别被代码吓跑!普通人3步搞定AI视频神器——Pixelle-Video - AI 全自动短视频引擎(附避坑)
我一个做自媒体运营的朋友找我吐槽:她每天要剪3-5条短视频发抖音和小红书,每条从找素材、写脚本、配音到剪辑,少则两小时多则半天。她不是技术背景,面对各种”AI视频生成工具”要么是英文界面劝退,要么要付费订阅,要么需要本地GPU。
我想起之前在GitHub上看到过一个开源项目Pixelle-Video,一个全自动的AI短视频引擎——你只需输入一句话描述,它自动完成脚本生成、素材搜索、配音合成、视频剪辑全流程。后台接的大模型是智谱的GLM系列,视频合成用FFmpeg,素材来源支持Pexels和Pixabay的免费素材库。
关键问题是:它需要API调用大模型。朋友需要一个国内可直接访问且性价比高的模型API。
解决方案:蓝耘MaaS平台的GLM-5.1模型。
目录
一、选型与蓝耘的作用
Pixelle-Video默认调用云端大模型API。翻了一下蓝耘的模型广场,智谱GLM-5.1在创意写作和内容生成方面口碑不错。关键是蓝耘支持国内直接访问,不需要代理,支付宝就能充值。
我去蓝耘的模型广场查了一下GLM-5.1的定价:输入0.5元/百万token,输出2元/百万token。手动算了一下:一条短视频脚本(300-500字)平均消耗约3000-5000 token,成本约0.3-0.8分钱。也就是说生成100条视频脚本的总成本不到8毛钱。
这个价格对比我朋友之前用的某SaaS视频生成工具(月费299元、每月100条额度),差距不是一点半点。
二、Windows环境部署
