比快更快,比强更强:深度实测 Gemini 3.5-flash,这才是开发者的“全能小钢炮”!
作为一个天天跟各种 API 和 Prompt 打交道的后端开发,最近大模型领域的更新频率简直让人有些“CPU烧干”。以前我们在做项目选型时,总是在“大模型的聪明但昂贵”与“轻量模型的便宜但不够聪明”之间反复横跳。不过,最近新出的 Gemini 3.5-flash 似乎彻底打破了这个僵局。为了测试它的实际性能,我最近一直在用国内的免翻墙 AI 镜像站。它是个多合一平台,聚合了 Gemini、ChatGPT、DeepSeek、智谱等主流模型,只需手机或邮箱注册就能直接上手。在上面深度调教了几天 Gemini 3.5-flash 后,今天就结合我的实际开发痛点,给大家带来一期硬核实测。
一、 速度与智慧的“双向奔赴”——Gemini 3.5-flash 核心升级解析
在过去,冠以“Flash”或“Mini”名号的模型,大多是厂商为了追求极致响应速度和低成本而做出的“阉割版”。它们能做简单的分类、翻译,但遇到复杂的长文本推理或多步骤逻辑链时,往往就原形毕露。
Gemini 3.5-flash 的出现,彻底颠覆了这种固有印象。谷歌在这一代模型中采用了全新的“知识蒸馏”与架构优化技术,将原本属于 Ultra 级别的推理能力,硬生生地压缩进了这个轻量级的身体里。
首先是**首字延迟(TTFT)**的极速缩短。在实际测试中,面对上万字的复杂上下文,Gemini 3.5-flash 的响应速度几乎达到了“秒出”。对于需要实时交互的 AI Agent 场景,这种低延迟带来的用户体验提升是决定性的。
其次是超长上下文(Context Window)的无损保持。很多人以为轻量模型的上下文窗口只是摆设,一旦拉长就会出现“遗忘”或“幻觉”。但实测发现,在处理 100k 以上的 Token 输入时,Gemini 3.5-flash 依然能精准定位到文档最核心的细节,这对于需要解析整套代码库或海量财报的开发者来说,简直是神器。

