇到类似任务时检索参考。
Agent 架构的演进远未结束。从 ReAct 的一个 Thought-Action 循环,到 Multi-Agent 的分布式协作系统,本质上是在回答一个工程问题:怎么让 LLM 的推理能力,在复杂任务里不被自身的短视和幻觉拖垮。目前的解法都不完美,但方向已经清晰:更明确的规划、更专业的分工、更系统的记忆——说白了,就是教 LLM 像工程师一样工作,而不只是像作家一样说话。
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐

 7
7 0
0- 0



 已为社区贡献92条内容
已为社区贡献92条内容

所有评论(0)