2.1 前置条件
Pixelle-Video的运行依赖Python 3.9+和FFmpeg。我朋友的电脑是Windows 11,正好拿来实操。
安装FFmpeg:
去 https://ffmpeg.org/download.html 下载Windows版本,解压后把bin目录加到系统环境变量PATH里。验证:
ffmpeg -version克隆项目:
git clone https://github.com/AIDC-AI/Pixelle-Video.git
cd Pixelle-Video
随后,我们将启动构建流程。由于国内网络环境的特殊性,建议在构建时开启镜像加速。
💡 终端语法差异提示: 如果你使用的是 PowerShell,环境变量的声明方式较为优雅,需用 $env: 起头,并用分号 ; 衔接后续命令:
$env:USE_CN_MIRROR="true"; docker compose build --no-cache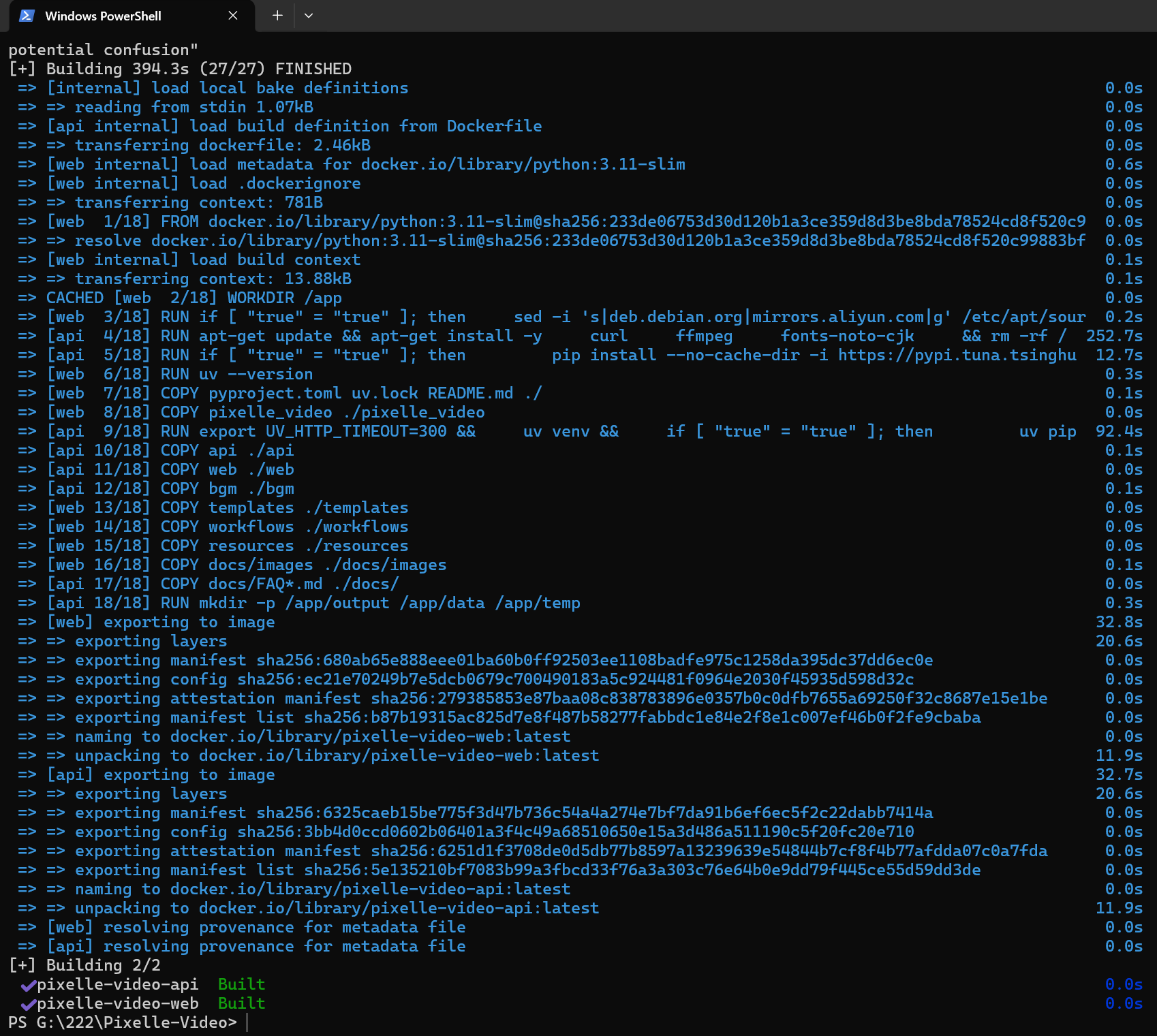
等构建完成后,再运行启动命令(同样带上环境变量):
$env:USE_CN_MIRROR="true"; docker compose up -d
若你更偏爱传统的 CMD 命令行,则使用 set 与 && 的组合:
set USE_CN_MIRROR=true && docker compose build --no-cache
set USE_CN_MIRROR=true && docker compose up -d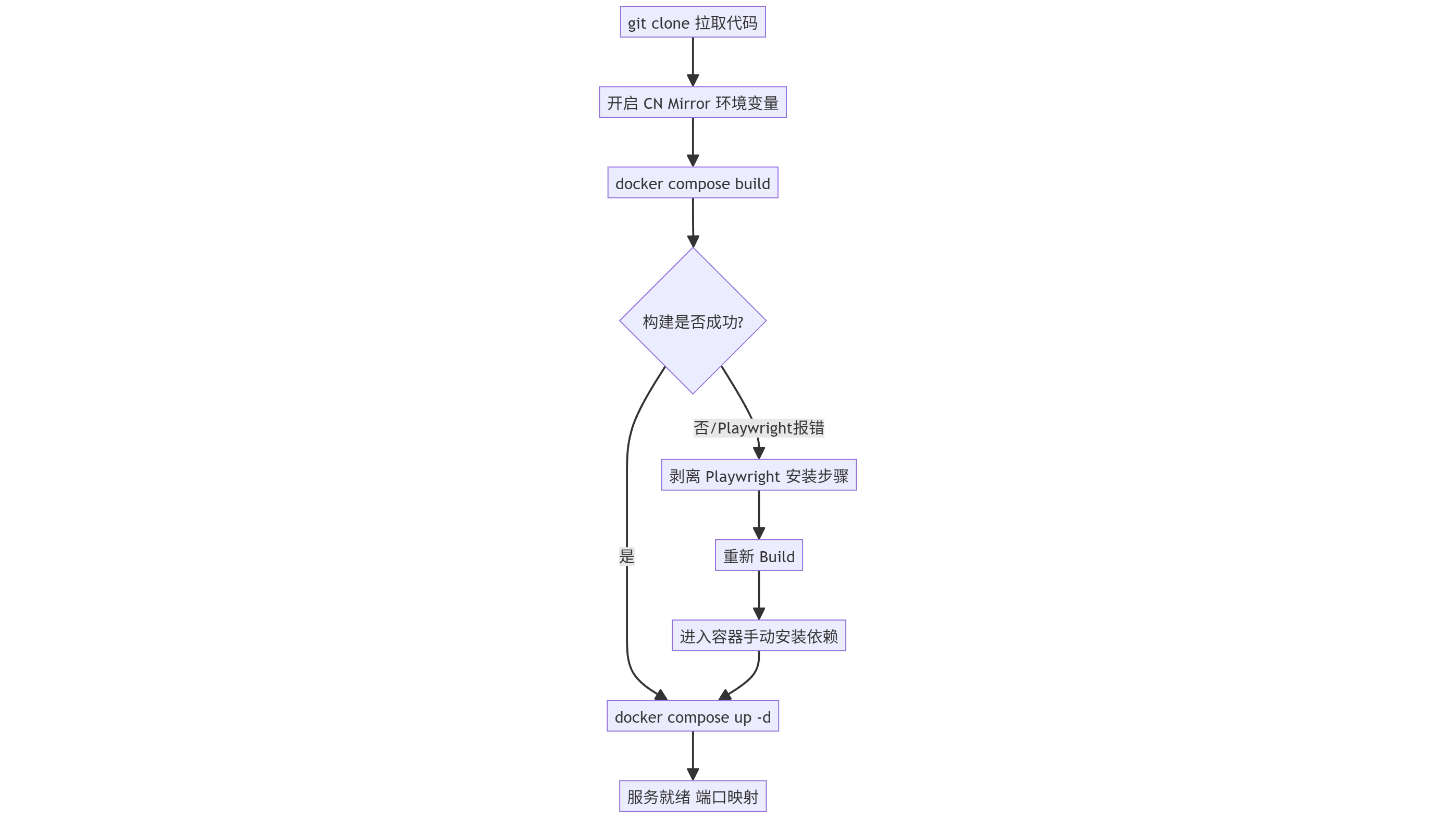