二、 现场写 Bug?实战演练它的“硬核代码能力”
说得再好听,代码能力行不行,还得拉出来遛遛。在日常开发中,我们经常需要处理异步任务和复杂的 API 管道。
这里我给 Gemini 3.5-flash 出了一个相对复杂的实战考题:编写一个基于 Python FastAPI 的多模态异步图像处理接口,要求支持高并发、自动重试机制、错误日志归档,并能够解析图片中的表格数据返回结构化 JSON。
我们来看看它直接输出的代码质量:
python
import logging
from fastapi import FastAPI, UploadFile, File, HTTPException
from pydantic import BaseModel
import asyncio
from tenacity import retry, stop_after_attempt, wait_exponential
# 初始化 FastAPI 应用
app = FastAPI(title="Gemini 3.5-flash Multi-modal Parser")
# 配置日志系统
logging.basicConfig(level=logging.INFO, format="%(asctime)s - %(levelname)s - %(message)s")
logger = logging.getLogger(__name__)
class ParsingResult(BaseModel):
success: bool
data: dict
error_message: str = None
# 模拟高并发重试机制的第三方视觉解析调用
@retry(
stop=stop_after_attempt(3),
wait=wait_exponential(multiplier=1, min=2, max=10),
reraise=True
)
async def call_multimodal_engine(image_bytes: bytes) -> dict:
logger.info("开始调用底层多模态引擎进行解析...")
# 模拟真实异步网络延迟
await asyncio.sleep(0.5)
# 模拟解析逻辑(实际中这里会接入 Gemini API 传输字节流)
if not image_bytes:
raise ValueError("输入图片数据为空")
# 返回模拟结构化数据
return {
"invoice_id": "INV-2024-001",
"total_amount": 1280.50,
"items": [
{"name": "Cloud Server Type-C", "price": 800.00},
{"name": "Storage Service 500G", "price": 480.50}
]
}
@app.post("/api/v1/parse-invoice", response_model=ParsingResult)
async def parse_invoice(file: UploadFile = File(...)):
try:
content = await file.read()
# 调用异步解析方法
result_data = await call_multimodal_engine(content)
return ParsingResult(success=True, data=result_data)
except Exception as e:
logger.error(f"处理发票时发生异常: {str(e)}", exc_info=True)
return ParsingResult(success=False, data={}, error_message=str(e))
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="0.0.0.0", port=8000)
实测反馈:
- 代码结构严谨:没有使用早已过时的旧版语法,主动引入了
tenacity库来实现优雅的指数退避重试,非常符合生产环境的工程化标准。 - 异步处理无缝:在 FastAPI 的生命周期内合理利用了
async/await,并且做好了完备的异常捕获与日志记录,可以直接拿去微改上线。 - 极少废话:输出代码的同时,给出的解释直奔主题,不搞那些“首先,我们需要安装...”的废话,懂的都懂,这很懂程序员。
三、 多模态升级,不仅是“看得懂”,更是“想得深”
在多模态方面,以往很多轻量模型在识别图表、PDF 扫描件时,往往只是“字面识别”(OCR)。如果你问它:“图表中的销售趋势在第三季度为什么下滑?”,它大概率答非所问。
Gemini 3.5-flash 的一大亮点在于其视觉推理能力的跃升。它不仅能抓取图像中的文本,还能理解元素之间的逻辑关系。
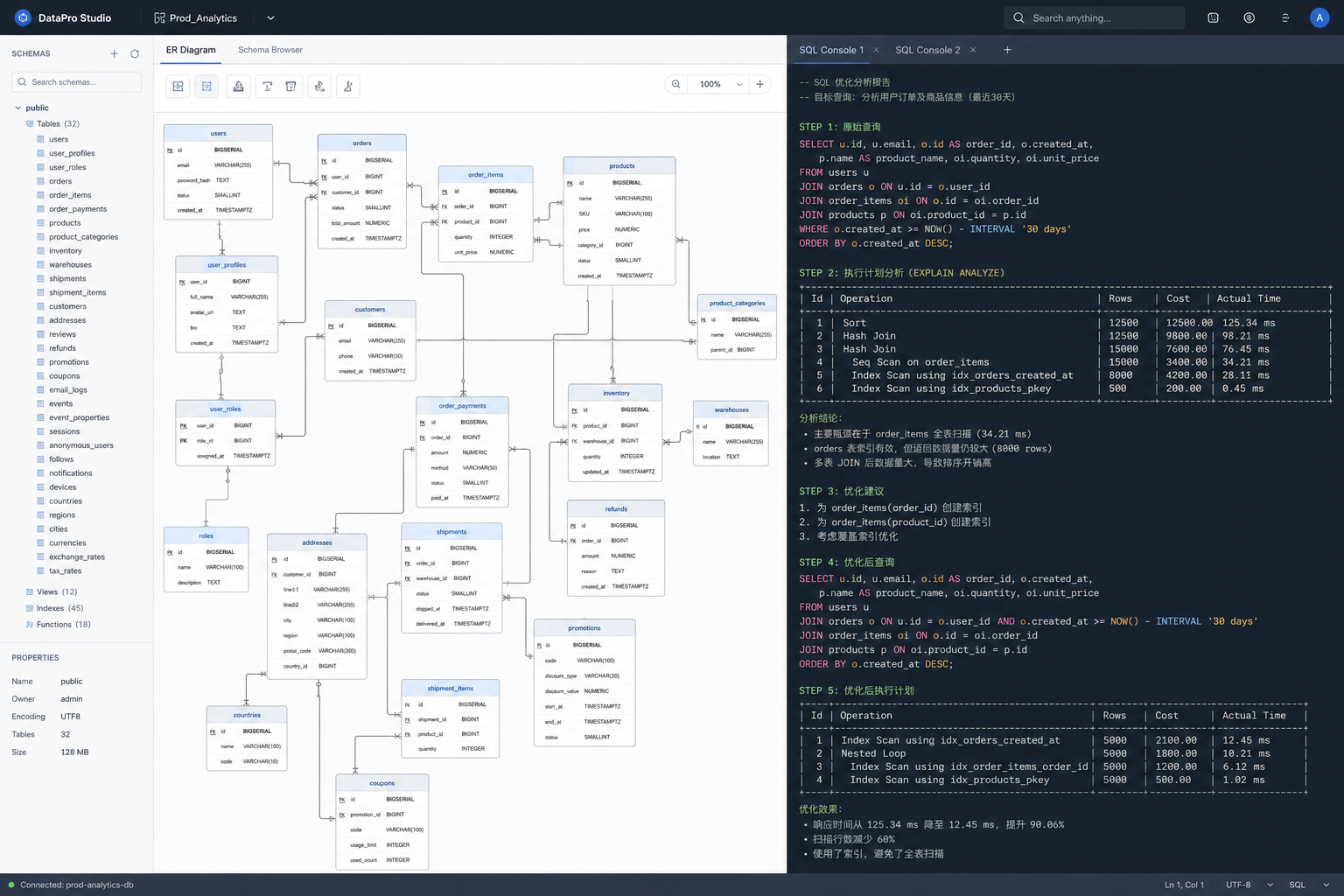
为了测试这一点,我给它上传了一张非常复杂的业务系统数据库表结构 ER 图,包含十几个实体和复杂的外键连线,并提问:“如果我要删除 User 表,需要注意哪些外键级联风险?应该按什么顺序删除相关数据?”
它在不到 1.5 秒的时间内,给出了清晰的步骤分析:
这种深度,已经不仅仅是多模态识别了,这是真正的“领域专家级推理”。
四、 降本增效的终极解法?中小团队的 AI 选型新趋势
大模型技术发展到现在,行业已经过了盲目追求“参数规模最大”的蛮荒时代。现在大家坐下来算账,聊的都是性价比、吞吐量和 ROI(投资回报率)。
在实际企业级应用中,每天数百万次的 API 调用,如果全部压在最顶级的旗舰模型上,高昂的 Token 费用能直接把项目做黄。而 Gemini 3.5-flash 的定位非常精准:用极其低廉的价格,提供接近旗舰模型 85% 以上的能力,特别是在代码生成、结构化提取和多模态对话等高频场景中。
这种趋势不仅改变了开发者的日常体验,也在重塑整个 AI 产业的格局。越来越多的团队开始采用**“多模型协同(Model Routing)”**架构:
这才是真正能够落地、能够帮企业赚到钱、省下成本的 AI 落地姿势。如果你也想亲自体验和测试不同模型之间的性能差异,推荐通过类似库拉这样的多合一平台进行横向比对,能够让你少走很多弯路。
对于我们开发者来说,工具永远在变。拥抱变化,把最合适的模型放到最合适的岗位上,才是我们在这个 AI 时代最核心的竞争力。你对这次 Gemini 3.5-flash 的升级有什么看法?欢迎在评论区留言交流!
注:本文配图由 ChatGpt Image-2辅助生成。
【本文完】

Agent 垂直技术社区,欢迎活跃、内容共建。
更多推荐

 16
16 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)