坦白说这里我遇到了一点依赖冲突——pillow和numpy版本不匹配。解决方法是先pip install numpy==1.24.3再装其他包,顺序很重要。
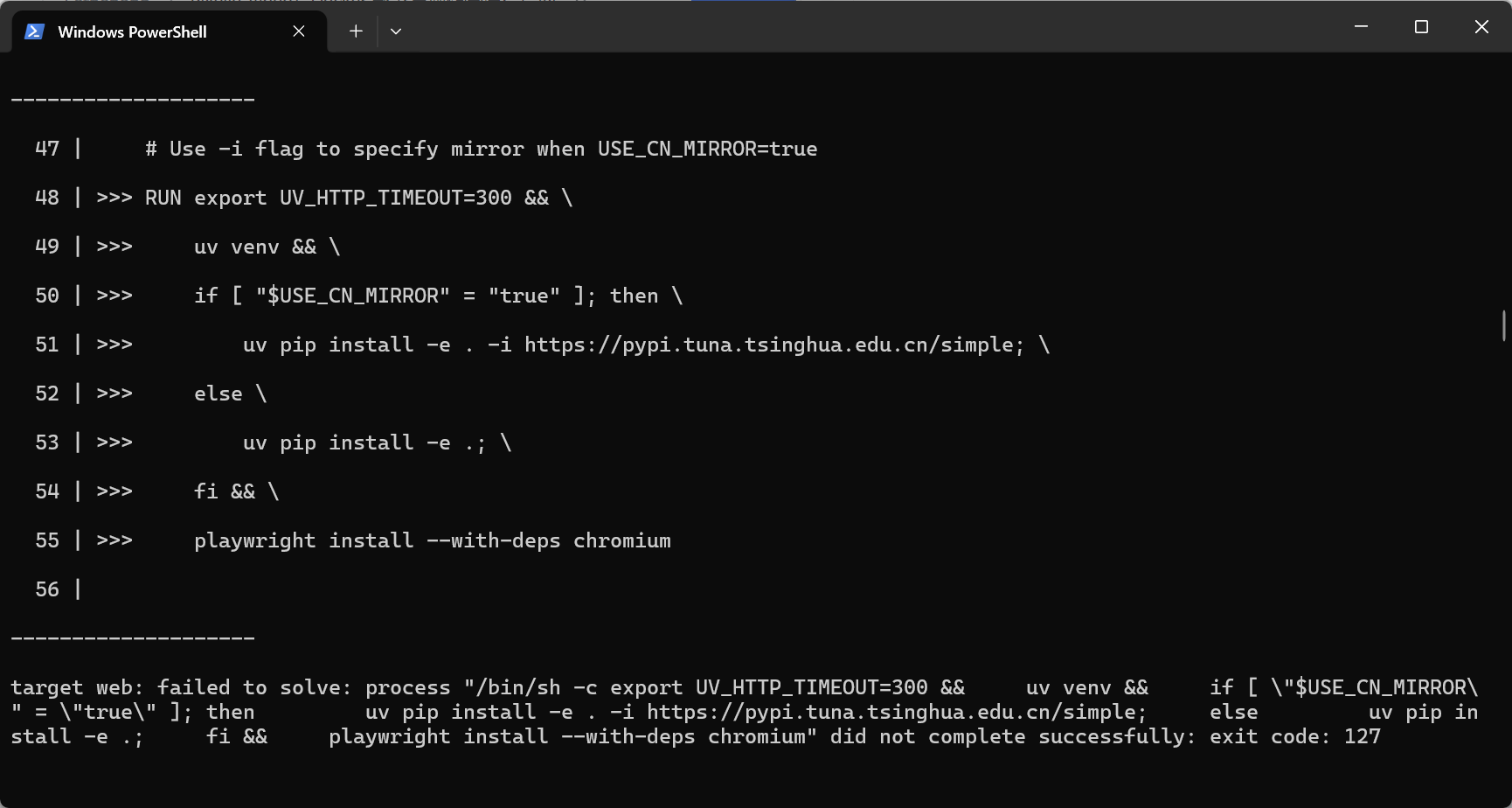
解决之道在于“化整为零”: 用任意编辑器打开项目根目录下的 Dockerfile,找到那段包含 playwright install --with-deps chromium 的代码块,将其临时删去,只保留 Python 依赖的安装:
RUN export UV_HTTP_TIMEOUT=300 && \
uv venv && \
if [ "$USE_CN_MIRROR" = "true" ]; then \
uv pip install -e . -i https://pypi.tuna.tsinghua.edu.cn/simple; \
else \
uv pip install -e .; \
fi && \
playwright install --with-deps chromium改成:
RUN export UV_HTTP_TIMEOUT=300 && \
uv venv && \
if [ "$USE_CN_MIRROR" = "true" ]; then \
uv pip install -e . -i https://pypi.tuna.tsinghua.edu.cn/simple; \
else \
uv pip install -e .; \
fi保存后,重新执行上述的 build 与 up 命令。此时容器能顺利跑起来,但我们还需要把缺失的浏览器内核补上。
潜入容器内部:
在终端输入:
docker exec -it pixelle-video-api bash如何判断是否进入到了容器内容,别着急,继续往下看
如果成功,你会发现最左边的提示符变了。
- 之前是:
PS G:\222\Pixelle-Video> - 现在会变成类似这样:
root@1a2b3c4d5e6f:/app#
只要看到类似 root@xxx:/app#,就说明你已经进入 Docker 容器内部(Linux 环境)了!

然后在当前内部环境下,输入下面的命令进行安装
export UV_HTTP_TIMEOUT=300
uv pip install playwright -i https://pypi.tuna.tsinghua.edu.cn/simple
playwright install --with-deps chromium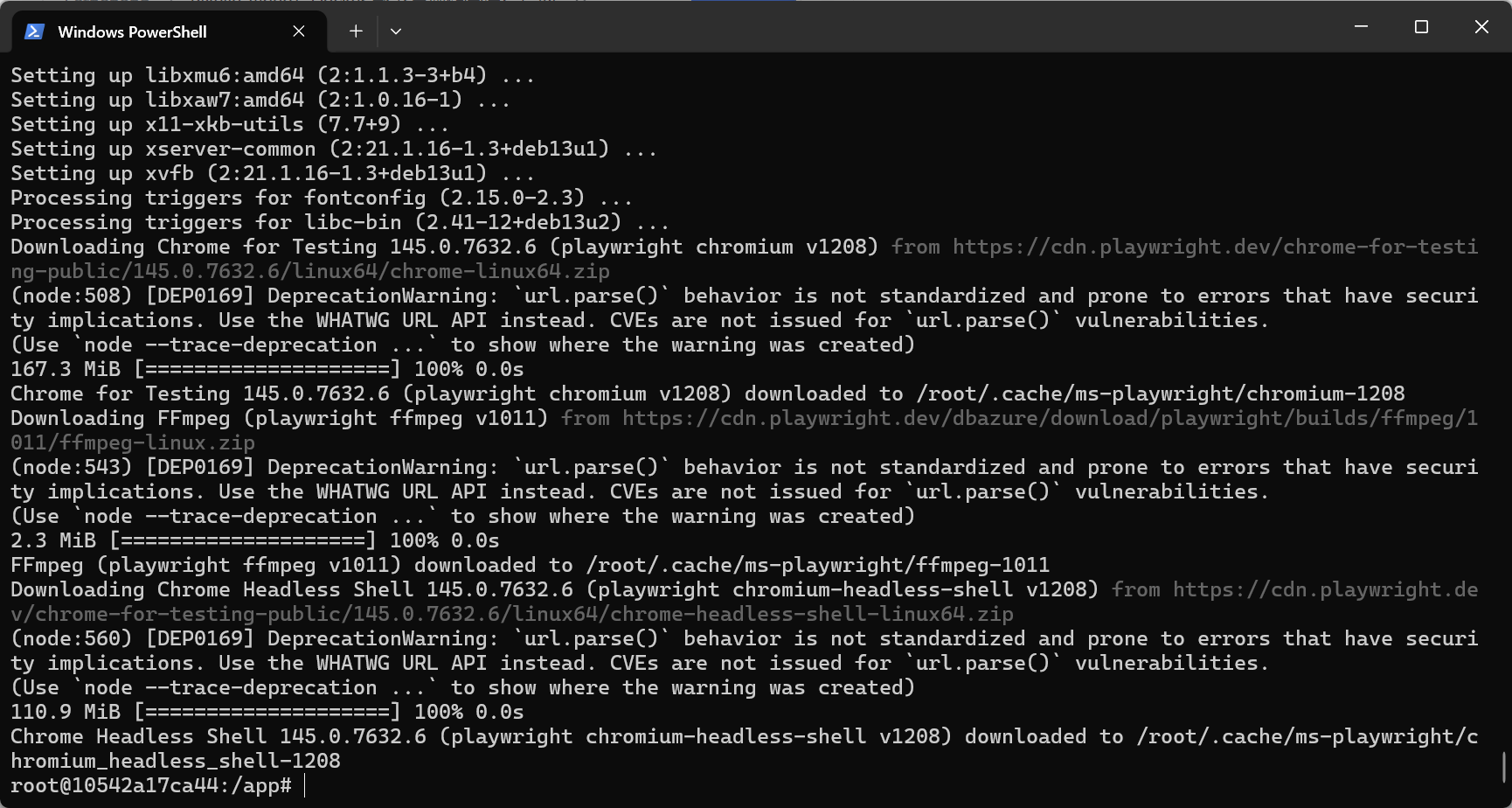
🕵️ 为什么不能直接输入 playwright? 项目使用了 uv venv 在 /app/.venv 下创建了隔离的虚拟环境。可执行文件被安放在 .venv/bin/ 的深处,而非系统的公共路径 /usr/local/bin/。理解了这个层级关系,就不会感到迷惑。
跑完后直接退出就行
装好之后在容器里执行:
exit回到 PowerShell,然后重启让环境生效:
docker compose restart
如果你是在 pixelle-video-api 里装的,但 Web 页面打开报浏览器/Chromium 相关错,那就再对 pixelle-video-web 也执行一遍同样的命令:
docker exec -it pixelle-video-web bash
# 进入后再执行:
export UV_HTTP_TIMEOUT=300
uv pip install playwright -i https://pypi.tuna.tsinghua.edu.cn/simple
.venv/bin/playwright install --with-deps chromium
exit然后 docker compose restart。
2.2 配置蓝耘API
编辑项目根目录的.env文件:
LLM_PROVIDER=openai
LLM_API_KEY=sk-ak********
LLM_BASE_URL=https://maas-api.lanyun.net/v1
LLM_MODEL=/maas/zhipu/GLM-5.1
VIDEO_LANGUAGE=zh
OUTPUT_DIR=./output
核心就这几行配置。Pixelle-Video内部用的是OpenAI兼容的API调用方式,蓝耘的接口完全兼容,所以几乎零配置——改API地址和Key就行。
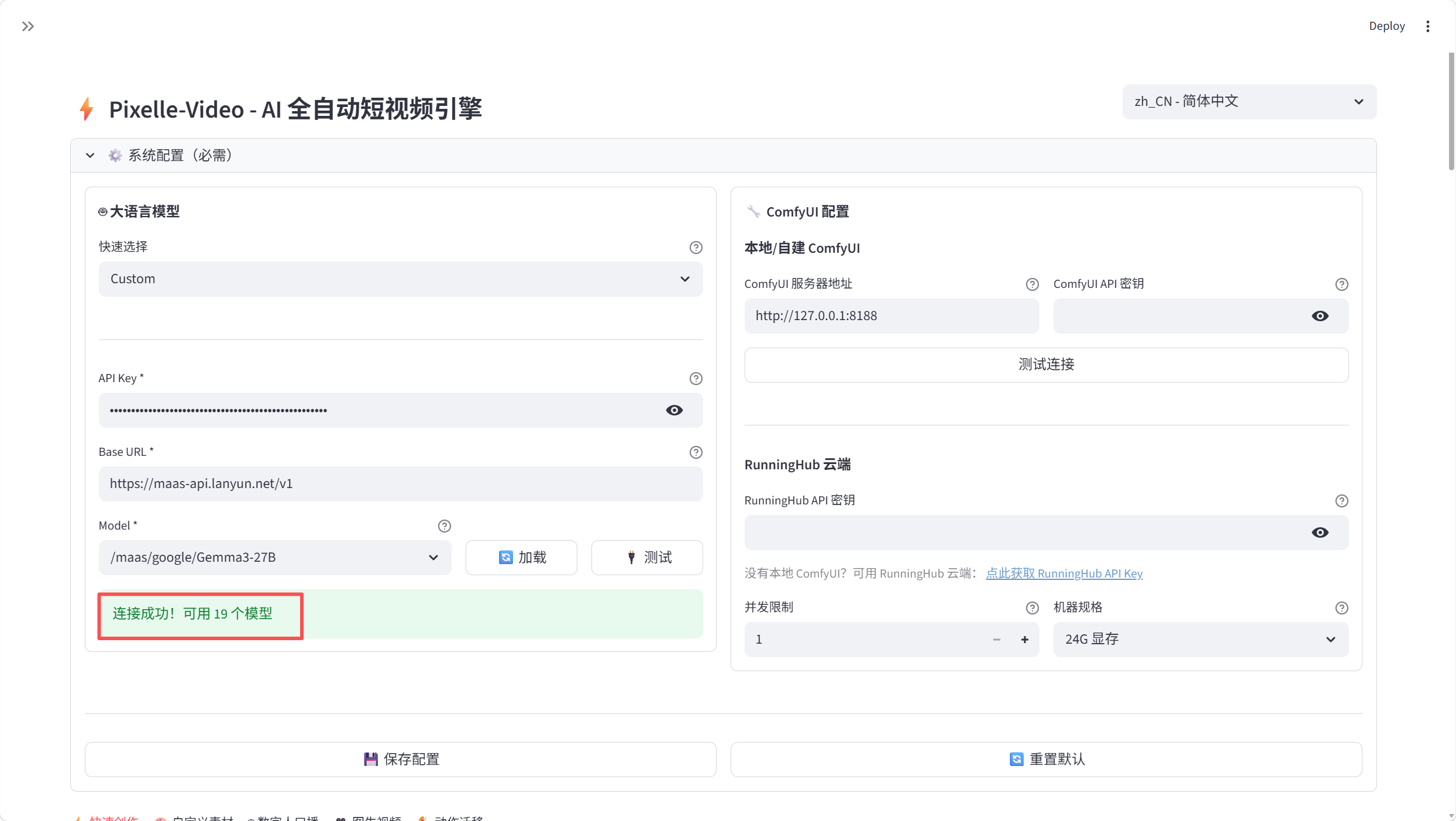
注意模型名要用蓝耘的完整路径/maas/zhipu/GLM-5.1。我第一次只写了GLM-5.1,返回404,翻了一下蓝耘的模型详情页才找到准确路径。
2.3 启动Web界面
python app.py浏览器打开http://localhost:5000,一个极简的Web界面出来了——一个输入框、一个”生成视频”按钮、一个历史列表。简单到我朋友这种非技术背景的人也能秒懂。
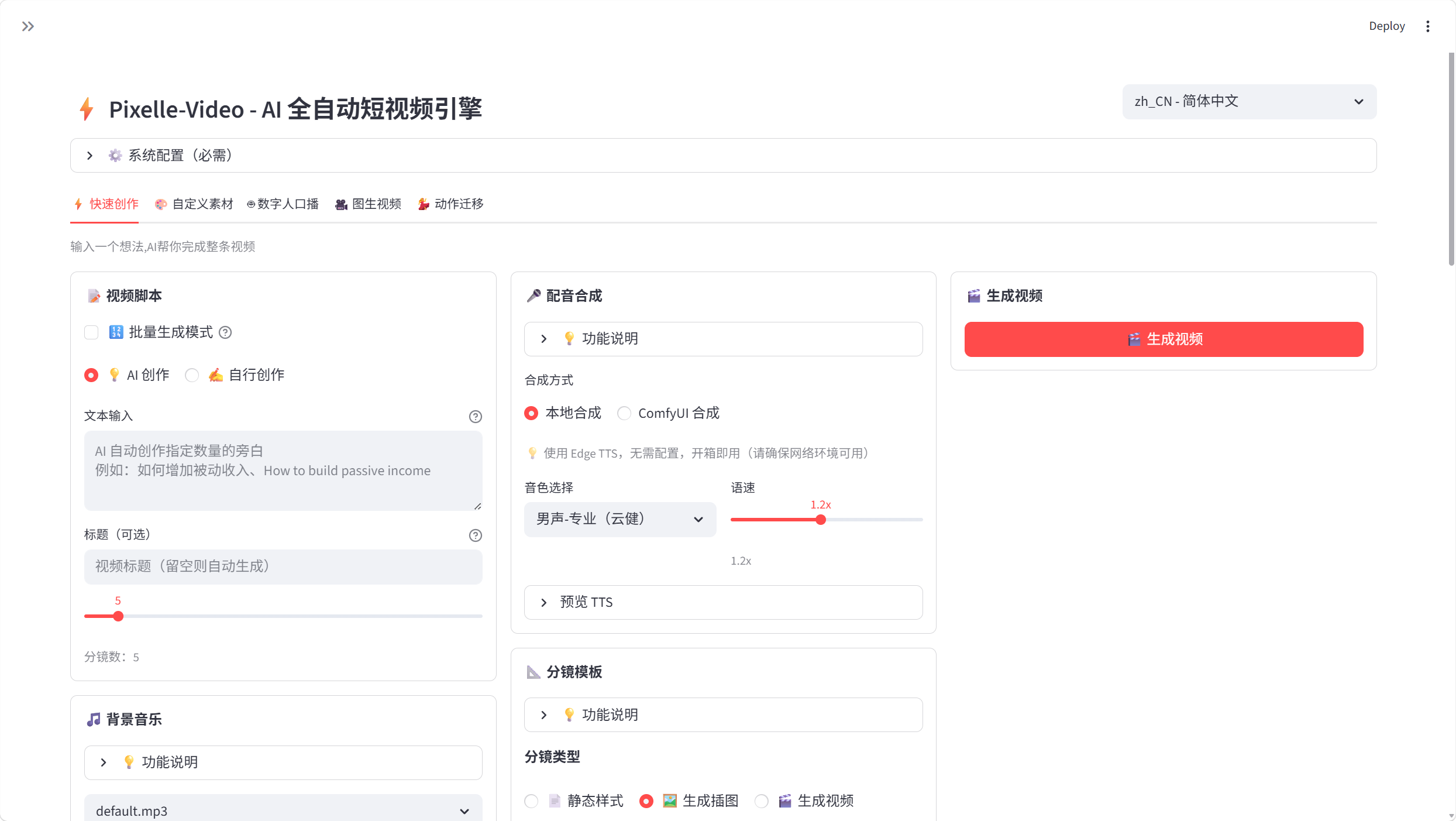
三、实战效果
3.1 生成速度
输入”为什么养成阅读习惯,30秒短视频”,点击生成:
- 脚本生成(蓝耘GLM-5.1):约4秒
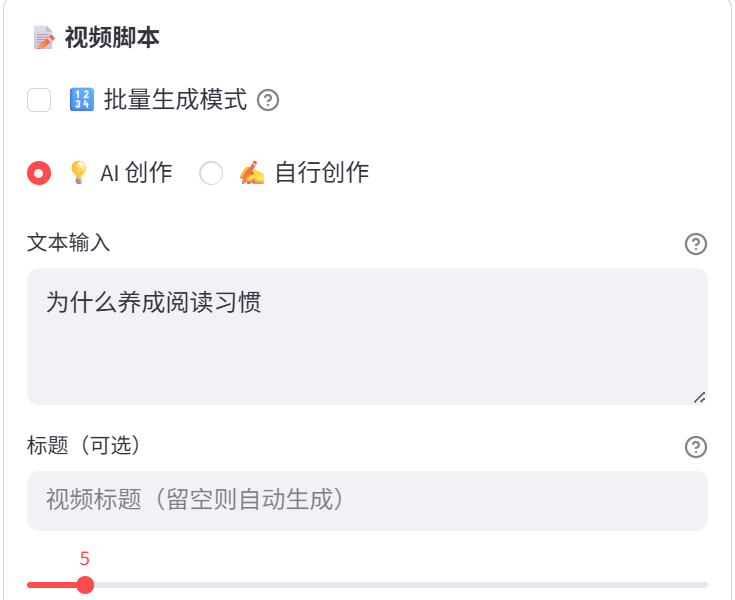
- 素材搜索与下载(Pexels API):约12秒
- 配音合成(Edge TTS):约8秒
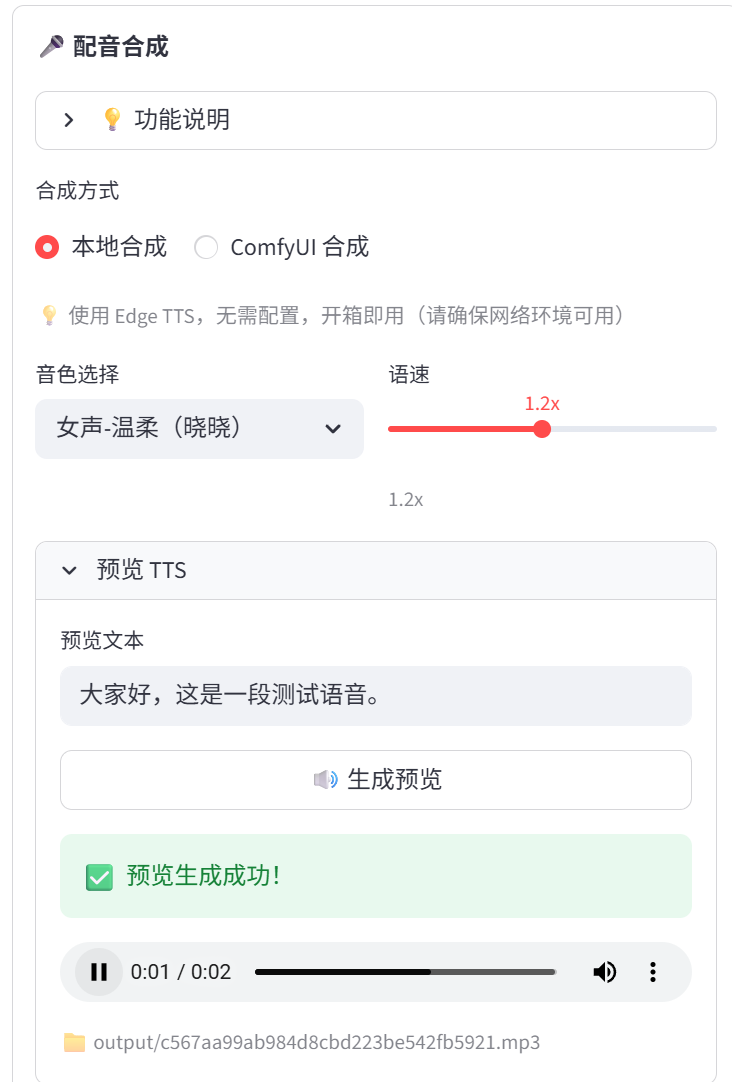
- 视频剪辑合成(FFmpeg):约6秒
- 总耗时:约30秒
一条30秒的短视频,从输入到输出只用了30秒。朋友当场表示:“我之前剪一条至少两小时。”
3.2 蓝耘API的表现
GLM-5.1在创意脚本生成方面的表现以及性能是相当不错。
我测试了不同风格的视频需求:
- “数码产品开箱评测”:脚本逻辑清晰,开头吸引人,结尾有引导关注的话术
- “三分钟读一本书”:自动提取核心观点,分章节展开,节奏感好
- “猫咪搞笑合集旁白”:语气活泼,有网感,知道在什么时间点加什么梗
不过GLM-5.1在极专业的垂直领域(比如医学知识科普)偶尔会出现术语不准确的问题。我让朋友在实际使用时,生成完脚本后再花两分钟快速过一遍关键信息,效率依然提升非常大。

3.3 成本算账
朋友用了一个月后的蓝耘账单:
- 生成视频脚本:约150条
- 总token消耗:约75万(输入+输出)
- 总API费用:不到1.2元
对比之前299元/月的SaaS工具,成本几乎是零。而且Pixelle-Video生成的视频直接保存在本地,不像SaaS工具那样有存储限制和视频水印。
四、避坑指南
4.1 素材搜索失败
Pexels和Pixabay的免费API有调用频率限制(Pexels免费版每小时200次)。如果连续大量生成视频,素材搜索会返回429错误。解决方案:在项目的config.py里找到Pexels API Key的设置,去Pexels官网注册一个免费账号,用自己的Key替换默认的——自己的Key有更高频率配额。
4.2 中文配音口音问题
Pixelle-Video默认用Edge TTS做中文配音,但Edge TTS的中文发音偶尔会有奇怪的断句或者把”什么”读成”什-么”。朋友说她的观众反馈”声音有点AI味儿”,我建议她换成Azure TTS的付费版(声音更自然,月费约15元),她试了后说提升明显。这个不是蓝耘或Pixelle-Video的问题,是TTS引擎本身的局限。
4.3 超长视频内存溢出
有一次朋友想生成一条3分钟的深度讲解视频,FFmpeg合成时报内存溢出。原因是Pixelle-Video默认把所有素材帧一次性加载到内存。解决方法是把video_processor.py里的batch_size从默认的0(全部加载)改成50(分批处理),内存占用从4GB降到了500MB。
五、GLM-5.1 vs 其他国产模型
我在蓝耘上做了个横向对比,同样的脚本生成任务:
|
模型 |
脚本生成时间 |
创意评分(主观) |
每万token成本 |
|
GLM-5.1 |
4.2秒 |
8/10 |
0.5+1元 |
|
DeepSeek-V3.2 |
6.8秒 |
7/10 |
2+3元 |
|
Qwen3-235B |
5.1秒 |
7.5/10 |
3+9元 |
GLM-5.1在创意脚本场景下性价比最高——速度快、创意评分高、价格最低。智谱在中文创意写作上的积累确实扎实。
结语
Pixelle-Video + 蓝耘GLM-5.1这套组合,从安装到生产出第一条视频,总共花了我约两个小时(其中至少40分钟在解决Python依赖冲突)。给朋友配好后她一个月生了150+条短视频。
最大的感受是:蓝耘的模型广场聚合了国内主流大模型,GLM-5.1、DeepSeek、Qwen这些国产模型都能在一个平台上直接调用。如果不走蓝耘,要同时用多个国产模型,要么在各家平台分别注册充值,要么自己部署GPU。蓝耘把多模型调用的门槛从”需要分别对接各家API”降到了”一个Key全搞定”。 Key”。
朋友最近在抖音上的播放量从每条一两百涨到稳定破千,问我要不要合伙做AI视频代运营。我说你先跑通了商业模式再找我,但我可以免费帮你看蓝耘的账单——反正你也花不了几块钱。

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐


 26
26 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)